













如何為你的 Kubernetes 集群保駕護航
隨著Kubernetes的不斷發(fā)展,技術不斷成熟,越來越多的公司選擇把自家的應用部署到Kubernetes中。但是把應用部署到Kubernetes中就完事了嗎?顯然不是,應用容器化只是萬里長征的第一步,如何讓應用安心、穩(wěn)定的運行才是后續(xù)的所有工作。
這里主要從以下幾個方面來進行整理,對于大部分公司足夠使用。
Node
Node可以是物理主機,也可以是云主機,它是Kubernetes的載體。在很多時候我們并不太關心Node怎么樣了,除非其異常。但是作為運維人員,我們最不希望的就是異常,對于Node也是一樣。
Node節(jié)點并不需要做太多太復雜的操作,主要如下:
>內核升級
對于大部分企業(yè),CentOS系統(tǒng)還是首選,默認情況下,7系列系統(tǒng)默認版本是3.10,該版本的內核在Kubernetes社區(qū)有很多已知的Bug,所以對節(jié)點來說,升級內核是必須的,或者企業(yè)可以選擇Ubuntu作為底層操作系統(tǒng)。
升級內核的步驟如下(簡單的升級方式):
- wget https://elrepo.org/linux/kernel/el7/x86_64/RPMS/kernel-lt-5.4.86-1.el7.elrepo.x86_64.rpm
- rpm -ivh kernel-lt-5.4.86-1.el7.elrepo.x86_64.rpm
- cat /boot/grub2/grub.cfg | grep menuentry
- grub2-set-default 'CentOS Linux (5.4.86-1.el7.elrepo.x86_64) 7 (Core)'
- grub2-editenv list
- grub2-mkconfig -o /boot/grub2/grub.cfg
- reboot
>軟件更新
對于大部分人來說,更新軟件在很多情況下是不做的,因為害怕兼容問題。不過在實際生產(chǎn)中,對于已知有高危漏洞的軟件,我們還需要對其進行更新,這個可以針對處理。
>優(yōu)化Docker配置文件
對于Docker的配置文件,主要優(yōu)化的就是日志驅動、保留日志大小以及鏡像加速等,其他的配置根據(jù)情況而定,如下:
- cat > /etc/docker/daemon.json << EOF
- {
- "exec-opts": ["native.cgroupdriver=systemd"],
- "log-driver": "json-file",
- "log-opts": {
- "max-size": "100m",
- "max-file": "10"
- },
- "bip": "169.254.123.1/24",
- "oom-score-adjust": -1000,
- "registry-mirrors": ["https://pqbap4ya.mirror.aliyuncs.com"],
- "storage-driver": "overlay2",
- "storage-opts":["overlay2.override_kernel_check=true"],
- "live-restore": true
- }
- EOF
>優(yōu)化kubelet參數(shù)
對于K8S來講,kubelet是每個Node的組長,負責Node的"飲食起居",這里對它的參數(shù)配置主要如下:
- cat > /etc/systemd/system/kubelet.service <<EOF
- [Unit]
- Description=kubelet: The Kubernetes Node Agent
- Documentation=https://kubernetes.io/docs/
- [Service]
- ExecStartPre=/usr/bin/mkdir -p /sys/fs/cgroup/pids/system.slice/kubelet.service
- ExecStartPre=/usr/bin/mkdir -p /sys/fs/cgroup/cpu/system.slice/kubelet.service
- ExecStartPre=/usr/bin/mkdir -p /sys/fs/cgroup/cpuacct/system.slice/kubelet.service
- ExecStartPre=/usr/bin/mkdir -p /sys/fs/cgroup/cpuset/system.slice/kubelet.service
- ExecStartPre=/usr/bin/mkdir -p /sys/fs/cgroup/memory/system.slice/kubelet.service
- ExecStartPre=/usr/bin/mkdir -p /sys/fs/cgroup/systemd/system.slice/kubelet.service
- ExecStart=/usr/bin/kubelet \
- --enforce-node-allocatable=pods,kube-reserved \
- --kube-reserved-cgroup=/system.slice/kubelet.service \
- --kube-reserved=cpu=200m,memory=250Mi \
- --eviction-hard=memory.available<5%,nodefs.available<10%,imagefs.available<10% \
- --eviction-soft=memory.available<10%,nodefs.available<15%,imagefs.available<15% \
- --eviction-soft-grace-period=memory.available=2m,nodefs.available=2m,imagefs.available=2m \
- --eviction-max-pod-grace-period=30 \
- --eviction-minimum-reclaim=memory.available=0Mi,nodefs.available=500Mi,imagefs.available=500Mi
- Restart=always
- StartLimitInterval=0
- RestartSec=10
- [Install]
- WantedBy=multi-user.target
- EOF
其功能主要是為每個Node增加資源預留,可以在一定程度上防止Node宕機。
>日志配置管理
這里的日志配置管理針對的是系統(tǒng)日志,非自研應用日志。默認情況下,系統(tǒng)日志都不需要我們特殊配置,我這里提出來,主要是保障日志的可追溯。當系統(tǒng)因為某種原因被入侵,系統(tǒng)系統(tǒng)被刪除的情況下,還有日志提供給我們分析。
所以在條件允許的情況下,對Node節(jié)點的系統(tǒng)日志進行遠程備份是有必要的,可以采用rsyslog進行配置管理,日志可以保存到遠端的日志中心或者oss上。
>安全配置
安全配置這里涉及的不多,主要是針對已知的一些安全問題進行加固。主要有以下五種(當然還有更多,看自己的情況):
- ssh密碼過期策略
- 密碼復雜度策略
- ssh登錄次數(shù)限制
- 系統(tǒng)超時配置
- 歷史記錄配置
Pod
Pod是K8S的最小調度單元,是應用的載體,它的穩(wěn)定直接關乎應用本身,在部署應用的時候,主要考慮一下幾個方面。
>資源限制
Pod使用的是主機的資源,合理的資源限制可以有效避免資源超賣或者資源搶占問題。在配置資源限制的時候,要根據(jù)實際的應用情況來決定Pod的QoS,不同的QoS配置情況不一樣。
如果應用的級別比較高,建議配置Guaranteed級別配置,如下:
- resources:
- limits:
- memory: "200Mi"
- cpu: "700m"
- requests:
- memory: "200Mi"
- cpu: "700m"
如果應用級別一般,建議配置Burstable級別,如下:
- resources:
- limits:
- memory: "200Mi"
- cpu: "500m"
- requests:
- memory: "100Mi"
- cpu: "100m"
強烈不建議使用BestEffort類型的Pod。
>調度策略
調度策略也是根據(jù)情況來定,如果你的應用需要指定調度到某些節(jié)點,可以使用親和性調度,如下:
- affinity:
- nodeAffinity:
- preferredDuringSchedulingIgnoredDuringExecution:
- - preference: {}
- weight: 100
- requiredDuringSchedulingIgnoredDuringExecution:
- nodeSelectorTerms:
- - matchExpressions:
- - key: env
- operator: In
- values:
- - uat
如果一個節(jié)點只允許某一個應用調度,這時候就需要用到污點調度了,也就是先給節(jié)點打污點,然后需要調度到該節(jié)點的Pod需要容忍污點。最穩(wěn)妥的方式是標簽+污點相結合。如下:
- tolerations:
- - key: "key1" #能容忍的污點key
- operator: "Equal" #Equal等于表示key=value , Exists不等于,表示當值不等于下面value正常
- value: "value1" #值
- effect: "NoExecute" #effect策略
- tolerationSeconds: 3600 #原始的pod多久驅逐,注意只有effect: "NoExecute"才能設置,不然報錯
當然,除了Pod和Node的關聯(lián),還有Pod和Pod之間的關聯(lián),一般情況下,為了達到真正的高可用,我們不建議同一個應用的Pod都可以調度到同一個節(jié)點,所以我們需要給Pod做反親和性調度,如下:
- affinity:
- podAntiAffinity:
- requiredDuringSchedulingIgnoredDuringExecution:
- - labelSelector:
- matchExpressions:
- - key: app
- operator: In
- values:
- - store
- topologyKey: "kubernetes.io/hostname"
如果某個應用親和其他應用,則可以使用親和性,這樣可以在一定程度上降低網(wǎng)絡延遲,如下:
- affinity:
- podAffinity:
- requiredDuringSchedulingIgnoredDuringExecution:
- - labelSelector:
- matchExpressions:
- - key: security
- operator: In
- values:
- - S1
- topologyKey: failure-domain.beta.kubernetes.io/zone
>優(yōu)雅升級
Pod默認是采用的滾動更新策略,我們關注點主要在新的Pod起來后,老的Pod如何能優(yōu)雅的處理流量,對外界是無感的。
最簡單的方式是"睡幾秒",這種方式并不能保證百分百的優(yōu)雅處理流量,方式如下:
- lifecycle:
- preStop:
- exec:
- command:
- - /bin/sh
- - -c
- - sleep 15
如果有注冊中心,可以在退出的時候先把原服務從注冊中心下線再退出,比如這里使用的nacos作為注冊中心,如下:
- lifecycle:
- preStop:
- exec:
- command:
- - /bin/sh
- - -c
- - "curl -X DELETE your_nacos_ip:8848/nacos/v1/ns/instance?serviceName=nacos.test.1&ip=${POD_IP}&port=8880&clusterName=DEFAULT" && sleep 15
>探針配置
探針重要嗎?重要!它是kubelet判斷Pod是否健康的重要依據(jù)。
Pod的主要探針有:
- livenessProbe
- readinessProbe
- startupProbe
其中startupProbe是v1.16版本后才新增的探針,其主要針對啟動時間較長的應用,在多數(shù)情況下只需要配置livenessProbe和readinessProbe即可。
通常情況下,一個Pod就代表一個應用,所以在配置探針的時候最好能直接反應應用是否正常,很多框架都帶有健康檢測功能,我們在配置探針的時候可以考慮使用這些健康檢測功能,如果框架沒有,也可以考慮讓開發(fā)人員統(tǒng)一開發(fā)一個健康檢測接口,這樣便于標準化健康檢測。如下:
- readinessProbe:
- failureThreshold: 3
- httpGet:
- path: /health
- port: http
- scheme: HTTP
- initialDelaySeconds: 40
- periodSeconds: 10
- successThreshold: 1
- timeoutSeconds: 3
- livenessProbe:
- failureThreshold: 3
- httpGet:
- path: /health
- port: http
- scheme: HTTP
- initialDelaySeconds: 60
- periodSeconds: 10
- successThreshold: 1
- timeoutSeconds: 2
如果需要配置startupProbe,則可以如下配置:
- startupProbe:
- httpGet:
- path: /health
- prot: 80
- failureThreshold: 10
- initialDelay:10
- periodSeconds: 10
>保護策略
這里的保護策略主要是指在我們主動銷毀Pod的時候,通過保護策略來控制Pod的運行個數(shù)。
在K8S中通過PodDisruptionBudget(PDB)來實現(xiàn)這個功能,對于一些重要應用,我們需要為其配置PDB,如下:
- apiVersion: policy/v1beta1
- kind: PodDisruptionBudget
- metadata:
- name: pdb-demo
- spec:
- minAvailable: 2
- selector:
- matchLables:
- app: nginx
在PDB中,主要通過兩個參數(shù)來控制Pod的數(shù)量:
- minAvailable:表示最小可用Pod數(shù),表示在Pod集群中處于運行狀態(tài)的最小Pod數(shù)或者是運行狀態(tài)的Pod數(shù)和總數(shù)的百分比;
- maxUnavailable:表示最大不可用Pod數(shù),表示Pod集群中處于不可用狀態(tài)的最大Pod數(shù)或者不可用狀態(tài)Pod數(shù)和總數(shù)的百分比;
注意:minAvailable和maxUnavailable是互斥了,也就是說兩者同一時刻只能出現(xiàn)一種。
日志
日志會貫穿應用的整個生命周期,在排查問題或者分析數(shù)據(jù)的時候,日志都不可缺少。對于日志,這里主要從以下方面進行分析。
>日志標準
日志一般分為業(yè)務日志和異常日志,對于日志,我們不希望其太復雜,也不希望其太簡單,更多的是希望通過日志達到如下目標:
- 對程序運行情況的記錄和監(jiān)控;
- 在必要時可詳細了解程序內部的運行狀態(tài);
- 對系統(tǒng)性能的影響盡量小;
那日志標準如何定義呢?我這里簡單整理以下幾點:
- 合理使用日志分級
- 統(tǒng)一輸出格式
- 代碼編碼規(guī)范
- 日志輸出路徑統(tǒng)一
- 日志輸出命名規(guī)范統(tǒng)一
這樣規(guī)定的主要目的是便于收集和查看日志。
>收集
針對不同的日志輸出有不同的日志收集方案,主要有以下二種:
- 在Node上部署Logging Agent進行收集
- 在Pod中以Sidecar形式進行收集
在Node上部署Logging Agent進行收集
這種日志收集方案主要針對已經(jīng)標準輸出的日志,架構如下:
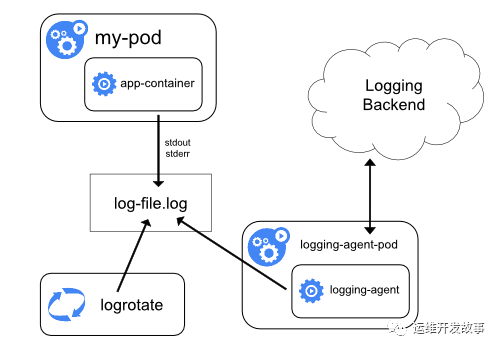
對于非標準輸出的日志就沒辦法進行收集。
在Pod中以Sidecar形式進行收集
這種收集方案主要針對非標準輸出的日志,可以在Pod中以sidecar的方式運行日志收集客戶端,將日志收集到日志中心,架構如下:
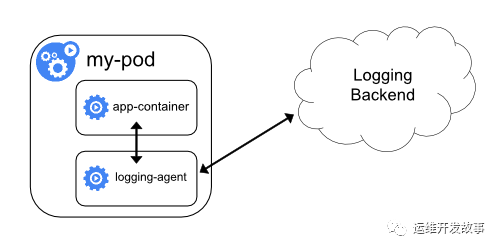
不過這種方式比較浪費資源,所以最理想的情況就是把應用日志都標準輸出,這樣收集起來比較簡單。
>分析
在業(yè)務正常的情況下,我們其實很少去查看日志內容,只有在出問題的時候才會借助日志分析問題(大部分情況下都是這樣),那為什么我這里要把分析提出來呢?
日志其實承載了很多信息,如果能對日志進行有效分析,可以幫助我們識別、排查很多問題,比如阿里云的日志中心,在日志分析方面做的就很不錯。
>告警
日志告警,可以讓我們快速知道問題,也縮小了故障排查范圍。不過要做日志告警就必須做好日志“關鍵字”管理,也就是要確定某一個關鍵字能夠準確的代表一個問題,最好不出現(xiàn)泛指的現(xiàn)象,這樣做的好處就是能夠讓告警更加準備,而不是出現(xiàn)一些告警風暴或者無效告警,久而久之就麻木了。
監(jiān)控
集群、應用等的生命周期里離不開監(jiān)控系統(tǒng),有效的監(jiān)控系統(tǒng)可以為我們提供更高的可觀測性,方便我們線性的分析問題,排查問題以及定位問題,再配上有效的告警通知,也方便我們能快速的知道問題。
對于監(jiān)控,主要從以下幾個方面進行介紹。
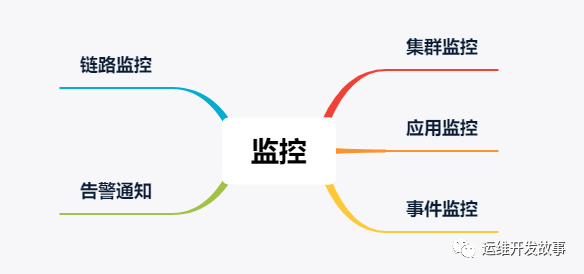
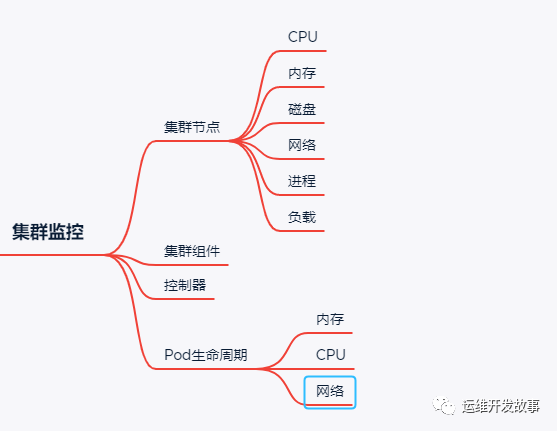
>集群監(jiān)控
對于K8S集群以及跑在K8S應用來說,普遍使用Prometheus來進行監(jiān)控。整個集群的穩(wěn)定性關乎著應用的穩(wěn)定性,所以對集群的監(jiān)控至關重要,下面簡單列舉了一些監(jiān)控項,在實際的工作中酌情處理。
>應用監(jiān)控
在很多企業(yè)中,并沒有接入應用監(jiān)控,主要還是沒有在應用中集成監(jiān)控指標,導致無法監(jiān)控,所以在應用開發(fā)的時候就強烈建議開發(fā)將應用監(jiān)控加上,將指標按prometheus標準格式暴露出來。
除了開發(fā)人員主動暴露指標外,我們也可以通過javaagent方式配置一些exporter,用來抓取一些指標,比如jvm監(jiān)控指標。
在應用級別做監(jiān)控,可以將監(jiān)控粒度更細化,這樣可以更容易發(fā)現(xiàn)問題。我這里簡單整理了一些應用監(jiān)控項,如下:

這些監(jiān)控項都有對于的exporter來完成,比如redis中間件有redis-exporter,api監(jiān)控有blcakbox-exporter等。
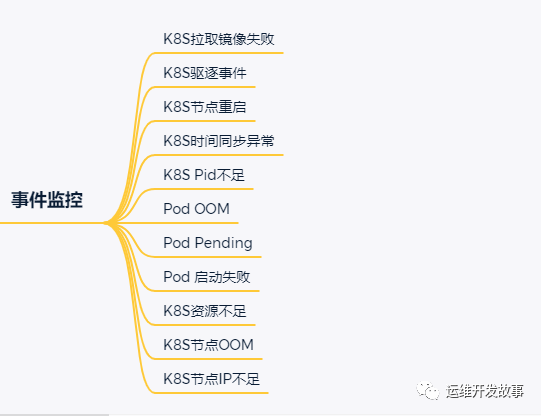
>事件監(jiān)控
在Kubernetes中,事件分為兩種,一種是Warning事件,表示產(chǎn)生這個事件的狀態(tài)轉換是在非預期的狀態(tài)之間產(chǎn)生的;另外一種是Normal事件,表示期望到達的狀態(tài),和目前達到的狀態(tài)是一致的。
事件大多數(shù)情況下表示正在發(fā)生或者已經(jīng)發(fā)生的事,在實際工作中很容易就忽略這類信息,所以我們有必要借助事件監(jiān)控來規(guī)避這類問題。
在K8S中,常用的事件監(jiān)控是kube-eventer,它可以收集pod/node/kubelet等資源對象的event,還可以收集自定義資源對象的event,然后將這類信息發(fā)送到相關人員。
通過事件,我們主要關注的監(jiān)控項如下:
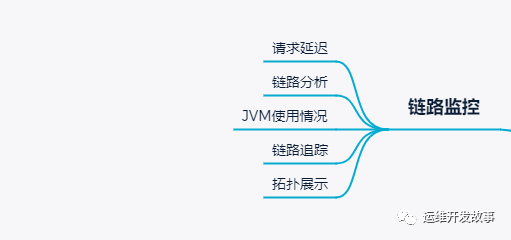
>鏈路監(jiān)控
正常情況下,K8S中的應用是單獨的個體存在,彼此之間沒有顯性的聯(lián)系,這時候就需要一種手段,將應用間的關系表現(xiàn)出來,方便我們跟蹤分析整個鏈路的問題。
目前比較流行的鏈路監(jiān)控工具有很多,我這邊主要是使用skywalking進行鏈路監(jiān)控,其主要agent端比較豐富,也提供了很高的自擴展能力,有興趣的朋友可以了解一下。
通過鏈路監(jiān)控,主要達到以下目的。
>告警通知
很多人會忽略告警通知,覺得告警就行。但是在做告警通知的時候還是需要仔細去考慮的。
如下簡單整理一下關注點。

個人覺得難點在于哪些指標需要告警。我們在選取指標的時候一定要遵循以下規(guī)則:
- 警的指標具有唯一性
- 告警的指標能正確反應問題
- 所暴露的問題是需要介入解決的
綜合這些規(guī)則考慮,才方便我們選取需要的指標。
第二就是緊急程度分類,這個主要是根據(jù)這個告警指標所暴露出來的問題是不是需要我們及時去解決,還有影響范圍來綜合衡量。
故障升級主要是針對需要解決的問題沒有解決而做的一種策略,提高故障等級,也相當于提高了緊急程度了。通知渠道分類主要是方便我們區(qū)分不同的告警,還有如果能快速接收到告警信息。
寫在最后
上面寫的都是一些基礎的操作,對于YAML工程師來說,算是必備的技能儲備,這一套放到大部分公司都是適用的。














