













一篇文章帶你了解抽象泄漏(Leaky Abstractions)
本文轉載自微信公眾號「ELab團隊」,作者ELab.xiebingyang 。轉載本文請聯系ELab團隊公眾號。
在 5 月 23 日 Online Meetup With Evan You 的問答環節中,Evan 在說到 low code 時提到一個概念 —— “abstraction leak”. 在前端開發過程中接觸過很多內部平臺和工具,包括 low code 建站平臺、組件庫、框架和二次封裝的元框架。在這個過程中會發現一個比較普遍的現象:
- 即便文檔覆蓋相對比較全面,開發者在實現或排查某一些特定的問題時仍然不可避免地需要閱讀對方平臺或庫的源碼,或了解更底層的原理。
- 一些特定的場景下,平臺或庫索提供的接口、界面或規范不再適用;它們的抽象層次不再能滿足業務場景要求。
但是往往這些痛點并不是系統本身的管理或設計缺陷;更多的是某些應用場景下的“抽象泄漏”導致。本文翻譯多篇相關英文文章,并在此基礎上整合、提煉,就系統設計中的抽象層級和抽象泄漏現象進行討論。
這篇文章將會介紹:
- 什么是抽象泄漏法則
- 抽象機制如何“泄漏”
- 開發者如何應對抽象泄漏
為了避免翻譯歧義,部分概念在特定場景下還會保留英文表述:
| 英文 | 翻譯 |
|---|---|
| abstraction | 抽象、抽象層級,名詞(在某種意義上也包含“封裝”的意思) |
| leak | 泄漏、漏洞、漏出 |
| interface | 接口(為更高一個抽象層級開發者、調用者、消費者、使用者所展示的“界面”) |
| consistency | 一致性;連貫、前后一致 |
引言
現在環顧四周,我們會發現日常生活中常常會用到一些非常復雜的系統:智能手機、計算機、打印機、汽車、電視、烤面包機…… 雖然我們自己很難自行從零制造這樣的一個機器,但是不論這些設備或系統多么復雜,我們都可以正常使用它們來完成日常所需的工作。
這個小小的奇跡歸功于我們稱為 “抽象”的概念(譯者:其中也離不開 encapsulation, 即“封裝”)。抽象是一種設計概念,它簡用潔的用戶界面 (interface) 屏蔽了復雜的細節,使得開發者不再需要關注這些細節就可以完成工作。抽象 (abstraction) 在每個軟件程序中都起著核心的作用,這樣的設計向站在更高抽象層級的調用者和使用者隱藏或屏蔽了 API 背后的實現細節。但這些抽象層級常常也會發生“泄漏”。
“抽象”是什么?
用一個實際例子解釋抽象和封裝——我們可以在瀏覽器的地址欄中輸入網址來訪問網站。在大部分前端開發場景中我們不需要了解瀏覽器如何執行 DNS 查找找到正確的網站,也不需要了解設備如何與網絡服務器進行 TCP 握手,也常常不需要知道網站如何渲染一個 DOM. 這個過程非常詳細、復雜,而很慶幸瀏覽器底層的邏輯幫我們完成了這些操作,我們不需要實現這些能力,在大部分場景中也不需要關心這些實現。
在計算機軟件設計中,隨著軟件本身的迭代、軟件系統體積和復雜度增加,我們會不斷構建新的抽象層級,并將其添加到已有的抽象層級中、豐富已有的抽象和封裝。做任何設計都是思考如何創建正確合理的抽象層級的過程。一個設計合理的抽象層次會向上層暴露所有重要的和必要的實現,但同時隱藏所有不必要的細節。一個合理的抽象層次會掌握好控制度與復雜度之間的平衡。一個合理的抽象層次可以輕松把它調用者的行為或執行任務映射到自身方法或屬性上。如果抽象層次設計得當,它會讓人感覺使用它很直接、便利,合乎常規邏輯。
To design something — anything — is to think about creating the right abstraction.
在軟件工程領域中,對抽象層級設計的關注會更加突出。在編寫任何的代碼時都需要考慮易用性和可維護性,一個開發者需要思考如何向其他代碼隱藏這部分的內部原理,又需要思考如何讓使用者順利地消費這段代碼的功能。抽象設計這個龐大的工程中至關重要的環節包括我們耳熟能詳的設計模式、命名、單元測試等等,這些看似關聯不密切的關注點都有一個共同的目標——在開發者設計抽象層時,幫助我們做出正確的決策,并保持其效果可控。
因為有“抽象” (abstraction) 設計的存在,我們可以在 HTML 文檔中直接編寫 <button> 而不需要繪制單個像素。我們可以編寫 SQL 查詢來獲取客戶的訂單歷史記錄,但不需要知道每一條記錄存儲的位置和大小。我們可以在不了解打印機語言的情況下打印文件,在不了解視頻編解碼器的情況下播放視頻文件,在不手動從硬盤上一個群集跳轉到另一個群集的情況下讀取文本文件,在不管理內存地址的情況下存儲數據集合。(當然,如果真的想這樣做,也是可以的。)
抽象如何“泄漏”
有一個真理:所有非簡單抽象層級都會泄漏。這個原則是由 Stack Overflow 聯合創作者 Joel Spolsky 在 2002 年提出的,在國內文獻中,有些人也將其翻譯為“抽象漏洞”、“技術露底”。它的含義是:任何試圖減少或隱藏復雜性的抽象,其實都并不能完全屏蔽細節;試圖被隱藏的復雜細節總是可能會從抽象層級中“泄漏”出來。
以下圖中黑色實線可以理解為“已定義的復雜度”;紅色實現為“超出定義范圍、超出預期的復雜度”:
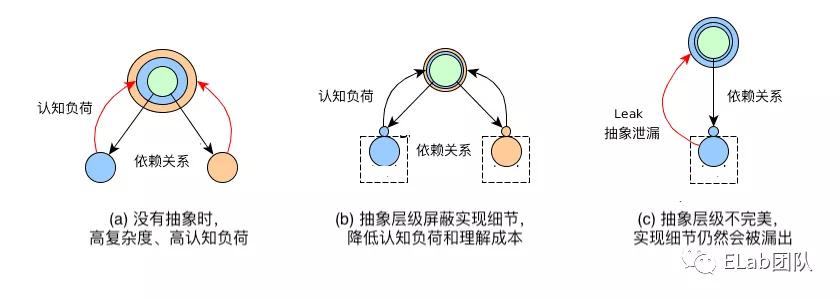
圖片來源:https://javadevguy.wordpress.com/2017/11/02/transcending-the-limitations-of-the-human-mind/
一種定義是:在軟件中,假設第 n 層抽象與第 n+1 層抽象和第 n-1 層抽象交互。第 n 層的實現復雜度為 N(n), 且它向第 n-1 層提供了范圍為 A(n, n-1) 的 API. 當第 n-1 層需要了解 N(n) - A(n, n-1) 的部分以實現某些功能,則發生了抽象泄露。
另一種定義是:在軟件中,如果第第 n 層抽象與第 n+1 和 n-1 層交互,但是第 n-1 層應該保證第 n 層不需要知道第 n-2 層的細節。如果第 n-2 層的實現細節出于某種原因暴露至第 n 層的細節,則發生了抽象泄漏。
通過建立抽象,我們可以在更高的層次上思考和編程。
抽象泄漏定律意味著:軟件市場上出現一個有趣的新工具,而且這個工具聲稱可以如何如何提高我們的工作效率時,更資深一些的開發者會說:“你先要學習怎么手動操作,然后再使用這些新工具來節省時間。” 在學 Vue 和 React 的 VDOM 之前我們需要先了解什么是實體 DOM. 新的編程工具實際上創造了一個抽象層級,它抽象出某種東西,而這個抽象層級如同其他所有抽象一樣在實際使用場景中總難免需要開發者在一定程度上了解它們的細節和實現原理:舉最簡單的例子,我們需要了解 Vue 雙向綁定的機制,以避免出現響應式對象無法更新的情況,這就是一個抽象泄漏。有效處理這些“泄漏” (leak) 的唯一方法是了解這個抽象層級的工作方式、了解它們到底向我們屏蔽了什么內容。抽象層級節省了我們的工作時間,但并沒有節省我們學習的時間。這也意味隨著技術的發展,我們擁有越來越高級的編程工具,建立越來越好的抽象、模型、設計理念,但精通編程這件事可能反而變得越來越困難。
但是這個規則為什么會存在?我們為什么不能建立完美的抽象層級?
這個問題在于,雖然抽象存在的意義是為了屏蔽細節,但抽象 (abstraction) 的價值也正是在于它所屏蔽或隱藏的細節當中。一個好的抽象應該做減法,也就需要將一些細節隱藏在調用者視線之外。但原 API 的設計范疇是有限的,其復雜度和操作支持范圍必定是它更下層抽象的一個子集。
The value of an abstraction is in the details that it hides.
在一個抽象層級“泄漏”得過于頻繁或泄漏規模過大時,導致開發者需要真正了解所有本應該被隱藏的細節,抽象層級實際上就已經失效了。這個所謂“便利”的抽象層級其實就沒有節省開發者任何時間或精力。軟件設計中的真正藝術是如何正確識別抽象層級、學會處理這些 abstractions 的漏洞,學會什么時候、以什么方式補全這些抽象層級上的缺口。
分割線內為譯者注解
為什么會出現抽象泄漏 (abstraction leak)?簡單說可能有幾個原因:
- 接口 (interface) 暴露的細節太多
- 接口 (interface) 所屏蔽的細節太多
- 抽象層級設計缺乏一致性 (consistency)
- 抽象層級缺乏完好的注解
接口暴露細節太多
例1:
Low code 或 no code 平臺是抽象泄漏的典型。部分 Low code 建站平臺的一個重要目標是賦能產品運營或非技術人員,但 low code 平臺在設計時往往無法完全屏蔽技術。一部分類似平臺會提供自定義代碼的功能,在實現產品賦能的同時滿足一定的研發靈活度。另一些 low code 平臺會屏蔽這些抽象層,取消頁面內代碼編輯器的支持。(提出這種平臺有抽象泄漏的存在只是陳述事實、不是帶有任何價值觀色彩;辯證地看,有些抽象泄露不一定是一個壞事。)
某個 low code 平臺初期會提供幾乎所有可以映射到 CSS 的屬性功能,但在后續的迭代版本中去除了這些屬性,只保留最簡單必要的“位置”、“背景圖”等屬性,引導使用者將自身的需要功能往已有屬性上映射。如文字需求映射為圖片、動畫需求映射為 gif 等,大大的降低了業務人員對平臺功能的認知成本。
例2:
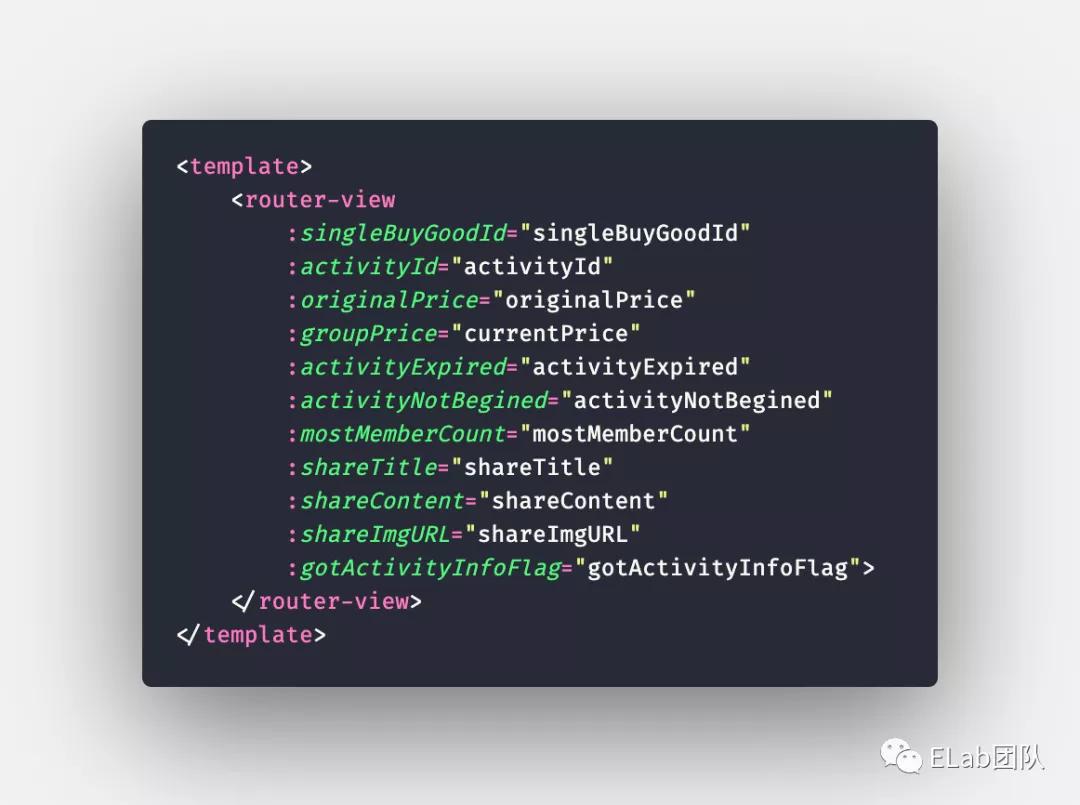
這一個設計的優化空間非常大——但是設計出來一個直接后果往往是因為暴露太多內容,導致優化成本過高。
實際上優化方式很多:使用狀態管理,父組件不需要處理這些參數,在子組件內直接處理數據;定義幾個合理的模型:shareConfig, activityConfig, 將數據在模型層封裝;放棄父組件的數據抽象層、子組件按需加載數據(GraphQL 是一種方案);…… 在一定程度都涉及到了抽象邊界的劃分、兩個抽象層級之間 API 的重新定義和設計。
接口屏蔽的細節太多
細節屏蔽的太多,接口范圍太窄,導致開發者真正想實現一些其他功能時只能去關注內部的實現細節。
例1:
前端框架和庫可能是一個很好的例子。React 16 及之前的事件封裝導致使用原生方法掛在 DOM 事件可能產生不可預期的后果;一個組件庫可能會重寫原生方法,如 Input 組件只暴露 onChange 和 onFocus 這類屬性,導致無法支持像 onCompositionStart 等小眾但真實存在的需求。
例2:
初學前端封裝某些組件時,可能會傾向于只封裝自己用到的部分:


一旦業務需求有變動、要求樣式變化,如果不重構已有的這個組件,就只能在它的調用方里關注這個組件實現的細節(即樣式和結構)在其父組件里覆蓋樣式,造成了抽象泄漏。但一個更好的設計可能是如圖2:在提供了一定的規范的基礎上,向調用方提供足夠靈活的 API、暴露可控的復雜度。
抽象層級設計缺乏一致性


當調用者或使用者難以理解抽象層級所提供的接口時,和業界規范不符合、組件或庫內部方法調用不一致會造成抽象泄漏現象——消費者或調用者(consumer)需要去了解或確認內部的實現。這個是命名在抽象層級設計中重要性的一個例子。
但更多的不一致性不是命名這么簡單,可能是這個抽象 (abstraction) 內部本身設計的不一致、設計缺陷導致的。比如服務內部不同函數返回是否緩存、緩存機制不一致;再比如后臺訪問一個學生的某些信息,A 接口需要傳入 parentId, B 接口需要 studentId;這個時候調用方就需要了解這兩個 id 之間的映射關系、甚至相互獲取的邏輯。
抽象層級缺乏完好的注解
除了常規定義的“缺乏注釋”以外,缺少注解還可以表現為:缺乏類型定義和功能定義,調用者從抽象層級外觀察難以低成本理解功能(接收什么參數、返回什么內容、在什么時機觸發);因為設計本身導致在調用層級中無法輕松看到或理解所調用的 API. 有些開發者認為最好的代碼是自注釋的代碼。
在 React hooks 之前,代碼復用通常會使用 mixin 或 HOC (高級組件). 在使用 mixin vs. HOC 的爭論中 React 官方是更推薦 HOC 的[1]:mixin 會引入大量不可控因素,引入隱形依賴、潛在命名沖突、復雜度急劇增加。
Composition over inheritance.
在 hooks 之后,設計模式的變動和編程范式轉移,使得代碼共享就更加簡單、直接,代碼在一定程度上可以更加“自動注釋”化 (self-documenting).

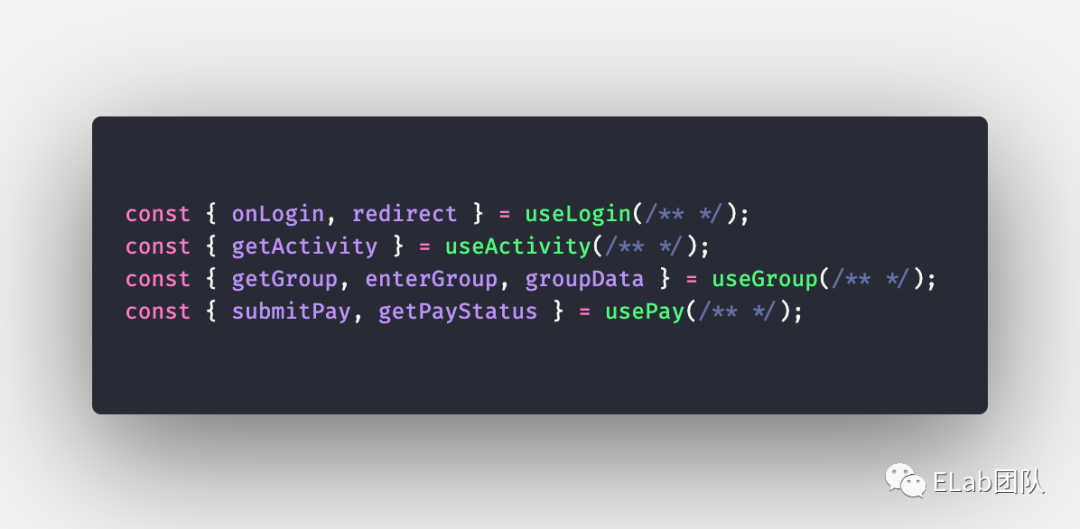
在一定程度上,“缺乏一致性”和“缺乏完好的注解”是抽象層級本身設計的一個缺陷。
”暴露的信息太多“、“屏蔽的信息太多”有一部分是設計缺陷;有一部分更可能是使用的場景或面向的受眾 (consumer) 已經偏離抽象層級設計的初衷,抽象層級在這一個場景內或面對這樣的調用者時已經不再完全適用。
開發者如何處理上游的抽象泄漏?
抽象和封裝降低了系統復雜度,但它們不是完美的解決方案。如果抽象泄漏太嚴重,我們可以直接刪除這個抽象層級,或創造一個更好的抽象。我們可以以文檔和注釋形式清清楚楚地記錄下它的功能和局限性。抽象和封裝是好事,但過多的抽象也反而會增加系統的復雜度。David J. Wheeler 指出:“計算機科學中的所有問題——除了“中間層太多”這個問題以外——都可以通過增加一個中間層解決。”
All problems in computer science can be solved by another level of indirection, except for the problem of too many layers of indirection.
--David J. Wheeler
增加一個抽象層
開發人員可以在這個抽象層級的基礎上二次封裝,增加一個抽象層級,達到屏蔽一些信息的目的。下游應用層會改調用這個新的抽象層級,這個抽象層級也會在它的層面收斂邏輯來完成下游應用所期望的行為。中臺是一個典型的例子:業務發展到一定規模,復雜度變高,原有的抽象層級泄漏嚴重不能滿足需求,所以抽象出一個新的中間層去統一處理邏輯、向調用方屏蔽實現細節。字節 Web Infra 一部分團隊成員也認為:長久以來 UX 和 DX 之間的矛盾是因為開發者所面臨的抽象層級過低;如果做更高一級的基礎建設,可以實現二者的雙贏——這就是企業內部元框架的誕生了。
重寫或拋棄抽象層
在更極端的情況下,開發者可以重新實現功能,甚至拋棄原有的抽象層次。這不是一個好習慣;隨著抽象層次的丟失,應用程序復雜度會提高。拋棄抽象層次的選擇是在兩種復雜度之間進行權衡取舍:取因為抽象缺失帶來的項目復雜度,還是取抽象泄漏的復雜度。
如果重新實現的抽象層級不能像原抽象層級那么優雅、達到原抽象 (abstraction) 的可用度,重新實現基礎功能還可能導致應用程序的其余部分(僅使用重新實現的功能的代碼部分)變得更加復雜。開發者由于某種原因無法在新的接口 (interface) 下兼容舊的接口 (interface) 時,也容易出現這個問題。如果業務程序員被迫放棄舊的接口、轉而開始自己思考軟件設計,這些開發者的產出其實很可能達不到原抽象層級的水準。客觀、不帶有價值判斷地說,業務開發者當前的第一優先級仍然是業務,業務開發者中大部分人可能沒有時間(或沒有興趣)去真正設計清晰優雅的系統。同樣,重寫抽象層也是一種權衡取舍:開發者接受了新引入的潛在抽象泄漏;放棄了“現在”的抽象泄漏、接受了“未來”的抽象泄漏。至于如何取舍也需要辯證地、根據實際情況判斷。
繞過抽象泄漏
另一種方法是所謂 "code between the lines":在了解抽象泄漏的基礎上,繞過它,或專門“為了它”編寫代碼。開發者需要了解抽象背后的實現細節,強扭業務代碼來適配抽象層級的實現。這會使得代碼復雜度增加,可讀性和移植性也會變差。
Coding between the lines 的一個典型的例子是虛擬內存。一個程序給多個對象分配內存時,通常會有一個“自然”的分配順序。但如果對象很多、內存分頁行為變得很關鍵時,人們通常會重寫程序讓“對象內存分配得靠近一些”,從而提升程序的性能。盡管虛擬內存著一層抽象相關的文檔沒有提及對象存儲的物理位置,但是程序員設法“扭曲”了自己的代碼,讓自己的代碼直接和抽象層級的內部實現一個“對話”,來獲得所需的性能提升。顯而易見當程序員被迫這樣編碼時,他們的程序復雜度將會顯著提高——而且更重要的是,這樣的代碼可移植性會降低。
一般而言開發者最開始的代碼實現會更簡單、清晰、直接,并且最大程度地復用了底層的抽象,這個時候開發者是面向一個最理想狀態(理想內存、理想 CPU、理想網絡、理想數據等等)進行編程的。但當程序需要實際交付共時可能會出現一些實際和底層抽象綁定或耦合問題:如何適配不同機器?如何利用交付環境提高程序的性能?……圍繞抽象泄漏編碼就相當于引進來一個魔法師,這個魔法師實際上運用他對內部工作原理的知識,將已有的簡單的代碼實現和涉及到的抽象層級背后的原理相結合(結合,原文為 convolve, 直譯為“卷積”,即扭曲在一起)去“神奇地”實現這個功能,也就是我們常常說的 "hack 一下"。原本的代碼可以實現局部的控制,將復雜度限定在某一個范圍內,但在這樣為了抽象泄漏專門編碼會將代碼打散、外露復雜度、外露細節實現。這個過程中,代碼也隱含地和交付平臺或所依賴的底層抽象更加耦合;耦合度提高也意味著可移植性降低。
開發者如何設計抽象層?
抽象層級的設計是很復雜的。但是我們可以先列舉出四個相互聯系的初步設計原則:范圍控制、概念分離、增量性、健壯性。
- 【范圍控制】指抽象層級應在一定的范圍內給予調用者適當的控制權。范圍控制有很多種。幾個更貼切和實際的例子可能是 low code 平臺對定義好的配置項有充分的控制;前端框架對函數中拋出異常的處理;組件庫組件在封裝一些基本能力以外都會提供 className 或類似屬性支持調用者在一定程度上覆蓋樣式。
- 【概念分離】意味著使用者或調用者應當不需要了解整個抽象層級的實現原理,就可以使用抽象層的接口實現某些特定的功能。在系統設計層面上這是很困難的,因為具體的實現有時不同的變量、方法、屬性之間的交互可能會產生令人意想不到的深遠的影響。
- 【增量原則】意味著如果一個開發者決定自定義這個抽象層的某一個部分,調用方應當可以聲明式地改變他們想自定義的內容,然后完全復用抽象層其他的部分。一個開發者不應該為了部分的自定義實現承擔全部抽象層級范圍的責任,他們也不應該需要從零開始重新編寫一個新的實現方式。
- 【健壯性】意味著客戶程序中的錯誤的影響應受到適當的限制,一部分的錯誤對系統其余部分的影響可控。
抽象泄漏在所難免;除此之外,針對抽象層級如何泄露的具體方法有:
- 確保所提供的抽象層級具有一致性 (consistency). 確保在這一個層級中提供統一的、一致的、同一個認知層面的抽象。
- 明確抽象層級的適用范圍。告知開發者或用戶這個抽象層級的明確的適用范圍、應用背景,在超出適用范圍后哪里可能存在抽象泄漏、他們可以從什么角度處理。
- 引入輔助或并行的抽象,讓調用方有更多選擇。如提供簡單模式、復雜模式;用戶不認為多模式這件事本身是抽象泄漏。同上條一樣,管理抽象、防止抽象泄漏在很大程度上是管理用戶的期望和認知。
- 擁抱抽象泄漏,并把它當作抽象層級的一部分,在制定好規范的基礎上鼓勵調用者填補框架的認知空白。典型例子如 webpack, eslint 等工具的插件機制。與其逼迫調用者 "hack" 你的抽象層,不如提供一個入口、邀請他們共建。
Exposing an abstraction leak might be the most effective solution to hide it
總結 TL;DR
- 計算機領域各處存在抽象和封裝。設計任何東西都是思考如何創建正確的抽象層級的一個過程。
- 任何試圖減少或隱藏復雜性的抽象其實并不能完全屏蔽實現細節;試圖被隱藏的復雜細節總是可能會從抽象層級中“泄漏”出來。
- 抽象泄漏的幾個直接表現可能是:
- 暴露細節太多
- 暴露細節太少
- 設計缺乏一致性
- 缺乏完好的注解
- 針對上游服務抽象泄漏,開發者可以:
- 增加一個抽象層
- 重寫或拋棄上游抽象層
- 繞過抽象漏洞去編碼、或“針對”抽象漏洞去編碼
- 開發者設計抽象層時,需要注意:
- 抽象層級需要在一定的范圍內給予下游適當的控制權
- 抽象層級之間概念互相分離(高內聚、低耦合)
- 支持讓調用方聲明式地改變他們想自定義的內容
- 客戶程序中的錯誤對系統其余部分的影響需要可控、有限
- 更具體一些,針對已有的抽象漏洞,可以:
- 確保所提供的接口 (interface) 的一致性
- 明確抽象層級的適用范圍
- 引入一個輔助或并行的抽象
- 擁抱抽象泄漏,并把它當作抽象層級的一部分
參考文獻
除譯者注部分和中間穿插少部分舉例,其他均翻譯+整合自:
- What are Leaky Abstractions - an Illustrated Guide[2]
- The Law of Leaky Abstractions[3]
- Leaky Abstractions[4]
- Plugging Leaky Abstractions[5]
- Towards a New Model of Abstraction in the Engineering of Software[6]
參考資料
[1]React 官方是更推薦 HOC 的: https://reactjs.org/blog/2016/07/13/mixins-considered-harmful.html
[2]What are Leaky Abstractions - an Illustrated Guide: https://medium.com/young-coder/what-are-leaky-abstractions-an-illustrated-guide-f2982ff21cae
[3]The Law of Leaky Abstractions: https://www.joelonsoftware.com/2002/11/11/the-law-of-leaky-abstractions/
[4]Leaky Abstractions: https://alexkondov.com/leaky-abstractions/
[5]Plugging Leaky Abstractions: https://blog.ndepend.com/plugging-leaky-abstractions/
[6]Towards a New Model of Abstraction in the Engineering of Software: http://www.itu.dk/people/ydi/PhD_courses/adaptability_design/kiczales92towards.pdf

















