













那些年,我們一起做過的性能優化
一直以來,性能都是技術層面不可避開的話題,尤其在中大型復雜項目中。猶如汽車整車性能,追求極速的同時,還要保障舒適性和實用性,而在汽車制造的每個環節、零件整合情況、發動機調校等等,都會最終影響用戶體感以及商業達成,如下圖性能對收益的影響。

性能優化是一個體系化、整體性的事情,印刻在項目開發環節的各個細節中,也是體現技術深度的大的戰場。下面我將以Quick BI的復雜系統為背景,深扒整個性能優化的思路和手段,以及體系化的思考。
如何定位性能問題?

通常來講,我們對動畫的幀率是比較敏感的(16ms內),但如果出現性能問題,我們的實際體感可能就一個字:“慢”,但這并不能為我們解決問題提供任何幫助,由此我們需要剖析這個字背后的整條鏈路。
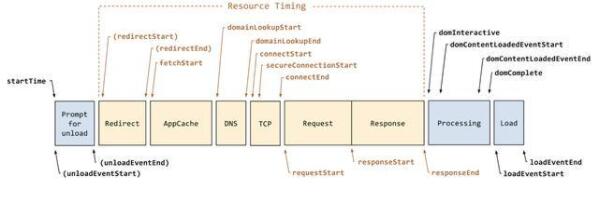
上圖是瀏覽器通用的處理流程,結合我們的場景,我這里抽象成以下幾個步驟:
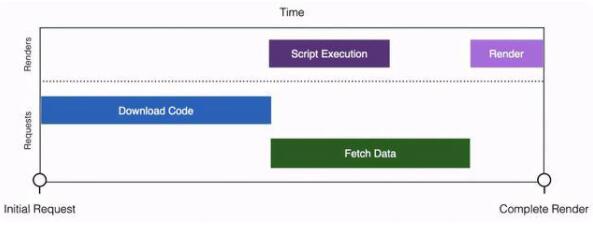
可以看出,主要的耗時階段分為兩個:
階段一:資源包下載(Download Code)
階段二:執行 & 取數(Script Execution & Fetch Data)
如何深入這兩個階段,我們一般會用以下幾個主要的工具來分析:
Network
首先我們要使用的一個工具是Chrome的Network,它能幫助我們初步定位瓶頸所在的環節:
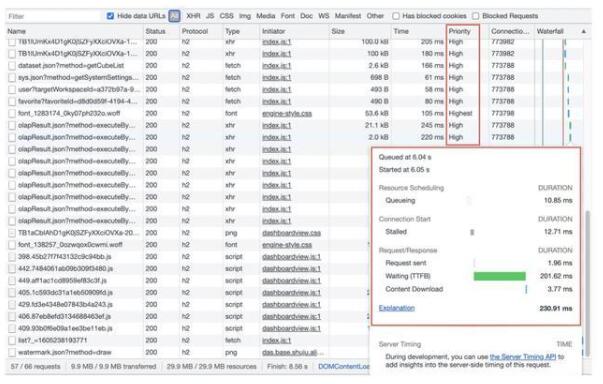
如圖示例,在Network中可以一目了然看到整個頁面的:加載時間(Finish)、加載資源大小、請求數量、每個請求耗時及耗時點、資源優先級等等。上面示例可以很明顯看出:整個頁面加載的資源很大,接近了30MB。
Coverage(代碼覆蓋率)
對于復雜的前端工程,其工程構建的產物一般會存在冗余甚至未被使用的情況,這些無效加載的代碼可以通過Coverage工具來實時分析:
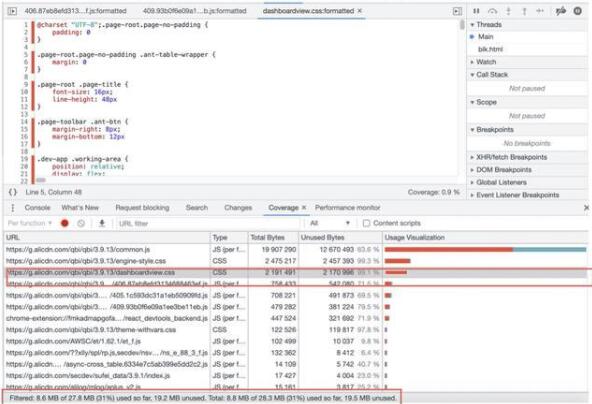
如上圖示例可以看到:整個頁面28.3MB,其中19.5MB都未被使用(執行),其中engine-style.css文件的使用率只有不到0.7%
資源大圖
剛才我們已經知道前端資源的利用率非常低,那么具體是哪些無效代碼被引入進來了?這時候我們要借助webpack-bundle-analyzer來分析整個的構建產物(產物stats可以通過webpack --profile --json=stats.json輸出):

如上例,結合我們當前業務可以看到構建產物的問題:
第一,初始包過大(common.js)
第二,存在多個重復包(momentjs等)
第三,依賴的第三方包體積過大
模塊依賴關系
有了資源構建大圖,我們也大概知道了可優化的點,但在一個系統中,成百上千的模塊一般都是通過互相引用的方式組織在一起,打包工具再通過依賴關系將其構建在一起(比如打成common.js單個文件),想要直接移除掉某個模塊代碼或依賴可能并非易事,由此我們可能需要一定程度抽絲剝繭,借助工具理清系統中模塊的依賴關系,再通過調整依賴或加載方式來作優化:
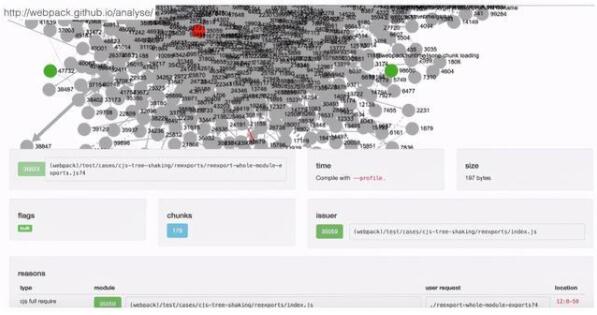
上圖我們使用到的是webpack官方的analyse工具(其他工具還有:webpack-xray,Madge),只需要將資源大圖stats.json上傳即可得到整個依賴關系大圖
Performance
前面講到的都是和資源加載相關的工具,那么在分析 “執行 & 取數” 環節我們使用什么,Chrome提供了非常強大的工具:Performance:
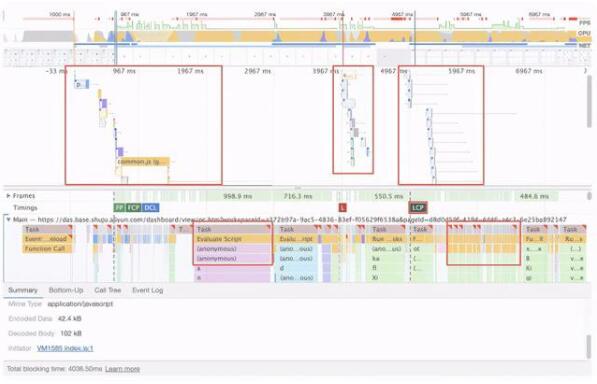
如上圖示例,我們可以至少發現幾個點:主流程串化、長任務、高頻任務。
如何優化性能?
結合剛才提到的分析工具,剛才提到的 “資源包下載”、“執行 & 取數” 兩個大的階段我們基本上已經覆蓋到,其根本問題和解法也在不斷的分析中逐步有了思路,這里我將結合我們這里的場景,給出一些不錯的優化思路和效果
大包按需加載
要知道,前端工程構建打包(如webpack)一般是從entry出發,去尋找整棵依賴樹(直接依賴),從而根據這棵樹產出多個js和css文件bundle或trunk,而一個模塊一旦出現在依賴樹中,那么當頁面加載entry的時候,同時也會加載該模塊。
所以我們的思路是打破這種直接依賴,針對末端的模塊改用異步依賴方式,如下:

將同步的import { Marker } from '@antv/l7'改為異步,這樣在構建時,被依賴的Marker會形成一個chunk,僅在此段代碼執行時(按需),該thunk才被加載,從而減少了首屏包的體積。
然而上面方案會存在一個問題,構建會將整個@antv/l7作為一個chunk,而非Marker部分代碼,導致該chunk的TreeShaking失效,體積很大。我們可以使用構建分片方式解決:

如上,先創建Marker的分片文件,使之具備TreeShaking的能力,再在此基礎上作異步引入。
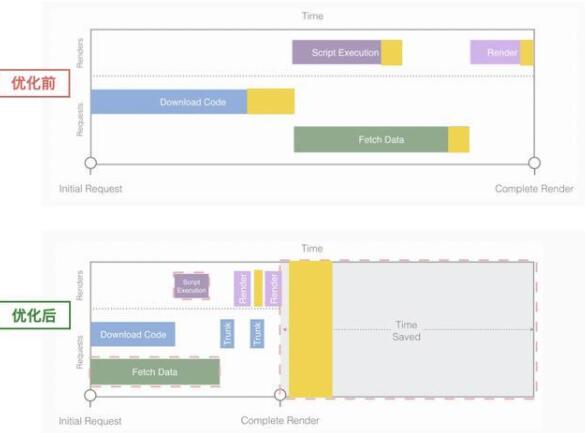
下方是我們優化后的流程對比結果:
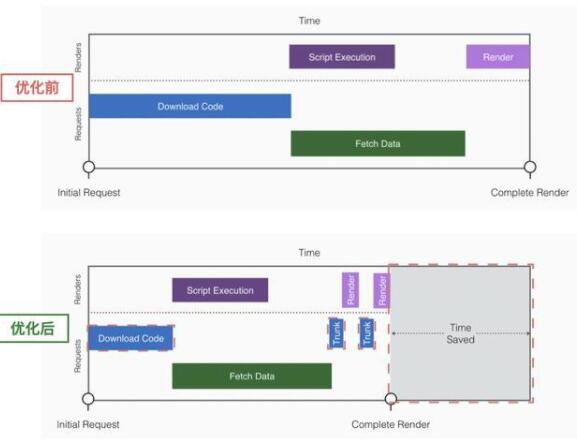
這一步,我們通過按需拆包,異步加載,節省了資源下載時間和部分執行時間
資源預加載
其實我們在分析階段已經發現一個“主流程串化”的問題,js的執行是單線程,但瀏覽器實際上是多線程運行的,這里面就包括異步請求(fetch等),所以我們進一步的思路是把取數(Fetch Data)與資源下載通過多線程并行。
按照當前現狀,接口取數的邏輯一般是耦合在業務邏輯或數據處理邏輯中的,所以解耦(與UI、業務模塊等解耦)的步驟必不可少,將純粹的fetch請求(及少量處理邏輯)剝離出來,放到優先級更高的階段來發起請求。那么放到什么地方呢?我們知道,瀏覽器對資源的處理是有優先級的,正常按如下順序:
HTML/CSS/FONT
Preload/SCRIPT/XHR
Image/Audio/Video
Prefetch
要做到資源拉取 和 發起取數并行,就有必要把取數提前到第1優先級(HTML解析完畢后立即執行,而非等待SCRIPT標簽資源加載執行過程中發起請求),我們的流程會變成如下:
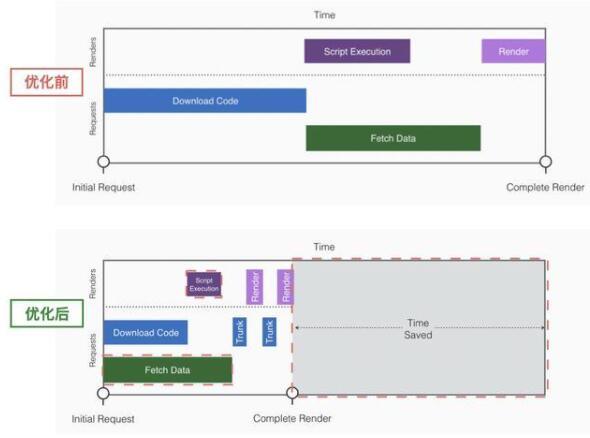
需要特別注意一點:由于JS的執行是串行,發起取數的那段邏輯必須要先于主流程邏輯執行,并且不能放到nextTick(如使用setTimeout(() => doFetch())),否則主流程會一直占用CPU時間使得請求無法發出
主動任務調度
瀏覽器對資源也有優先級策略,但它并不知道業務層面的我們,到底想要哪些資源先加載/執行,哪些資源后加載/執行,所以我們跳出來看,若把整個業務層面的資源加載+執行/取數流程拆成一個一個小的任務,這些任務全權由我們自己來控制其:打包粒度、加載時機、執行時機,是不是意味著能最大化利用CPU時間和網絡資源了?
答案是肯定的,不過一般對于簡單的項目,瀏覽器本身的調度優先級策略已經足夠滿足需要,但如果針對大型復雜項目,要做的相對極致的優化,就有必要引入“自定義任務調度”方案了。
以Quick BI為例,我們的前期目標是:讓首屏主要內容展現更加快速。那么從資源加載、代碼執行、取數層面是應該根據我們業務優先級作CPU/網絡分配的,比如:我希望“卡片的下拉菜單”,在首屏主要內容展示完畢后或CPU空閑時,才開始加載(即降低優先級,更甚至在用戶鼠標移入卡片中時,又希望它提高優先級立即開始加載并展示)。如下:

這里我們封裝了一個任務調度器,其目的是可以聲明一段邏輯,在其某個依賴(Promise)完成后開始執行。我們的流程圖變化如下:
黃色區塊代表 作優先級降級處理的部分模塊,其幫助減少了整個首屏時間
TreeShaking
上面講方法大多從優先級出發,其實在前端工程化日益復雜的時代(中大型項目已超幾十萬行代碼),誕生了一個較為智能的優化方案用于減少包大小,其思想很簡單:工具化分析依賴關系,將沒有被引用到的代碼從最終產物中剔除掉。
聽起來很酷,實際用起來也非常不錯,但這里想講一些很多其官網也不會提到的點 --- TreeShaking經常失效的情況:
副作用
副作用(Side Effects)通常表達的是對全局(如window對象等)或環境會產生影響的代碼。

如圖示例,b代碼看似未被使用,但其文件中存在console.log(b(1))這樣的代碼,webpack等打包工具不敢輕易移除它,所以它會被照常打入。
解決方法
在package.json 或 webpack配置中明確指定哪些代碼具備副作用(例如sideEffects: [“**/*.css”]),無副作用的代碼將被移除
IIFE類代碼
IIFE即會被立即執行的函數表達式(Immediately invoked function expression)

如圖,這類型的代碼,會導致TreeShaking失效
解決方法
三個原則:
[避免]立即執行的函數調用
[避免]立即執行的new操作
[避免]立即影響全局的代碼
懶加載
我們在“按需加載”處提到過異步import來做拆包會導致TreeShaking失效,這里再進一步說明一下另外一個case:

如圖,由于index.ts同步import了bar.ts中的sharedStr,然后在某個地方,又同時異步import('./bar'),這種情況下,會同時導致兩個問題:
TreeShaking失效(unusedStr會被打入)
異步懶加載失效(bar.ts會和index.ts打入到一起)
當代碼量達到一定量級,N個人協同開發就很容易出現這個問題
解決方法
[避免]同步和異步import同個文件
按需策略(Lazy)
其實前面有講到一些按需加載的方案,這里我們適當延伸一下:既然資源包的加載可以做到按需,是否某個組件的渲染可以按需?某個對象實例的使用可以按需?某個數據緩存的生成也可以按需?
懶組件(LazyComponent)
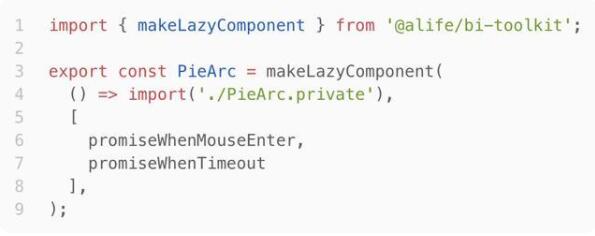
如圖,PieArc.private.ts對應一個復雜的React組件,PieArc通過makeLazyComponent封裝成默認懶加載的組件,只有在代碼執行到此處時,組件才會加載并執行。甚至,還可以通過第二個參數(deps)申明依賴,待依賴(promise)完畢時,才加載和執行。
懶緩存(LazyCache)
懶緩存用于這種場景:需要在任何地方使用到數據流(或其他可訂閱數據)中的某個數據經過轉換后的結果,且僅在使用的那一刻才進行轉換

懶對象(LazyObject)
懶對象意即該對象只有在被使用的時候(屬性/方法被訪問、修改、刪除等等),才會被實例化

如圖,globalRecorder被引入時,其并未實例化,僅當調用globalRecorder.record()時進行實例化
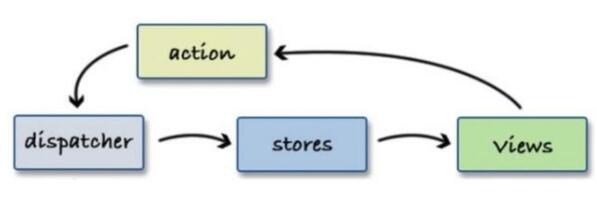
數據流:節流渲染
中大型項目中為了方便狀態管理,通常會使用到數據流的方案,如下流程:
store中存儲的數據通常偏原子化,粒度非常小,比如state中有:a、b、c ...等N個原子屬性,某個組件依賴這N個屬性來作UI渲染,假設N個屬性會在不同的ACTION下被改變,且這些改變均在16ms內發生,那么若N=20,則16ms內(1幀)會有20次View更新:
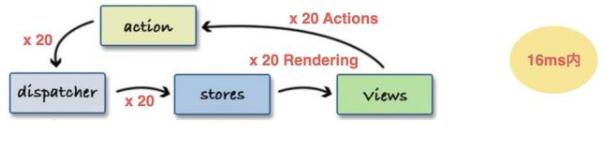
這顯然會引發非常大的性能問題,由此,我們需要對短時間的ACTION量作一個緩沖節流,待20次ACTION狀態改變完畢后,僅進行1次View更新,如下:
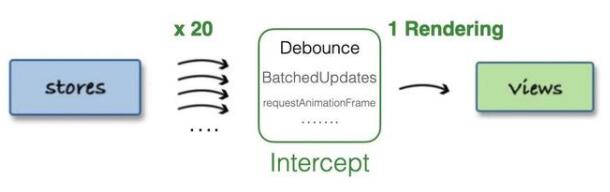
此方案在Quick BI以redux中間件的形式發揮作用,在復雜+頻繁數據更新場景起到了不錯的效果
思考
“君子以思患而豫防之”,當我們回過頭去看看,出現的這些性能問題,在架構設計、編碼階段是可以避免掉80%以上的,20%的則可以“空間<=>時間置換策略”等方式去平衡。所以,最佳的性能優化方案,是在于我們對每一段代碼質量的執著:是否考慮到了這樣的模塊依賴關系,可能帶來的構建產物體積問題?是否考慮到了這段邏輯可能的執行頻次?是否考慮到了隨著數據增長,空間或CPU占用的可控性?等等。性能優化沒有銀彈,作為技術人,需要內修于心(熟知底層原理),把對性能的執念植入本能思考當中,方為銀彈。
原文鏈接:http://click.aliyun.com/m/1000283335/




















