













手把手教你Golang的協程池設計
本文轉載自微信公眾號「程序員小飯」,作者飯米粒。轉載本文請聯系程序員小飯公眾號。
前言
現在很多公司都在陸續的搭建golang的語言棧,大家有沒有想過為什么會出現這種情況?一是因為go比較適合做中間件,還有一個原因就是go的并發支持比較好,也就是咱們平時所謂的高并發,并發支持離不開協程,當然協程也不是亂用的,需要管理起來,管理協程的方式就是協程池,所以協程池也并沒有那么神秘,今天咱們就來一步一步的揭開協程池的面紗,如果你沒有接觸過go的協程這塊的話也沒有關系,我會盡量寫的詳細。
goroutine(協程)
先來看一個簡單的例子
- func go_worker(name string) {
- for i := 0; i < 5; i++ {
- fmt.Println("我的名字是", name)
- time.Sleep(1 * time.Second)
- }
- fmt.Println(name, "執行完畢")
- }
- func main() {
- go_worker("123")
- go_worker("456")
- for i := 0; i < 5; i++ {
- fmt.Println("我是main")
- time.Sleep(1 * time.Second)
- }
- }
咱們在執行這段代碼的時候,當然是按照順序執行
go_worker("123")->go_worker("456")->我是main執行
輸出結果如下
- 我的名字是 123
- 我的名字是 123
- 我的名字是 123
- 我的名字是 123
- 我的名字是 123
- 123 執行完畢
- 我的名字是 456
- 我的名字是 456
- 我的名字是 456
- 我的名字是 456
- 我的名字是 456
- 456 執行完畢
- 我是main
- 我是main
- 我是main
- 我是main
- 我是main
這樣的執行是并行的,也就是說必須得等一個任務執行結束,下一個任務才會開始,如果某個任務比較慢的話,整個程序的效率是可想而知的,但是在go語言中,支持協程,所以我們可以把上面的代碼改造一下
- func go_worker(name string) {
- for i := 0; i < 5; i++ {
- fmt.Println("我的名字是", name)
- time.Sleep(1 * time.Second)
- }
- fmt.Println(name, "執行完畢")
- }
- func main() {
- go go_worker("123") //協程
- go go_worker("456") //協程
- for i := 0; i < 5; i++ {
- fmt.Println("我是main")
- time.Sleep(1 * time.Second)
- }
- }
我們在不同的go_worker前面加上了一個go,這樣所有任務就異步的串行了起來,輸出結果如下
- 我是main
- 我的名字是 456
- 我的名字是 123
- 我的名字是 123
- 我是main
- 我的名字是 456
- 我是main
- 我的名字是 456
- 我的名字是 123
- 我是main
- 我的名字是 456
- 我的名字是 123
- 我的名字是 456
- 我的名字是 123
- 我是main
大家可以看到這樣的話就是各自任務執行各自的事情,互相不影響,效率也得到了很大的提升,這就是goroutine
channel(管道)
有了協程之后就會帶來一個新的問題,協程之間是如何通信的?于是就引出了管道這個概念,管道其實很簡單,無非就是往里放數據,往外取數據而已
- func worker(c chan int) {
- num := <-c //讀取管道中的數據,并輸出
- fmt.Println("接收到參數c:", num)
- }
- func main() {
- //channel的創建,需要執行管道數據的類型,我們這里是int
- c := make(chan int)
- //開辟一個協程 去執行worker函數
- go worker(c)
- c <- 2 //往管道中寫入2
- fmt.Println("main")
- }
我們可以看到上述例子,在main函數中,我們定義了一個管道,為int類型,而且往里面寫入了一個2,然后在worker中讀取管道c,就能獲取到2
協程會引發的問題
既然golang中開啟協程這么方便,那么會不會存在什么坑呢?
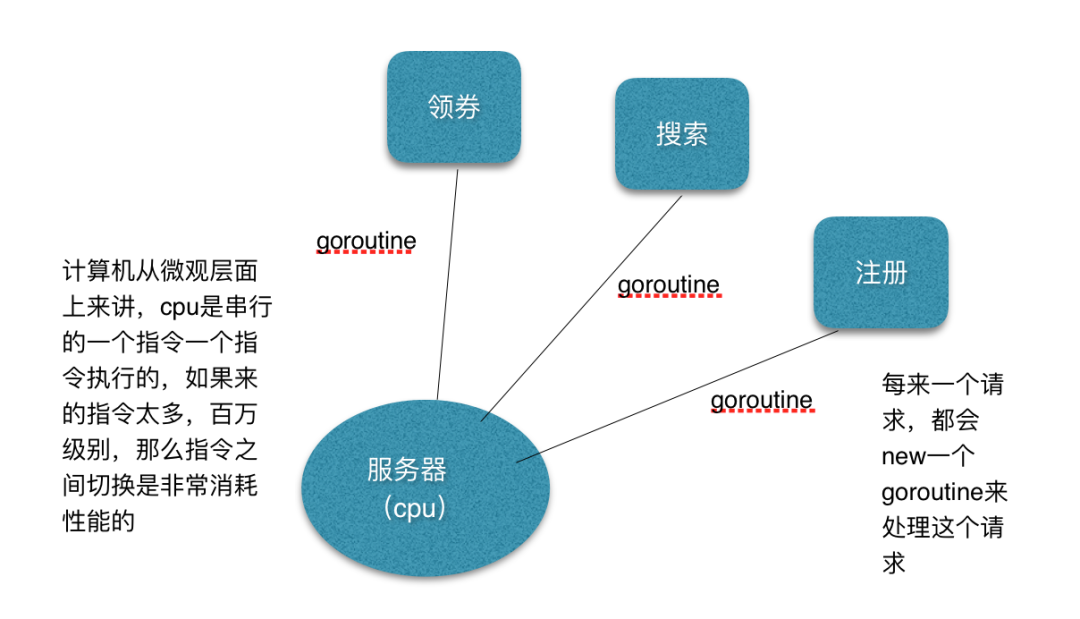
我們可以看上圖,實際業務中,不同的業務都開啟不同的goroutine來執行,但是在cpu微觀層面上來講,是串行的一個指令一個指令去執行的,只是執行的非常快而已,如果指令來的太多,cpu的切換也會變多,在切換的過程中就需要消耗性能,所以協程池的主要作用就是管理goroutine,限定goroutine的個數
協程池的實現
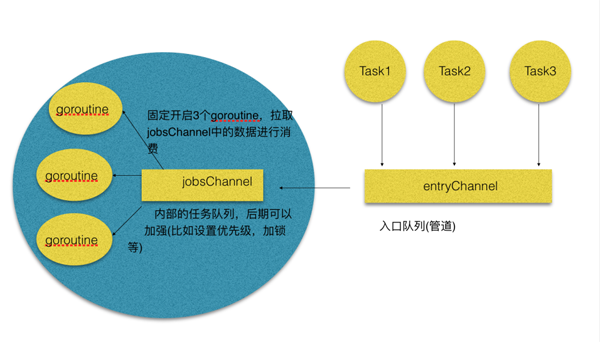
- 首先不同的任務,請求過來,直接往entryChannel中寫入,entryChannel再和jobsChannel建立通信
- 然后我們固定開啟三個協程(不一定是三個,只是用三個舉例子),固定的從jobsChannel中讀取數據,來進行任務處理。
- 其實本質上,channel就是一道橋梁,做一個中轉的作用,之所以要設計一個jobsChannel和entryChannel,是為了解耦,entryChannel可以完全用做入口,jobsChannel可以做更深入的比如任務優先級,或者加鎖,解鎖等處理
代碼實現
原理清楚了,接下來我們來具體看代碼實現
首先我們來處理任務 task,task無非就是業務中的各種任務,需要能實力化,并且執行,代碼如下
- //定義任務Task類型,每一個任務Task都可以抽象成一個函數
- type Task struct{
- f func() error //一個task中必須包含一個具體的業務
- }
- //通過NewTask來創建一個Task
- func NewTask(arg_f func() error) *Task{
- t := Task{
- f:arg_f,
- }
- return &t
- }
- //Task也需要一個執行業務的方法
- func (t *Task) Execute(){
- t.f()//調用任務中已經綁定好的業務方法
- }
接下來我們來定義協程池
- //定義池類型
- type Pool struct{
- EntryChannel chan *Task
- WorkerNum int
- JobsChanel chan *Task
- }
- //創建一個協程池
- func NewPool(cap int) *Pool{
- p := Pool{
- EntryChannel: make(chan *Task),
- JobsChanel: make(chan *Task),
- WorkerNum: cap,
- }
- return &p
- }
協程池需要創建worker,然后不斷的從JobsChannel內部任務隊列中拿任務開始工作
- //協程池創建worker并開始工作
- func (p *Pool) worker(workerId int){
- //worker不斷的從JobsChannel內部任務隊列中拿任務
- for task := range p.JobsChanel{
- task.Execute()
- fmt.Println("workerId",workerId,"執行任務成功")
- }
- }
- EntryChannel獲取Task任務
- func (p *Pool) ReceiveTask(t *Task){
- p.EntryChannel <- t
- }
- //讓協程池開始工作
- func (p *Pool) Run(){
- //1:首先根據協程池的worker數量限定,開啟固定數量的worker
- for i:=0; i<p.WorkerNum; i++{
- go p.worker(i)
- }
- //2:從EntryChannel協程出入口取外部傳遞過來的任務
- //并將任務送進JobsChannel中
- for task := range p.EntryChannel{
- p.JobsChanel <- task
- }
- //3:執行完畢需要關閉JobsChannel和EntryChannel
- close(p.JobsChanel)
- close(p.EntryChannel)
- }
然后我們看在main函數中
- //創建一個task
- t:= NewTask(func() error{
- fmt.Println(time.Now())
- return nil
- })
- //創建一個協程池,最大開啟5個協程worker
- p:= NewPool(3)
- //開啟一個協程,不斷的向Pool輸送打印一條時間的task任務
- go func(){
- for {
- p.ReceiveTask(t)//把任務推向EntryChannel
- }
- }()
- //啟動協程池p
- p.Run()
基于上述方法,咱們一個簡單的協程池設計就完成了,當然在實際生產環境中這樣做還是不夠的,不過這些方法能手寫出來,那對golang是相當熟悉了,


 分享到微信
分享到微信  分享到微博
分享到微博














