













對比四大典型的云數據倉庫:Snowflake、Redshift、BigQuery和Azure
譯文【51CTO.com快譯】毋庸置疑,數據不但可以幫助企業在決策的過程中消除各種猜測,而且能夠讓用戶團隊使用由數據驅動的證據,來決定要構建哪些產品,添加哪些功能,以及需要改進哪些計劃與目標。不過,數據感知力并非簡單等于洞察驅動力,后者往往需要找到一種近乎實時的數據分析方法。
如今,作為可擴展類型的數據存儲庫,云數據倉庫能夠讓企業通過存儲和分析大量結構化、以及半結構化的數據,來尋找并發現洞察驅動力,進而為企業即將推出的各種產品、營銷策略和工程決策,提供全面的業務信息。
當然,選擇云數據倉庫的提供商往往是一件具有挑戰性的工作。用戶必須根據他們的需求,綜合評估數據倉庫的成本、性能、處理實時負載的能力、以及其他方面。在此,我們將分析當前四大流行云數據倉庫:Snowflake、Amazon Redshift、Google BigQuery和Azure Synapse Analytics,綜合比較它們優缺點,并深入探討您在選擇云數據倉庫時需要考慮的各項因素。
什么是數據倉庫?
數據倉庫是一個系統,它將來自各種源頭的數據導入一個中央存儲庫中,并為后續的快速檢索做好準備。數據倉庫通常包含了從事務系統、操作數據庫、以及其他來源,提取到的結構化和半結構化的數據。數據工程師和分析師可以將這些數據用于商業智能、以及其他各種目的。
數據倉庫既可以被部署在本地、又可以在云端、還可以兩者混合起來實施。在本地部署的方案中,由于其需要擁有物理服務器,因此用戶會時常詬病于購買更多的硬件。這會讓數據倉庫的擴展性,變得更加高昂且具有挑戰性。相比之下,其云端在線存儲方案的成本較低,且具備自動化的擴展能力。
何時該使用數據倉庫
數據倉庫可被用于多項任務。例如,您可以使用它,將歷史數據存儲在一個作為單一事實源的統一環境中,以便整個組織的用戶可以依據該存儲庫,來執行日常任務。
同時,數據倉庫可以統一、并分析來自Web、客戶關系管理(CRM)、移動設備、以及其他應用程序的數據流。通過將它們轉換為可使用的格式,用戶可以采用各種分析工具,充分利用各種SQL查詢服務,提高對于存儲數據的業務理解和洞察力。例如,通過使用Google Analytics(GA),企業可以了解到客戶會如何與他們的應用程序、或網站進行互動。為了突破在深度洞察上的限制,GA還能夠與已存儲在Salesforce、Zendesk、Stripe等平臺上的數據倉庫相連接,將所有數據存儲在一處,通過分析和比較不同的變量,進而生成富有洞察力和可視化的數據視圖。
只使用數據庫不夠嗎?
傳統觀點認為,除非您擁有TB或PB的復雜數據集,否則您可能只需使用諸如PostgreSQL之類的OLTP數據庫即可搞定。然而,云計算使得數據倉庫對于更小的數據量具有了成本效益。例如,BigQuery對于首個TB量級的查詢處理是免費的。此外,無服務器類云數據倉庫的總擁有成本,也會使得分析變得更加簡單。

BigQuery的定價方案
時下流行的云數據倉庫
目前,業界有許多新興的云數據倉庫提供商,其中當屬Snowflake、Amazon Redshift、Google BigQuery和Microsoft Azure Synapse Analytics,四種最為主流和可靠。他們在成本或技術細節上雖然有所不同,但是都具有高度可擴展性等共同特征。例如,它們都采用了大規模并行處理(massively parallel processing,MPP)的方式,來同時處理多項操作的存儲結構。這樣既加速了存儲和計算資源的擴縮容,又實現了以數據列格式的存儲,所帶來的更好的壓縮和查詢特性。它們即便在發生中斷或故障時,也能保證可靠的數據復制、備份、以及快速檢索。
此外,與部署在本地的數據倉庫相比,云端方案更具有商業智能上的可擴展性,能夠加速分析操作,快速上線,提供數據的集成、可觀察性,以及整個生態系統。
數據倉庫對比一覽表
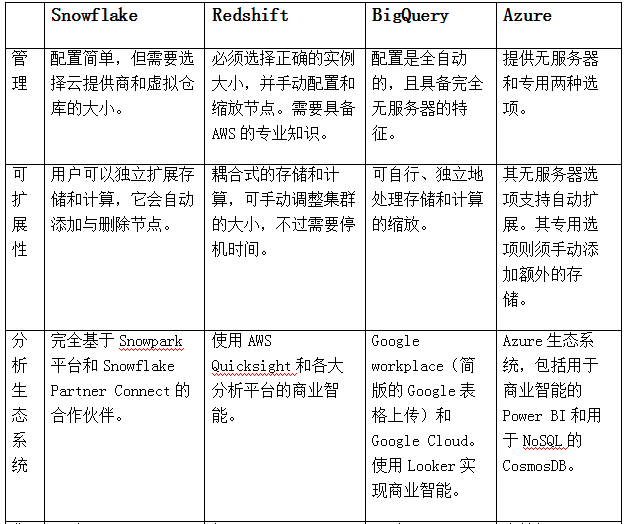

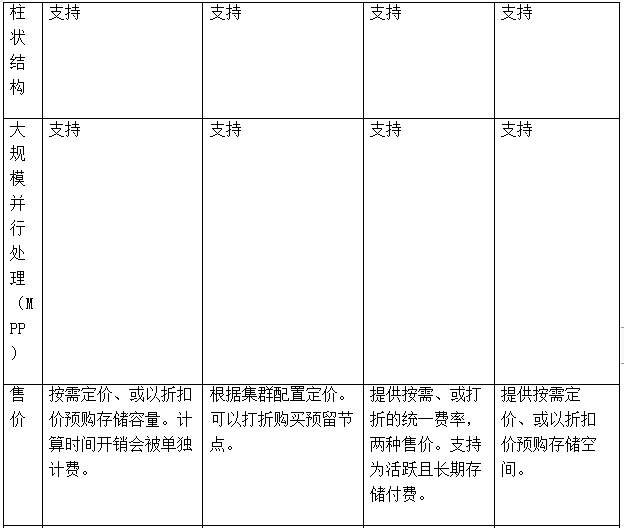

Snowflake
Snowflake是一個可運行在Google Cloud、Microsoft Azure和AWS架構之上的云數據倉庫。由于其并非運行在自己的云基礎架構上,而使用的是主流公共云服務提供商,因此它可以讓用戶更加輕松地,以跨云平臺、跨區域的方式移動數據。
Snowflake支持幾乎無限數量的并發用戶,并且可以在幾乎零維護與管理的情況下運行。與之相關的更新與清理元數據,按需擴展,按秒計費,以及許多其他瑣碎的維護任務都可以被自動化。
用戶還可以使用SQL或其他商業智能(BI)和機器學習(ML)工具,去查詢半結構化的數據。同時,Snowflake還提供了對于XML、JSON、以及Avro等文檔存儲格式的原生支持。如下圖所示,其混合架構分為:云服務層、計算層和存儲層,三個不同的層次。
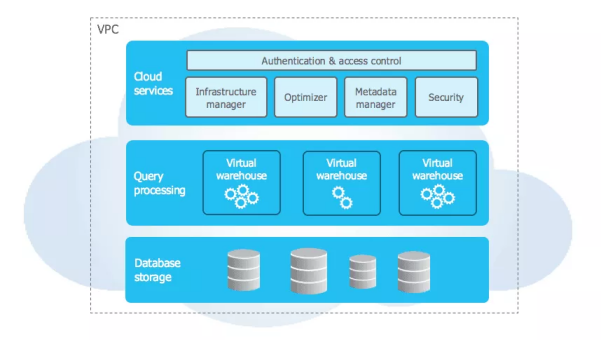
Snowflake的三層架構
作為Snowflake的主要客戶,日本樂天電子商務集團使用它來擴展其數據資源。該公司曾有一個被稱為Rakuten Rewards的現金返還和購物獎勵計劃。隨著投入CPU和內存數量的不斷增加,其用戶需求逐漸超出了現有的數據倉庫能力。通過在引入Snowflake后,樂天為各個團隊設立了專門的倉庫。由于Snowflake能夠將存儲層與計算層相分離,因此那些來自不同業務部門的工作負載,被隔離到了不同的倉庫中,避免了相互干擾。最終,樂天不但降低了整體成本,提高了數據的處理效率,而且獲得了對其數據操作上的更多可見性。
Amazon Redshift
由Amazon提供的云數據倉庫服務—Redshift,可以處理從GB到PB量級大小的數據集。在使用過程中,用戶需要先啟動一組節點并將其配置好,以便上傳并分析數據。作為Amazon Web Services(AWS)生態系統的一部分,Redshift數據倉庫服務提供了諸如將用戶數據從數據湖中導出,并與其他平臺(如:Salesforce、Google Analytics、Facebook Ads、Slack、Jira、Splunk、以及Marketo)相集成等服務。此外,Redshift倉庫服務使用列式存儲、數據壓縮、以及區域映射,來實現高性能和高效存儲。
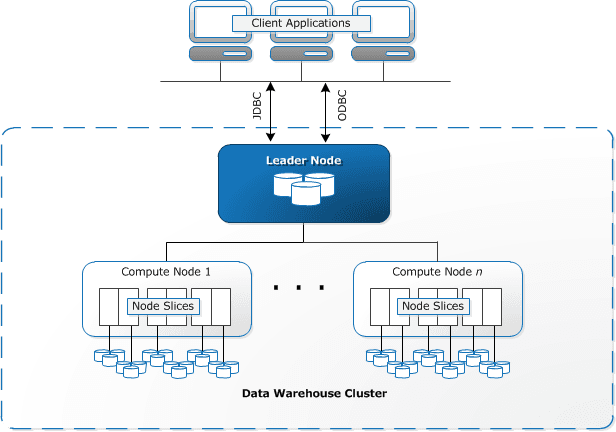
AWS Redshift 架構
目前,Redshift擁有包括Pfizer、Equinox、以及Comcast等數以萬計的客戶。2020年,全球知名連鎖餐廳--必勝客使用Redshift,來整合那些由亞太地區門店所產生的數據,以便其團隊能夠快速地訪問、查詢和可視化PB級的數據。過去需要幾小時才能生成的商業智能報告,如今幾分鐘便可搞定。
Google BigQuery
BigQuery是由Google提供的無服務器多云式數據倉庫。該服務可以快速地分析從TB到PB量級的數據。與Redshift不同,BigQuery無需預先配置,便可自動執行諸如:數據復制、以及計算資源擴展等后端操作。同時,它能夠自動加密各種靜態和傳輸中的數據。
如下圖所示,BigQuery架構是由多個組件所組成。其中,Borg是整體的計算部分;Colossus負責分布式存儲;它的執行引擎叫做Dremel;而Jupiter就是它的網絡。
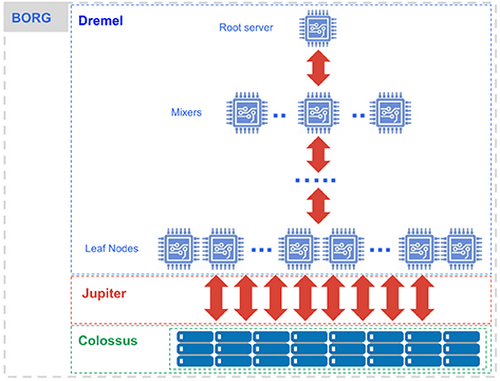
BigQuery架構
由于BigQuery能夠與其他Google Cloud產品協同工作,因此其用戶包括Dow Jones、Twitter、The Home Depot、以及UPS等知名企業。例如,豐田的加拿大公司就曾建立了一個名為Build & Price的比較工具,以方便網站訪客定制車輛,并獲得即時報價。這些數據會由Google Analytics 360負責收集,并被提取到BigQuery中。然后,其倉儲服務會將機器學習(ML)模型應用到這些數據上,并根據購買的可能性,為每個訪客分配一個傾向得分。這些預測得分會每八小時刷新一次,并持續被導入Analytics 360。據此,豐田根據傾向得分創建了不同的群體,進而向每個群體投放個性化的廣告。
Azure Synapse Analytics
由Microsoft提供的云數據倉庫--Azure Synapse Analytics,通過統一的用戶界面(UI)將數據倉庫、數據集成、以及大數據分析結合在一起。借助在無代碼環境中構建的ETL/ELT流程,用戶不但可以從近百個本地連接器中提取數據,也可以通過集成化的人工智能(AI)和商業智能工具,實現Azure機器學習、認知服務、以及Power BI。此外,該智能工具還可以輕松地被應用于包括Dynamics 365、Office 365、以及各種SaaS產品的數據集中。
在Azure Synapse Analytics中,用戶能夠使用T-SQL、Python、Scala、以及.NET等語言,以預配置或無服務器的方式,按需分析數據資源。

Azure Synapse Analytics體系結構
目前,Microsoft的云數據倉庫服務擁有眾多的客戶。其中作為零售和批發藥業巨頭的Walgreens,已經將其庫存管理數據遷移到了Azure Synapse處,以便供應鏈分析師能夠在其界面上,通過直接拖放和調用Power BI工具的方式,來查詢并創建可視化的數據,進而降低了整體投入的成本。
選擇云數據倉庫時需要考慮的因素
用例
用戶的獨特運行環境和用例,往往是評估數據倉庫提供商的關鍵因素之一。例如,使用JSON的企業可能會更喜歡Snowflake,畢竟它為該格式提供了原生支持。而沒能配備專門數據管理員的小型組織,可能會避免使用Redshift,畢竟它需要定期監控和配置。對此,那些具有即插即用設置(plug-and-play)的服務,可能會更適合它們。
支持實時的負載
許多公司需要在數據生成之后,立即對其進行分析。例如,一些公司可能需要實時地檢測各種欺詐或安全問題,而另一些公司可能需要處理大量的物聯網(IoT)數據流,以進行異常檢測。對此,IT團隊應重點評估云數據倉庫是如何處理數據流的攝取。例如:BigQuery提供了一個流式的API,用戶只需幾行代碼即可完成調用。Azure為實時數據的攝入提供了內置的Apache Spark流等功能選項。Snowflake將Snowpipe作為附加組件,以實現實時的攝入。而RedShift則需要使用Kinesis Firehose,來實現數據流的攝取。
安全性
雖然每一個云數據倉庫提供商都非常重視安全性,但是它們在技術上,特別是加密處理方式上會有所差異。例如,BigQuery能夠在默認情況下,對傳輸中和靜止的數據進行加密;而該功能需要在Redshift中得到明確的啟用。
計費
由于提供商會以不同的方式來為服務計費,因此公司需要估算并知曉,他們期望每個月花費在集成、存儲和分析的數據量與成本。據此,IT團隊可以選擇性價比高的云數據倉庫提供商。
例如:Redshift會將計算資源和存儲捆綁在一起,因此用戶需要在接受預購的存儲和內存容量的前提下,選用其簡單的定價方案。Google會根據字節讀取、流式插入、以及存儲空間,來收取服務費。不過,由于讀取的字節數往往會產生波動,因此由BigQuery采取的計費方式雖然精細,但是其成本難以被預測。Azure Synapse使用數據倉庫單元(DWU)的概念,來為計算資源的定價,以便向用戶單獨收取存儲的費用。Snowflake會根據用戶使用到的虛擬倉庫的數量和時長,進行計費;而它在存儲方面,則是按照每月使用到的TB數量,來單獨計費。
生態系統
生態系統對于應用程序和數據的留存也是非常重要的。例如:那些數據已經被存放在Google Cloud中的企業,可以通過使用BigQuery或Snowflake,來獲得額外的性能提升。同時,由于共享著相同的基礎設施,因此他們的數據非但不會在公共互聯網上移動,而且其傳輸路徑也會得到更好的優化。
數據類型
企業往往會用到結構化、半結構化、以及非結構化的數據,而大多數數據倉庫只能支持前兩種數據類型。因此,IT團隊應當根據實際需求,確保選擇的云倉庫基礎設施,能夠存儲和查詢到特殊類型的數據。
擴縮容
既然是云數據倉庫,那么針對存儲和性能的擴展能力就需要被納入評估的范疇。對此,Redshift要求用戶手動添加更多的節點,以增加存儲和算力資源。而Snowflake則具有自動擴縮容的功能,可以動態添加或刪除各個節點。
維護
根據公司的規模和數據的不同需求,數據倉庫應當通過提供自動或手動的方式,來實現日常的管理與維護。小型團隊可以選用BigQuery或Snowflake所提供的自動優化服務。而Redshift等云數據倉庫則提供了更具靈活性和掌控度的、手動級別的維護方式,以便用戶團隊更好地優化其數據資產。
小結
我們從各項參數、技術規格、以及定價模型等方面,為您綜合比較了Snowflake、Redshift、BigQuery、以及Azure Synapse Analytics,這四種典型的云數據倉庫。希望根據上述給出的考慮因素,您和您的團隊能夠從公司業務的實際需求出發,選定合適的服務提供商及其產品,讓云數據倉庫為貴司的產品、市場、銷售、以及其他部門,提升數據的洞察力,減少盲目的猜測,并為激烈的競爭優勢鋪平道路。
原文標題:Cloud Data Warehouse Comparison: Redshift vs BigQuery vs Azure vs Snowflake for Real-Time Workloads,作者: Mariana Park
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】
















