這些 Kubernetes 多集群的思考,運維了解一下~
隨著 Kubernetes 在企業中應用的越來越廣泛和普及,越來越多的公司在生產環境中運維多個集群。本文主要講述一些關于多集群 Kubernetes 的思考,包括為什么選擇多集群,多集群的好處以及多集群的落地方案。
VMware2020 年 Kubernetes 使用報告中指出,在采用 kubernetes 組織中 20%的組織運行 40+數目的集群。
為什么企業需要多集群?
單集群 Kubernetes 承載能力有限
首先看看官方文檔中關于單集群承載能力的描述:
在 v1.12,Kubernetes 支持最多具有 5000 個節點的集群。更具體地說,我們支持滿足以下所有條件的配置:
- 不超過 5000 個節點
- Pod 總數不超過 150000
- 總共不超過 300000 個容器
- 每個節點不超過 100 個 Pod
雖然現在 Kubernetes 已經發展到 v1.20,但是關于單集群承載能力一直沒有變化。可見提高單集群負載能力并不是社區的發展方向。
如果我們的業務規模超過了 5000 臺,那么企業不得不考慮多個集群。
混合云或是多云架構決定了需要多個集群
到目前,其實多云或是混合云的架構很普遍了。
比如企業是一個全球化的公司,提供 Global 服務。
或像新浪微博一樣,自建數據中心 + 阿里云,阿里云用于服務彈性流量。
另外公有云并沒有想象中的海量資源。比如公有云的頭部客戶搞大促需要很大數量機器的時候,都是需要提前和公有云申請,然后公有云提前準備的。
為了避免被單家供應商鎖定,或是出于成本等考慮,企業選擇了多云架構,也決定了我們需要多個集群。
不把雞蛋放到一個籃子里
即使前面兩條都未滿足,那么我們是否要把所有的工作負載部署到一個集群哪?
如果集群控制面出現故障,那么所有的服務都會受到影響。
也許大家認為 Kubernetes 的控制面本身就是高可用的(三個 api-server),不會有整個控制層不可用的可能。
其實則不然,我們在生產環境中,已經處理很多次類似故障了。如果一個應用(一般指需要調用 api-server 接口)在大量地調用 api-server,會導致 api-server 接連掛掉,最終不可用。直到找到故障應用,并把故障應用刪除。
所以在生產環境中,一是需要嚴格控制訪問 api-server 的權限,二是需要做好測試,三是可以考慮業務應用和基礎設施分開部署。其實單集群和多集群的選擇和”選擇一臺超算 or 多臺普通機器“的問題類似。后來分布式計算的發展說明大家選擇了多個普通機器。
多集群的好處
多集群在以下三個方面,有著更好地表現:
- 可用性
- 隔離性
- 擴展性
多集群應用程序架構
實際上,可以通過兩種模型來構建多集群應用程序架構
- 副本 :將應用程序復制到多個可用性區域或數據中心,每個集群都運行應用程序的完整副本。我們可以依靠 Smart DNS(在 GCP,有 Global 負載均衡器的概念) 將流量路由到距離用戶最近的集群,以實現最小的網絡延遲。如果我們一個集群發生故障,我們可以將流量路由到其他健康集群,實現故障轉移。
- 按服務劃分:按照業務相關程度,將應用部署在不同的集群。這種模型,提供了非常好的隔離性,但是服務劃分卻比較復雜。
社區多集群落地方案
實際上,社區一直在探索多集群 Kubernetes 的最佳實踐,目前來看主要有以下兩種。
以 Kubernetes 為中心
著力于支持和擴展用于多集群用例的核心 Kubernetes 原語,從而為多個集群提供集中式管理平面。Kubernetes 集群聯邦項目采用了這種方法。
理解集群聯邦的最好方法是可視化跨多個 Kubernetes 集群的元集群。想象一下一個邏輯控制平面,該邏輯控制平面編排多個 Kubernetes 主節點,類似于每個主節點如何控制其自身集群中的節點。
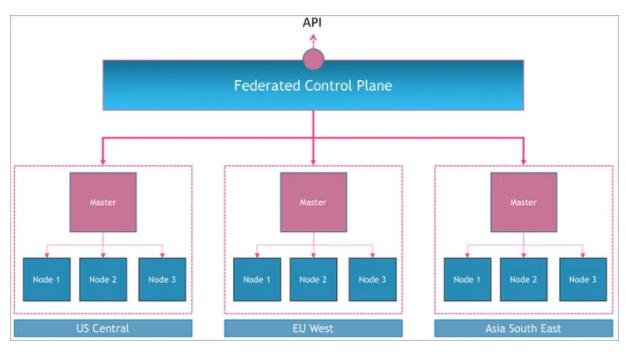
其實集群聯邦本質上做了兩件事情:
- 跨集群分發資源:通過抽象 Templates ,Placement,Overrides 三個概念,可以實現將資源(比如 Deployment)部署到不通的集群,并且實現多集群擴縮。
- 多集群服務發現:支持多集群 Service 和 Ingress。截止到目前,聯邦項目尚處于 alpha 狀態,當我們選擇落地的時候,需要一定量的開發工作。
以網絡為中心
以網絡為中心的方法專注于在集群之間創建網絡連接,以便集群內的應用程序可以相互通信。
Istio 的多集群支持,Linkerd 服務鏡像和 Consul 的 Mesh 網關是通過 Service mesh 解決方案來實現網絡連通。
而另外一種是 Cilium 關于多集群網絡的方案。Cilium 本身是一種 CNI 網絡,該方案少了服務治理的功能。
Cilium Cluster Mesh 解決方案通過隧道或直接路由,解決跨多個 Kubernetes 集群的 Pod IP 路由,而無需任何網關或代理。當然我們需要規劃好每個集群的 POD CIDR。
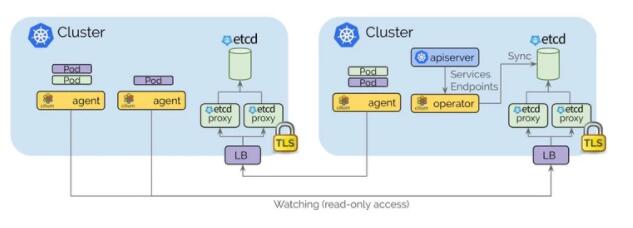
- 每個 Kubernetes 集群都維護自己的 etcd 集群,其中包含該集群的狀態。來自多個集群的狀態永遠不會混入 etcd 中。
- 每個集群通過一組 etcd 代理公開其自己的 etcd。在其他集群中運行的 Cilium 代理連接到 etcd 代理以監視更改,并將多集群相關狀態復制到自己的集群中。使用 etcd 代理可確保 etcd 觀察程序的可伸縮性。訪問受 TLS 證書保護。
- 從一個集群到另一個集群的訪問始終是只讀的。這樣可以確保故障域保持不變,即一個集群中的故障永遠不會傳播到其他集群中。
- 通過簡單的 Kubernetes secret 資源進行配置,該資源包含遠程 etcd 代理的尋址信息以及集群名稱和訪問 etcd 代理所需的證書。
思考
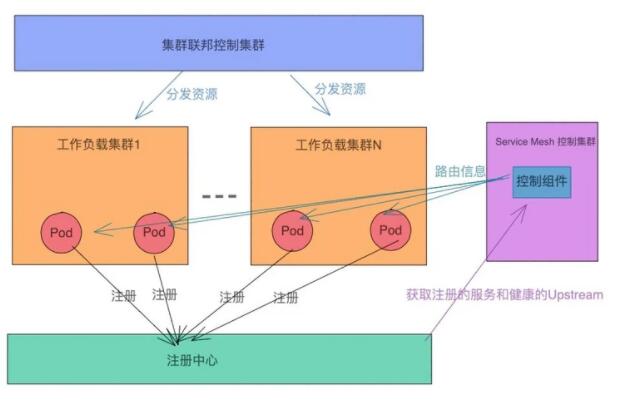
上面我們講到了兩種落地多集群 Kubernetes 的方案,其實并不是非 A 即 B。
比如,當我們在落地大集群的過程中,很多公司只是用 Kubernetes 解決部署的問題。服務發現選擇 consul,zk 等注冊中心,配置文件管理使用配置中心,負載均衡也沒有使用 kubernetes 中 Service。
此時結合兩種方案是最佳實踐。
集群聯邦解決部署和發布的問題。Service mesh 解決多集群流量訪問的問題。不過此時,工作負載集群中的 Pod,Service mesh 的控制面以及網關都需要對接外部的注冊中心。具體架構如下: