聊聊圍繞HugeTLB的創新優化
內容簡介
介紹以一種創新的方式優化HugeTLB對應的struct page內存占用。
相信大家對HugeTLB在虛擬化及DPDK等場景應用并不陌生,在動不動就上百GB的服務器上,輕輕松松預留上百GB HugeTLB。相信不少云廠商也注意到HugeTLB的內存管理上存在一定的問題。既然有問題,為何upstream上遲遲看不到相關的優化patch呢?
答案很簡單:問題棘手。
Linux在內存管理方面已經發展了十幾年,即使某些機制不夠優秀,想大改也不是簡單的事情。內存管理貫徹整個Linux內核,與眾多子系統交互。究竟Linux在HugeTLB的管理上存在什么問題呢?
如何管理物理內存
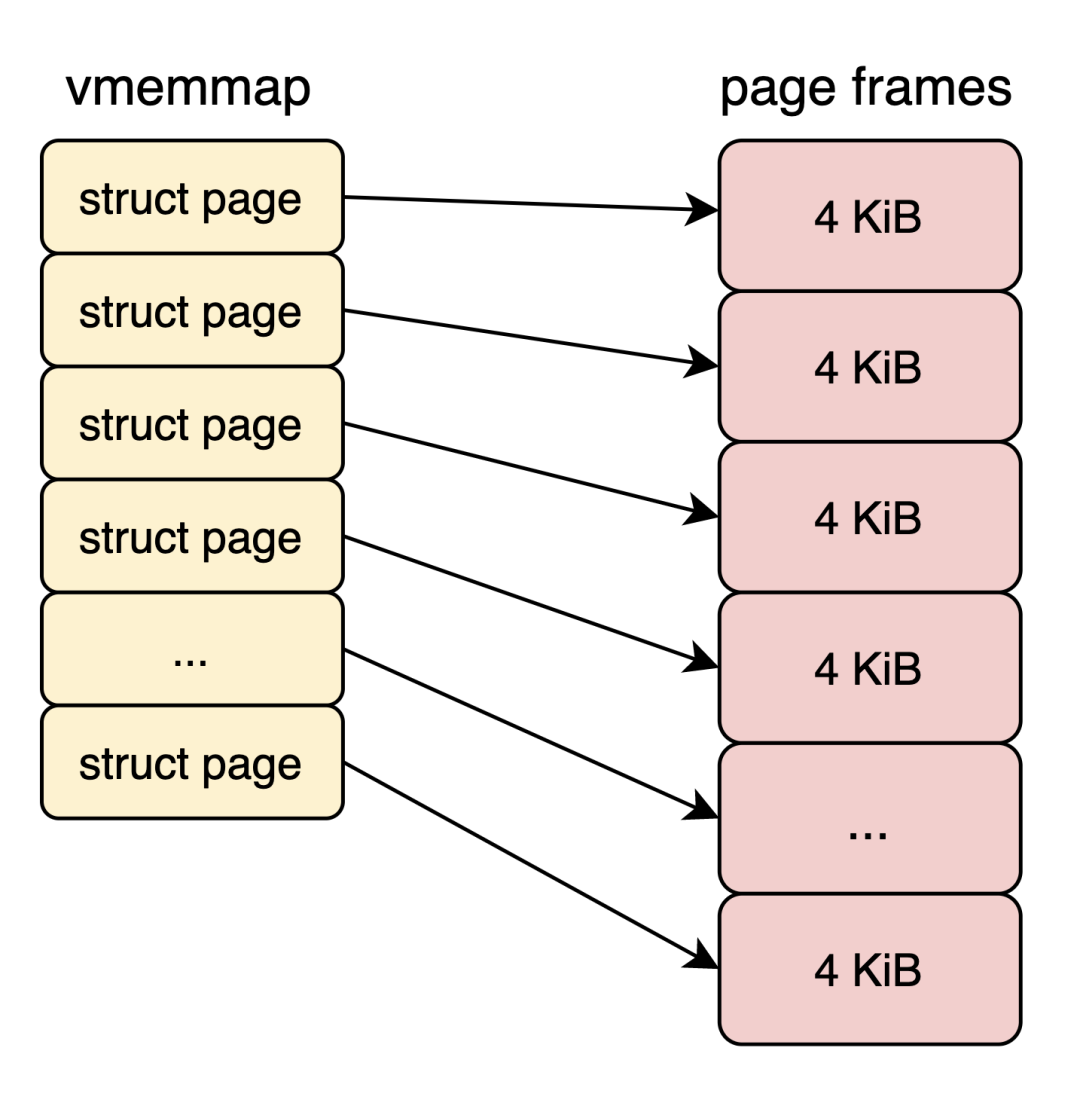
現在Linux Kernel主要以頁為單位管理內存,而頁的大小默認4 KB。為了方便管理物理內存,Linux為每個頁分配一個metadata結構體,即struct page結構,其大小通常64 Bytes。struct page可以簡單理解成一個數組,數組的index就是PFN(物理頁幀號)。我稱這段區域vmemmap。
圖片4KB頁我們稱之為小頁,與之相反的是大頁。在x86-64平臺,硬件支持2 MB和1 GB大頁。Linux為了方便用戶使用大頁,提供2種不同的機制,分別是THP (Transparent Huge Page) 和 HugeTLB。HugeTLB經常出現在我們的工程實踐中,HugeTLB為我們為我們帶來不錯的性能提升。
但是也有一朵烏云常伴其身。雖然2 MB的HugeTLB page理論上也只需要1個struct page結構,但是,在系統啟動之初,所有的物理內存均以4 KB為單位分配struct page結構。因此每個 HugeTLB page對應 512個struct page結構,占用內存32 KB(折合8個4 KB小頁)。
可能你會好奇這能有多少內存。針對嵌入式系統,確實不值一提。但是別忘了,我們有動不動就2 TB物理內存的服務器。
現在我們可以簡單的算一筆賬了。假設在一臺1 TB的服務器上,我們分配1 TB的2 MB大頁(理想情況下),那么struct page本身占用的內存是多少呢?沒錯,是16 GB。如果有上千臺,上萬臺,甚至上十萬臺機器呢?如果我們能夠優化掉16 GB的內存浪費或者盡可能的降低struct page的內存占用,我們將會降低服務器平臺成本。我們的目標就是盡量驅散這朵烏云。
面臨的挑戰
我們試圖找到一種最簡單并且對其他模塊影響最小的設計方案,在這過程中我們遇到不少挑戰。
1. 不需要用戶適配
理想情況下,我們的優化不應該涉及用戶態的適配。如果引入一種全新的內存管理方式,所有的用戶需要適配。我們的目標是開箱即用。
2. 不影響內核其他模塊功能
在確定不需要用戶適配的前提下,我們預期所有的代碼修改只會集中于內核。我們知道內存管理的幾乎全是圍繞著struct page管理,各個不同子系統的模塊幾乎都和struct page息息相關。暴力的釋放所有的HugeTLB相關的struct page結構體是不合適的,否則將會影響內核各個內存子系統。既要釋放,但又不能釋放。這恐怕是最棘手和矛盾的問題了。
3. 代碼修改最小化
代碼量間接的決定了bug的數量。內存管理子系統修改代碼過多,勢必影響內核的穩定性。我們既要實現功能,又要以最少的代碼量實現。這不但可以降低bug出現的概率,同時也易于維護和理解。
初次探索
圖片
一種最簡單直接的方法浮出水面。那就是動態分配和釋放struct page。
HugeTLB的使用方法一般是先預留后使用。并且struct page只會被內核代碼訪問,我們傾向內核訪問struct page的概率較低。因此我們第一次提出的方案是壓縮解壓縮的方法。
我們知道HugeTLB對應的512個struct page對應的信息可以壓縮到 100 個字節左右,因此我們可以為每個HugeTLB準備一個全新的metadata結構體,然后將所有的信息壓縮到新的metadata結構體。并且將struct page區域對應的頁表的present清除,然后就可以將其對應的物理頁釋放。是不是和zram機制如出一轍?
內核在下次訪問HugeTLB的struct page的時候觸發page fault,在fault里面分配struct page需要的物理頁,并解壓縮(從新的metadata結構體恢復數據)。
當內核使用完成后,會執行put_page操作。我們在put_page里面做壓縮操作,并釋放vmemmap對應的物理頁。思路很直接,但是這里面存在很多挑戰。
1. page fault里面無法分配怎么辦(例如:OOM)?
2. page fault可能發生在任何上下文,用GFP_NOWAIT分配內存?這只會加重第一個問題。
3. 如果某一持有A鎖的路徑觸發page fault,page fault里面也嘗試持有A鎖怎么樣?只會死鎖。所以page fault的操作需要格外小心。
4. 壓縮和解壓縮操作如何做到原子?或者說壓縮操作如何和解壓縮操作互斥同步?
5. 每次put_page都需要壓縮操作,性能影響如何?
6. 如果某些內核路徑并沒有get操作訪問struct page(自然也不會put),壓縮的時機會是什么時候?
我們列出了很多問題,但就第一個問題來說就很難解決。這不得不讓我們放棄了這個想法。我們只能另尋他路。換個思路或許柳暗花明。
另辟蹊徑
俗話說“知己知彼百戰不殆”。我們先詳細了解struct page是如何組織和管理的,清楚每一處細節,才可能運籌帷幄。
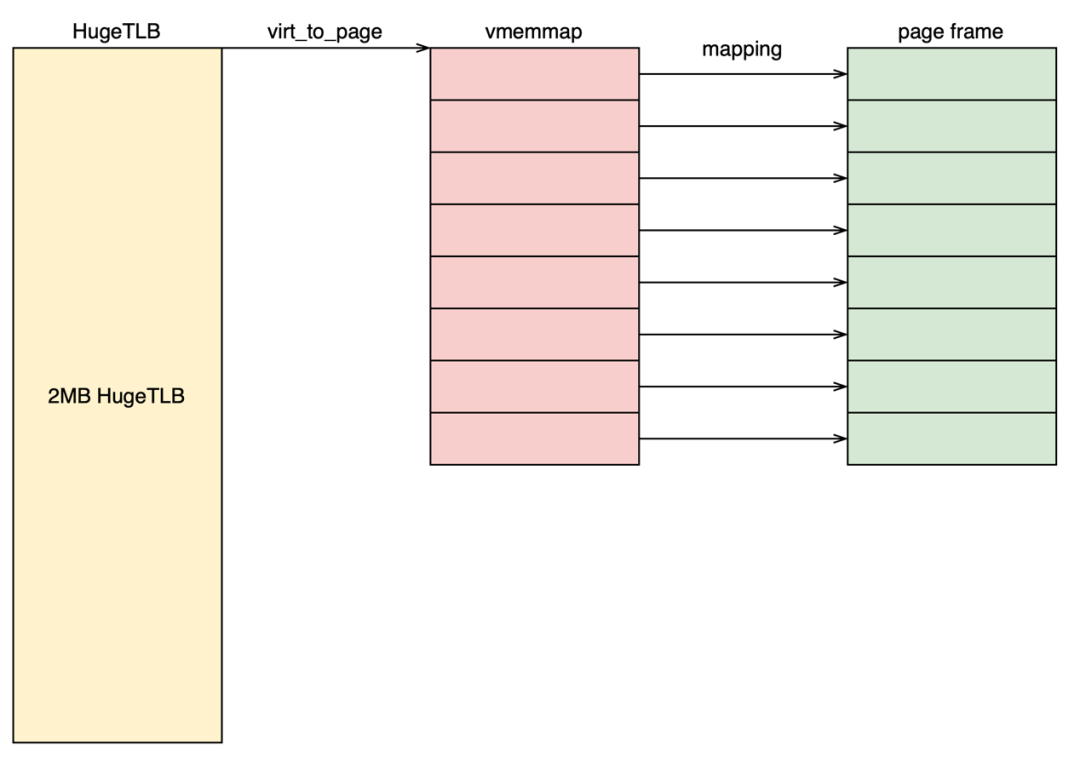
我們上面提到每個HugeTLB page對應512個struct page結構,而HugeTLB只使用前3個struct page結構存儲大頁相關的metadata。那么其余509個struct page是否完全沒有意義呢?如果沒有意義我們是不是就可以直接釋放這些內存。
然而事情并沒有那么簡單。這些509個struct page會存儲第一個struct page的地址(struct page中compound_head字段)。如果第一個struct page稱之為head page的話,那么其余的struct page都是tail page。在Linux內核的內存管理的代碼中充斥著大量的代碼,這些代碼都可能試圖從tail page獲取head page。所以我們并不能單純的釋放這些內存。
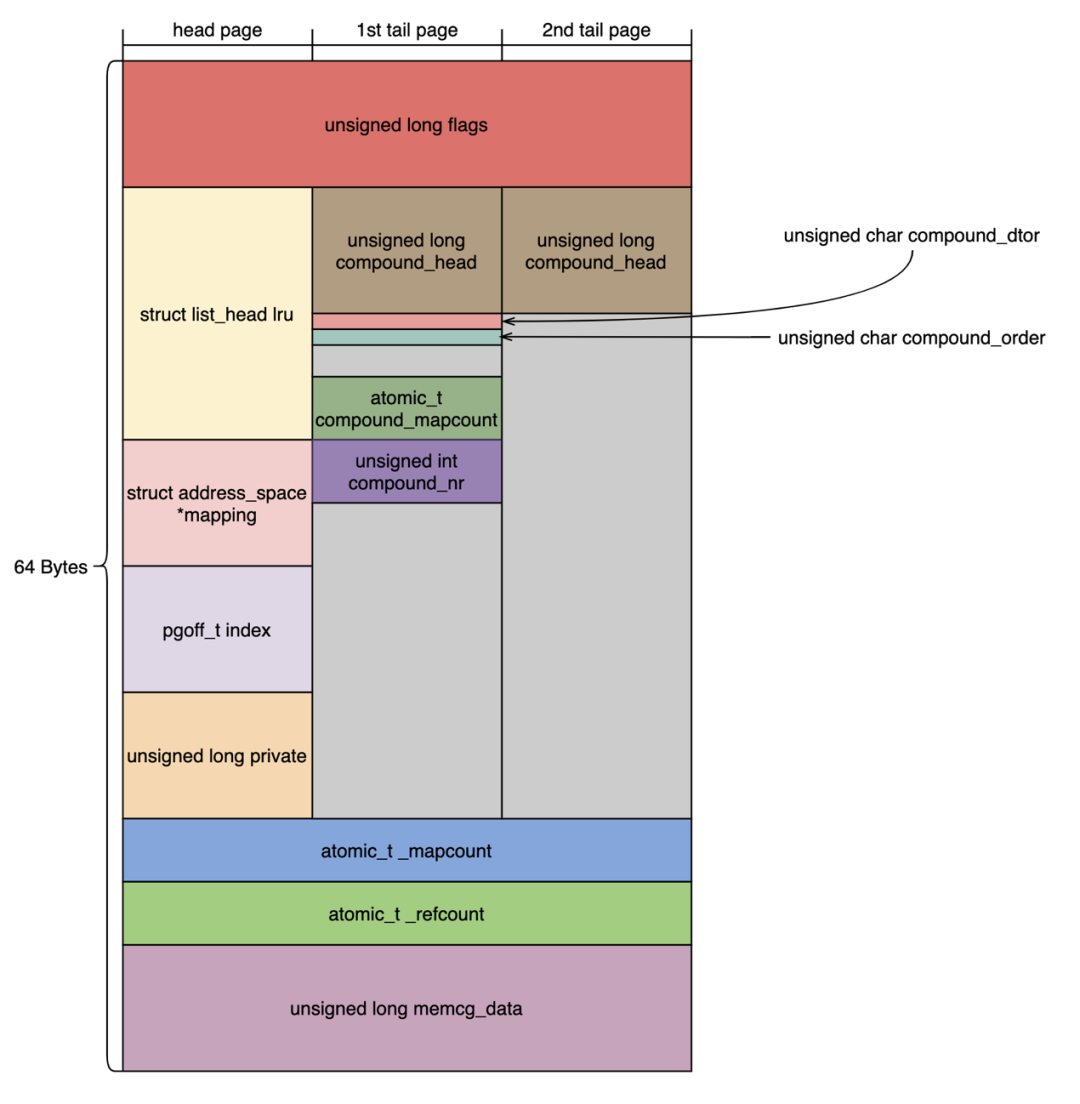
上圖展示的3個struct page的結構體示意圖(第3個tail page至第511個struct page結構體使用的位域同圖中2nd tail page)。我們可以總結出以下特點:
1. struct page結構體的大小在大多數情況下是64字節,因此每個4 KB的物理頁可以存儲整數個數的struct page結構體。
2. 第2個tail page至第511個struct page結構體的內容完全一樣。
3. 內存管理的代碼中只會修改head page,1st tail page的2nd tail page的結構體,其余的tail page結構體內存不會修改。
4. 每個2MB HugeTLB page對應512個struct page,內存占用8個頁(4KB * 8)。
5. struct page所在的vmemmap區域和內核的線性映射地址不重合。
基于以上特點,我們可以提出全新的解決方案:共享映射,將HugeTLB對應的后7個頁的vmemmap虛擬地址映射到第1個vmemmap頁對應的物理頁幀。第1-2點是共享映射方案的基礎。基于第3點我們可以將這7個物理頁釋放,交給buddy系統管理。而第5點是buddy能夠管理這塊物理內存的基礎。內核通過線性地址訪問物理內存,所以這個地址不能和vmemmap共用。其原理如下圖所示。基于第3點,我們將共享映射屬性改成只讀,防止出現異常情況。
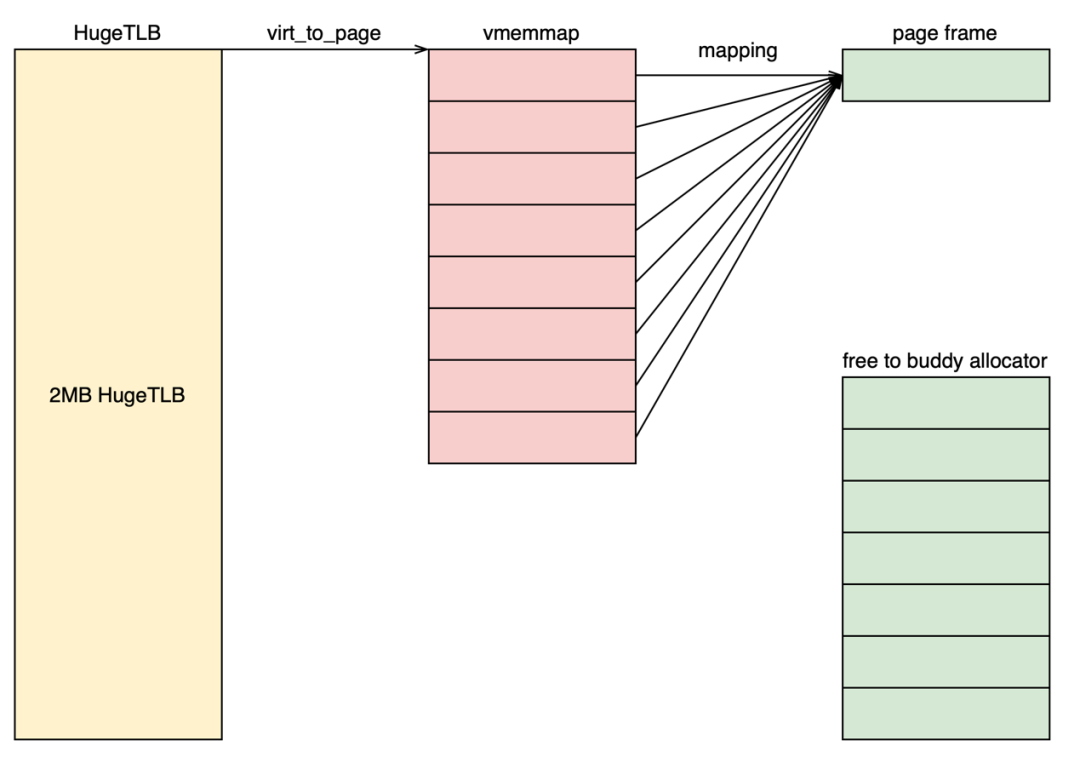
內存收益
經過上面的優化,我們成功的降低了服務器平臺成本,并且收益不錯。針對1 GB和2 MB不同size的HugeTLB page,內存收益也同樣不同。簡單歸納表格如下:
|
Total Size of HugeTLB Page |
HugeTLB Type |
Memory Gain |
|
512 GB |
1 GB |
~8 GB |
|
1024 GB |
1 GB |
~16 GB |
|
512 GB |
2 MB |
~7 GB |
|
1024 GB |
2 MB |
~14 GB |
如果使用1 GB HugeTLB,內存收益約為HugeTLB總量的1.6%。如果使用2 MB HugeTLB,內存收益約為HugeTLB總量的1.4%。
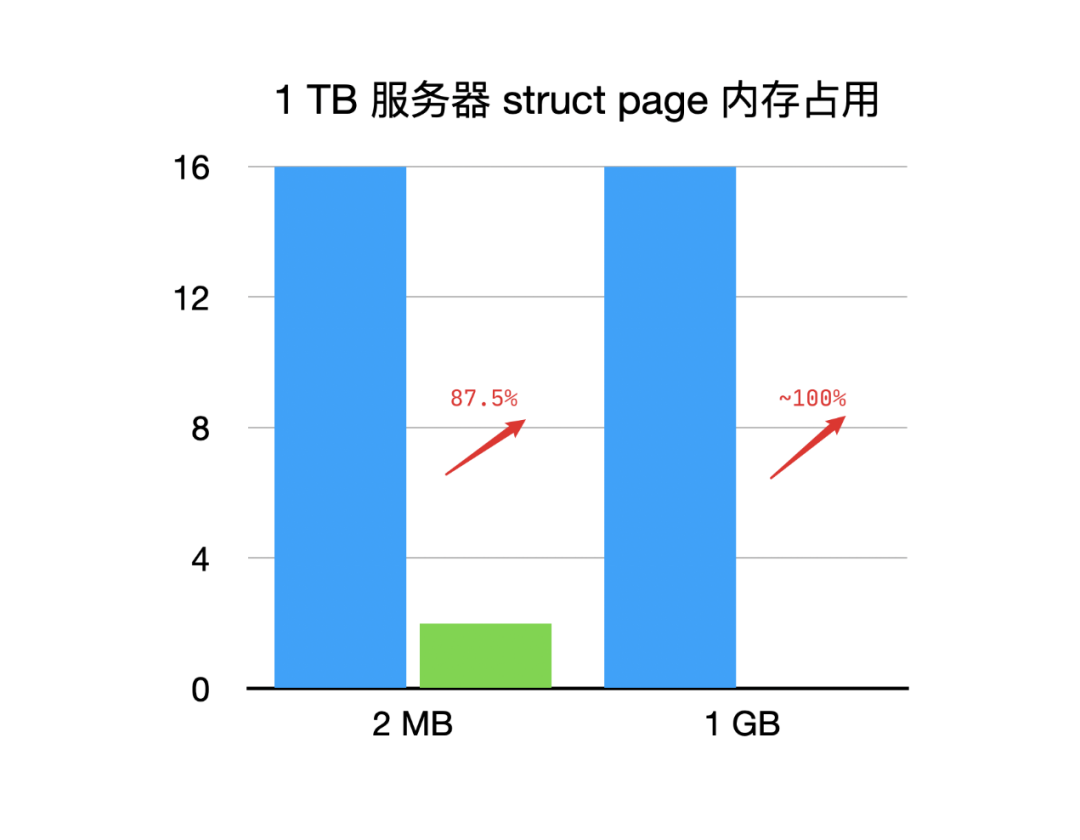
因此,在我們1臺1 TB內存的服務器上,如果使用1 GB大頁,struct page內存占用優化提升接近100%。如果使用2MB大頁,struct page內存占用優化提升約87.5%。
性能分析
我們知道vmemmap區域映射的單位是2 MB。但是我們需要以4 KB頁為單位修改頁表,因此必須修改vmemmap區域為小頁映射。這相當于在內核訪問vmemmap區域時,MMU會多訪問一級 PTE 頁表。但是有TLB的存在,所以查找的性能損失并不大。
但是我們同樣也有性能提升的地方,由于我們減少了vmemmap對應的物理頁。理論上來說,我們更容易命中cache。實際上也確實這樣,經過upstream的測試數據顯示,對HugeTLB page進行get_user_page操作性能可以提升接近 4 倍。
開源計劃

為了降低代碼review的難度,我們決定將全部patch拆分成3筆patchset。目前第一步基礎功能已經合入linux-next分支(代碼參考: [v23,0/9] Free some vmemmap pages of HugeTLB page,點擊文末左下角閱讀原文可達),不出意外的話,預計Linux 5.14會和大家見面。
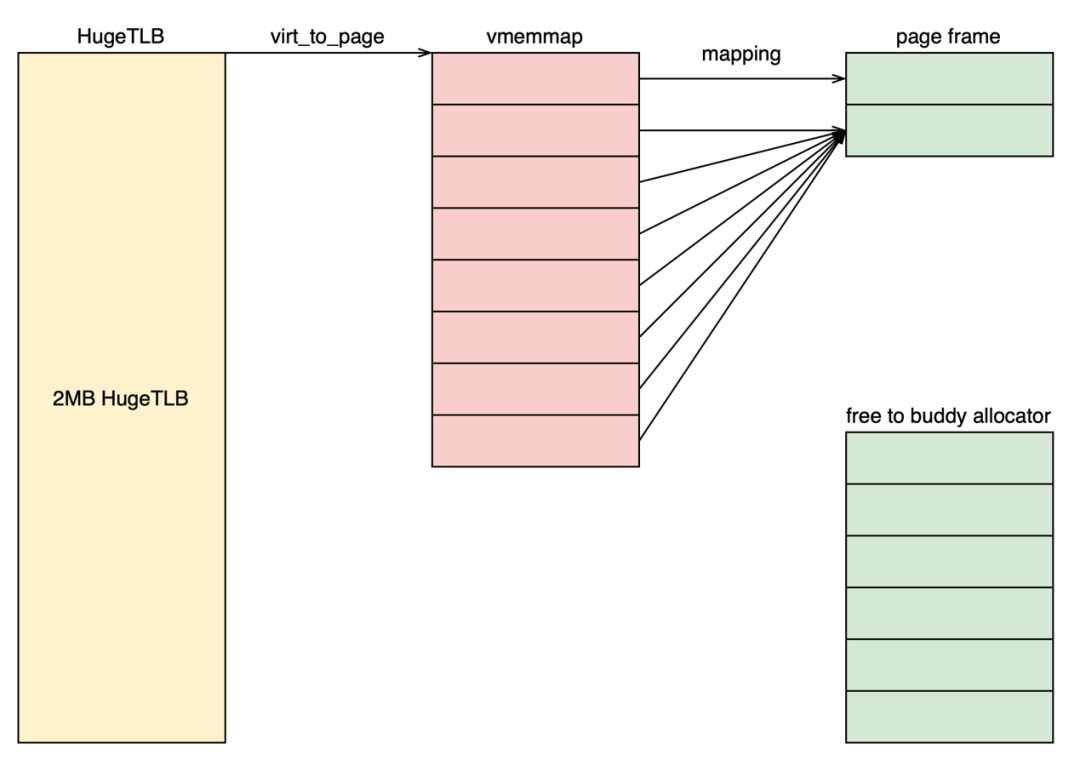
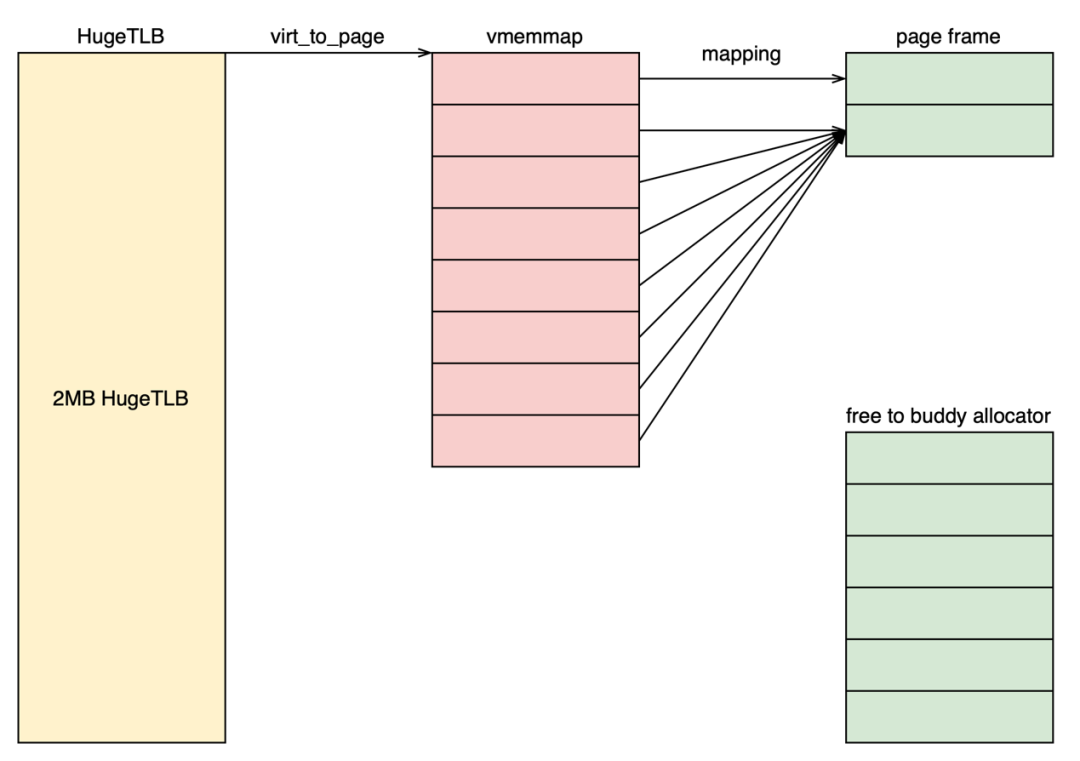
后續我們繼續放出接下來的patchset。那么接下來有哪些功能呢?
首先第一個功能是釋放7個page。什么?這不是上面已經說的功能嗎?是的,但是我們的第一個patchset只釋放了6個page。所以在上面的patchset中,我們建立的映射關系其實如下圖所示。這才是最簡單的情況。因為我們head page和tail page的結構體內容其實是不一樣的,如果要實現上面的圖的映射關系,必然要有一些trick才行。另一組patchset是拆分vmemmap頁表。第一組patchset的實現并不包含拆分vmemmap頁表,而是系統啟動時使vmemmap頁表以PTE方式建立映射,而非PMD映射。
作者簡介
宋牧春,字節跳動系統技術與工程團隊,Linux內核工程師。
本文轉載自微信公眾號「Linux閱碼場」,可以通過以下二維碼關注。轉載本文請聯系Linux閱碼場公眾號。