













從源頭解決 Service Mesh 問題最徹底!
我在 Shopee 維護一個 Service Mesh 系統,大部分的 RPC 調用要經過這個系統,這個系統每分鐘要處理上千萬的請求。我們在本文中就把它叫做 Oitsi 系統吧,方便描述一些。干的事情其實和 Istio 是差不多的。
Oitsi 將對 RPC 調用設置了很多錯誤碼,類似于 HTTP 協議的 404, 502 等等。Application 報出來的錯誤碼在一個區間,Oitsi 內部產生的錯誤在另一個區間,比如 0-1000,類似于 System Internal Error,監控這些錯誤碼可以讓我們知道這個系統的運行情況。
這個系統自從接手之后就有一個問題,就是它每時每刻都在報出來很多內部錯誤,比如發生內部超時,路由信息找不到,等等,每分鐘有上萬個錯誤。然而,系統的運行是完全正常的。
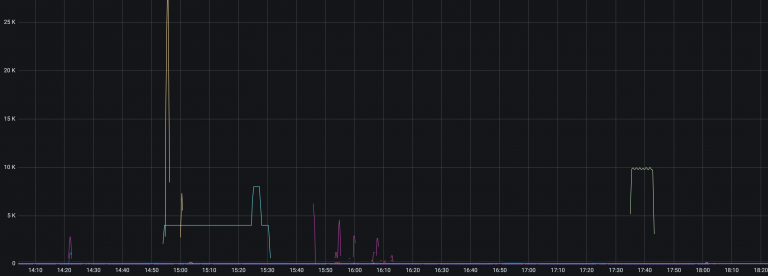
Oitsi 系統在正常情況下的錯誤
從這個脫敏之后的監控可以看到,經常有一些錯誤一下子動輒上萬,除了圖中幾 K 的那些錯誤,在 1K 以下有更多密集的錯誤,只不過它們都被其他巨量的錯誤給拉平了,在這張圖不明顯。
這就給我們造成了很多問題:到底是 Oitsi 真出了問題,還是屬于“正常的錯誤”?很難判斷,每次發生這種情況都費時費力。大部分情況都是排查一番,然后發現是用戶“濫用”造成的問題,不需要關心。而它又掩蓋了很多真實的問題,比如一個新的版本發布之后偶爾會有一些內部的錯誤,是不應該發生的,卻被真實的問題掩蓋住了。基于這樣的監控數據我們也無法設置告警,因為這些噪音太多了,即使有告警,也和沒有一樣。
這讓我想起之前在螞蟻的工作,我們有類似的問題。我有一年多的時間都在一個叫做“故障定位”的項目上。在螞蟻我們也有很多告警(99%的)都是無效的,給 On Call 的同事帶來很多噪音和打擾。在螞蟻的思路是:開發一個“智能系統”(AI Ops),當告警發生的時候,自動地判斷這個告警是不是噪音,是不是真正的問題,問題出在了哪里。拿到 Oitsi 的例子上說,當現在一個錯誤的數量突增,那么這個智能故障定位系統就去檢查 Oitsi 的一些指標是否正常,導致告警的服務具體是什么,它之前是不是一直有類似的監控曲線模式,如果有,說明它一直在發生,是正常的,我們可以不管。
這樣做了一年,效果還是不怎么樣。我倒是發現,很多告警的規則本身就有問題,比如一個請求量每分鐘只有兩位數的服務,領導的要求是 “1分鐘發現故障,5分鐘定位故障”,不要說自動定位,就算是人去判斷都不靠譜。為了達成這個目標,監控團隊設置了很多非常敏銳的告警,交給定位團隊說:“我們負責發現問題,你們負責定位問題。如果出問題了,1分鐘之內有告警觸發,那么我們的工作就達標了。但是至于沒有問題我們也觸發了很多噪音告警,就是你們的工作了。” 它們的 KPI 確實是完成了,只要有故障必定有告警。但事實是,在很多情況下,告警發出來,大家打開監控,盯著監控:“在等等看,看下一分鐘,有請求進來了,服務沒問題!”
所以這一年工作里,我有一個想法,就是在源頭解決問題比使用高級的魔法系統去解決問題要簡單、徹底很多。我們真的需要這么多人來開發一個“魔法系統”來幫我們診斷這種問題嗎?
比如監控配置的不對,那就優化監控。監控為什么配置的不對?監控系統太難用,UI 讓人捉摸不透,配置了告警無法調試,監控只能保存7天的數據,不能基于歷史的監控數據配置告警。很多人為了“規則”,對服務配上了告警然后就走了,至于后面告警觸發了,也不去響應。
回到 Oitsi 的問題上,我找了幾個服務,發現這些 Oitsi 內部錯誤上并不能完全說是“正常的錯誤”,畢竟它是錯誤,沒有錯誤會是正常的。只能說它沒有導致線上問題而已。它們是可以被修復的。于是一個月前,我決定從源頭去解決這些問題。把所有不應該報告出來的錯誤都消滅掉。
乍一看這么多錯誤數,用那么多團隊在用,看起來是難以管理的,性價比非常低的工作。但是畢竟也沒有人催我要快點完成,我可以一點一點去做。做一點錯誤就少一些(只要我解決問題的速度比新的問題出現的速度快)。
于是我按照下面的流程開始處理:
- 在 Jira(我們內部的工單系統)建立一個專題 tag,叫做 oitsi-abuse,后面的工單可以關聯這個 tag,這樣,可以在處理的時候方便參考之前的 Case;
- 創建一個監控,專門針對錯誤做一個面板,點擊面板右側的 Legend 可以直接跳到服務的監控面板,在服務的監控面板上顯示下游,并且關聯 CMDB 的 PIC(Person in charge);
- 這樣,我從錯誤數最高的服務開始,查看監控,看下游服務,以及機器上的日志,看相關的錯誤碼是什么時候開始的,到底是什么引起的,確定了是服務的問題就創建工單給這個服務的負責人,然后跟他聯系,說明這個有什么問題,會對我們的監控、告警造成什么影響,需要修復;
- 等他確認問題,然后要求提供一個 ETA(預計修復的時間),把 ETA 寫到工單中,到了時間去檢查確認;
- 如果是 Oitsi 本身的問題,去找 Oitsi 開發同事排查問題;
- 等所有的問題都解決了的話,對錯誤設置告警,一有錯誤就去聯系開發。一般情況下,都是他們做的配置變更或者發布引起了問題。這樣對于業務其實是更加健康的,我們發現問題的能力更強了。
就這樣,其實這樣坐下來就發現只有那么幾類問題,排查的速度越來越快。中間還發現一個庫,它會去對 Oitsi 服務做心跳檢查,這個檢查設置不當會有一些錯誤。很多引用了這個庫的應用都有一只在報錯誤的問題。但是我們系統本身其實已經做了探活可以保證心跳之類的問題了,溝通之后這個庫的心跳檢查行為可以下線。于是庫發布了新的版本,我找所有的引用者去升級版本,很多錯誤一下子就消失了,非常有成就感。
這項工作的進度比我想象中的要快,一個多月,聯系了 20 多個團隊。雖然說也遇到了一些很扯的事情,明明是服務 A 的問題,就直接讓我去找下游,讓我們排查半天,最后又說回來找服務 A 負責人,拉了個群,擺出來日志,才承認是自己的問題,開始排查。但是大部分團隊都非常配合,說明問題之后馬上去排查,發現問題下一個版本就修復了。如此默契的合作讓我感到驚訝又幸福!現在,系統錯誤維持在 200 以下了,并且現有的錯誤都已經找到了根因,還有3個服務待修復。最晚的會在 2 個周之后發布修復。可以預見到在不遠的未來,這個系統將會成為一個 0 錯誤的系統!
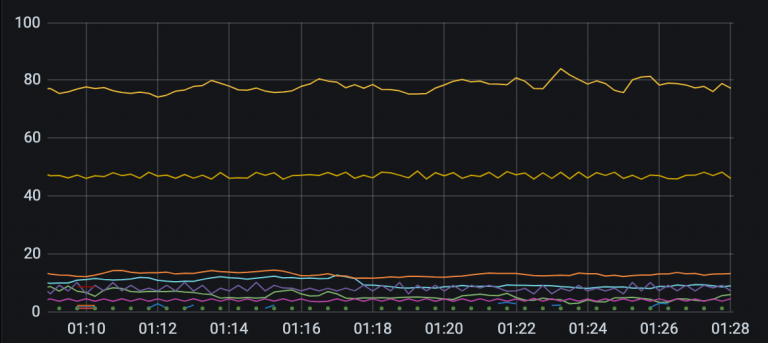
今天系統報出的錯誤,還是有一些服務在一直報錯,不過已經大大減少了。
這項工作雖然不涉及任何的 KPI 之類的,也沒有什么技術含量,還都是一些“溝通”的工作,但是卻帶給我很大的成就感。我相信它也會在未來節省我很多時間。比如說我們評估系統的 SLI 和 SLO,由于 false alarm 太多,導致要花很多工作確定 down time 有多少,現在直接通過監控就可以確定了。
這項工作帶給我的一些感想:
- 從源頭解決問題最徹底;
- 不要害怕溝通;
- 錯誤的發生都有原因,排查下去,零就是零,一就是一(從這個 Case 看,也確實所有的錯誤都可以被解決的);
- 每個公司都有臟活,累活(畢業去的第一家公司維護爬蟲,也有很多臟活、累活),這些都需要有人去做。
需要補充一下,我并不是完全否定做故障定位的思路。畢竟之前在螞蟻,有四五個組在做相同的東西,我們(和其他做一樣東西的組)嘗試過非常多的思路,也有很多人因為這些晉升了(你說去聯系了無數個團隊,排查了很多問題,這有什么 impact 呢?你說自己做了一個“智能定位”系統,晉升就穩了吧。)。印象比較深刻的是有個項目制定了上千個(他們稱為)決策樹,簡單來說就是:如果發生這個,就去檢查這個。頗有成效,很多配置不當的告警就被這種規則給過濾掉了(雖然我覺得直接改報警要好一些)。我非常佩服他們的毅力。
說了這么多濕貨,再說點干貨。我們其實還有一個問題沒有解決。如果讀者有思路,歡迎評論。
在 Service Mesh 中,所有的服務都是通過 Agent 來調用的。比如 App1 要調用 App2,它會把請求發到本地的 Agent 中,由 Agent 去調用 App2 所在機器的 Agent。
這里,超時的問題就難處理。比如我們設置了 1s 超時。假如說 server 端的 Application 超時了,那么 Server 段的 Agent 可以報告一個應用超時錯誤,不算做我們 Oitsi 系統錯誤。但是對于客戶端的 Agent 呢?它無法知道到底是 Server 的應用超時了,還是 Server 的 Agent 超時了。所以對于 Server 超時的情況下,客戶端的 Agent 總會報出一個內部超時錯誤。
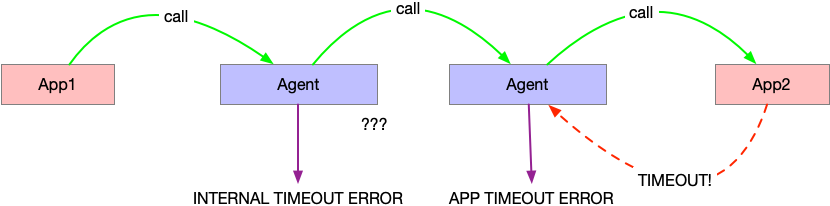
這種錯誤,我們當前還是無法區分是否是由應用引起的。
















