從 WiscKey 看 LSMtree 的不足
本文轉載自微信公眾號「碼農桃花源」,作者冉小龍。轉載本文請聯系碼農桃花源公眾號。
近期,閱讀WiscKey論文深有感觸,特寫這篇文章來闡述自己的觀點。
說一句廢話就是:任何軟件的發展,其實都依賴于硬件的設計和進步,所以從這一點來看,LSMtree誕生于上世紀80年代,在那個年代,還是機械硬盤的時代。所以,可以看的到的是,整個LSMtree最初的構建思想都是基于機械硬盤的設計思路,但是需求是無止境的。WiscKey自我感覺是,在LSMtree的基礎上,基于SSD的設計思路所做的一種優化,基于這個思路,我們來簡單分析一下論文中所闡述的觀點。
先闡述幾個LSMtree的概念:
- Read amplification is the number of I/O’s required to satisfy a particular query
- Write amplification is the amount of data written to storage compared to the amount of data that the application wrote.
- Space amplification is the space required by a data structure can be inflated by fragmentation or requirements for temporary copies of the data.
讀寫放大就不說了,知道LSMtree的人基本都了解,現在說一下空間放大的問題。
空間放大大體上是說:存儲采用的數據結構因分裂或臨時數據拷貝造成的磁盤空間占用放大。
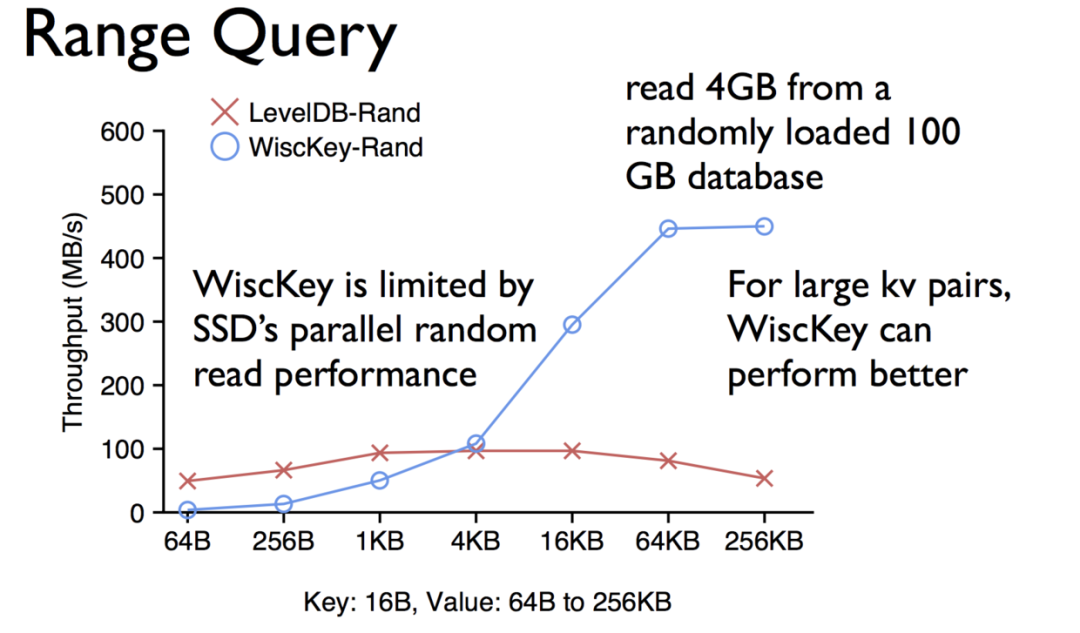
LSMtree誕生的那一天起,并不是為了存儲這些大的value的情況。在這種大value的情況下LSMtree的性能會急速下降,所以,其實數據庫都有自我的一種保護機制,來限定每一行value所能夠存儲的最大值。下面是wisckey和LSMtree的對比,可以看到在value較大的時候,wisckey的性能要遠遠大于LSMtree的。
下面是隨機和排序之后,wisckey和LSMtree的對比:
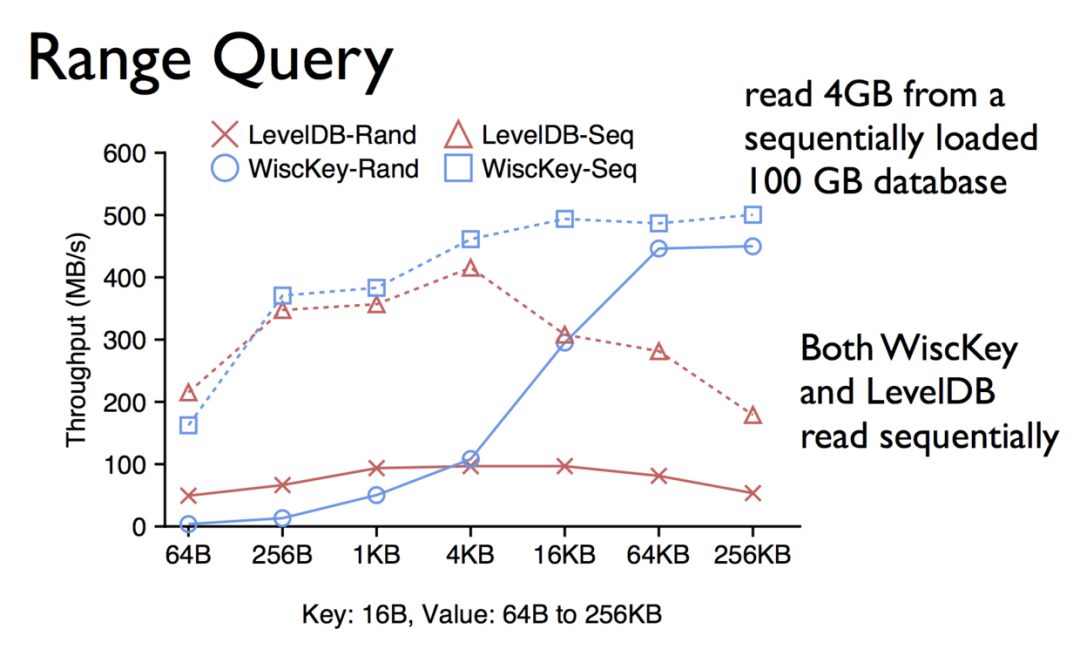
其次,LSMtree都有這種compaction的操作,在做compaction的時候,對磁盤IO的壓力是比較大的。再者,LSMtree并不能很好的利用SSD的并行計算能力,這一點也可以理解。
但是,在當下的存儲引擎中,LSMtree還是很受歡迎,從性能的角度來考量,讀寫放大哪怕是空間放大(這三者是不可并存的)我最差的情況也就放大個10-50倍左右的放大成本,但是我能在性能上帶來將近千倍的速度提升(將隨機寫轉化為順序寫),所以,在性能面前,這些都是可以容忍的。
SSD與SATA的差異
- 順序IO與隨機IO
- 并行計算能力
- 大量的重讀寫會使SSD的壽命降低。
當value較大的時候,LSMtree的表現
- value越大,越容易觸發compaction
- LSMtree的每一層level都可以簡單理解為其下一層的cache,value越大,cache的效果越差,每次訪問讀取到下層level的概率會增加。
- 每條數據每次merge的時候,會造成寫入的量增加。
wisckey誕生的前景
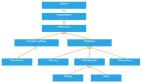
其實,我們可以仔細回想一下,在LSMtree中,我們并不需要value是有序的,只要保證key是有序的,就可以滿足我們的需求。所以,我們是否可以考慮將key繼續存儲在LSMtree中,而將value區分存儲到log文件中,然后把value的指針一起存儲到LSMtree中,是的,這也是wisckey的思路:分離后的模型大致如下:
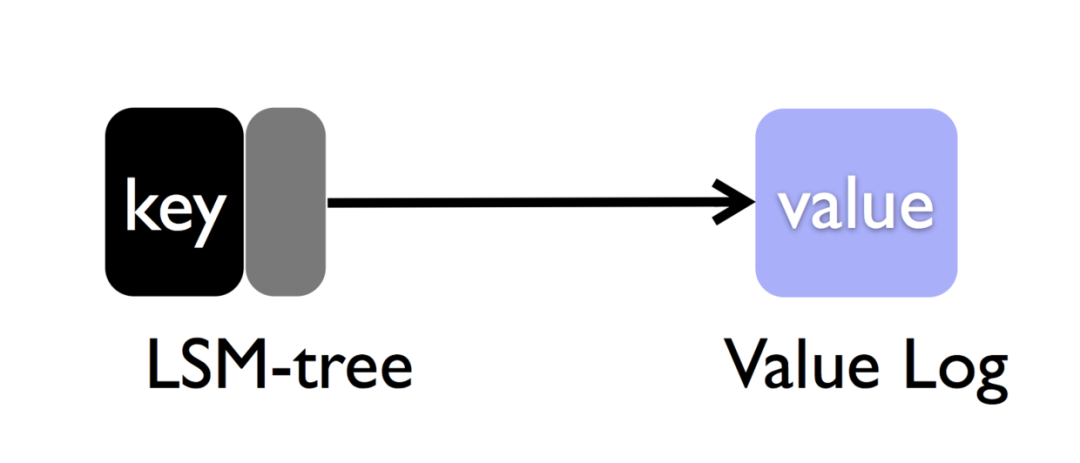
此時,我訪問數據的思路是這個樣子的:
- insert:先append到value log的末尾,再將剛才append的value的地址塞到LSMtree中。
- delete:將key從LSMtree中刪除,當compaction的時候,如果找不到對應的key那就在垃圾回收的時候順便一起將它回收掉就OK。
- select:拿LSMtree中的key+addr直接獲取到value對應的地方,拿出來就行。
wisckey key/value分離的優勢
首先,key的存儲數據量相比原先的存儲模型減少的不僅僅是一個量級,所以,可以充分發揮LSMtree的特性。其次,將value分離之后,避免了compaction操作的時候無效的value移動,從而極大的降低了讀寫放大,增加SSD的使用壽命。再者,由于key的存儲量級的減少,cache能起到更好的效果。
可能引發的問題
之前對range進行操作的時候,只需要順序讀就OK,但是k/v分離之后,可能需要順序讀+多次隨機讀來達到目的,論文中提到,這個可以充分利用SSD的并行能力解決,但是能解決多少有待進一步追蹤。
上面也提到,lsmtree中value的delete操作,是依賴于compaction的時候的GC來操作的,但是k/v分離導致這個回收是異步的進行。基于這一點,我們來看看wisckey的處理思路:
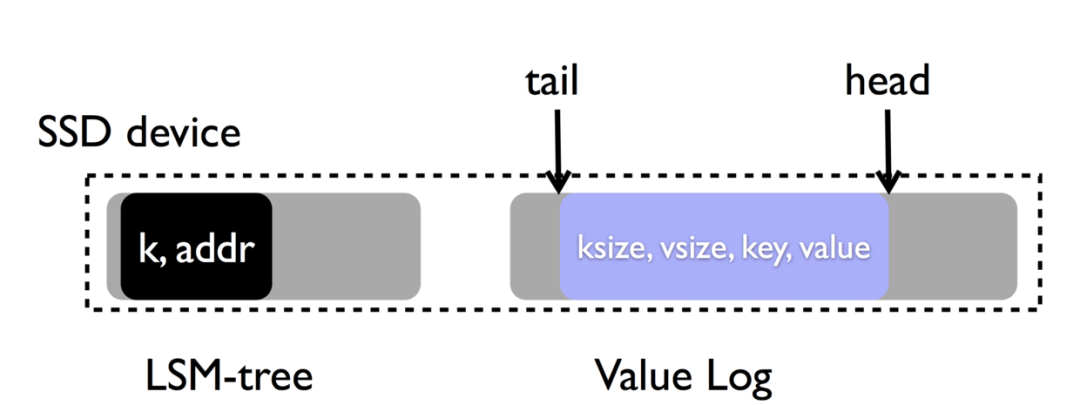
whiskey優化了原有垃圾回收的做法,head指向最新的block插入的位置,tail表示回收value操作開始的那個位置,GC被觸發之后,我們從tail開始進行掃描,將有效的block移到head的后面,把tail到head的這一段位置清空,重置tail和head標記。不難看出,將有效的block后移這個操作,在某種程度上也帶來了寫放大,但是的確提高了效率,總之是在時間和空間這兩個點上進行權衡。wisckey他會根據delete這個操作請求的多少來決定觸發GC的時機。
奔潰一致性。
由于分離操作,一旦出現事故,wisckey如何保證奔潰情況下的一致性問題呢?
- 對key和value的操作都是原子的,總共分為三種情況:
- key/value都寫入成功,OK這就是我們要的效果。
- key寫入成功,value寫入失敗,則把LSMtree中的key刪除,返回value不存在。
- key寫入失敗,value寫入成功,返回不存在,寫入的value在后續的垃圾回收中回收掉就OK。
如果遇到宕機重啟,在恢復的過程中,它是順序恢復的。
可能存在的問題
- 假如我的value log中存儲的都是一些較短的value,每次都需要和磁盤交互,對磁盤的吞吐量是一種考驗。在這里是否可以考慮添加一層緩存結構,將多個小的value合并之后再寫。
- 待續
最后,致敬一下國外同行,關于這篇論文有一篇100頁的slides[1]和PDF[2],非常詳盡的描述了這篇論文的思路。
參考資料
[1]WiscKey:slides: https://www.usenix.org/sites/default/files/conference/protected-files/fast16_slides_lu.pdf
[2]WiscKey:pdf: https://www.usenix.org/system/files/conference/fast16/fast16-papers-lu.pdf
作者簡介:
Apache Pulsar committer
Apache BookKeeper contributor
Apache Pulsar Go client 作者及國內主要維護者
Apache Pulsar Go Functions 作者及國內主要維護者
Stremnative/pulsarctl 作者及國內主要維護者
streamnative/rop 作者及國內主要維護者
【責任編輯:武曉燕 TEL:(010)68476606】