服務器又崩了?深度解析高可用架構的挑戰和實踐
大家好,我是騰訊微服務平臺TSF 產品經理劉閻,目前主要負責TSF高可用能力建設及演進規劃工作,本次分享我會結合自己對微服務架構的理解以及TSF在高可用能力建設上的最佳實踐與大家共同討論如何構建高可用的微服務架構。
微服務架構挑戰
軟件架構的演進歷程
首先我們先來看下軟件架構的演進歷程:
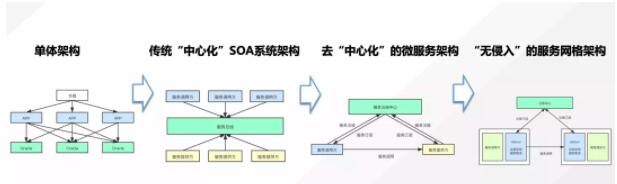
單體架構:沒有復雜邏輯分層,前后代碼耦合,單個應用可能與多個數據庫關聯
適用于:迭代頻率低,并發量小,業務邏輯簡單的應用場景,目前單體架構在政府、金融、工業領域仍有廣泛應用。
SOA架構:按業務邏輯進行服務拆分,服務間通過服務總線進行服務管理及流量轉發
其主要問題在于:服務總線成為系統新的瓶頸,難以伴隨業務的不斷發展滿足線性擴容的要求。
微服務架構:服務架構通過服務注冊中心實現服務注冊發現,服務啟動時將服務實例注冊到注冊中心,調用方在發起調用時通過注冊中心進行服務尋址,直接與提供方進行通信。理論上服務可以伴隨業務發展實現線性擴展,不同服務之間可單獨迭代,實現敏捷開發。
服務網格:版本云原生k8s及容器技術發展,服務網格技術已趨于成熟,相較于傳統的微服務架構,服務網格通過sidercar模式進行流量代理和服務注冊發現,無需業務感知,輕松實現跨語言服務治理,幫助業務快速遷移,使業務應用更加專注自身業務邏輯實現。
每種軟件架構沒有嚴格意義上的好壞之分,用戶需要根據自身的業務特點進行架構選型。
微服務應用常見問題
微服務架構在滿足高并發、敏捷迭代的同時,業務模塊數量成幾何數增長,給應用運維帶來了嚴峻挑戰,微服務架構相較于傳統單體架構,具有流量洪峰激增、模塊依賴復雜、故障定位難度大、故障恢復耗時長的特點。
- 流量激增:單體應用拆分為微服務應用后,原有的單一請求邏輯拆分為多個微服務應用的組合業務邏輯,接口調用量成1:N的增長關系,面對流量洪峰,接口調用量激增。
- 模塊依賴復雜:原有的單體應用僅存在單一進程內的業務邏輯組合,微服務應用拆分為多個進程,各模塊間的服務上下游依賴關系復雜,單個微服務或單個接口異常通常引發鏈式反應,造成服務雪崩。
- 故障定位難度大:單次請求異常需要依據各模塊的依賴關系分析整個調用鏈路定位故障原因,由于橫跨多個微服務應用進程的不同業務邏輯,故障定位難度陡增。
- 故障恢復耗時長:由于各微服務模塊依賴關系復雜,需要根據調用鏈準確定位故障問題根源并進行逐級恢復,故障恢復及恢復后驗證評價結果耗時長。
如何度量系統可用性指標
管理學大師彼得德魯克曾說“你如果無法度量它,就無法管理它”(“It you can’t measure it, you can’t manage it”)。要想有效管理,就難以繞開度量的問題。
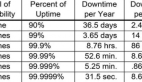
那如何度量分布式系統的可用性指標呢,這里有一個簡單公式,可用性=平均故障間隔時間/平均故障間隔時間與平均故障恢復時間之和。

所謂平均故障間隔時間是指相鄰兩次故障之間的平均工作時間,也稱為平均故障間隔。平均修復時間是從出現故障到修復中間的這段時間。MTTR 越短表示易恢復性越好。
MTBF:即平均故障間隔時間,英文全稱是“Mean Time Between Failure”。是衡量一個產品(尤其是電器產品)的可靠性指標。單位為“小時”。
MTTR:全稱是 Mean Time To Repair,即平均修復時間。是指可修復產品的平均修復時間,就是從出現故障到修復中間的這段時間。MTTR 越短表示易恢復性越好。
高可用架構設計的道、法、術
那如何設計高可用的微服務架構呢?接下來我將分別從道、法、術三個層面講高可用微服務架構設計的基本原理、架構設計原則、以及高可用架構常用的解決方法。
道:從CAP到BASE
CAP 理論:在一個分布式系統中, 一致性(C:Consistency)、可用性(A:Availability) 和 分區容忍性(P:Partition Tolerance),最多只能同時滿足其中兩項。其中分區容忍性(P:Partition Tolerance)是復雜網絡環境下的必須要素,因此分布式系統的架構設計需要在一致性和可用性之間進行取舍。就誕生了諸如:Paxos 算法 和 Raft 算法強一致性共識算法,以及2階段提交,3階段提交的最終一致性算法。
BASE 理論:BASE是對 CAP 中一致性和可用性權衡的結果,它的理論的核心思想是:即使無法做到強一致性,但每個應用都可以根據自身業務特點,采用適當的方式來使系統達到最終一致性。
法:微服務高可用架構設計原則
結合我對微服務高可用架構的理解,總結出以下6點高可用架構設計的原則,分別是服務無狀態、異步解耦、分區容錯、故障隔離、快速恢復、最終一致性:
服務無狀態:服務應用進行無狀態設計,將服務應用的狀態數據通過緩存、數據庫進行集中存儲,通過nginx或網關進行負載均衡實現水平擴展。
異步解耦:各服務模塊通過發布訂閱、事件驅動方式進行異步解耦,單次請求調用通過異步回調方式快速響應,將通知事件與處理結果分離,避免異常雪崩。
分區容錯:基于指定的業務規則實現業務分流路由,將流量分發至多個可用區,不同可用區通過數據同步、多備份機制保障數據一致性。
故障隔離:單一進程、單一接口、單一服務通過熔斷、降級機制實現故障隔離,避免系統關聯異常,引發雪崩效應。
快速恢復:通過流量切分,版本管理、應用回滾機制實現應用快速回退至健康版本,快速恢復應用。
最終一致性:通過多數據源雙寫、數據稽核、數據修復實現數據跨可用區數據最終一致性。
術:高可用常用手段
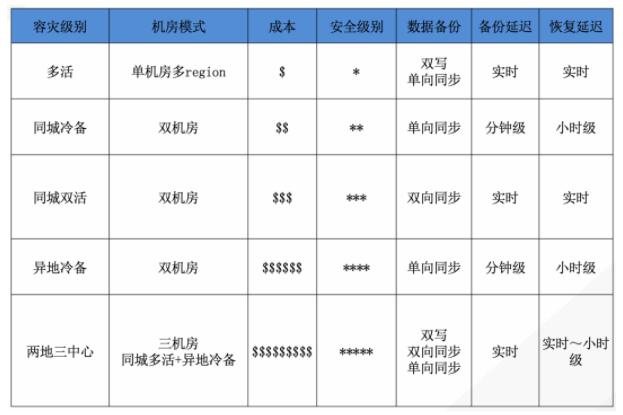
分區容錯:
異地容災是高可用架構典型的應用場景,通過將不同地域的數據中心構建多套應用服務,當單一地域服務宕機時可快速通過流量切換災備中心保障業務持續、穩定。異地容災按保障級別不同分為,多可用區、同城冷備、同城雙活、異地冷備、兩地三中心五個級別,其保障級別、應用成本、恢復延遲都呈遞增趨勢。
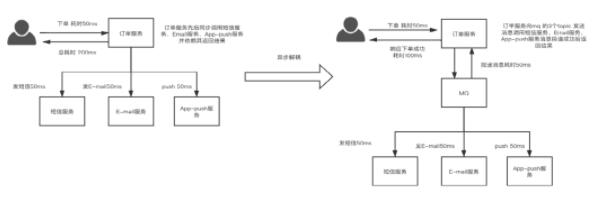
異步解耦:
在微服務應用中通過引入消息中間件將上游組合服務對下游多個微服務的同步調用進行異步解耦,基于消息的可靠投遞能力快速響應用戶請求,能夠大幅提升服務并發訪問性能及用戶體驗,并通過數據補償手段保障數據最終一致性。
服務限流:
由于 API 接口無法控制調用方的行為,因此當遇到瞬時請求量激增時,會導致接口占用過多服務器資源,使得其他請求響應速度降低或是超時,嚴重導致服務器宕機。服務限流主要是保護服務節點或者數據節點,防止瞬時流量過大造成服務和數據崩潰,導致服務不可用。
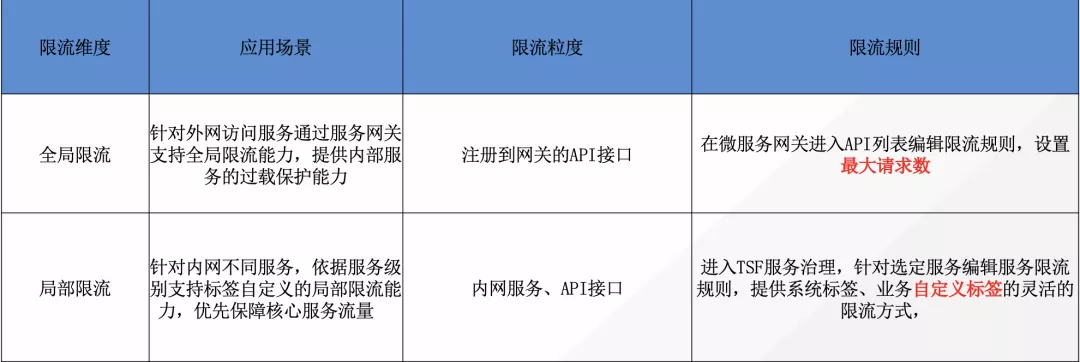
局部限流:基于簡單計數、令牌桶、漏斗算法在單個節點內的限流,僅能限制傳入此節點的請求,無需引入中間件,通過局部限流達到全局限流的目的,同時避免實例級別單一接口訪問量激增問題
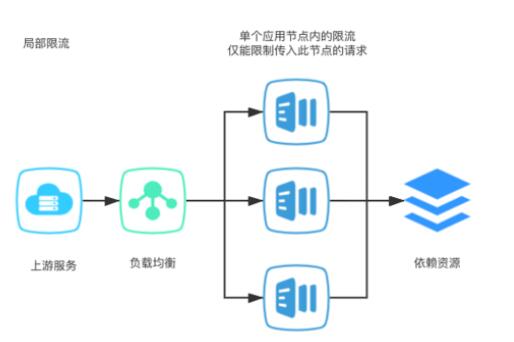
全局限流:基于簡單計數、令牌桶算法,通過引入中間件如redis,針對整個集群流量進行全局控制。

服務熔斷:
服務熔斷是應對服務異常,實現服務容錯,避免服務雪崩的有效手段。
從下圖中可以看出,當網關入口服務請求下游多個服務接口,當服務C接口異常將導致入口服務流量的不可用,服務A、服務E請求則白白占用。
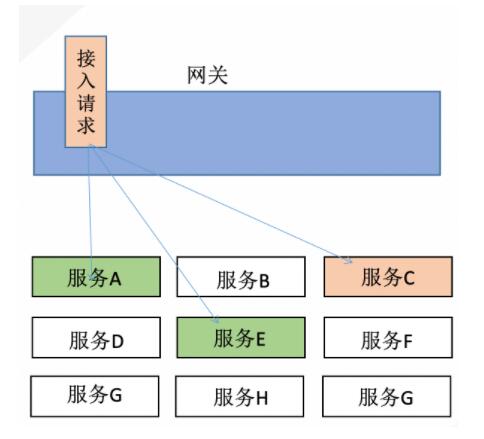
從下圖中可以看出,當網關入口的服務請求下游的單一服務接口,當服務B接口異常將導致入口請求夯住,占用網關請求資源,導致整體業務異常。

針對以上兩種異常場景,通過在服務調用時配置熔斷策略能夠快速失敗,直接反饋上游業務異常結果,避免請求線程夯死及服務雪崩。
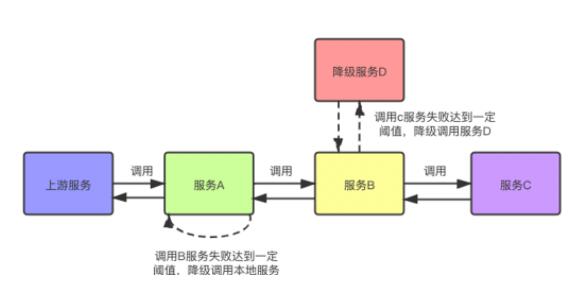
降級容錯:
服務降級是在服務器壓力陡增的情況下,利用有限資源,根據當前業務情況,關閉某些服務接口或者頁面,以此釋放服務器資源以保證核心服務的正常運行。
TSF高可用最佳實踐
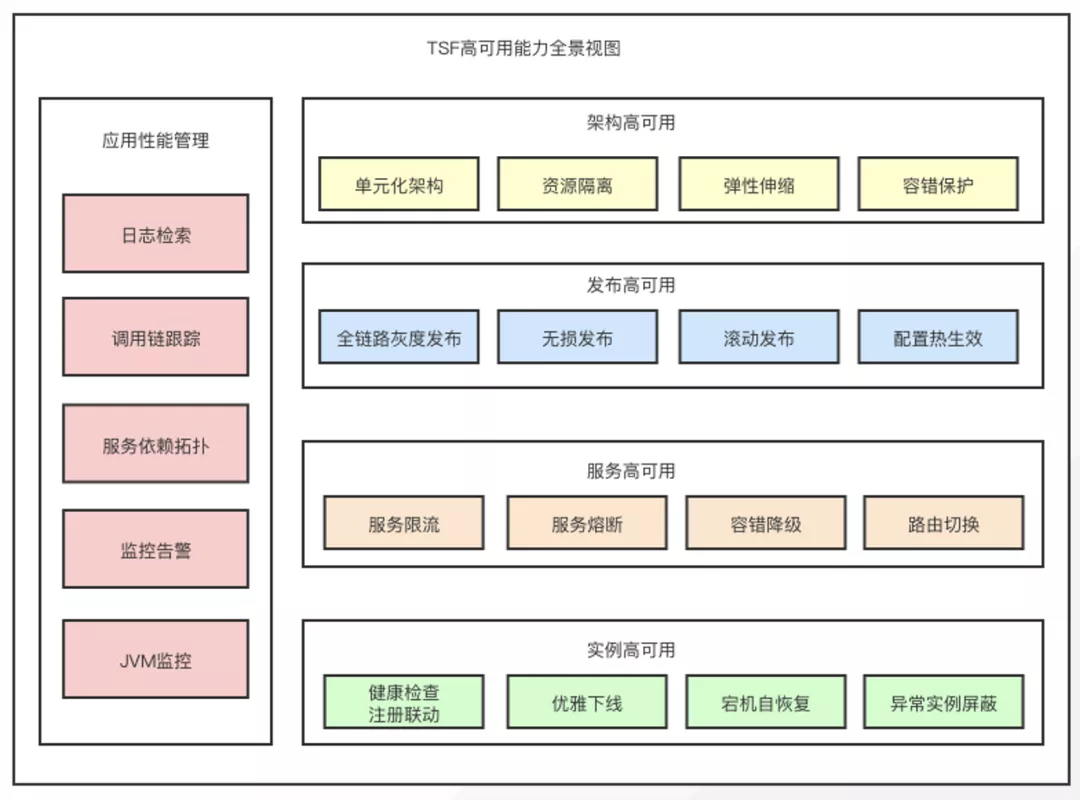
TSF微服務平臺針對業務流量激增、服務異常容錯等問題提供架構容災、灰度發布、服務容錯兜底、實例優雅啟停、應用性能管理的一體化高可用服務架構。突出立體化、自動化、可視化的優勢,提供端到端的應用性能監控,多維度可視化的運行監控數據聚合分析,實現故障自動感知,自動處理,快速恢復故障業務,保障系統的穩定高效運行。
單元化架構部署
單元化架構是一種高級的高可用架構設計模式,通過對核心業務數據分片,應用服務無狀態設計將相同領域的業務服務劃分為一個個獨立的部署單元,單元內整體業務閉環。通過單元化部署架構能夠有效滿足彈性伸縮,故障隔離,異地容災等高可用建設要求。此外基于單元化部署可以實現以部署單元為基準,構建靈活的發布策略。
單元化架構產品能力:
- 網關業務單元路由標簽
- 支持跨單元橫向調用
- 單元內服務容錯兜底
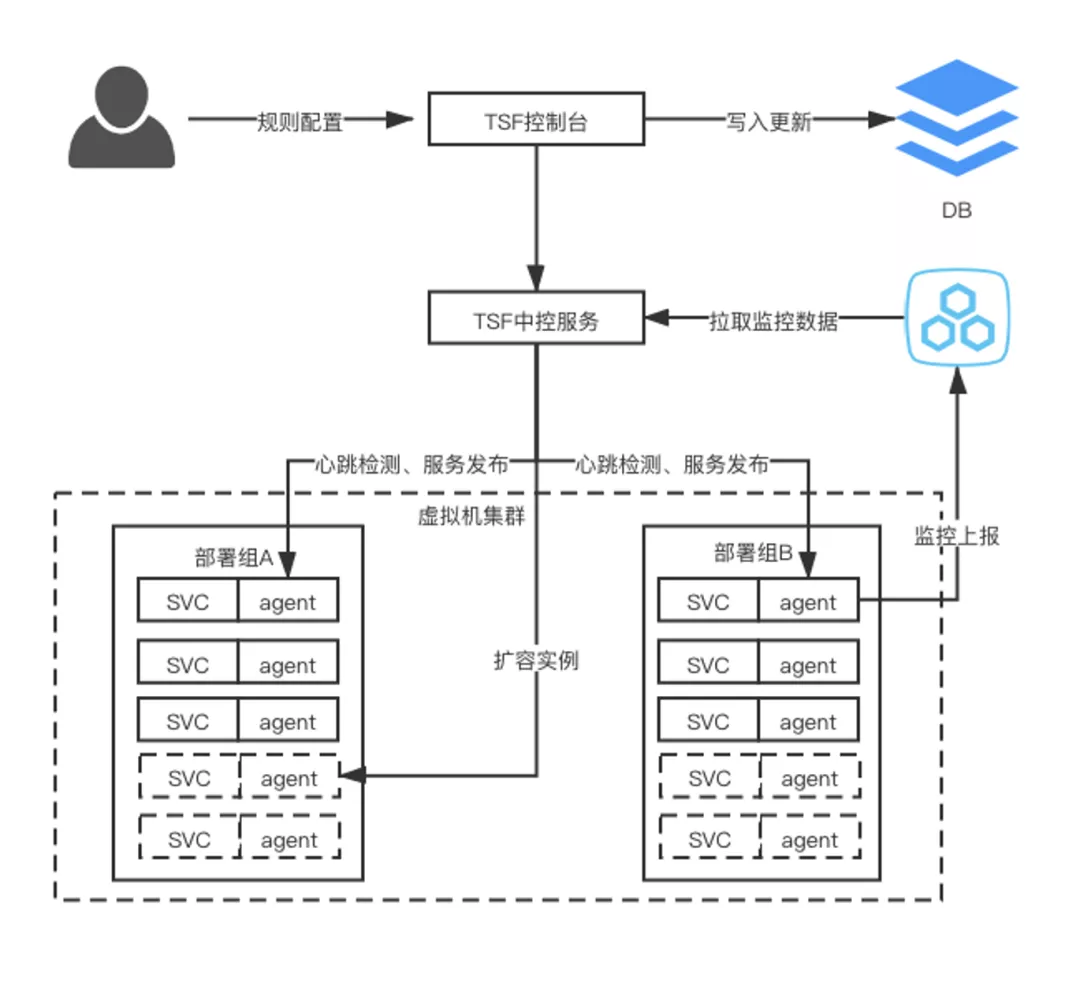
彈性伸縮
通過配置動態伸縮規則,TSF中控服務基于agent上報的監控數據實現實時統計,滿足流量激增自動擴容或流量低峰自動縮容能力,有效保障服務高效穩定及資源利用率提升。
全鏈路灰度發布
灰度發布是將具有一定特征或者比例的流量分配到需要被驗證的版本中,用來觀察新的驗證版本的線上運行狀態。相比全量上線,灰度發布是更加謹慎的發布形式。當線上調用鏈路較為復雜時,全鏈路灰度發布可以將線上的各個服務隔離出一個單獨的運行環境。
全鏈路灰度產品能力:
- 基于業務級別的全鏈路灰度發布能力
- 支持按照業務級別請求參數對流量進行劃撥
- 泳道間流量隔離
優雅啟停
在應用滾動發布過程中,可以通過調整部署組滾動發布更新策略達到服務優雅下線,降低發布過程中業務中斷影響。
這里簡單介紹優雅下線的簡單流程
- 下線實例在注冊中心進行反注冊,注銷該實例注冊信息;
- 注冊中心節點訂閱更新周期為15s,調用方在感知注冊中心實例變更后,更新本地緩存服務地址,不再將流量路由到下線實例,期間保障業務無中斷;
- 下線實例等待30s(2個心跳周期)后進行實際下線操作;
優雅啟停產品能力:
- 支持容器、虛機部署方式
- 實例反注冊下線事件詳情
- 實例啟動就緒檢測
服務限流
TSF 限流基于監控服務流量的 QPS 指標,當達到指定的閾值時進行流量控制,避免被瞬時高峰流量沖垮,從而確保服務的高可用。支持在網關配置全局限流策略保障入口服務流量穩定支持針對單一服務配置局部限流策略保障當前服務流量穩定,同時提供靈活的限流規則配置及動態生效,提供可視化的限流操作及監控數據展示。
服務熔斷
TSF服務熔斷能力支持服務、實例、API多維度的熔斷隔離級別,提供控制臺可視化配置及熔斷事件展示,滿足熔斷配置熱生效需求。
熔斷器狀態轉換:
熔斷器開始處于closed狀態,一旦檢測到錯誤(或慢響應)達到一定閾值,便轉為open狀態,此時不再調用下游目標服務。
一段時間后轉化為half open狀態,嘗試放行一部分請求到下游服務。
一旦檢測到響應成功,回歸到closed狀態,也即恢復服務;否則回到open狀態。
健康檢查與注冊中心聯動流程
健康檢查分為存活檢查及就緒檢查;存活檢查主要作用是確定進程存活狀態,判斷是否需要進行實例重啟。就緒檢查主要作用是確定服務實例能否支持對外服務,將健康檢查結果與注冊中心狀態聯動避免流量接入異常節點。
健康檢查與注冊中心聯動流程
1.就緒檢查,檢查實例狀態是否ready
2.如果就緒檢查ready則更新實例注冊狀態為passing,反之則檢查狀態為cirtical
3.監聽注冊中心服務提供方實例狀態變更
4.存在狀態變更更新緩存及本地文件
5.發起服務調用
- 健康檢查產品能力:
- 存活檢查
- 就緒檢查
- 多種探測方式:http,tcp,執行命令
- 支持虛機&容器部署
應用性能管理能力
最后我們從一個問題排查流程全局展示tsf應用性能管理能力:
- 用戶收到監控平臺發送的告警信息,確定異常基本信息。
- 通過服務依賴拓撲確定異常服務的上下游依賴關系,進行全局視圖分析。
- 接下來可以服務接口調用情況確定是全局接口異常或是單一接口異常。
- 如果是全局接口異常說明服務提供方服務實例存在異常問題,找到對應的異常實例通過日志檢索或JVM監控分析排查具體問題;如果是單一接口異常說明提供方接口邏輯處理,通過日志檢索可排查具體問題。
- 當然也可以在全局視圖分析后通過對直接服務進行調用鏈分析排查單筆請求的調用鏈路,通過調用鏈與日志聯動排查具體異常。