全方位支持圖文和音視頻、100+增強功能,Facebook開源數據增強庫
最近,Facebook 開源了一個新的 Python 庫——AugLy,該庫旨在幫助 AI 研究人員使用數據增強來評估和改進機器學習模型的可用性。AugLy 提供了復雜的數據增強工具,可以創建樣本來訓練和測試不同的系統。
項目地址:https://github.com/facebookresearch/AugLy
該庫基于 Facebook 和 Instagram 等平臺上的真實圖片和視頻提供了 100 多種數據增強功能,因此對于處理與社交媒體應用程序相關的模型或數據的研究工作特別有用。
目前 AugLy 支持四個模態:文本、圖像、音頻和視頻。使用真實世界的數據進行數據增強能夠幫助機器更好地理解復雜的任務。以文本短語「love the way you smell today」為例,該文本想要表達的意思是喜歡,但是將此短語應用到臭鼬的圖片上時,想要表達的意思全部變了。AugLy 更類似于人們為了了解周圍的世界而從多種感官獲取信息的方式。隨著數據集和模型變得越來越具有多模態,在一個統一的庫和 API 下轉換項目的所有數據是非常有必要的。
對于該數據增強庫,機器學習界的大佬 Yann LeCun 也轉推推薦。
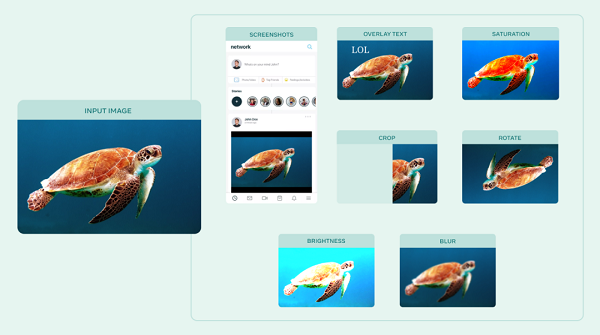
AugLy 如何工作
AugLy 包含四個子庫,每個子庫對應不同的模態,每個庫遵循相同的接口:AugLy 提供了基于函數和類格式的轉換,并提供強度函數,幫助了解轉換的強度(基于給定參數)。AugLy 還可以生成有用的元數據,以幫助了解數據轉換過程。
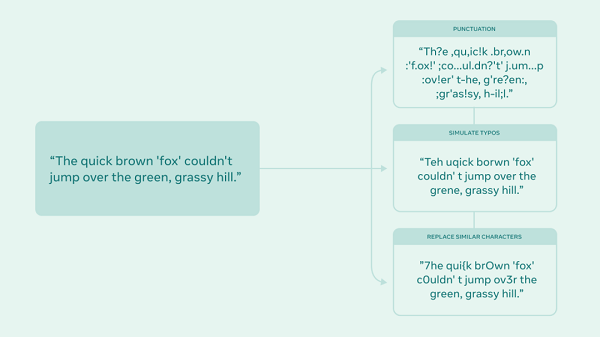
此外,該庫已經聚合了許多擴展,以及以前從未存在過的擴展。例如,增強功能將圖像或視頻疊加到社交媒體界面上,使其看起來像是用戶在 Facebook 等社交網絡上截屏的圖像或視頻,然后重新共享。這對于許多用例來說是一個有用的補充,因為 Facebook 上的用戶通常會以這種方式重新共享內容。
AugLy 為何如此重要
數據增強對于確保 AI 模型的魯棒性至關重要。如果可以教會模型對數據中不重要的屬性擾動具有魯棒性,那么模型將學會關注特定用例中數據的重要屬性。
在 Facebook 中,一個重要的應用程序是檢測特定內容的「相似副本」。例如,同一條信息可能以不同的形式重復出現。又例如圖像經過修改后被裁剪了幾個像素,或者用過濾器或新的文本覆蓋進行了增強。通過使用 AugLy 數據增強 AI 模型,它們可以在上傳已知侵權內容 (如歌曲或視頻) 時識別出來。
使用 AugLy 訓練模型來檢測相似內容意味著我們可以主動阻止用戶上傳已知侵權的內容。例如 SimSearchNet,一個基于卷積神經網絡的模型,可以專門用來檢測精確復制內容,該模型是用 AugLy 增強訓練的。
除了使用 AugLy 訓練模型外,該庫還可用于確定模型相對于一組增強的魯棒性。事實上,AugLy 已經被用來評估 deepfake 檢測模型在「Deepfake 檢測挑戰賽」(Deepfake Detection Challenge)中的魯棒性,最終影響了前五名獲勝者。
AugLy 支持圖像增強,如裁剪、填充圖像、截屏和重新共享照片。數據增強的用途是廣泛的,AugLy 可以幫助研究人員從事各種工作,從物體檢測模型到識別仇恨言論再到語音識別。