TIDB,面向未來的數據庫到底是什么?
本文轉載自微信公眾號「咖啡拿鐵」,作者咖啡拿鐵。轉載本文請聯系咖啡拿鐵公眾號。
背景
tidb這個技術名詞很多同學或多或少都曾經耳聞過,但是很多同學覺得他是分布式數據庫,自己的業務是使用mysql,基本使用不上這個技術,可能不會去了解他。最近業務上有個需求使用到了tidb,于是學習了一下基本原理,會發現這些原理其實不僅僅局限于分布式數據庫這一塊,很多技術都是通用的,所以在這里寫一下分享一下學習tidb的一些心得。
先說說為什么選擇tidb吧,一般來說在咱們的業務中都是使用的mysql,但是單機數據庫容量和并發性能都有限,對于一些大容量或者高并發的場景我們會選擇sharding-jdbc去做,使用sharding-jdbc的確解決了問題但是增加了開發難度,我需要對我的每一個表都設置分表key,并且每個查詢都得帶入這個key的值,這樣就增加了查詢限制,如果不帶key的值就得所有庫表都得查詢一次才行,效率極低,所以我們又異構了一份數據到es來滿足其他條件。怎么解決這個問題呢?正好公司最近內部在推tidb,我看了下tidb基本兼容mysql,存儲無限擴展,開發成本比較低,性能整體也不錯,所以決定使用了tidb。
數據庫發展歷史
關系型單機數據庫
關系型數據庫的開始是以1970年Edgar F.Codd 提出了關系模型。在數據庫發展早期階段,出現了很多優秀的商業數據庫產品,如Oracle/DB2。在1990年之后,出現了開源數據庫MySQL和PostgreSQL。這些數據庫不斷地提升單機實例性能,再加上遵循摩爾定律的硬件提升速度,往往能夠很好地支撐業務發展。
分布式數據庫
隨著摩爾定律的失效,單體數據庫的發展很難應對更高級別的挑戰,所以就出現了分布式數據庫,分布式數據庫擁有應對海量并發,海量存儲的能力所以能應對更難的挑戰。
- nosql:HBase是其中的典型代表。HBase是Hadoop生態中的重要產品,Google BigTable的開源實現,當然還有我們熟悉的redis,nosql有一些自己的特殊使用場景,所以有一些自己的弊端,BigTable不支持跨行事務,用java開發性能也跟不上,redis的話用內存存儲,無法保證事務。并且nosql已經是不靠關系模型了。
- sharding: 我們依然可以通過單機數據庫完成我們分布式數據庫的功能,我們通過某個組件實現對sql進行分發到不同分片的功能,比如比較出名開源的有sharing-jdbc,mycat,阿里云上商業的有drds。sharing的話對于運維來說比較困難,如果需要擴容需要不斷的進行手動遷移數據,還需要自己指定某一個分片key。
- newsql:在newsql中可以保證acid的事務,也維持了關系模型,并且還支持sql。比較出名的有goole的F1和Spanner,阿里的OceanBase,pingCap的tidb。
學前提問
在我們學習某個知識的時候,一般都是會帶著一些問題去學習,有目的的學習會讓你更快的上手,對于tidb或者分布式數據庫,我在使用的時候會有這些疑問:
如何保證無限擴展?因為平時使用的大多都是sharding-jdbc那種有個sharding-key的技術,這種其實無限擴展是比較麻煩的,所以我最開始就對tidb如何保證無限擴展發出了疑問?
如何保證id唯一,分布式數據庫往往會進行分片,在單機數據庫中的自增id就不成立,tidb是如何保證的呢?
如何保證事務?前面我們說過newsql是需要支持acid的事務的,那么我們的tidb是如何保證的呢?
通過索引是如何查詢數據的呢?單機數據庫使用了索引加速查詢,tidb又是如何做到用索引加速查詢的呢?
tidb
架構
再回答我們上面的那些問題之前,先看一看tidb的整體架構是什么?
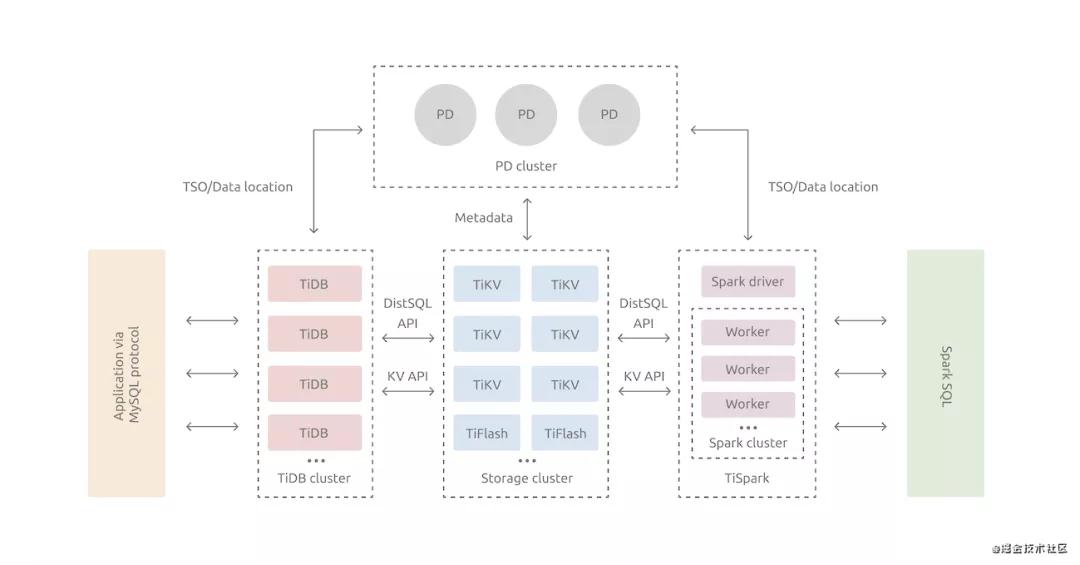
tidb其實是典型的計算分離的架構,對計算分離架構不熟悉的可以看看我之前的文章:聊聊計算與分離
TiDB Server:計算層,對外暴露協議的連接端口,負責管理客戶端的連接,主要做的就是執行SQL解析以及優化,生成分布式執行計劃,由于這里是計算層是沒有狀態的,所以是可以無限擴展。
PD Server:PD是整個集群的大腦,負責存儲每個 TiKV 節點實時的數據分布情況和集群的整體拓撲結構,提供 TiDB Dashboard 管控界面,需要保持高可用。
TiKV: k-v存儲引擎,在tikv內部,存儲數據的基本單位是Region。
Tiflash:這個是用于列式的存儲引擎
TSpark: 這是tidb對spark進行支持,所以tidb他是一個HTAP的數據庫。
如何無限擴展?
我們首先來到我們的第一個問題,Tidb如何做到無限擴展?
首先我們來看看計算層: tidb-server,我們剛才說過在計算層中,是無狀態的,所以就可以進行無限擴展,如果你的場景并發度很高或者數據庫連接很多,可以考慮多擴展tidb-server。
然后我們來看看存儲層,有一類數據云數據庫通常也會被誤認為是分布式數據庫,也就是aws的auroradb和阿里云的polardb,這兩個數據庫也是采用的計算與存儲分離的架構,在計算層也可以無限擴展,但是在存儲層他們使用的是一份數據,這個也就是shared-storage架構,這兩個數據庫依靠這大容量磁盤,來支撐更高容量的數據。
在tidb中是shared-nothing架構,存儲層也是分離的:
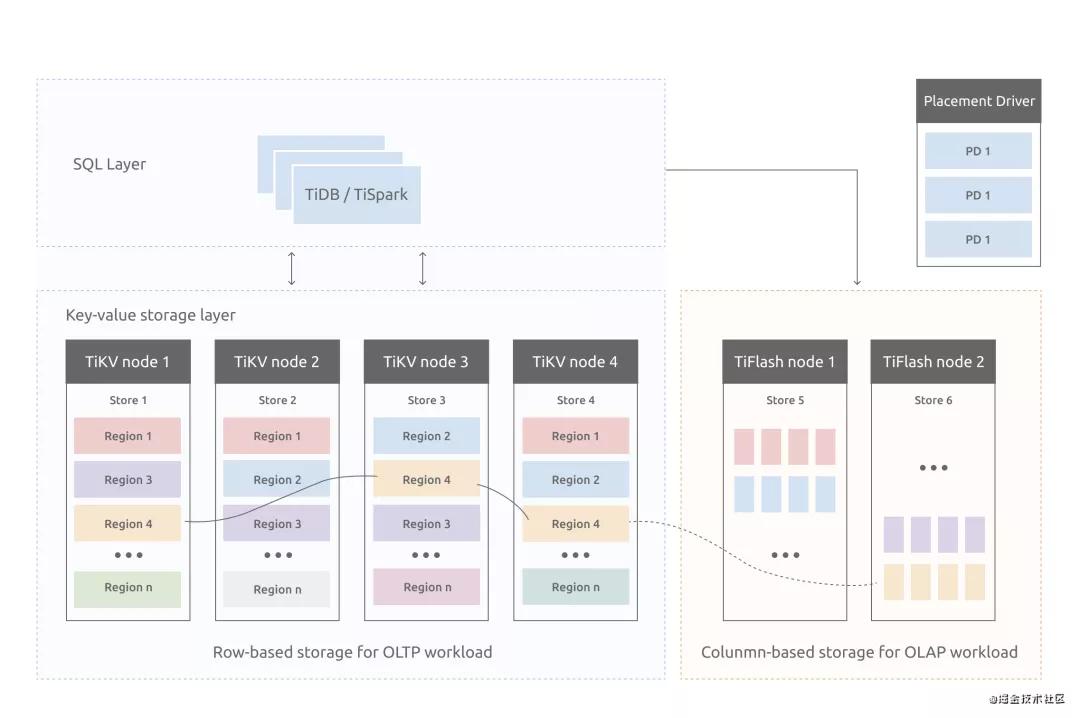
在每個tikv上會劃分出多個Region,這個也就是我們的基本存儲單位,大家見這個圖是不是發現這個架構似曾相識呢?
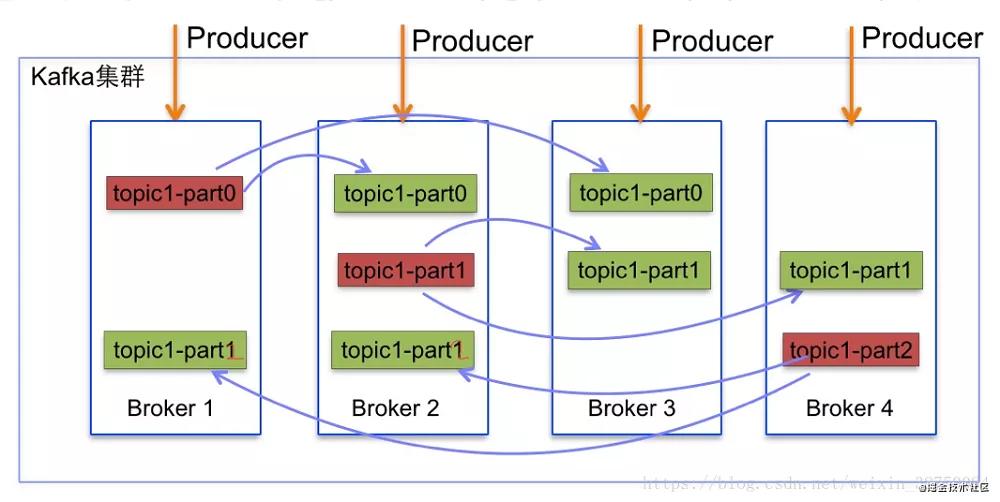
從上面看,region就對應這kafka下的partition,partition在kafka中的作用也是用來將topic的壓力打散到不同broker上,同樣的在tidb的region上也是一樣的,我們通過region為最小單位進行存儲。
再詳細介紹region之前先說一下存儲引擎為什么叫tikv呢?原因就是這個存儲引擎就是保存的就是一個key-value,你可以理解成java里面的hashmap,在tikv中沒有選擇自己研發如何將這個map數據去落地,而是通過一個非常優秀的kv存儲引擎——rocksdb去進行磁盤落地。RocksDB是Facebook開源的一個KV高性能單機數據庫,很多公司基于rocksdb做了很多優秀的存儲產品,后面也會詳細的寫一篇介紹rocksdb的文章。
rocksdb是一個單機的存儲引擎那么我們是需要保證數據在分布式環境下是不丟失的,在kafka中有其他partition的副本會不斷的拉取leader副本,并且通過一個ISR的機制去維護。在tikv中,直接使用的raft協議去做數據復制,每個數據變更都會落地為一條 Raft 日志,通過 Raft 的日志復制功能,將數據安全可靠地同步到復制組的每一個節點中。不過在實際寫入中,根據 Raft 的協議,只需要同步復制到多數節點,即可安全地認為數據寫入成功。
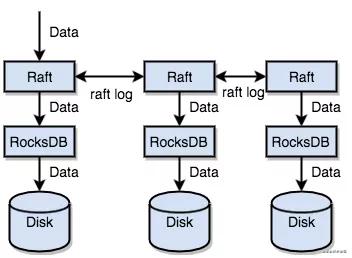
可以發現其實這里是寫的raft,通過raft接口再寫的rocksdb。
我們這里回到region,region還有一個partition不一樣的點在于,partition一般不會自動去擴容,在業務開發中他往往是一個恒定得值,而region不一樣,region的大小默認是96MB,再實際得業務中,我們的region的個數會隨著我們數據量而變多,當然如果我們的數據量變小,他也會自動合并。
如何確定某個數據是在哪個region上呢?一般來說有hash(key)和range(key)的方案,在tikv中選擇的是rangekey,因為對于region分裂是比較方便的,每一個region其實就是一個[StartKey,EndKey) 的表示:
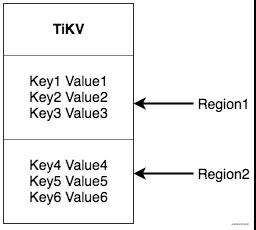
出現region的分裂的時候,只需要新增一個region,將老region的數據拿出一部分到新region, 譬如 [a, b) -> [a, ab) + [ab, b),如果是hash來做的話,他會將所有region的數據都會重新hash,所以在tikv中選的是range(key)的方式,合并也是一樣。
所以對于tidb來說無論是存儲層還是計算層,我們都可以無限擴展。
如何保證id唯一
在mysql中我們可以對于主鍵直接設置 AUTO_INCREMENT來達到自增列的效果,mysql是怎么做到自增的呢?
在MySQL5.7及之前的版本:InnoDB引擎的自增值,自增值保存在內存里,并沒有持久化。每次重啟后,第一次打開表的時候,都會去找自增值的最大值max(id),然后將max(id)+步長作為這個表當前的自增值。
在MySQL8.0版本:將自增值的變更記錄在了redo log中,重啟的時候依靠redo log恢復重啟之前的值。
在單機中這些都好做,但是在分布式數據庫中,我們就沒法保證id的唯一了,我之前有寫過相關的文章:如果再有人問你分布式ID,這篇文章丟給他。我們在使用sharding-jdbc的時候就是使用的文章介紹的leaf這個ID生成中間件,來完成ID生成。
在Tidb中同樣支持 AUTO_INCREMENT,實現的原理和leaf中的號段模式一樣,不能保證嚴格遞增,只能保證趨勢遞增,具體原理是:,對于每一個自增列,都使用一個全局可見的鍵值對用于記錄當前已分配的最大 ID。由于分布式環境下的節點通信存在一定開銷,為了避免寫請求放大的問題,每個 TiDB 節點在分配 ID 時,都申請一段 ID 作為緩存,用完之后再去取下一段,而不是每次分配都向存儲節點申請。
tidb還支持 AUTO_RANDOM,可以用于解決大批量寫數據入 TiDB 時因含有整型自增主鍵列的表而產生的熱點問題。因為region是有序的如果一段時間大量有序的數據產生有可能會在同一個region上,所以我們可以使用AUTO_RANDOM來將我們的主鍵數據打散。
如何保證事務
這里我們先回顧一下事務的四大特性ACID,我們來想想在mysql的innodb中這個是怎么做的呢?
- A:原子性,指一個事務中的所有操作,或者全部完成,或者全部不完成,不會結束在中間某個環節,原子性在mysql中我們是依賴redolog和undolog共同完成
- C:一致性,指在事務開始之前和結束以后,數據庫的完整性沒有被破壞。一致性是依靠其他幾個特性來保證的。
- I:隔離性,指數據庫允許多個并發事務同時對其數據進行讀寫和修改的能力。隔離性可以防止多個事務并發執行時由于交叉執行而導致數據的不一致,主要用于處理并發場景。mysql隔離性依靠的是鎖和mvcc,在mysql里面鎖的種類很豐富,mysql支持多種隔離性。
- D:持久性,事務處理結束后,對數據的修改就是永久的,即便系統故障也不會丟失,持久性是依靠redolog和mysql的刷盤機制。
在tidb中ACID是什么做到的呢?
- A:通過 Primary Key 所在 Region 的原子性來保證分布式事務的原子。
- C:TiDB 在寫入數據之前,會校驗數據的一致性,校驗通過才會寫入內存并返回成功。
- I:也是通過鎖和mvcc來完成隔離性,但是在tidb只支持RR(可重復讀)級別,RC隔離級別在4.0之后樂觀模式下也能支持。
- D:事務一旦提交成功,數據全部持久化存儲到 TiKV,并且還有多副本機制,如果發生宕機數據也不會丟失。
在mysql中的事務模型都是悲觀事務模型,而在tidb中事務模型提供了樂觀和悲觀兩種,怎么去理解悲觀和樂觀兩種模型呢:
- 悲觀模型:其實和名字一樣,只要在事務執行的時候認為每一條被你修改的數據都很大概率被其他事務修改(悲觀的看法)。在mysql里面,如果你在事務中你對某一行修改是會給你加上行鎖的,如果此時有其他事務想對這個數據進行修改,那么其他事務會被阻塞等待住。可以簡單理解成邊執行邊檢測沖突。
- 樂觀模型:我們認為我們修改的數據很大概率不會和其他事務產生沖突,所以不需要邊執行邊進行沖突檢測,而是最后提交的時候進行沖突檢測。如果沖突比較少這樣就可以獲得較高的性能。
在tidb中是如何實現這兩種模式的呢?因為我們是分布式數據庫,兩階段提交一般是分布式事務的通用解決方案,之前我寫過很多分布式事務相關的文章大家可以自行查閱一下。
樂觀模式
tidb同樣使用兩階段提交來保證分布式事務的原子性,分為 Prewrite 和 Commit 兩個階段:
- Prewrite:對事務修改的每個 Key 檢測沖突并寫入 lock 防止其他事務修改。對于每個事務,TiDB 會從涉及到改動的所有 Key 中選中一個作為當前事務的 Primary Key,事務提交或回滾都需要先修改 Primary Key,以它的提交與否作為整個事務執行結果的標識。
- Commit:Prewrite 全部成功后,先同步提交 Primary Key,成功后事務提交成功,其他 Secondary Keys 會異步提交。
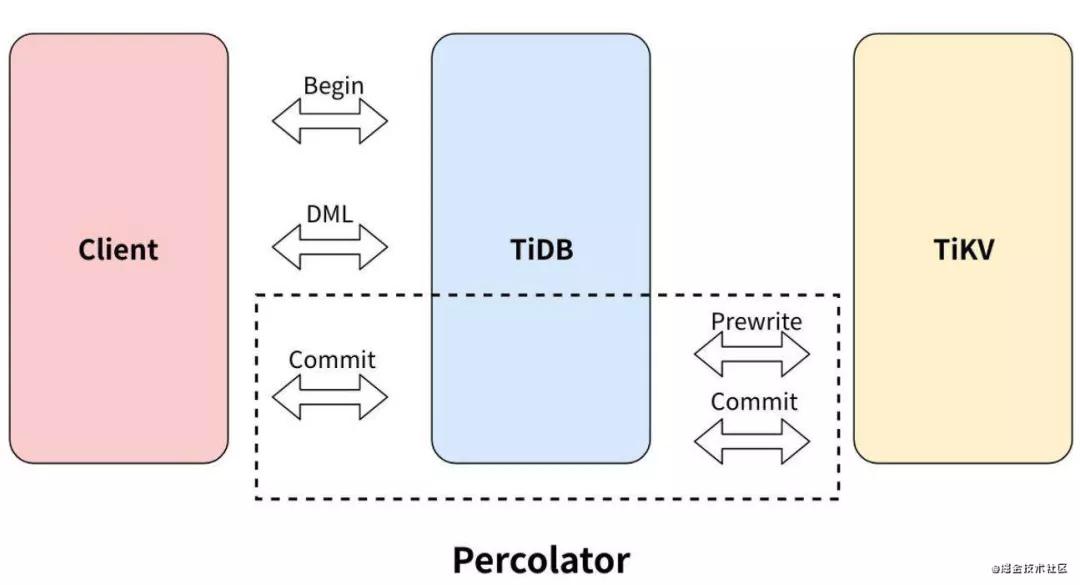
整個事務步驟如下:
- Step 1: 客戶端開啟事務,類似我們在mysql里面的 begintrasaction;
- Step 2: TiDB 向 PD 獲取全局時間,可以知道這個事務的全局順序,用于后續mvcc的處理
- Step 3: 發起DML,比如update xxx; 這個時候不會有沖突檢測,只會在tidb內存中進行保存;
- Step 4: 提交事務,類似我們在mysql里面的commit,這個時候tidb會在commit階段完成兩階段提交,先進行prewrite 各種加鎖檢測之后如果沒有問題再進行commit。這里舉個例子:
- begin; //step1
- insert into xx; // step3
- update xx; // step3
- update xx; // step3
- commit;// step4
在上面的例子中如果是悲觀模式step3的時候就會進行加鎖檢測了,樂觀模式下所有的工作都放在了commit中,所以會出現commit出現異常的狀態,所以我們使用樂觀模式需要更好的處理commit階段的異常行為,這和我們一般的編程不一樣。但是如果數據的競爭不是太激烈的話是可以使用樂觀模式來提升性能的。
悲觀模式

悲觀模式把lock進行了提前,每個 DML 都會加悲觀鎖,鎖寫到 TiKV 里,同樣會通過 raft 同步,在加悲觀鎖時檢查各種約束,如 Write Conflict、key 唯一性約束等。
悲觀事務下能保證我們的commit成功,這種模式比較符合我們的編程模式,所以tidb默認的模式也是悲觀模式。
如何做的索引查詢
為什么我會想到這個索引查詢這個問題呢?當時是在看到了rocksdb是tidb的底層存儲介質之后,我想到了在innodb中我們的索引是B+樹,如果tidb的索引是b+樹的話,那么rocksdb應該怎么去構造呢?
事實上在tidb中的索引也是使用的k-v形式去做的,我們先看看對于每一行的數據是怎么存儲的:
- 為了保證同一個表的數據放在一起,方便查找,TiDB 會為每個表分配一個表 ID,用 TableID 表示。表 ID 是一個整數,在整個集群內唯一。
- TiDB 會為表中每行數據分配一個行 ID,用 RowID 表示。行 ID 也是一個整數,在表內唯一。對于行 ID,TiDB 做了一個小優化,如果某個表有整數型的主鍵,TiDB 會使用主鍵的值當做這一行數據的行 ID。每行數據按照如下規則編碼成 (Key, Value) 鍵值對:
- Key: tablePrefix{TableID}_recordPrefixSep{RowID}
- Value: [col1, col2, col3, col4]
假定我們的tablePrefix是常量字符t,recordPrefixSep是常量字符r,我們的tableId是1,rowID在這里是我們的主鍵假定是100,如果有一個用戶表的數據,如下:
- Key: t1_r100
- Value: [100, "zhangsan"]
如果我們的主鍵為整數的情況下,那么上面也可以看作是我們的主鍵索引,如果我們的主鍵不為整型或者說在唯一索引的情況下,規則編碼如下:
- Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
- Value: RowID
indexId是tidb為每個索引分配的ID,所以上面那個情況下一個indexedColumnsValue只能對應一條數據滿足唯一性,如果是非唯一索引,我們可以有:
- Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue_rowId
- Value: null
這樣一個indexedColumnsValue就可以有多行數據,所以其實我們region中的數據的索引并不會和region的數據再一起,而是有自己的region分片,同樣的我們查詢數據的時候需要依靠我們的tidb-server分析出來我們應該用什么樣的索引,先根據索引數據查詢出來rowId再根據rowId查詢出來我們對應的數據。
總結
不管是tidb還是分布式數據庫,要學習的知識還有非常的多,上面只是對tidb做了一些粗解的分析,如果大家要學習可以看看下面的一些資料:
pingcap文檔: https://docs.pingcap.com, ping cap的文檔是我見過做得算是比較頂級的文檔了,他可以說不叫做文檔,其實是一個文章知識庫,我的文章很多圖和內容都是借鑒而來。
極客時間《分布式數據庫》:極客時間有一個課叫分布式數據庫,不會局限于講tidb,主要講解的是分布式數據庫的各種知識,并且會列舉市場上的分布式數據庫做對比。
《數據庫系統內幕》:豆瓣評分8.5,這本書講解了很多數據庫理論基本知識,不論上分布式數據庫還是單機數據庫都會使用到,稍微有一點難懂,但是還是會有不少收獲。