不是所有圖像都值16x16個詞,清華與華為提出動態ViT
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
在NLP中,Transformer以自注意力模型機制為法寶,在圖像識別問題上的成功已經很廣泛了。
尤其是,ViT在大規模圖像網絡上性能特別高,因此應用特別廣。
但隨著數據集規模的增長,會導致計算成本急劇增加,以及自注意力中的tokens數量逐漸增長!
最近,清華自動化系的助理教授黃高的研究團隊和華為的研究人員另辟蹊徑,提出了一種Dynamic Vision Transformer (DVT),可以自動為每個輸入圖像配置適當數量的tokens,從而減少冗余計算,顯著通過效率。
該文以《Not All Images are Worth 16x16 Words: Dynamic Vision Transformers with Adaptive Sequence Length》為標題,已發表在arXiv上。
提出動態ViT
很明顯,當前的ViT面臨計算成本和tokens數量的難題。
為了在準確性和速度之間實現最佳平衡,tokens的數量一般是 14x14/16x16的。
研究團隊觀察到:
一般樣本中會有很多的“簡單”圖像,它們用數量為 4x4 標記就可以準確預測,現在的計算成本( 14x14)相當于增加了8.5倍,而其實只有一小部分“困難”的圖像需要更精細的表征。
通過動態調整tokens數量,計算效率在“簡單”和 “困難”樣本中的分配并不均勻,這里有很大的空間可以提高效率。
基于此,研究團隊提出了一種新型的動態ViT(DVT )框架,目標是自動配置在每個圖像上調節的tokens數量 ,從而實現高計算效率。
這種DVT被設計成一個通用框架。
在測試時間時,這些模型以較少的tokens 開始依次被激活。
一旦產生了充分置信度的預測,推理過程就會立即終止。
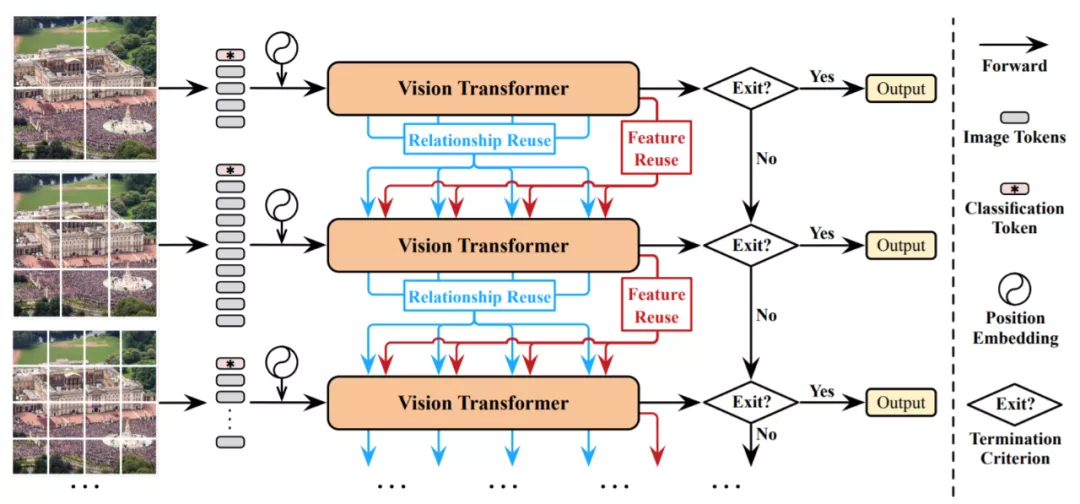
模型的主體架構采用目前最先進的圖像識別Transformer,如ViT、DeiT和T2T-ViT,可以提高效率。
這種方法同時也具有很強的靈活性。
因為DVT的計算量可以通過簡單的提前終止準則進行調整。
這一特性使得DVT適合可用計算資源動態變化,或通過最小功耗來實現給定性能的情況。
這兩種情況在現實世界的應用程序中都是普遍存在的,像搜索引擎和移動應用程序中都經常能夠看到。
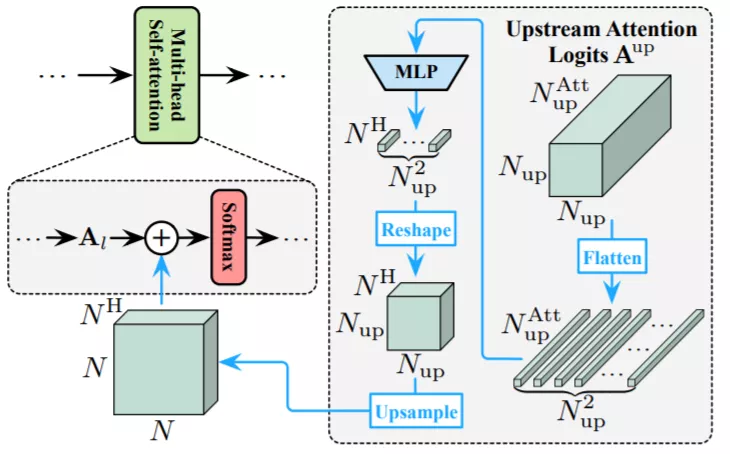
根據上面的流程圖,仔細的讀者還會發現:
一旦從上游往下游計算無法成功的時候,就會采取向先前信息或者上游信息進行重用的方法實現進一步數據訓練。
研究團隊在此基礎上,還進一步提出了特征重用機制和關系重用機制,它們都能夠通過最小化計算成本來顯著提高測試精度,以減少冗余計算。
前者允許在先前提取的深度特征的基礎上訓練下游數據,而后者可以利用現有的上游的自注意力模型來學習更準確的注意力。
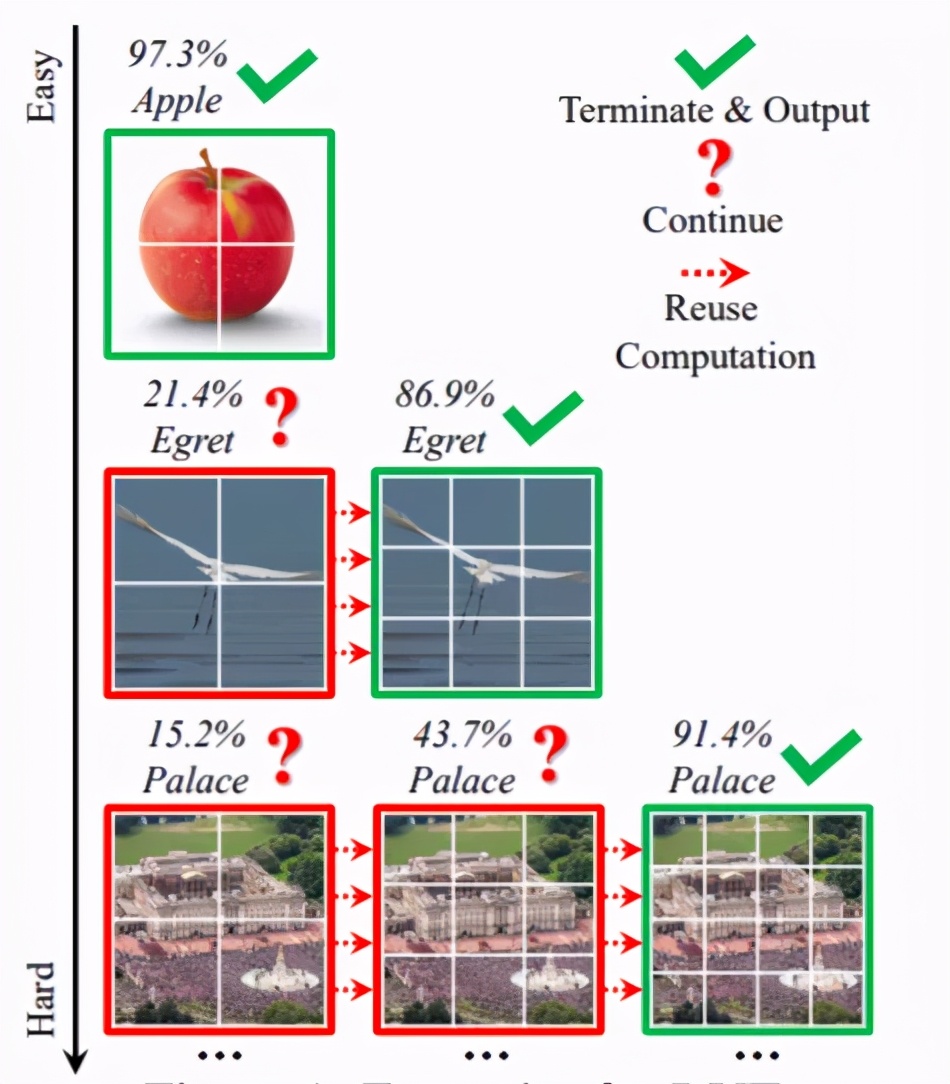
這種對“簡單”“困難”動態分配的方法,其現實效果可以由下圖的實例給出說明。
那么,接下來讓我們來看看這兩種機制具體是怎么做的?
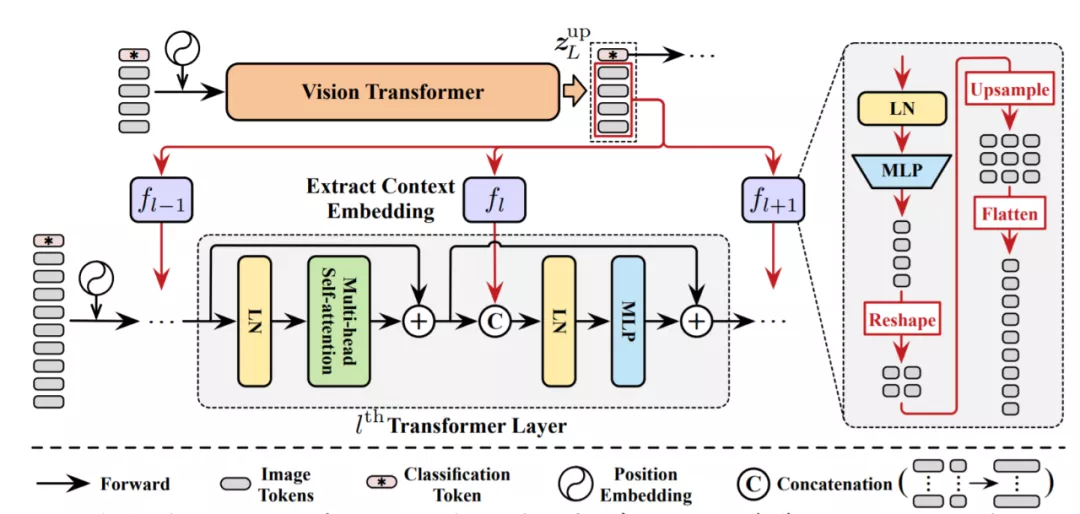
特征重用機制
DVT中所有的Transformer都有一個共同的目標:提取特征信號來實現準確的識別。
因此,下游模型應該在之前獲得的深度特征的基礎上進行學習,而不是從零開始提取特征。
在上游模型中執行的計算對其自身和后續模型都有貢獻,這樣會使模型效率更高。
為了實現這個想法,研究團隊提出了一個特征重用機制。
簡單來說,就是利用上游Transformer最后一層輸出的圖像tokens,來學習逐層的上下文嵌入,并將其集成到每個下游Transformer的MLP塊中。
關系重用機制
Transformer的一個突出優點是:
自注意力塊能夠整合整個圖像中的信息,從而有效地模型化了數據中的長期依賴關系。
通常,模型需要在每一層學習一組注意力圖來描述標記之間的關系。
除了上面提到的深層特征外,下游模型還可以獲得之前模型中產生的自注意力圖。
研究團隊認為,這些學習到的關系也能夠被重用,以促進下游Transformer學習,具體采用的是對數的加法運算。
效果如何?
多說無益,讓我們看看實際效果如何?
在ImageNet上的 Top-1準確率v.s.計算量如下圖。
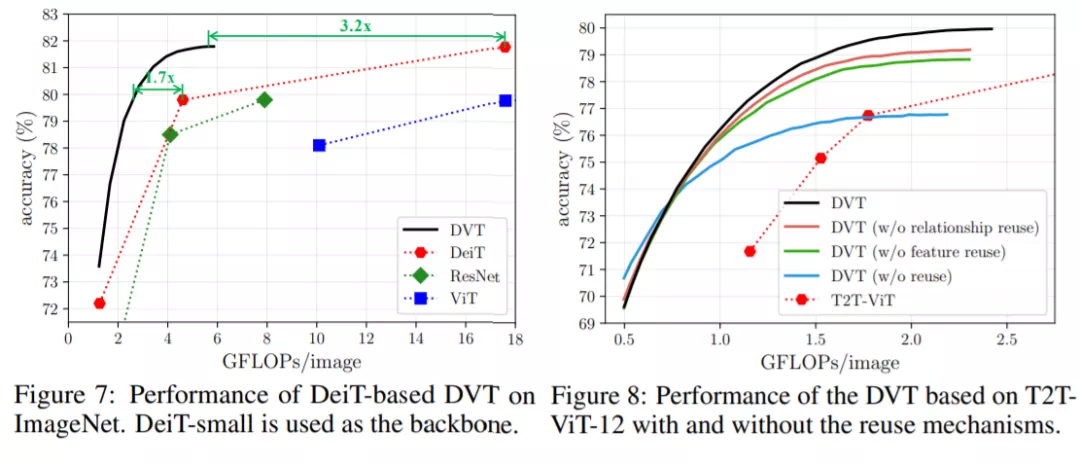
可以看出,DVT比DeiT和T2T-VIT計算效率要顯著更好:
當計算開銷在0.5-2 GFLOPs內時,DVT的計算量比相同性能的T2T-ViT少了1.7-1.9倍。
此外,這種方法可以靈活地達到每條曲線上的所有點,只需調整一次DVT的置信閾值即可。
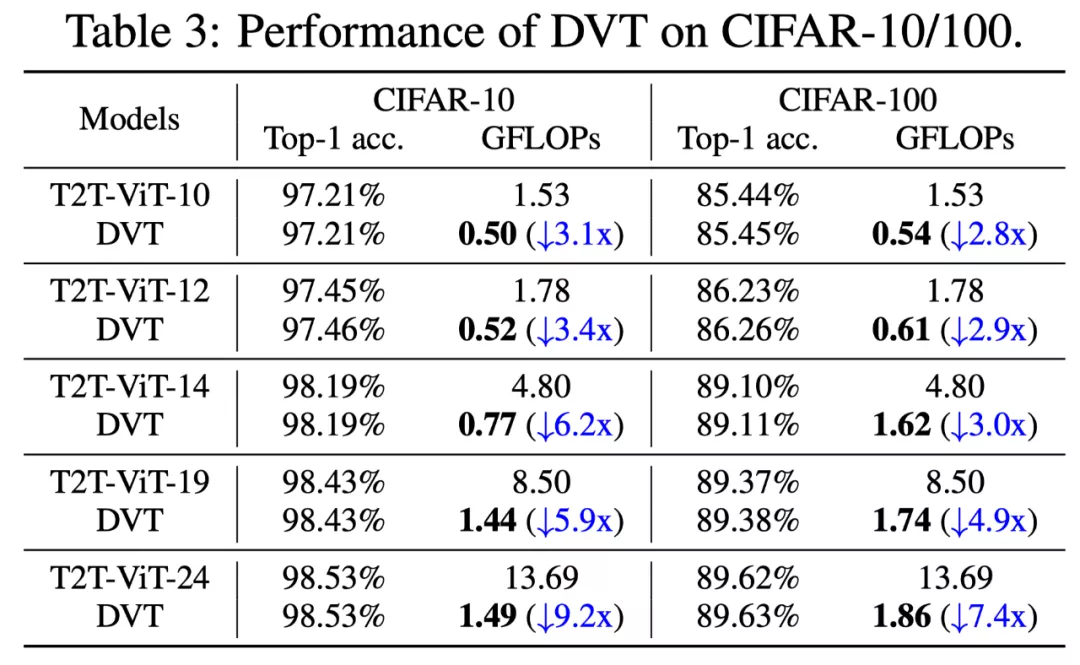
CIFAR的 Top-1 準確率 v.s. GFLOP 如下圖。
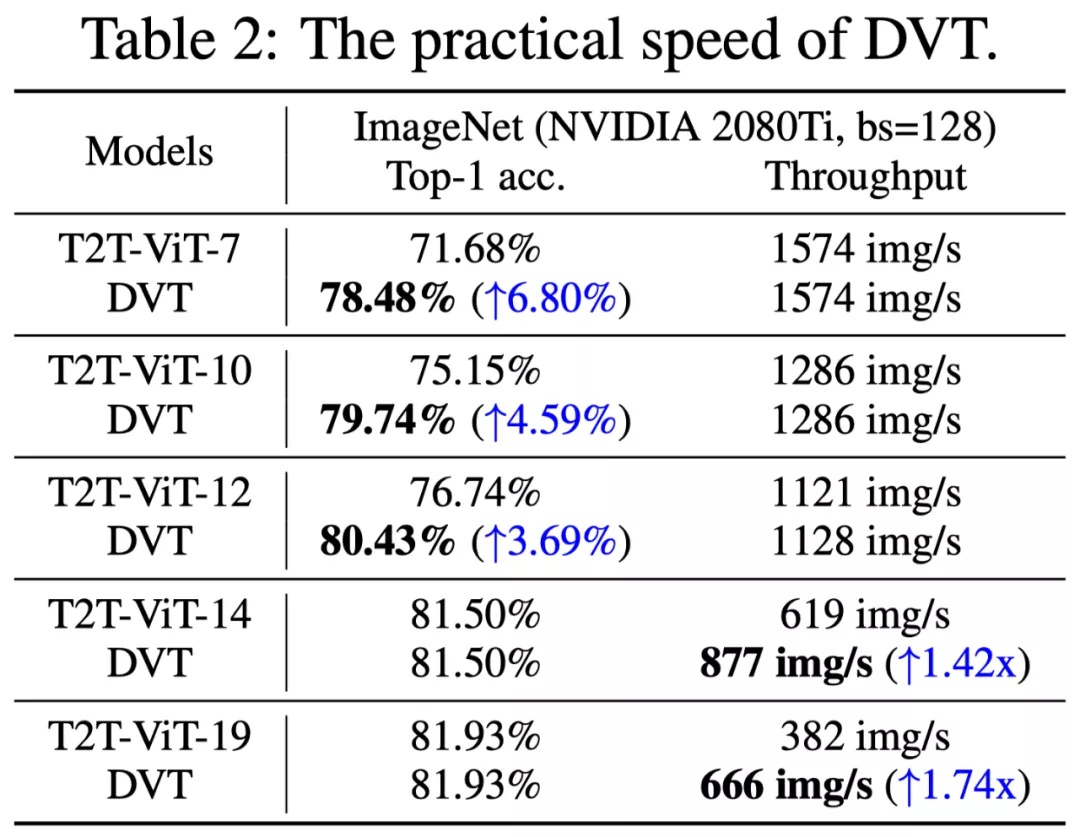
在ImageNet上的 Top-1準確率v.s.吞吐量如下表。
在DVT中,“簡單”和 “困難”的可視化樣本如下圖。

從上面ImageNet、CIFAR-10 和 CIFAR-100 上的大量實證結果表明:
DVT方法在理論計算效率和實際推理速度方面,都明顯優于其他方法。
看到這樣漂亮的結果,難道你還不心動嗎?
有興趣的小伙伴歡迎去看原文哦~
傳送門
論文地址:
https://arxiv.org/abs/2105.15075
研究團隊
黃高
目前年僅33歲,已是清華大學自動化系助理教授,博士生導師。
獲得過2020年阿里巴巴達摩院青橙獎,研究領域包括機器學習、深度學習、計算機視覺、強化學習等。