為了讓AI不斷打怪升級,DeepMind打造了一個“元宇宙”
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
DeepMind又冷不丁給了我們一個小驚喜。
我們都知道,強化學習苦于泛化能力差,經常只能針對單個任務來從頭開始學習。
像DeepMind之前開發的AlphaZero,盡管可以玩轉圍棋、國際象棋和日本將棋,但對每種棋牌游戲都只能從頭開始訓練。
泛化能力差也是AI一直被詬病為人工智障的一大原因。人類智能厲害的一點就是,可以借鑒之前的經驗,迅速適應新環境,比如你不會因為是第一次吃川菜,就看著一口鴛鴦鍋不知所措,你吃過潮汕火鍋嘛,不都是涮一下的事情嘛。
但是,泛化能力也不是一蹴而就的,就像我們玩游戲的時候,也是先做簡單任務,然后逐步升級到復雜任務。在游戲《空洞騎士》中,一開始你只需要隨意走動揮刀砍怪就行,但在噩夢級難度的“苦痛之路”關卡中,沒有前面一點點積累的爛熟于心的技巧,只能玩個寂寞。
1、多任務元宇宙
DeepMind此次就采用了這種“課程學習”思路,讓智能體在不斷擴展、升級的開放世界中學習。也就是說,AI的新任務(訓練數據)是基于舊任務不斷生成的。
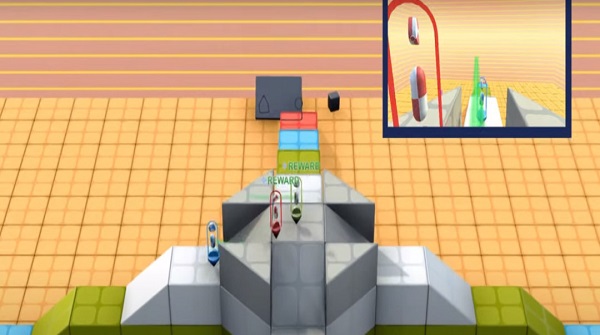
在這個世界中,智能體可以盡情鍛煉自己,簡單的比如“靠近紫色立方體”,復雜一點的比如“靠近紫色立方體或將黃色球體放在紅色地板上”,甚至還可以和其他智能體玩耍,比如捉迷藏——“找到對方,并且不要被對方找到”。
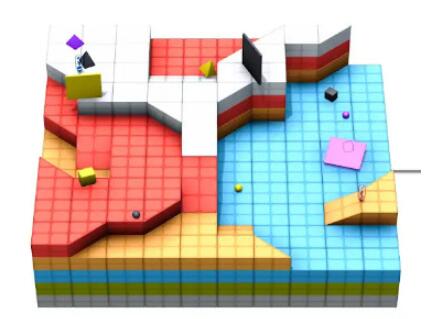
每個小游戲存在于世界的一個小角落,千千萬萬個小角落拼接成了一個龐大的物理模擬世界,比如下圖中的幾何“地球”。
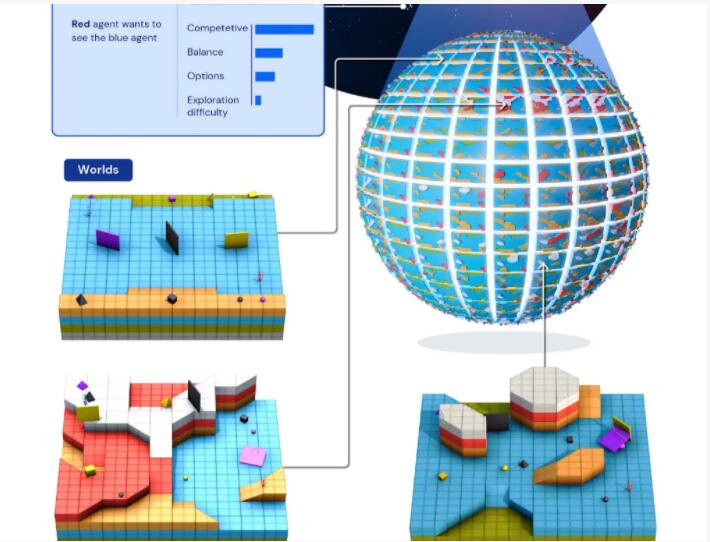
總體來說這個世界的任務由三個要素構成,即任務=游戲+世界+玩家,并根據三個要素的不同關系,決定任務的復雜度。
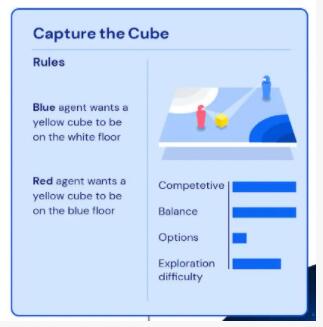
復雜度的判斷有四個維度:競爭性,平衡性,可選項,探索難度。
比如在“搶方塊”游戲中,藍色智能體需要把黃色方塊放到白色區域,紅色智能體需要把黃色方塊放到藍色區域。這兩個目標是矛盾的,因此競爭性比較強;同時雙方條件對等,平衡性比較高;因為目標簡單,所以可選項少;這里DeepMind把探索難度評為中上,可能是因為定位區域算是比較復雜的場景。
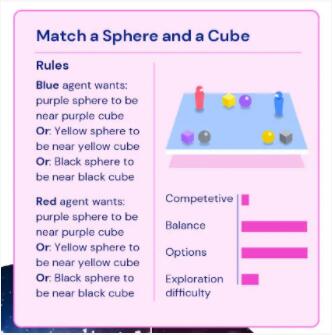
再例如,在“球球喜歡和方塊一起玩”游戲中,藍色和紅色智能體都有一個共同的目標,讓相同顏色的球體和方塊放在相近的位置。
這時候,競爭性自然很低;平衡性毋庸置疑是很高的;可選項相比上面的游戲會高很多;至于探索難度,這里沒有定位區域,智能體隨便把球體和方塊放哪里都行,難度就變小了。
基于這四個維度,DeepMind打造了一個任務空間的、超大規模的“元宇宙”,幾何“地球”也只是這個元宇宙的一個小角落,限定于這個四維任務空間的一個點。DeepMind將這個“元宇宙”命名為Xland,它包含了數十億個任務。
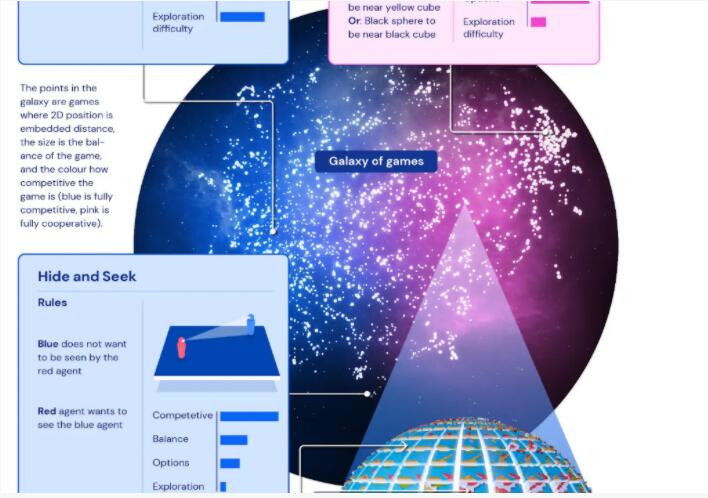
來看看XLand的全貌,它由一系列游戲組成,每個游戲都可以在許多不同的模擬世界中進行,這些世界的拓撲和特征平滑地變化。

2、終生學習
數據有了,那么接下來就得找到合適的算法。DeepMind發現,目標注意網絡 (GOAT) 可以學習更通用的策略。
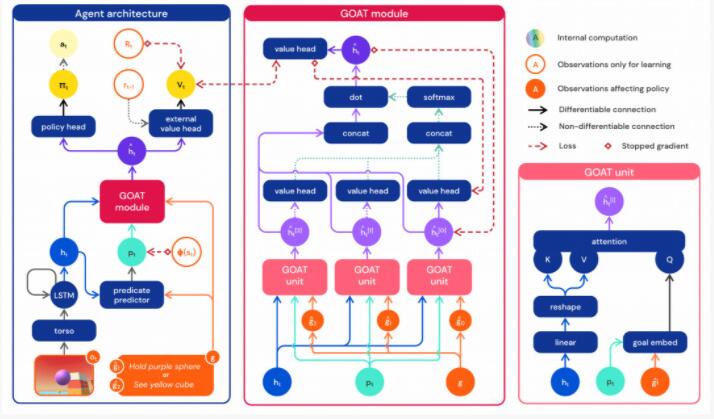
具體來說,智能體的輸入包括第一視角的RGB圖像、本體感覺以及目標。經過初步處理后,生成中間輸出,傳遞給GOAT模塊,該模塊會根據智能體的當前目標處理中間輸出的特定部分,并對目標進行邏輯分析。
所謂邏輯分析是指,對每個游戲,可以通過一些方法,來構建另一個游戲,并限制策略的價值函數的最優值上限或者下限。
到這里,DeepMind向我們提出了一個問題:對于每個智能體,什么樣的任務集合才是最好的呢?換句話說,在打怪升級中,什么樣的關卡設置才會讓玩家能順利地升級為“真”高手,而不是一刀9999?
DeepMind給出的答案是,每個新任務都基于舊任務生成,“不會太難,也不會太容易”。其實,這恰好是讓人類學習時感到“爽”的興奮點。
在訓練開始時,太難或太容易的任務可能會鼓勵早期學習,但會導致訓練后期的學習飽和或停滯。
實際上,我們不要求智能體在一個任務上非常優秀,而是鼓勵其終身學習,即不斷去適應新任務。
而所謂太難、太容易其實是比較模糊的描述。我們需要的是一個量化方法,在新任務和舊任務之間做彈性連接。
怎么不讓智能體在新任務中因為不適應而“暴死”呢?進化學習就提供了很好的靈活性。總體來說,新任務和舊任務是同時進行的,并且每個任務有多個智能體參與“競爭”。在舊任務上適應得好的智能體,會被選拔到新任務上繼續學習。
在新任務中,舊任務的優秀智能體的權重、瞬時任務分布、超參數都會被復制,參與新一輪“競爭”。
并且,除了舊任務中的優秀智能體,還有很多新人參與,這就引進了隨機性、創新性、靈活性,不用擔心“暴死”問題。
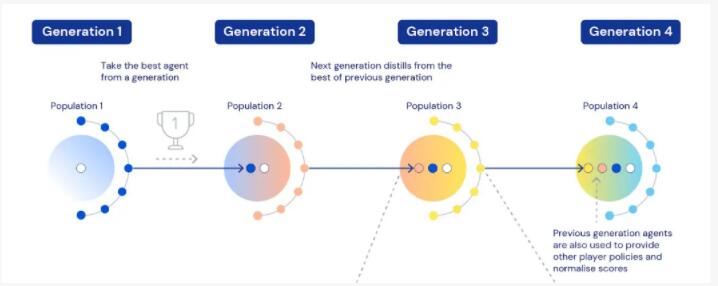
當然,在每個任務中不會只有一種優秀智能體。因為任務也是不斷在生成的、動態變化的,一個任務可以訓練出有不同長處的智能體,并往不同的方向演化(隨著智能體的相對性能和魯棒性進行)。
最終,每個智能體都會形成不同的擅長任務的集合,像極了春秋戰國時期的“百家爭鳴”。說打怪升級顯得格局小了,這簡直是在模擬地球嘛。
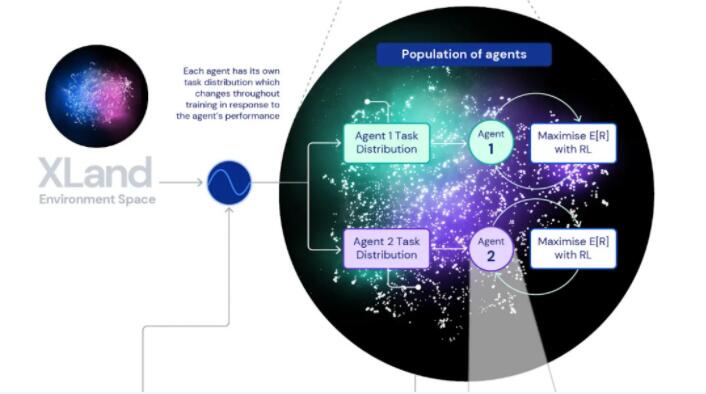
DeepMind表示,“這種組合學習系統的迭代特性是,不優化有界性能指標,而是優化迭代定義的通用能力范圍,這使得智能體可以開放式地學習,僅受環境空間和智能體的神經網絡表達能力的限制。”
3、智能初現
最終,在這個復雜“元宇宙”中升級、進化、分流的智能體形成了什么優秀物種呢?
DeepMind說道,智能體有很明顯的零樣本學習能力,比如使用工具、打圍、數數、合作&競爭等等。

來看幾個具體的例子。
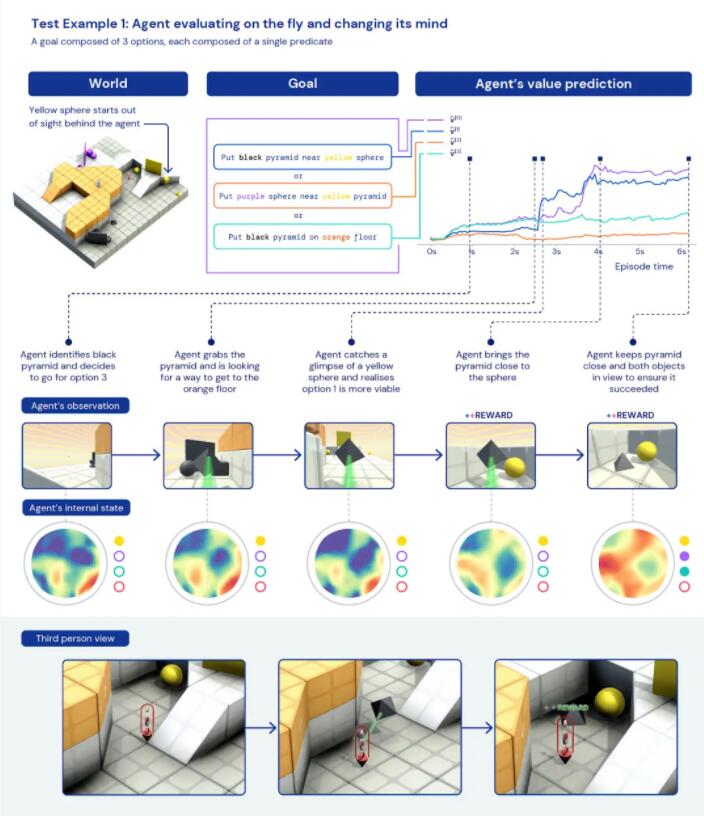
首先是,智能體學會了臨場應變。它的目標有三個:
- 將黑色金字塔放到黃色球體旁邊;
- 將紫色球體放到黃色金字塔旁邊;
- 將黑色金字塔放到橙色地板上。
AI一開始找到了一個黑色金字塔,想著把它拿到橙色地板上(目標3),但在搬運過程中瞄見了一個黃色球體,瞬間改變主意,“我可以實現目標1啦”,將黑色金字塔放到了黃色球體旁邊。
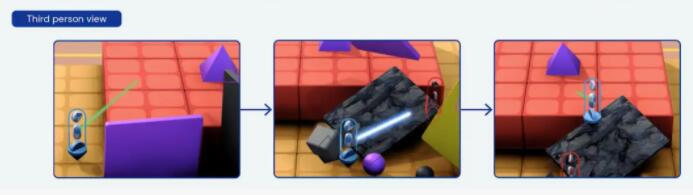
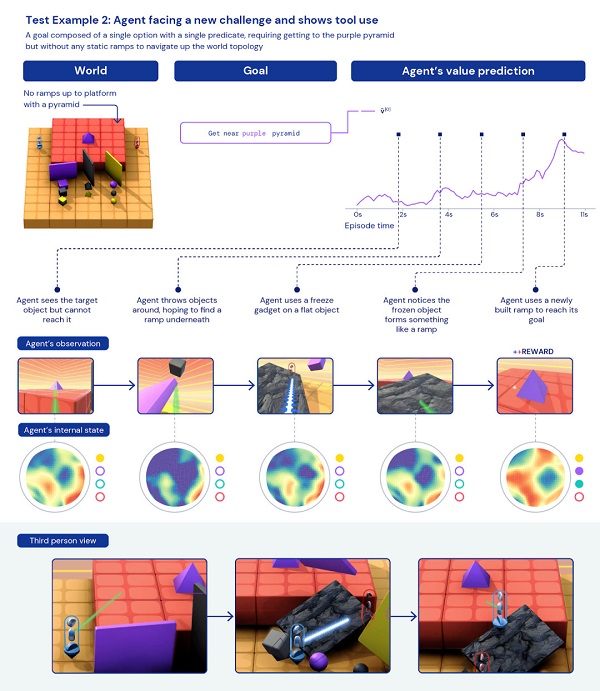
第二個例子是,不會跳高,怎么拿到高臺上的紫色金字塔?
在這個任務中,智能體需要想辦法突破障礙,取到高臺上的紫色金字塔,高臺周邊并沒有類似階梯、斜坡一樣的路徑。
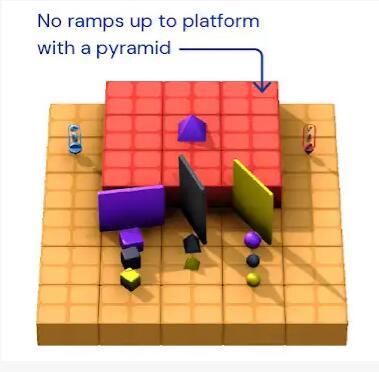
因為不會調高,所以智能體急的“掀桌子”,把周邊的幾塊豎起來的板子都弄倒了。然后,巧的是,一塊黑色石板倒在高臺邊上,“咦,等等,這不就是我要的階梯嗎?”
這個過程是否體現了智能體的智能,還無法肯定,可能只是一時的幸運罷了。關鍵還是,要看統計數據。
經過5代訓練,智能體在 XLand 的 4,000 個獨立世界中玩大約 700,000 個獨立游戲,涉及340 萬個獨立任務的結果,最后一代的每個智能體都經歷了 2000 億次訓練步驟。
目前,智能體已經能夠順利參與幾乎每個評估任務,除了少數即使是人類也無法完成的任務。
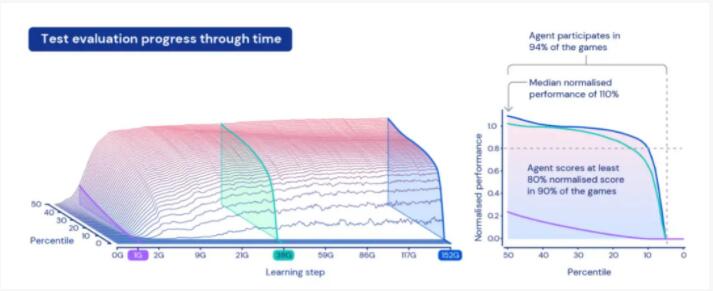
DeepMind的這項研究,或許一定程度上體現了“密集學習”的重要性。也就是說,不僅是數據量要大,任務量也要大。這也使得智能體在泛化能力上有很好的表現,比如數據顯示,只需對一些新的復雜任務進行 30 分鐘的集中訓練,智能體就可以快速適應,而從頭開始用強化學習訓練的智能體根本無法學習這些任務。
在往后,我們也期待這個“元宇宙”變得更加復雜和生機勃勃,AI經過不斷演化,不斷給我們帶來驚喜(細思極恐)的體驗。