如何一次性訓練100,000+個Vision Transformers?
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
經過漫長的等待,ICCV 2021終于迎來放榜時刻!
ICCV官方在推特上公布了這一消息,并表示今年共有6236篇投稿,最終1617篇論文被接收,接收率為25.9%,相比于2017年(約29%),保持了和2019年相當的較低水平。
而投稿量則依舊逐年大幅增長,從2017年的2143篇,到2109年的4328篇,再到如今的6236篇,相比上一屆多了50%左右。
你看郵件的時候是這表情嗎?
不得不說,官方皮起來也是接地氣、真扎心、沒誰了哈哈~
論文ID地址:https://docs.google.com/spreadsheets/u/1/d/e/2PACX-1vRfaTmsNweuaA0Gjyu58H_Cx56pGwFhcTYII0u1pg0U7MbhlgY0R6Y-BbK3xFhAiwGZ26u3TAtN5MnS/pubhtml
也就在今天,AI科技評論發現了一項非常厲害的研究,號稱可一次性訓練10萬個ViT,論文也剛剛喜提ICCV accepted!
近來,Vision Transformer (ViT) 模型在諸多視覺任務中展現出了強大的表達能力和潛力。
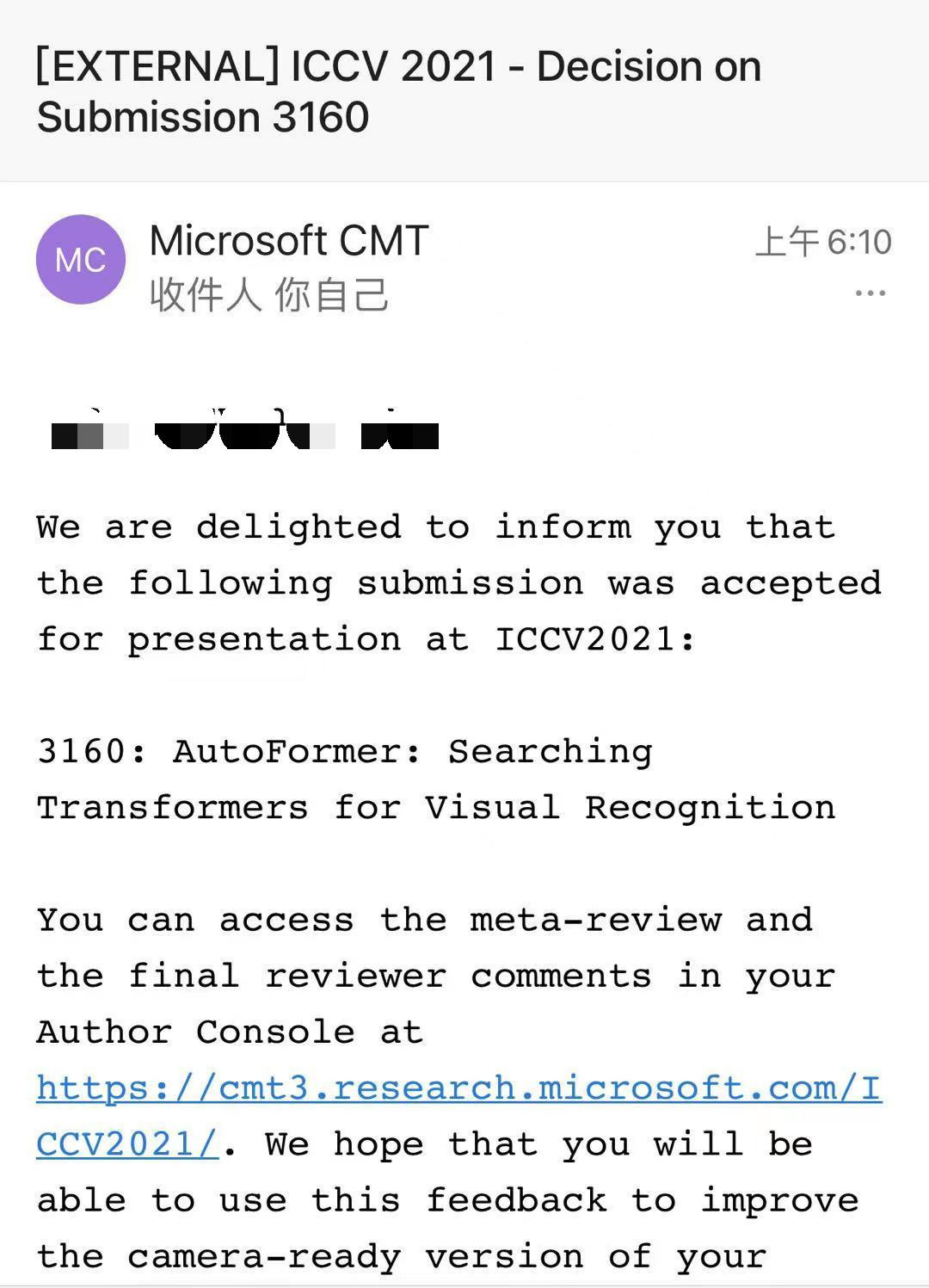
紐約州立大學石溪分校與微軟亞洲研究院的研究人員提出了一種新的網絡結構搜索方法AutoFormer,用來自動探索最優的ViT模型結構。
AutoFormer能一次性訓練大量的不同結構的ViT模型,并使得它們的性能達到收斂。
其搜索出來的結構對比手工設計的ViT模型有較明顯的性能提升。

方法亮點:
-
同時訓練大量Vision Transformers模型,使其性能接近單獨訓練;
-
簡單有效,能夠靈活應用于Vision Transformer的變種搜索;
-
性能較ViT, DeiT等模型有較明顯提升。
論文地址:https://arxiv.org/abs/2107.00651
代碼地址:https://github.com/microsoft/AutoML/tree/main/AutoFormer
1. 引言
最近的研究發現,ViT能夠從圖像中學習強大的視覺表示,并已經在多個視覺任務(分類,檢測,分割等)上展現出了不俗的能力。
然而,Vision Transformer 模型的結構設計仍然比較困難。例如,如何選擇最佳的網絡深度、寬度和多頭注意力中的頭部數量?
作者的實驗發現這些因素都和模型的最終性能息息相關。然而,由于搜索空間非常龐大,我們很難人為地找到它們的最佳組合。

圖1: 不同搜索維度的變化會極大地影響模型的表現能力
本文的作者提出了一種專門針對Vision Transformer 結構的新的Neural Architecture Search (NAS) 方法 AutoFormer。AutoFormer大幅節省了人為設計結構的成本,并能夠自動地快速搜索不同計算限制條件下ViT模型各個維度的最佳組合,這使得不同部署場景下的模型設計變得更加簡單。

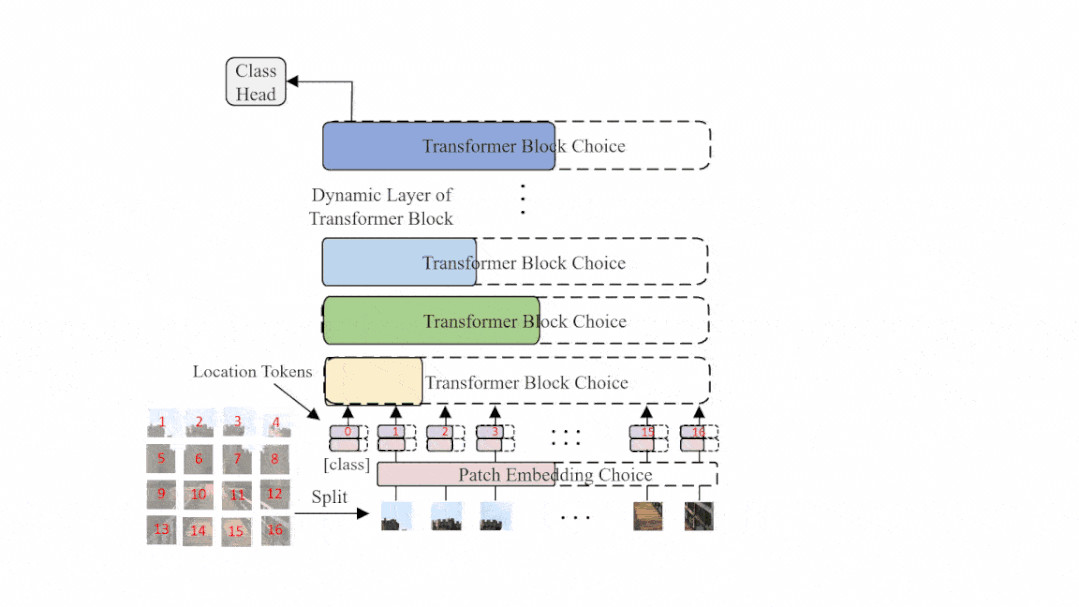
圖2: AutoFormer的結構示意圖,在每一個訓練迭代中,超網會動態變化并更新相應的部分權重
2. 方法
常見的One-shot NAS 方法[1, 2, 3]通常采取權重共享的方式來節省計算開銷,搜索空間被編碼進一個權重共享的超網 (supernet) 中,并運用超網權重作為搜索空間中結構權重的一個估計。其具體搜索過程可分為兩個步驟,第一步是更新超網的權重,如下公式所示。

第二步是利用訓練好的超網權重來對搜索空間中結構進行搜索。
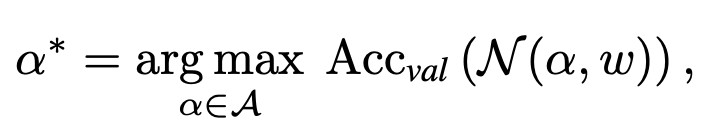
在實驗的過程中,作者發現經典One-shot NAS方法的權重共享方式很難被有效地運用到Vision Transformer的結構搜索中。這是因為之前的方法通常僅僅共享結構之間的權重,而解耦同一層中不同算子的權重。
如圖3所示,在Vision Transformer的搜索空間中,這種經典的策略會遇到收斂緩慢和性能較低的困難。
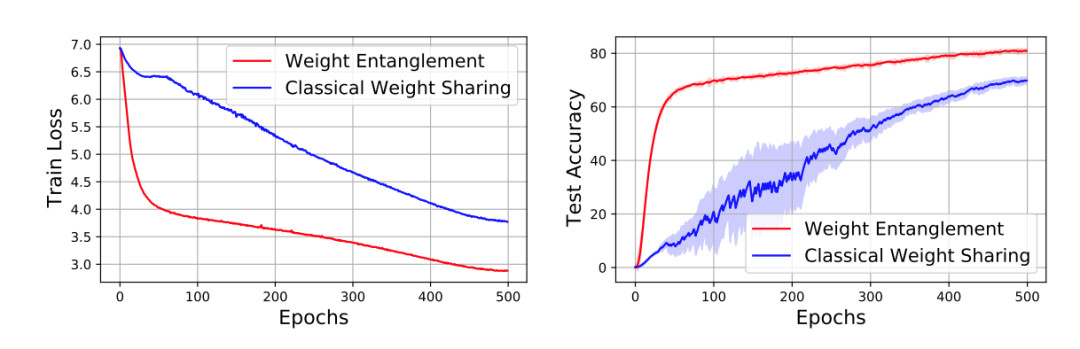
圖3 權重糾纏和經典權重共享的訓練以及測試對比
受到OFA [4], BigNAS [5] 以及Slimmable networks [6, 7] 等工作的啟發,作者提出了一種新的權重共享方式——權重糾纏 (Weight Entanglement)。
如圖4所示,權重糾纏進一步共享不同結構之間的權重,使得同一層中不同算子之間能夠互相影響和更新,實驗證明權重糾纏對比經典的權重共享方式,擁有占用顯存少,超網收斂快和超網性能高的優勢。
同時,由于權重糾纏,不同算子能夠得到更加充分的訓練,這使得AutoFormer能夠一次性訓練大量的ViT模型,且使其接近收斂。(詳情見實驗部分)
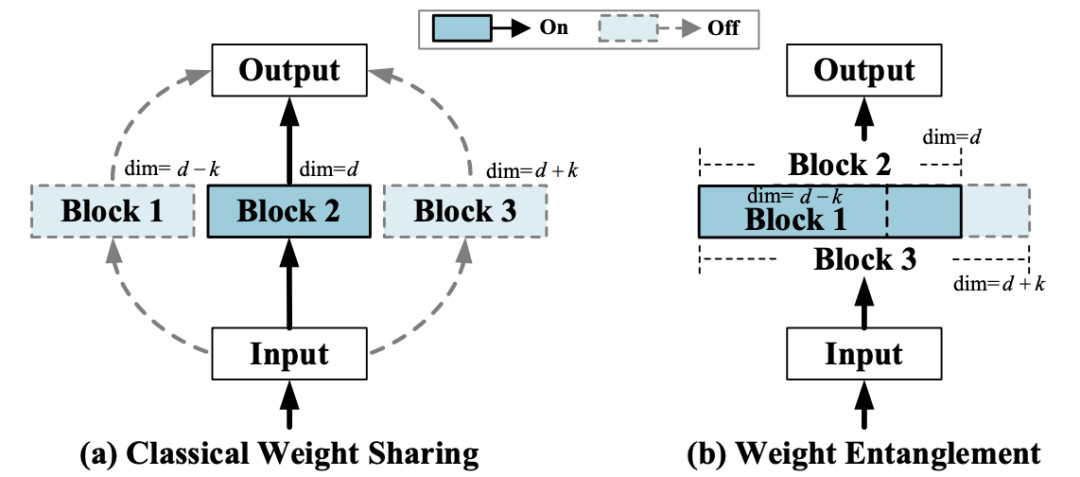
圖4 權重糾纏和權重共享的對比示意圖
3. 實驗
作者設計了一個擁有超過1.7x10^17備選結構的巨大搜索空間,其搜索維度包括ViT模型中的五個主要的可變因素:寬度 (embedding dim)、Q-K-V 維度 (Q-K-V dimension)、頭部數量 (head number)、MLP 比率 (MLP ratio) 和網絡深度 (network depth),詳見表1。
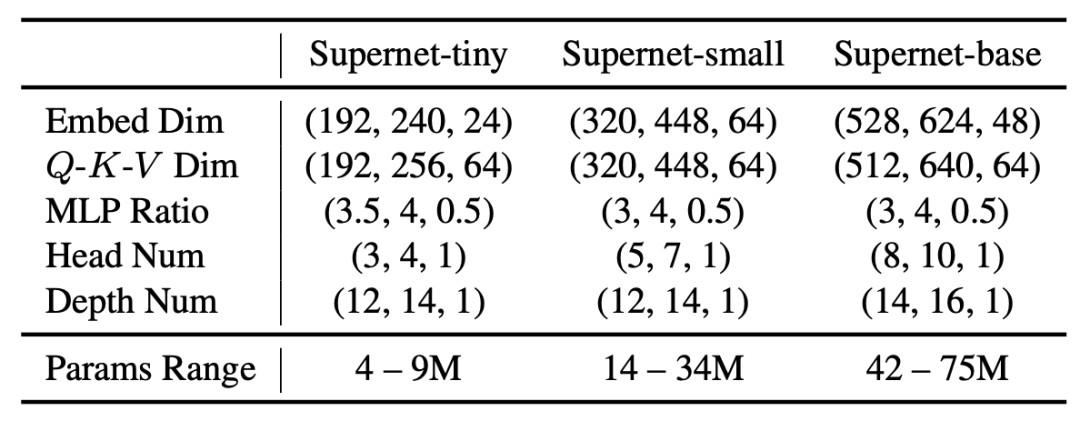
表1:AutoFormer的搜索空間
為了驗證方法的有效性,作者將AutoFormer搜索得到的結構和近期提出的ViT模型以及經典的CNN模型在ImageNet上進行了比較。
對于訓練過程,作者采取了DeiT [8]類似的數據增強方法,如 Mixup, Cutmix, RandAugment等, 超網的具體訓練參數如表2所示。所有模型都是在 16塊Tesla V100 GPU上進行訓練和測試的。
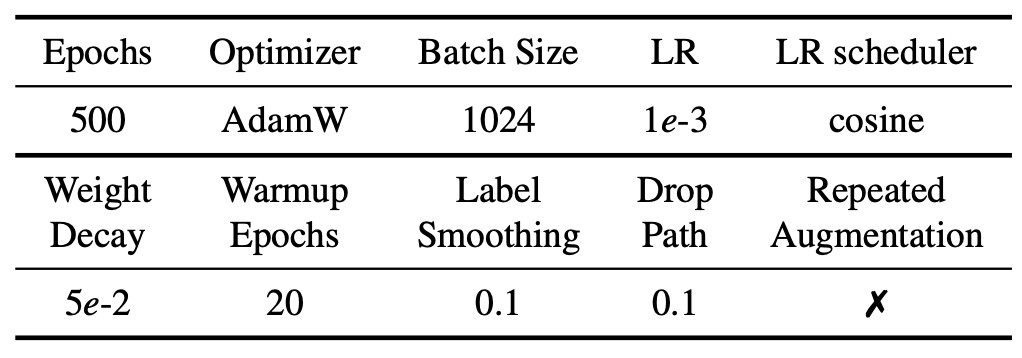
表2 超網的訓練參數
如圖5 和表3所示,搜索得到的結構在ImageNet數據集上明顯優于已有的ViT模型。
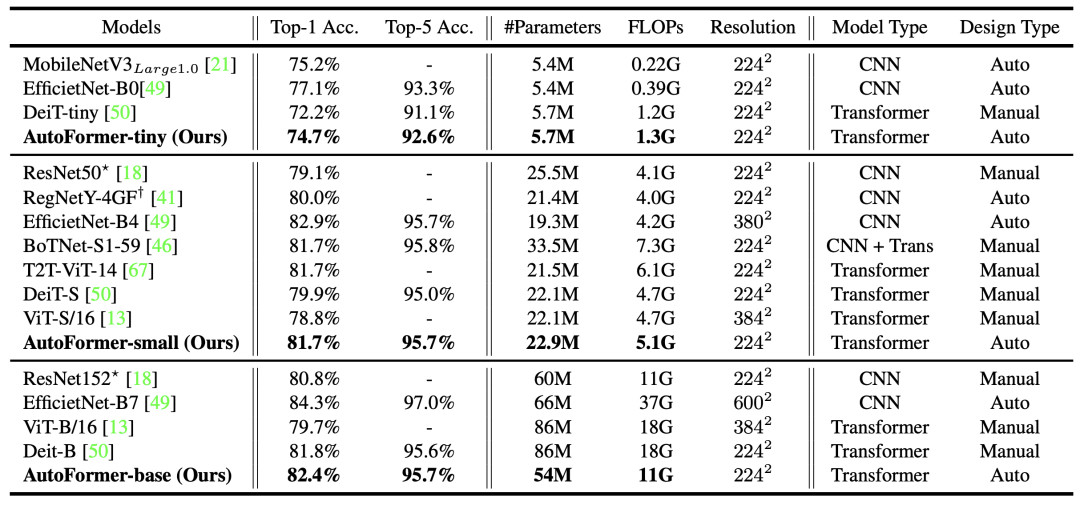
表3:各個模型在ImageNet 測試集上的結果
從表4中可以看出,在下游任務中,AutoFormer依然表現出色,利用僅僅25%的計算量就超越了已有的ViT和DeiT模型,展現了其強大的泛化性能力。

表4:下游分類任務遷移學習的結果
同時,如圖5所示,利用權重糾纏,AutoFormer能夠同時使得成千上萬個Vision Transformers模型得到很好的訓練(藍色的點代表從搜索空間中選出的1000個較好的結構)。
不僅僅使得其在搜索后不再需要重新訓練(retraining)結構,節約了搜索時間,也使得其能在各種不同的計算資源限制下快速搜索最優結構。
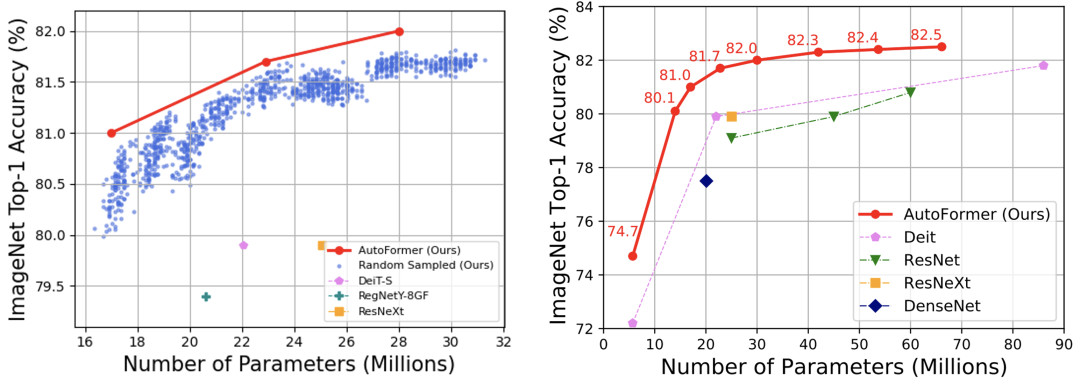
圖5:左:AutoFormer能夠同時訓練大量結構,并使得其接近收斂。藍色的點代表從搜索空間中選出的1000個較好的結構。右:ImageNet上各模型對比
4. 結語
本文提出了一種新的專用于Vision Transformer結構搜索的One-shot NAS方法—— AutoFormer。AutoFormer 配備了新的權重共享機制,即權重糾纏 (Weight Engtanglement)。在這種機制下,搜索空間的網絡結構幾乎都能被充分訓練,省去了結構搜索后重新訓練(Retraining)的時間。大量實驗表明所提出的算法可以提高超網的排序能力并找到高性能的結構。在文章的最后,作者希望通過本文給手工ViT結構設計和NAS+Vision Transformer提供一些靈感。在未來工作,作者將嘗試進一步豐富搜索空間,以及給出權重糾纏的理論分析。