高并發服務優化篇:淺談數據庫連接池

本文轉載自微信公眾號「Coder的技術之路」,作者Coder的技術之路。轉載本文請聯系Coder的技術之路公眾號。
被N多大號轉載的一篇博客,引起了我的注意,說的是數據庫連接池使用threadlocal的原因,文中結論如下圖所示。

姑且不談threadlocal的作用和工作原理,單說數據庫連接池這個知識點,猛地一看挺有理;仔細一看,怎么感覺不太對啊,同學,這是什么虎狼之詞。
$ 實踐是檢驗真理的唯一標準
個人理解,連接池提供的獲取連接的能力,需要對"任務"唯一,即,只有當某一線程完成了本次數據操作,將連接放回到連接池之后,其他線程才能夠再次獲取并使用。原因我們后面細說,先來親自測試一下。
連接池選一個druid,設置連接池中只有一個connection,方便驗證多線程應對同一個connection的場景。
首先,將datasource共享資源傳入線程,采用datasource.getConnection()方式獲取連接 :
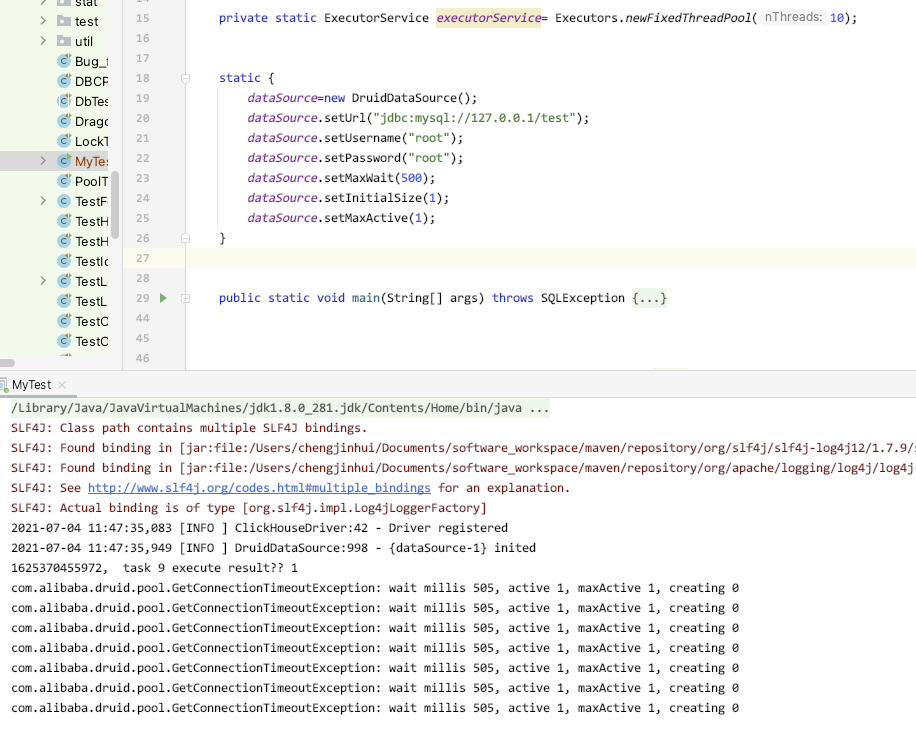
注:Runnable中故意不執行connection.close
結果如上圖:只有一個線程可以正常執行,由于沒有被關閉,其他線程都獲取連接失敗了。說明,數據庫連接池的作用方式是某個線程任務"獨占"的。
$ 退一步來講
假設如同開頭文章中描述的,用了一個功能不完備的連接池,讓多個線程拿到了同一個connection,那么,用threadlocal真的可以起到互不影響的作用么?
- //驗證思路參考自:https://blog.csdn.net/sunbo94/article/details/79409298
- //Connection設置 autoCommit=false
- private static final ThreadLocal<Connection> connectionThreadLocal=new ThreadLocal<>();
- private static class InnerRunner implements Runnable{
- @Override
- public void run() {
- //其他代碼省略...
- String insertSql="insert into user(id,name) value("+RunnerIndex+","+RunnerIndex+")";
- statement=connectionThreadLocal.get().createStatement();
- statement.executeUpdate(insertSql);
- System.out.println(RunnerIndex+" is running");
- //讓特定的線程執行回滾,用來驗證事務之間的影響
- if (RunnerIndex==3){
- //模擬異常時耗時增加
- Thread.sleep(100);
- //從threadlocal里拿連接對象
- connectionThreadLocal.get().rollback();
- System.out.println("3 rollback");
- }else{
- //從threadlocal里拿連接對象
- connectionThreadLocal.get().commit();
- System.out.println(RunnerIndex +" commit");
- }
- }
- }
結果如下:
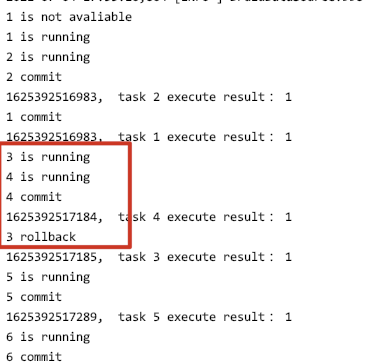
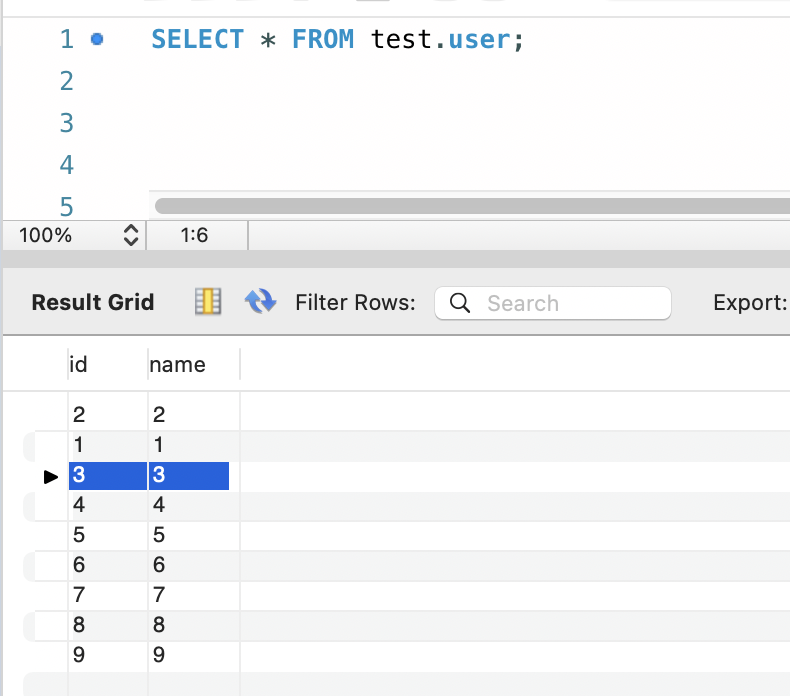
只要是線程3的statement.executeUpdate 語句運行在前,而事務回滾語句執行在某個commit之后,就會出現問題,即需要回滾的數據被提交的情況。
如下圖,3的insert結果確實沒有被回滾,而是出現在了表中:
所以,對于知識,大家不能盲目的接收,建議抱些懷疑的態度,還是有必要的。
$ 話說回來,為什么threadlocal對同一個數據庫連接不起作用呢?
Connection是什么?
connection可以當成是服務器和數據庫的一個會話,而statemant用來在會話的上下文中執行sql以及返回結果。一個connection可以包含多個statement;然而在兩者中間,還有一個事務(Translation)的概念,事務用來保證其內部的語句,要么都執行,要么都不執行,如果autoCommit被開啟,則默認是一個語句一個事務。
往簡單點說,connection是一種共享資源,更簡單一點,它是一個共享變量,在被連接池創建之后,在內存中的地址是唯一的一個變量。
ThreadLocal能存共享變量么?
存肯定能存,但不建議,因為將Connection set進ThreadLocalMap,也其實是保存一個內存對象的地址引用而已,真正使用的時候,還是唯一的那個對象在起作用。
ThreadLocal最常用的功能,是為了避免層層傳遞而提供了對象保存和獲取方法。
高中學數學的時候曾經有過一個技巧,叫證難則反,在這里也適用。我們反過來想,如果用threadlocal的副本拷貝能實現connection的隔離,那豈不是只要一個connection就可以了?實時上呢,數據庫連接常常會出現不夠用的情況,結論就顯而易見了~
$ 話又說回來,threadLocal想要完成數據庫連接隔離的功能,需要怎么做呢?
如果非要用ThreadLocal實現這個連接隔離的功能,那么,只能是為每個線程創建新的連接,然后保存在Threadlocal中,這樣,每個線程在自己的生命周期范圍內只會使用這個連接,即可實現線程隔離。
$ 話又又說回來,druid、zadl等一眾數據庫連接池是怎么進行連接的管理工作的呢?
最大連接數為1的druid連接池原理概覽:
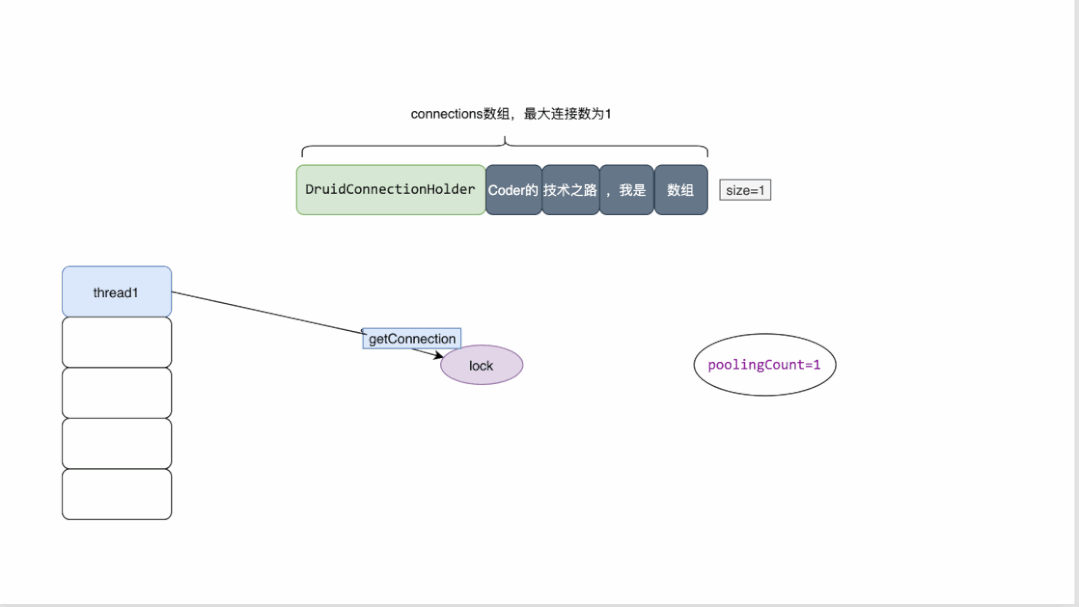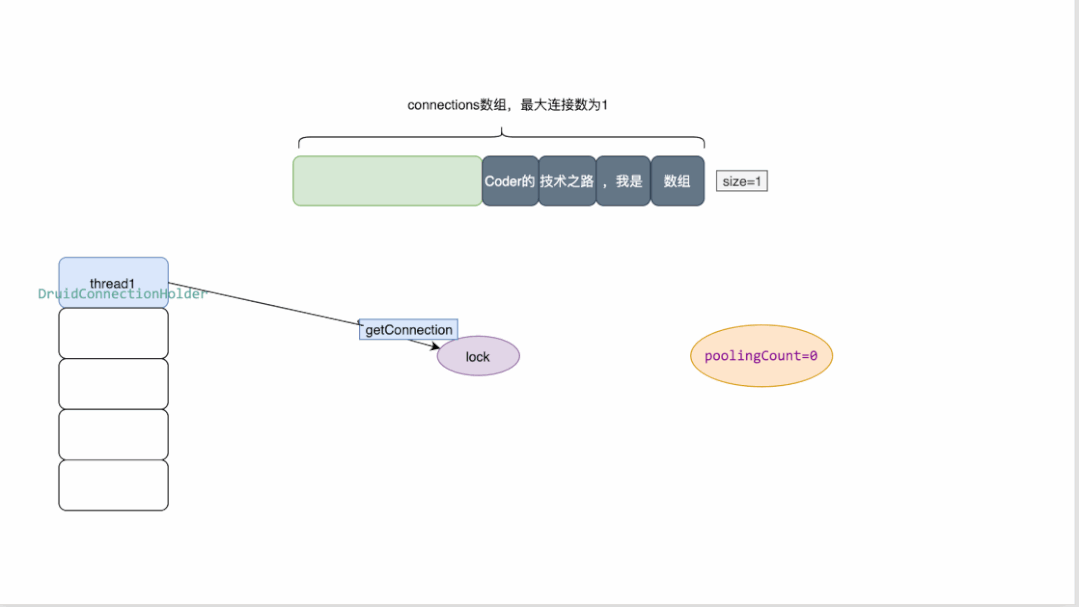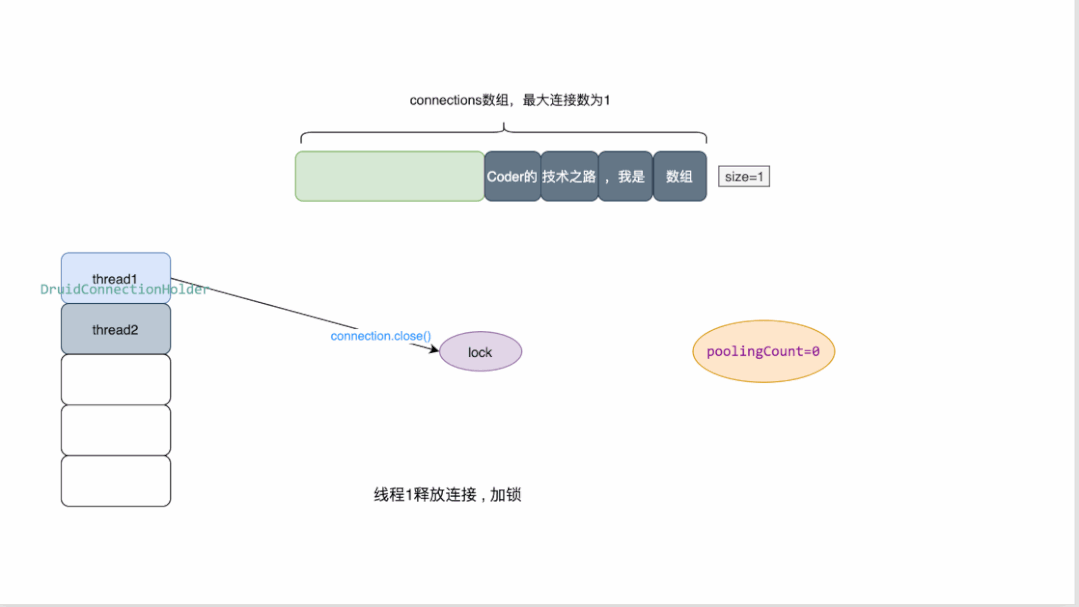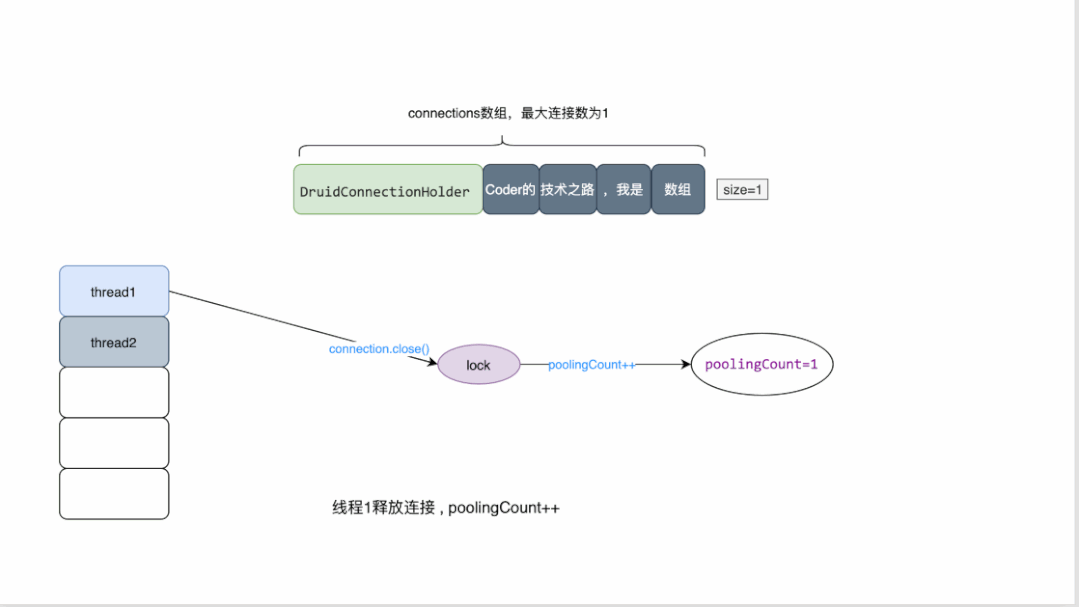
- druid維護一個數組來存放連接
- 同時維護了多個變量來檢測連接池的狀態,其中poolingCount用來表示池中連接的數量
- 當有線程來獲取連接時,需要先加鎖,對數量進行減一操作。
- 當獲取連接時發現數量為0 ,則返回為空
- 當連接關閉時,會將連接資源放回數組,并對數量做加一操作。
*上述只是druid連接池的極簡版流程敘述,實際上,還有連接池空等待、滿通知、活躍數、異常數等的復雜判斷。*有興趣的同學可以看下源碼。
zdal的連接池管理源碼一覽:
- public class InternalManagedConnectionPool{
- //最大連接數
- private final int maxSize;
- //用來存放連接的鏈表
- private final ArrayList connectionListeners;
- //內部的信號量,用來控制允許獲取資源的線程總數
- private final InternalSemaphore permits;
- //正在使用的連接數
- private volatile int maxUsedConnections = 0;
- protected InternalManagedConnectionPool(...){
- //構造函數中,初始化了連接池大小和信號量大小
- connectionListeners = new ArrayList(this.maxSize);
- permits = new InternalSemaphore(this.maxSize);
- }
getConnection()方法:
- //獲取連接
- public ConnectionListener getConnection(){
- //信號量嘗試獲取許可
- if (permits.tryAcquire(poolParams.blockingTimeout, TimeUnit.MILLISECONDS)) {
- ConnectionListener cl = null;
- do {
- //加鎖資源池
- synchronized (connectionListeners) {
- if (connectionListeners.size() > 0) {
- //獲取list的最后一個
- cl = (ConnectionListener) connectionListeners.remove(connectionListeners.size() - 1);
- //最大連接數 減去 正在工作的信號量
- int size = (maxSize - permits.availablePermits());
- if (size > maxUsedConnections){
- maxUsedConnections = size;
- }
- }
- }
- if (cl != null) {
- return cl;
- }
- }while(connectionListeners.size() > 0);
- //OK, 在連接池中找不到正在工作的連接了. 那就創建個新的
- createNewConnection(){...}
- }else{
- if (this.maxSize == this.maxUsedConnections) {
- throw new ResourceException(
- "數據源最大連接數已滿,并且在超時時間范圍內沒有新的連接釋放,poolName = "
- + poolName
- + " blocking timeout="
- + poolParams.blockingTimeout +
- "(ms)");
- }
- }
這里把內部連接池的管理類的關鍵屬性和連接獲取方法流量進行了簡化,連接歸還就不弄了,大同小異,仔細看,我們看到了什么
- volatile 標識的maxUsedConnections用來完成線程間數據可見
- 隸屬于AQS系列的Semaphone,用來控制共享資源并發訪問量。
都是些常見的八股文,不過組合起來可就了不得~
$ 話又又又說回來,在druid、zdal中,threadlocal的作用體現在哪里呢?
我們知道,誠如druid、zdal等優秀的中間件,可不止是數據庫連接池這一個作用,阿里數據庫中間件zdal源碼解析 文中也有提及。
那么,ThreadLocal能在這里扮演什么角色呢?
就以zdal為例,因為阿里的數據庫規模基本都非常大,但又有一套完備的數據庫庫表拆分規范,因此,分庫鍵、分表鍵、主鍵、虛擬表名等在設計和存儲時需要遵循規范,而zdal中的解析操作,也需要與之相匹配。
這個解析工作是相對復雜且繁重的,然而,針對同一用戶的操作,通常庫表的路由是相對固定的,因此,當我們解析過一次sql,通過各個字段和配置規則,計算出了庫表路由,那么,可以直接put進線程上下文,供本次請求的后續數據庫操作使用。
- public Object parse(...){
- SimpleCondition simpleCondition = new SimpleCondition();
- simpleCondition.setVirtualTableName("user");
- simpleCondition.put("age", 10);
- ThreadLocalMap.put(ThreadLocalString.ROUTE_CONDITION, simpleCondition);
- }
- public void 后續操作(){
- RouteCondition rc = (RouteCondition) ThreadLocalMap.get(ThreadLocalString.ROUTE_CONDITION);
- if (rc != null) {
- //不走解析SQL,由ThreadLocal傳入的指定對象(RouteCondition),決定庫表目的地
- metaData = sqlDispatcher.getDBAndTables(rc);
- } else {
- // 通過解析SQL來分庫分表
- try {
- metaData = sqlDispatcher.getDBAndTables(originalSql, parameters);
- } catch (ZdalCheckedExcption e) {
- throw new SQLException(e.getMessage());
- }
- }
- }
這個也正好是對前面ThreadLocal正確使用方法的補充。
起因是對一篇文章敘述產生疑問,通過簡單的驗證,證實了自己的想法,然后又從幾個方面對數據庫連接和threadlocal進行了擴展,以上,大家如果發現有任何問題,歡迎留言幫忙指正和補充。