干貨|一文讀懂阿里云數據庫 Autoscaling 是如何工作的
1. 前言
Gartner預測到2023年,全球3/4的數據庫都會跑在云上,云原生數據庫最大的優勢之一便是天然擁有云計算的彈性能力,數據庫可以像水、電、煤一樣隨取隨用,而Autosaling能力便是彈性的極致體現。數據庫的Autoscaling能力是指數據庫處于業務高峰期時,自動擴容增加實例資源;在業務負載回落時,自動釋放資源以降低成本。
業界的云廠商AWS與Azure在其部分云數據庫上實現了Autoscaling能力,阿里云數據庫同樣實現了其特有的Autosaling能力,該能力由數據庫內核、管控及DAS(數據庫自治服務)團隊共同構建,內核及管控團隊提供了數據庫Autoscaling的基礎能力,DAS則負責性能數據的監測、Scaling決策算法的實現及Scaling結果的呈現。DAS(Database Autonomy Service)是一種基于機器學習和專家經驗實現數據庫自感知、自修復、自優化、自運維及自安全的云服務,幫助用戶消除數據庫管理的復雜性及人工操作引發的服務故障,有效保障數據庫服務的穩定、安全及高效。其解決方案架構如圖1.所示,Autoscaling/Serverless能力在其中屬于“自運維”的部分。
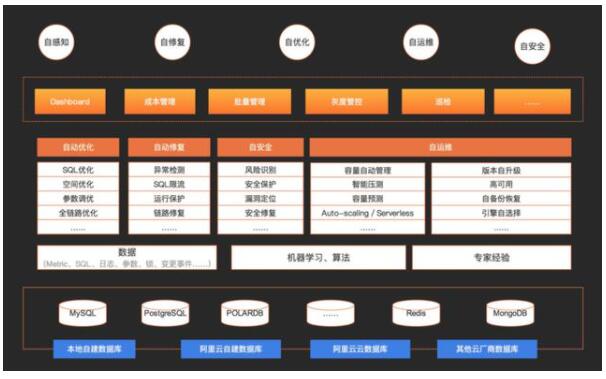
圖1. DAS的解決方案架構
2. Autosaling的工作流程
數據庫Autoscaling整體的工作流程可定義為如圖2.所示的三個階段,即“When:何時觸發Scaling”、“How:采取哪種方式Scaling”及“What:Scaling到哪個規格”。
何時觸發Scaling即確定數據庫實例的擴容與回縮的時機,通常的做法是通過觀測數據庫實例的性能指標,在實例的負載高峰期執行擴容操作、在負載回落時執行回縮操作,這是常見的Reative被動式觸發方式,除此之外我們還實現了基于預測的Proactive主動式觸發方式。關于觸發時機在2.1章節會進行詳細的介紹。
Scaling的方式通常有ScaleOut(水平擴縮容)與ScaleUp(垂直擴縮容)兩種形式。以分布式數據庫PolarDB為例,ScaleOut的實現形式是增加只讀節點的數量,例如由2個只讀節點增加至4個只讀節點,該方式主要適用于實例負載以讀流量占主導的情形;ScaleUp的實現形式是升級實例的CPU與內存規格,如由2核4GB升級至8核16GB,該方式主要適用于實例負載以寫流量占主導的情形。關于Scaling方式在2.2章節會進行詳細的介紹。
在擴容方式確定后需要選擇合適的規格,來使實例的負載降至合理的水位。例如對于ScaleOut方式,需要確定增加多少個實例節點;對于ScaleUp方式,需要確定升級實例的CPU核數與內存,以確定升級至哪種實例規格。關于擴容規格的選擇在2.3章節會進行詳細的介紹。
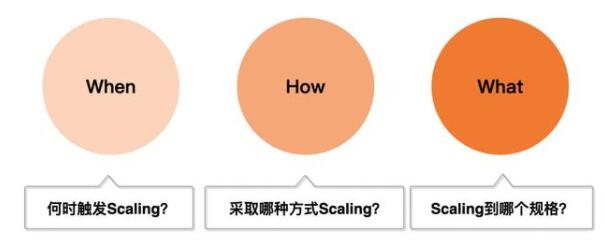
圖2. Autoscaling的工作流程圖示
2.1 Autoscaling的觸發時機
2.1.1 Reactive被動式觸發(基于觀察)
基于觀察的Reactive被動式觸發是當前Autoscaling主要的實現形式,由用戶為不同的實例設置不同的擴、縮容觸發條件。對于計算性能擴容,用戶可以通過設置觸發CPU閾值、觀測窗口長度、規格上限、只讀節點數量上限及靜默期等選項來配置符合業務負載的觸發條件;對于存儲空間擴容,用戶可以通過設置空間的擴容觸發閾值及擴容上限來滿足實例業務的增長,并避免磁盤資源的浪費。被動式觸發的配置選項在3.2章節會進行詳細的展示。
Reactive被動式觸發的優點是實現相對容易、用戶接受度高,但如圖3.所示,被動式觸發也存在其缺點,通常Scaling操作在達到用戶配置的觀測條件后才會真正執行,而Scaling操作的執行也需要一定的時間,在這段時間內用戶的實例可能已經處于高負載較長時間,這會在一定程度上影響用戶業務的穩定性。
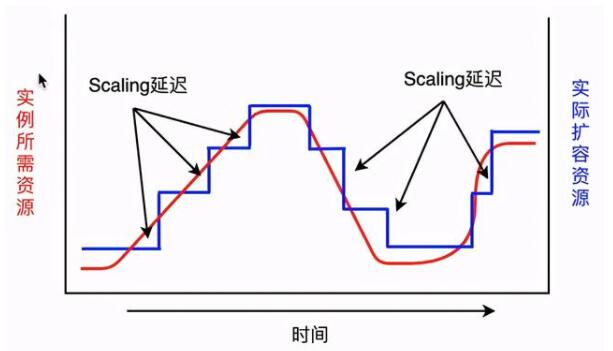
圖4. 主動式觸發的擴容資源對比圖示
我們同樣在RDS-MySQL的存儲空間擴容里實現了基于預測的方式,基于實例過去一段時間的磁盤使用量指標,使用機器學習算法預測出實例在接下來的一段時間內存儲空間會達到的最大值,并會根據該預測值進行擴容容量的選擇,可以避免實例空間快速增長帶來的影響。
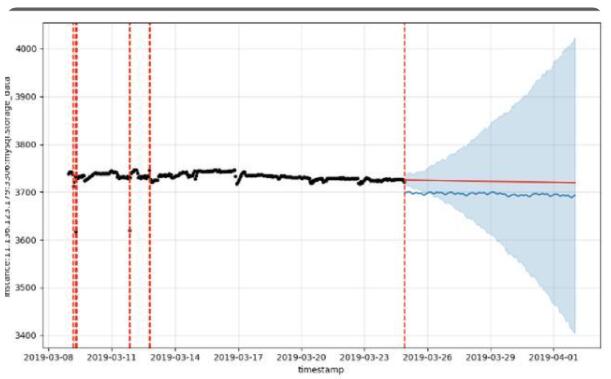
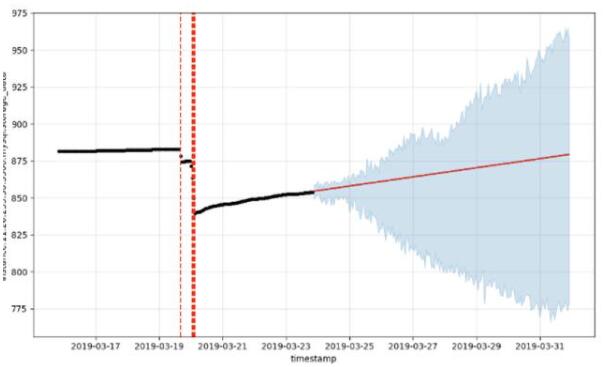
圖5. 基于磁盤使用量趨勢的預測
2.2 Autoscaling的方式決策
DAS的Autoscaling方式有ScaleOut與ScaleUp兩種,在給出Scaling方案的同時也會結合Workload全局決策分析模塊給出更多的診斷建議(如SQL自動限流、SQL索引建議等等)。如圖6.所示是Scaling方式的決策示意圖,該示意圖以PolarDB數據庫作為示例。PolarDB數據庫采用的是計算存儲分離的一寫多讀的分布式集群架構,一個集群包含一個主節點和多個只讀節點,主節點處理讀寫請求,只讀節點僅處理讀請求。圖6.所示的“性能數據監測模塊”會不斷的監測集群的各項性能指標,并判斷當前時刻的實例負載是否滿足2.1章節所述的Autoscaling觸發條件,當滿足觸發條件時,會進入到圖6.中的Workload分析模塊,該模塊會對實例當前的Workload進行分析,通過實例的會話數量、QPS、CPU使用率、鎖等指標來判斷實例處于高負載的原因,若判斷實例是由于死鎖、大量慢SQL或大事務等原因導致的高負載,則在推薦Autoscaling建議的同時也會推出SQL限流或SQL優化建議,使實例迅速故障自愈以降低風險。
在Autoscaling方式的決策生成模塊,會判斷采取何種Scaling方式更有效。以PolarDB數據庫為例,該模塊會通過實例的性能指標以及實例的主庫保護、事務拆分、系統語句、聚合函數或自定義集群等特征來判斷集群當前的負載分布,若判斷實例當前以讀流量占主導,則會執行ScaleOut操作增加集群的只讀節點數量;若判斷實例當前以寫流量占主導,則會執行ScaleUp操作來升級集群的規格。ScaleOut與ScaleUp決策的選擇是一個很復雜的問題,除了考慮實例當前的負載分布外,還需要考慮到用戶設置的擴容規格上限及只讀節點數量上限,為此我們也引入了一個效果追蹤與決策反饋模塊,在每次決策判斷時,會分析該實例歷史上的擴容方式及擴容效果,以此來對當前的Scaling方式選擇算法進行一定的調整。
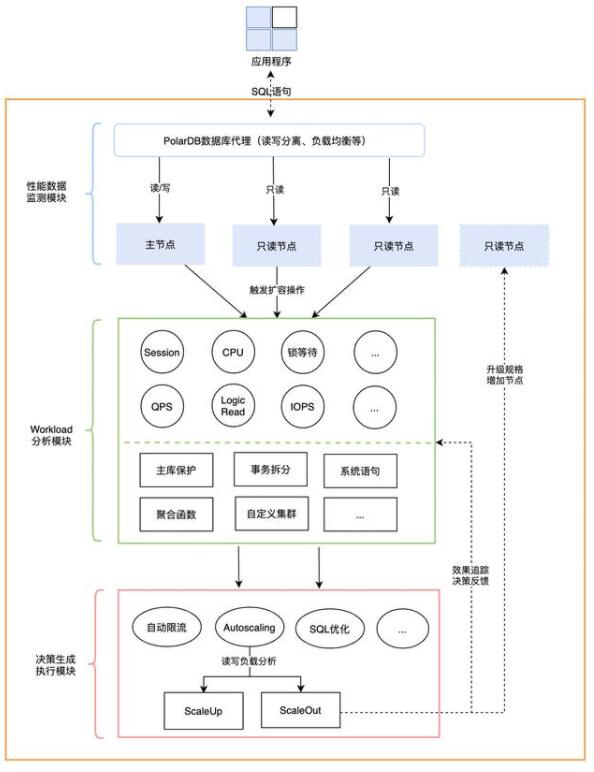
圖6. PolarDB的Scaling方式決策示意圖
2.3 Autoscaling的規格選擇
2.3.1 ScaleUp決策算法
ScaleUp決策算法是指當確定對數據庫實例執行ScaleUp操作時,根據實例的workload負載及實例元數據等信息,為當前實例選擇合適的規格參數,以使實例當前的workload達到給定的約束。最開始DAS Autoscaling的ScaleUp決策算法基于規則實現,以PolarDB數據庫為例,PolarDB集群當前有8種實例規格,采用基于規則的決策算法在前期足夠用;但同時我們也探索了基于機器學習/深度學習的分類模型,因為隨著數據庫技術最終迭代至Serverless狀態,數據庫的可用規格數量會非常龐大,分類算法在這種場景下會有很大的用武之地。如圖7.及圖8.所示,我們當前實現了基于性能數據的數據庫規格離線訓練模型及實時推薦模型,通過對自定義CPU使用率的范圍標注,參考DAS之前落地的AutoTune自動調參算法,在標注數據集進行模型分類,并通過實現的proxy流量轉發工具進行驗證,當前的分類算法已經取得了超過80%的準確率。
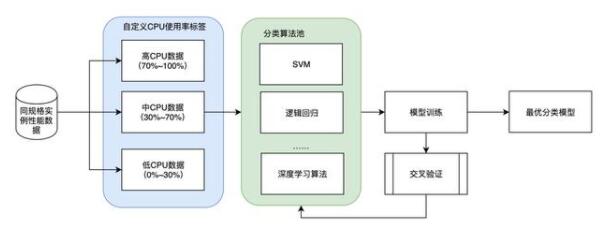
圖7. 基于性能數據的數據庫規格ScaleUp模型離線訓練示意圖
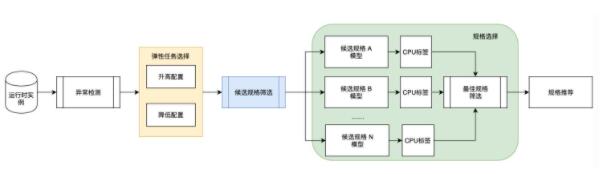
圖8. 基于性能數據的數據庫規格ScaleUp實時推薦方法示意圖
2.3.2 ScaleOut決策算法
ScaleOut決策算法與ScaleUp決策算法的思路類似,本質問題是確定增加多少個只讀節點,能使實例當前的workload負載降至合理的水位。在ScaleOut決策算法里,我們同樣實現了基于規則的與基于分類的算法,分類算法的思想與2.3.1章節里描述的基本類似,基于規則的算法思想則如圖9.所示,首先我們需要確定與讀流量最相關的指標,這里選取的是com_select、qps及rows_read指標,s_i表示第i個節點讀相關指標的表征值,c_i表示第i個節點的目標約束表征值(通常使用CPU使用率、RT等直接反應業務性能的指標),f指目標函數,算法的目標便是確定增加多少個只讀節點X,能使整個集群的負載降至f函數確定的范圍。該計算方法明確且有效,算法上線后,以變配后集群的CPU負載是否降至合理水位作為評估條件,算法的準確率達到了85%以上,在確定采取ScaleOut變配方式后,ScaleOut決策算法新增的只讀節點基本都能處于“恰好飽和”的工作負載,能夠有效的提升數據庫實例的吞吐。
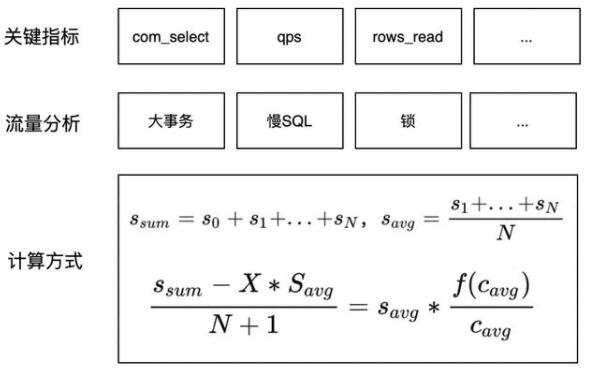
圖9. 基于性能數據的數據庫節點數量ScaleOut推薦算法示意圖
3. 落地
3.1 實現架構
Autoscaling能力集成在DAS服務里,整個服務涉及異常檢測、全局決策、Autoscaling服務、底層管控執行多個模塊,如圖10.所示是DAS Autoscaling的服務能力架構。異常檢測模塊是DAS所有診斷優化服務(Autoscaling、SQL限流、SQL優化、空間優化等)的入口,該模塊會7*24小時對監控指標、SQL、鎖、日志及運維事件等進行實時檢測,并會基于AI的算法對其中的趨勢如Spike、Seasonaliy、Trend及Meanshift等進行預測及分析;DAS的全局決策模塊會根據實例當前的workload負載給出最佳的診斷建議;當由全局決策模塊確定執行Autoscaling操作時,則會進入到第2章節介紹的Autoscaling工作流程,最終通過數據庫底層的管控服務來實現實例的擴、縮容。
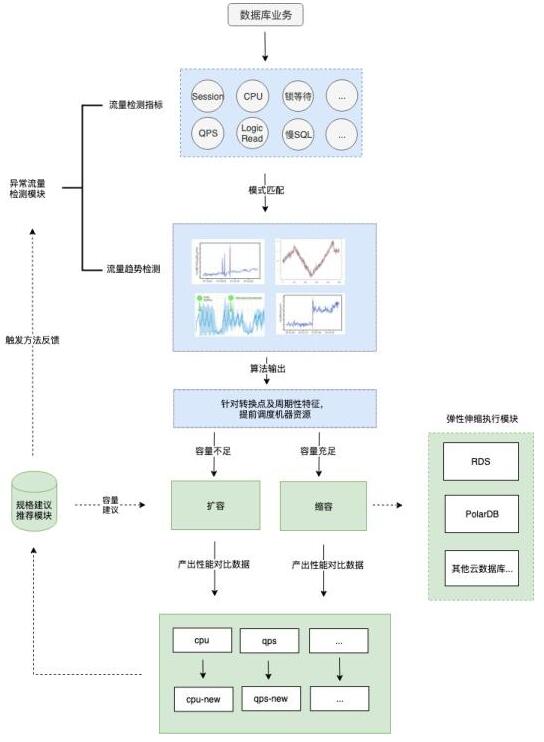
圖10. DAS及AutoScaling的服務能力架構
3.2 產品方案
本章節將介紹Autoscaling功能在DAS里的開啟方式。如圖11.所示是DAS的阿里云官網產品首頁,在該界面可以看到DAS提供的所有功能,如“實例監控”、“請求分析”、“智能壓測”等等,點擊“實例監控”選項可以查看用戶接入的所有數據庫實例。我們點擊具體的實例id鏈接并選擇“自治中心”選項,可以看到如圖12.及圖13.所示的PolarDB自動擴、縮容設置及RDS-MySQL自動擴容設置,對于PolarDB實例,用戶可以設置擴容規格上限、只讀節點數量上限、觀測窗口及靜默期等選項,對于RDS-MySQL實例,用戶可以設置觸發閾值、規格上限及存儲容量上限等選項。
圖11. DAS產品首頁
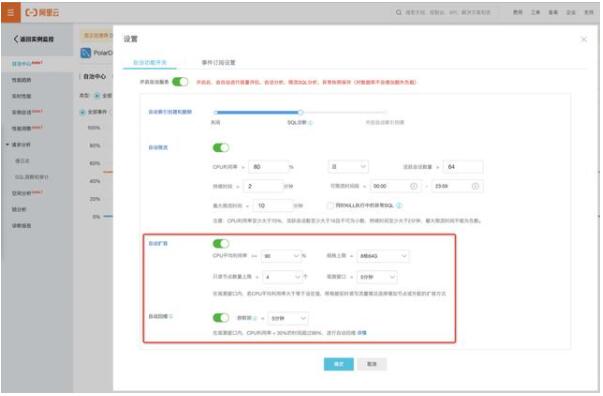
圖12. PolarDB自動擴、縮容設置圖示
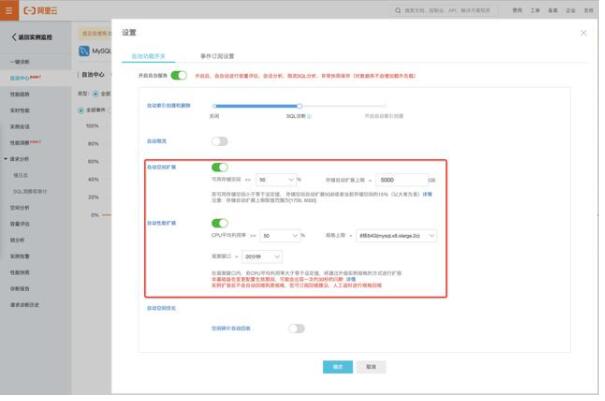
圖13. RDS-MySQL自動擴、縮容設置圖示
3.3 效果案例
本章節將介紹兩個具體的線上案例。如圖14.所示為線上PolarDB實例的計算規格Autoscaling觸發示意圖,在05:00-07:00的時間段,實例的負載慢慢上升,最終CPU使用率超過了80%,在07:00時觸發了自動擴容操作,后臺的Autoscaling服務判斷實例當前讀流量占主導,于是執行了ScaleOut操作,為集群增加了兩個只讀節點,通過圖示可以看到,增加節點后集群的負載明顯下降,CPU使用率降至了50%左右;在之后的2個小時里,實例的業務流量繼續增加,導致實例負載繼續在緩慢上升,于是在09:00的時候再次達到了擴容的觸發條件,此時后臺服務判斷實例當前寫流量占主導,于是執行了ScaleUp操作,將集群的規格由4核8GB升級到8核16GB,由圖示可以看到規格升級后實例的負載趨于穩定,并維持了近17個小時,之后實例的負載下降并觸發了自動回縮操作,后臺Autoscaling服務將實例的規格由8核16GB降至4核8GB,并減少了兩個只讀節點。Autoscaing服務在后臺會自動運行,無需人工干預,在負載高峰期擴容、在負載低谷時回縮,提升業務穩定性的同時降低了用戶的成本。
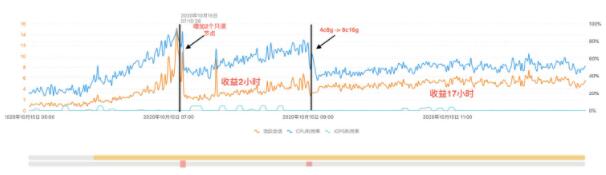
圖14. 線上PolarDB 水平擴容、垂直擴容效果示意圖
如圖15.所示為線上RDS-MySQL實例的存儲空間自動擴容示意圖,左側圖表示實例在近3個小時內觸發了3次磁盤空間擴容操作、累計擴容近300GB,右側是磁盤空間的增長示意圖,可以發現在實例存儲空間迅速增長時,空間自動擴容操作能夠無縫執行,真正做到了隨用隨取,在避免實例空間打滿的同時節省了用戶的成本。
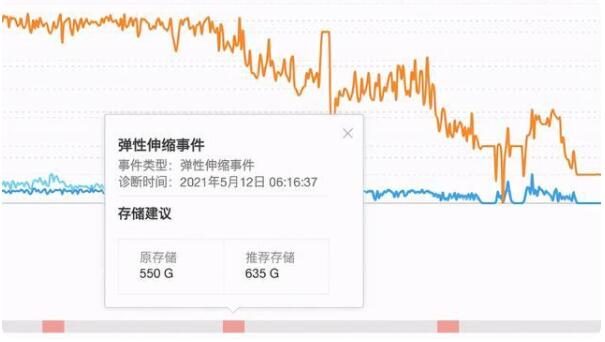
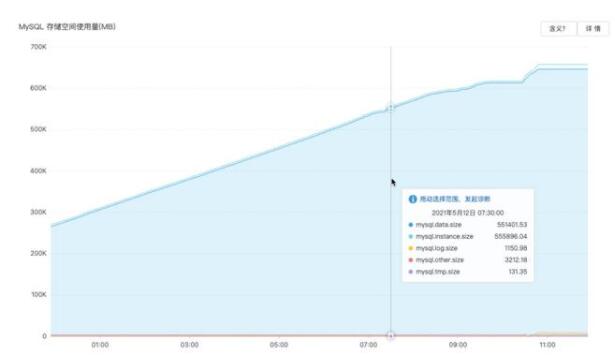
圖15. 線上RDS-MySQL空間擴容效果示意圖
原文鏈接:http://click.aliyun.com/m/1000282741/