詳解新一代數據湖--數據平臺
譯文【51CTO.com快譯】一提到企業數據平臺,人們往往想到的是各種數據目錄結構、數據質量監控、CI/CD、以及數據民主公眾化(Data Democratization,即:提供數據查詢的公共渠道)等方面。它們在滿足用戶的多元化需求與體驗的同時,不斷通過合理的架構、以及高效的分揀手段,來持續提高其自身的質量和使用價值。不過,我們在數據獲取、過濾、以及分析環節,往往會受到因素的限制:
- 團隊成員的知識儲備。
- 在云服務中的使用效率。
- 與現有業務和產品的集成度。
- 總體處置的成本。
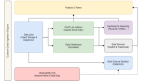
自定義的數據獲取引擎
基于上述考慮,企業在搭建與集成數據平臺時,往往會以開源技術作為平臺的核心,以流式和批處理的方式提供數據服務,并試圖將數據服務層與數據持久化引擎進行解耦。當然,他們也可以一股腦地將這些任務交給諸如:BigQuery、Redshift、以及Snowflake等增值服務提供商、及其特定產品來實現。
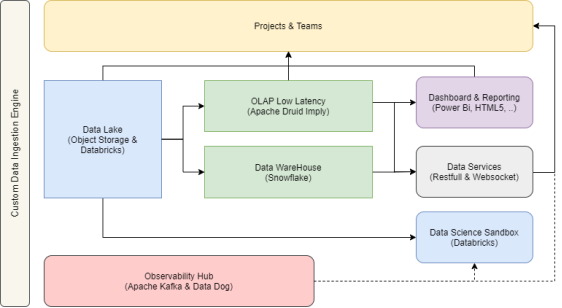
數據平臺架構的示例
數據模型(域驅動設計)
說到數據平臺,它往往需要全局性的數據模型定義。目前,許多企業、特別是一些技術類型的公司,都會采用域驅動設計(Domain Driven Design,DDD)的方法。該方法通常會涉及到如下方面:
- 生產者(producers)和消費者(consumers)。其中,消費者域是由來自多個生產者域的數據組合而成。
- 特定的數據可以擁有一個主域和一個輔域。
- 數據域的組織結構并非一成不變,可能會出現更改、合并、演化、以及移除。
在數據域處置方面,我們常用的方法是遵循自底向上的設計原則。這意味著:從生產者的數據域開始,數據產品將被視為自己的消費者進行構建。因此,數據平臺需要為它們提供所有必要的工具、服務、支持、標準化流程、以及集成。
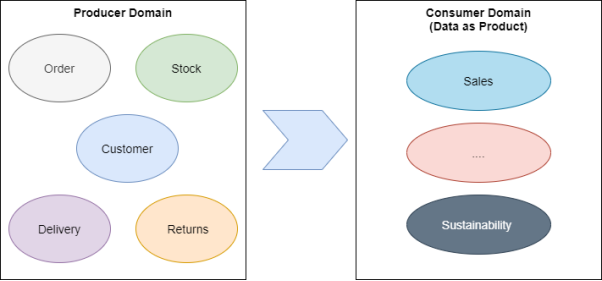
從生產者域到消費者域(數據即產品)
銷售域是消費者數據域的一個極其常見的例子,當然也是非常復雜的。在那些擁有多渠道訂單(如:電子商務、社交媒體、實體店等)的大公司中,渠道和部門之間有關銷售的概念雖然略有不同,但是它往往是由那些來自多個域的數據所組成。
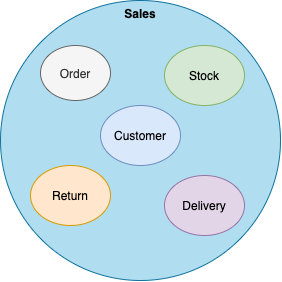
銷售域
例如:由于每個團隊所需要的數據、數據的驗證過程、以及衡量指標有所不同,因此電商部門和財務部門的銷售數據產品就可能不一樣。如果您對該專題感興趣的話,請參閱有關Data Mesh范例的文章。
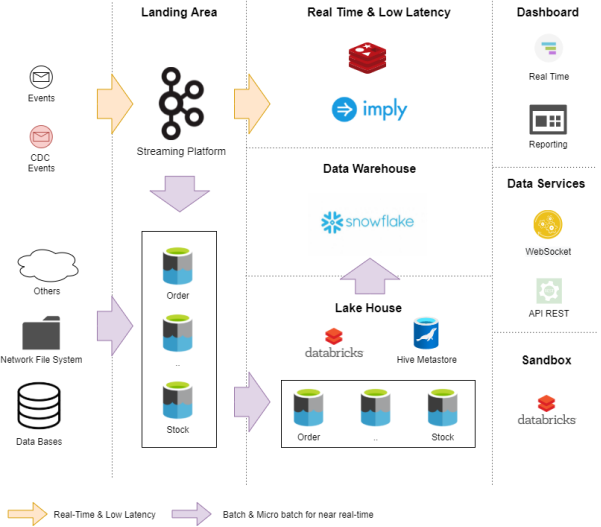
數據的獲取模式
眾所周知,數據平臺最具價值的資源便是數據。同時,數據也是最為復雜的。我們通常有兩種上傳數據的方式:
- 拉式(Pull):核心團隊基于集中式的管理,通過開發數據管道,將數據引入平臺中。不過,由于最初鮮少有與其他團隊的依賴關系,因此該方法比較有效;但是到了后期,則可能陷入瓶頸。
- 推式(Push):它對于運營、架構和范式來說是絕好的方法,但不一定適合其他團隊。例如,分銷團隊在分析銷售數據時,需要銷售團隊將他們的數據推送到數據平臺中。而由于銷售團隊業務繁忙,而且這并不是他們的首要任務,因此分銷團隊可能會等待較長的時間。
可見,“推式”方法雖好,但是許多公司往往有著各種遺留下來的系統,以至于團隊無法及時準備好適合推送的數據。而通過提供“拉式”方法,我們則可以開發自動化的數據獲取引擎服務。
什么是數據獲取引擎服務(Data Ingestion Engine Service)?
總的說來,它是一個無需代碼,只需各種SQL語句和映射,即可創建ETL流程和數據流程的自助服務平臺。其目標是通過提供多種風格,來涵蓋如下方面:
- 允許團隊自行將數據推送到交換區。
- 提供一個集中式的核心團隊,為非技術團隊上傳數據。
- 通過提供自助服務平臺,來簡化技術團隊的數據獲取過程。
如果我們對所有類型的數據獲取管道,都采取相同的方法,將會擁有一整套自動化的連接器,可方便團隊推送他們的各種數據。例如:變更數據的捕獲,各類事件、鏡像、以及文件等。也就是說,通過為產品所有者構建可用于數據推送的通用組件,我們將能夠實現自動化的獲取層。
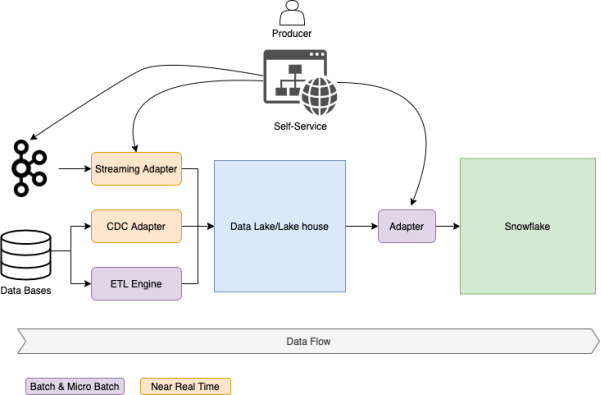
批處理的數據流
如上圖所示,我們必須提供各種工具和標準化的流程(包括:數據獲取與質量控制等),以允許生產者將他們的數據,通過Web門戶或GitOps等自動化的方式,推送到數據平臺上。
下面,我們將重點討論如何開發一個獲取引擎。
微服務架構之推送
事件驅動型的微服務架構,是被應用到基于數據流的“推送策略(Push Strategy)”的最佳場景之一。此類架構通常是基于諸如Apache Kafka等持久性的消息傳遞系統,并遵循的是“發布-訂閱(publish-subscribe)”的通信模式。
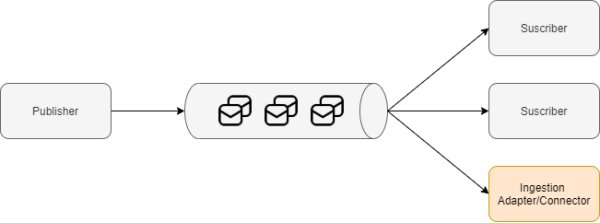
微服務架構模式
如上圖所示,這種模式提供了一種可擴展的、松散耦合的架構,即:
- 發布者向主題(topic)發送一條消息。
- 所有已注冊該主題的訂閱者都會收到此消息,也就實現了:事件被一次產生,多次消費的效果。
- 由于發布者和訂閱者之間并無依賴關系,因此他們的操作可以彼此獨立。
我們可以通過提供標準化的獲取連接器,來訂閱此類主題,并將各種事件以近乎實時的方式,獲取到我們的數據平臺。當然,此類架構在信息范圍方面會存在著如下缺陷:
- 由于持久性主題通常具有基于時間或大小的限制,因此在出現錯誤時,其重新處理的過程較為復雜。
- 不具備重新發送歷史數據的流程。
- 不提供針對各種海量場景的異步數據質量性API。
數據湖(Data Lake)
在存儲與分析原始數據,以及機器學習環境中,也就產生了數據湖的概念。它是一種基于對象存儲的數據存儲庫,能夠方便我們進行如下存儲:
- 來自關系型數據庫的結構化數據。
- 來自NoSQL或其他來源(如:CSV、XML、JSON等)的半結構化數據。
- 非結構化數據和二進制數據(如:文檔、視頻、圖像等)。
目前,云存儲服務既能夠為頻繁調用的數據提供高性能與低延遲的處理能力,又能夠為非頻繁調用的數據提供低成本的大容量存儲空間。因此,我們可以通過選用Azure Data Lake Storage Gen2,來為云對象的存儲提供如下功能:
- 卷:可以管理海量數據、PB級信息、以及千兆位(gigabits)的吞吐量。
- 性能:針對各種待分析的用例進行優化。
- 安全性:允許對目錄或單個文件設置POSIX(可移植操作系統接口,Portable Operating System Interface)權限。即:使用服務主體和OAuth2.0,將Azure Data Lake Storage Gen2的文件系統掛載到DBFS(數據庫文件系統)上。
- 事件:作為一種服務,可以為每個執行操作(如:創建和刪除文件)自動生成一個事件。通過這些事件,我們可以設計事件驅動的數據流程。
我們需要根據用戶的實際需求和用例做到:
- 提供對于數據的只讀訪問權限,以便讓數據湖成為所有用戶的數據來源,以及單一的數據存儲庫。
- 結構化數據和半結構化數據能夠通過諸如Delta Lake的存儲庫,以列的格式存儲。
- 讓數據能夠按照業務域進行分區存儲,并分布在多個對象存儲中。
- 提供Hive的Metastore服務,并通過使用各種外部表提供spark-SQL的訪問。這將允許用戶從數據的物理位置中抽象出來,并擁有數據的單獨鏡像。

Spark-SQL流經MariaDB
如上圖所示,我們可以使用外部開源版本的Hive Metastore,而非具有集成限制的供應商管理服務,來自由地集成任何Spark平臺環境(如:Databricks、Cloudera等)。
Spark-SQL和HiveMetastore
Spark-SQL為我們提供了一個分布式的查詢引擎,以方便我們以更為優化的方式使用結構化與半結構化數據,并使用類似于數據目錄的Hive Metastore。通過SQL,我們可以從如下位置查詢到數據:
- 數據幀和數據集API。
- 外部工具,如Databricks Notebooks便是一個用戶友好的工具。它能夠協助非技術用戶去消費數據。
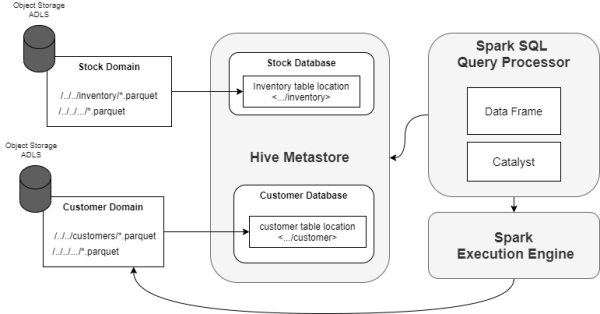
Spark-SQL和HiveMetastore的流程
數據湖即服務(Data Lake as a Service)
基于上述理論與知識基礎,我們可以設計和構建出具有如下特征的數據湖平臺:
- 其數據獲取引擎負責獲取數據,創建和管理在Hive Metastore的元數據。
- 其核心是由對象存儲層和Hive Metastore兩個主要組件構成,它們提供了計算層即服務(compute layer as a service)。
- 其中的計算層是由集成到數據湖中的多個Sparks群集組成。它們通過各種Spark作業、SQLAnalytics或Databrick Notebook來訪問數據。
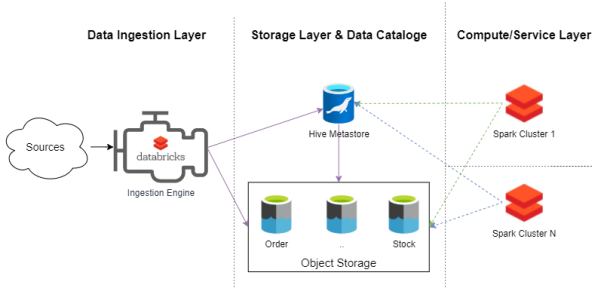
數據湖即服務的架構
數據湖平臺即服務是一種動態且可擴展的計算與服務層能力。其中,作為核心的Spark集群是數據湖平臺的最小服務目錄。我們既可以創建一個7x24的永久性集群,又可以創建一個臨時的工作集群。例如,若想為數據產品團隊提供沙盒分析服務,我們可以為每個成員都創建一個包含有相同數據,但彼此隔離的計算環境。對此,我們需要實現:
- 根據Spark技術,來定義組成沙箱分析的組件。
- 通過Web服務目錄、或代碼方式(如git-ops),提供自助式的服務功能。
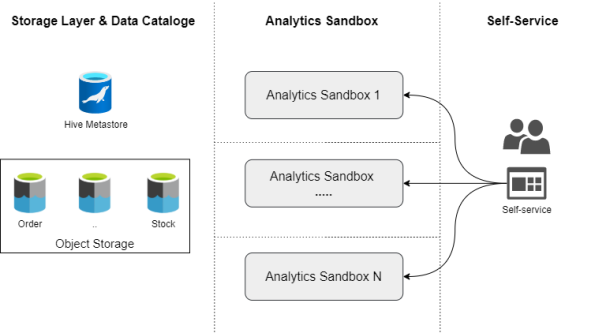
自助式的服務層
當然,上圖只是一個非常簡單化的視圖,其中并沒有定義安全性、高可用性、以及數據質量的相關服務。
數據湖能夠提供什么?
如下圖所示,作為一個開源層,數據湖提供了ACID功能,并確保用戶能夠看到一致性的數據。各種數據管道可以被用來刷新數據,但不會影響正在運行中的Spark過程。
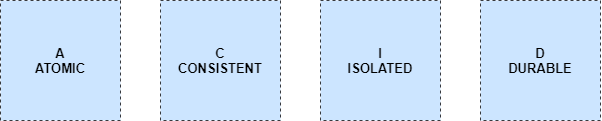
ACID:原子性、一致性、隔離性、持久性
其他重要的功能還包括:
- Schemaon-write:它在寫入數據時強制執行模式檢查,如果檢測到模式不匹配,則返回作業失敗。
- SchemaEvolution:它支持諸如添加新的列等,針對兼容性方案的模式進化。
- Time travel:數據版本控制可方便我們將數據作為代碼進行管理。在代碼存儲庫中,用戶能夠讓數據集的每次更改,都會在其整個生命周期中生成新的數據版本。
- Merge:支持合并、更新和刪除操作,以實現復雜的數據獲取場景。
數據湖的進化
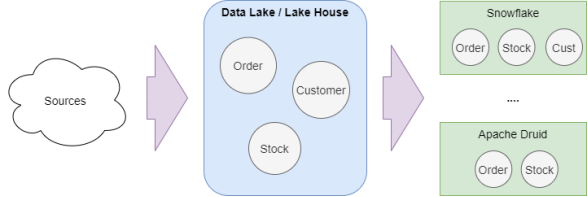
如下圖所示,傳統的數據湖、數據倉庫、以及數據中心(Hub)之間有著概念性和技術性的區別。

數據湖、數據中心、數據倉庫圖表
Apache Hudi為傳統的、基于Hadoop、Spark、Parquet、Hive等數據湖技術生態,添加了新的實用功能。其中包括:將計算和存儲層進行架構上的解耦、無服務器化、SQL分析、Delta Engine、以及Databricks等新一代的數據湖平臺。而根據Databricks的理論,Lake House可以被理解為新一代、更為成熟的數據湖。它包含了如下兩個部分:
數據中心流程圖
- 用于特定或簡化場景的數據倉庫
數據倉庫流程圖
目前,隨著數據倉庫的能力得到了大幅提升,諸如Snowflake、Bigquery、以及Oracle Autonomous Data Warehouse等技術產品,在數據分發等方面都表現出了不俗的性能。
小結
總的說來,結合了Kafka等事件中心的新一代數據湖,是我們構建數據平臺核心的優先選擇。它作為一項成熟的技術,不但開源、持續進化,而且具有極具競爭力的性價比。我們可以將其部署到各種云端服務環境中,以更好地發掘數據的價值。
原文標題:Data Platform: The New Generation Data Lakes,作者:Miguel Garcia和Albert Palau
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】