Hdfs 相對路徑與靜態代碼塊引起的問題
本文轉載自微信公眾號「明哥的IT隨筆」,作者IT明哥。轉載本文請聯系明哥的IT隨筆公眾號。
前言
大家好,我是明哥。
HIVE 作為大數據生態的數倉解決方案,因為歷史的原因在很多行業很多公司都有著廣泛的應用。對于比較復雜的業務邏輯,HIVE SQL 往往比較難以表達,此時大家在開發中往往會輔以 HIVE UDF。所以充分理解和掌握 HIVE UDF正確的表寫和使用方式,是大數據從業人員必不可少的一項技能。
關于HIVE UDF 的使用,明哥在前段時間發過兩篇博文,分別是 “如何在 hive udf 中訪問配置數據-方案匯總與對比” 和 “淺析 hive udaf 的正確編寫方式- 論姿勢的重要性" ,兩篇博文描述的都是 HIVE UDF 在編寫使用過程中容易犯的錯誤。
但 UDF 編寫使用過程中遇到的問題往往很多遠遠不止以上兩個,所以明哥決定編寫一個系列 - “淺析 hive udf 的正確編寫和使用方式 - 論姿勢的重要性“,以上兩篇博文可以算做這個系列中的系列一和系列二,本文是該系列的系列三。以下是正文。
時間緊張,急于知道結論的小伙伴,可以直接看最后一部分,問題總結。
問題現象與初步分析
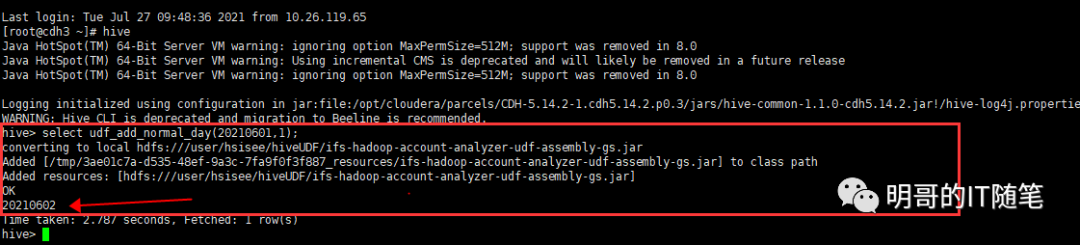
產品部人員反饋,某 HIVE UDF 通過 hive 的舊客戶端即 hive service --cli方式可以正常使用,但使用新客戶端 beeline 時卻會報錯,客戶端的報錯信息沒有啥明確的有意義的信息,如下圖圖一和圖二所示:

beeline
hive
咨詢產品部開發人員,該 UDF 的功能是返回給定業務日期的下一個業務日期,在背后會讀取 HDFS上的一個日期類配置文件;經查看該 UDF 源碼,發現該日期類配置文件的路徑,使用的是相對路徑,如下圖所示:

code-relative-path
熟悉 HDFS 的小伙伴都知道 HDFS 有相對路徑的概念,即代碼中用相對路徑方式指定的文件, 在不同用戶執行作業時會被解析為不同用戶的根目錄下的文件,比如相對路徑 dir1/fileA, 使用hive 用戶執行時作業時會被解析為 /user/hive/dir1/fileA, 使用xyz用戶執行作業時會被解析為 /user/xyz/dir1/fileA, 很多 hdfs 上的文件找不到的問題都是因為該原因。因為有的環境有的用戶能執行成功而另外的環境另外的用戶執行卻會失敗,我們往往戲謔是人品問題,哈哈。
所以順藤摸瓜,看到這里有使用相對路徑指定文件,我們一個自然的思路是查看日志驗證問題。需要注意,這里要查看的是服務端的日志,即 beeline 連接的 hiveserver2 實例的日志,在 cdh 中一般是 /var/log/hive下。果不其然,看到了熟悉的報錯信息:
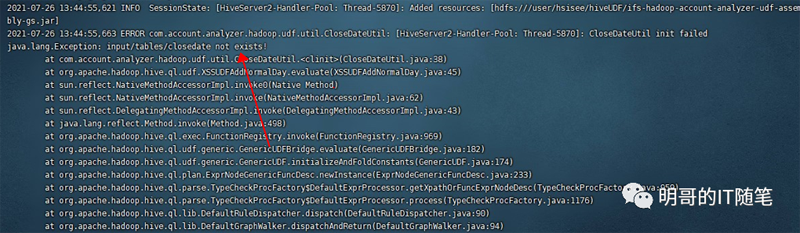
hiveserver2-log
進一步咨詢產品部人員,他們把該配置文件上傳到了 /user/root/ 目錄下,沒有上傳過其它目錄。這也解釋了,為什么 他們 hive service --cli 方式能夠成功,而 beeline方式如 beeline -u jdbc:hive2://xxx:10000/default -n userA -p passwd 方式卻會失敗:因為他們使用前者時是固定在 root 登錄用戶的身份下提交的作業(這其實不太合規范,一般不建議用root身份運行應用程序),而使用后者時實際生效的用戶是 -n 參數指定的用戶而不是當前登錄用戶!(沒有啟用用戶身份認證或啟用ldap認證時,都是通過 -n 參數指定用戶身份;啟用kerberos認證時,通過kerberos的 principal指定用戶身份)。這里還有個小細節,如果沒有啟用身份認證且 beeline后沒有使用 -n參數指定用戶,真正生效的用戶時anonyous匿名用戶,對應的 home directory 是 /user/anonymous.
分析到這里,我們覺得只需要上傳該配置文件到對應用戶的 home directory下,即可解決該問題了。但實際驗證發現,啪啪打臉,同樣的問題仍然存在!
問題進一步分析與解決
再次仔細查看相關代碼,發現了問題所在:該 UDF 讀取配置文件的內容,使用的是類的靜態代碼塊(不是靜態方法)。為什么使用靜態代碼塊會引起問題?要回答這個問題,需要比較扎實的 JAVA 功底, 和對 UDF 執行機制的深刻理解。小伙伴們可以下想下。
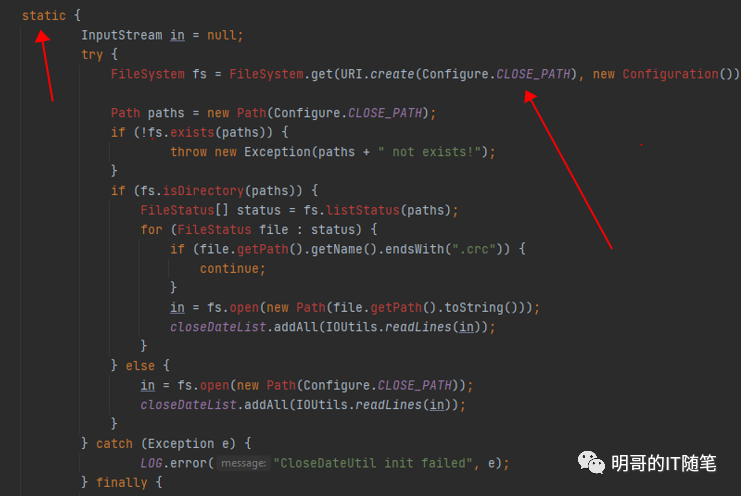
code-static
不賣關子,直接說原因:我們知道 SQL 和 UDF 的解析編譯優化和生成 mr/tez/spark 任務是在 hiveserver2 中進行的,但并不是所有的 sql 和 udf 都會生成 mr/tez/spark 任務,比如這里該 UDF就不會生成 mr/tez/spark 任務,也不需要向 yarn 申請資源獲得 container 容器,而是直接在 hiveserver2 中執行的。所以前幾次 UDF的失敗調用時,該 hiveserver2 這個jvm 已經加載了對應的類,此次再次調用該 UDF 時不需要重新加載該類,自然也不會重新執行類的靜態代碼塊,所以沒有重新讀取配置文件的內容,所以沒有更新對應的配置變量,執行也就失敗了。
重新啟動該 hiveserver2 實例后,再次提交該 udf,會重新加載對應的類,并執行其中的靜態代碼塊讀取配置文件的內容,讀取成功后會更新對應的配置變量,最后作業執行成功。
問題總結
- HDFS 有相對路徑的概念,即代碼中用相對路徑方式指定的文件, 在不同用戶執行作業時會被解析為不同用戶的根目錄下的文件,比如相對路徑 dir1/fileA, 使用hive 用戶執行時作業時會被解析為 /user/hive/dir1/fileA, 使用xyz用戶執行作業時會被解析為 /user/xyz/dir1/fileA, 很多 hdfs 上的文件找不到的問題都是因為該原因;
- Hive SQL 和 UDF 的解析編譯和優化是在 hiveserver2 中進行的,解析編譯和優化的結果一般是生成 mr/tez/spark 任務,這些 mr/tez/spark 任務是在向 yarn 申請獲得的 container 容器對應的 jvm 中執行的;但并不是所有的 sql 和 udf 都會生成 mr/tez/spark 任務,此時其真正的執行就是直接在 hiveserver2 這個已經存在的 jvm 中執行的,該 hiveserver2 這個 jvm 的生命周期跟 udf 的執行無關,如果涉及到配置環境變量,系統參數,或加載類及執行靜態代碼塊,要尤其小心,必要時需要重啟 hiveserver2;(udf 中需要謹慎只用靜態代碼塊,因為靜態代碼塊只有在初次加載類的時候才會執行)
- udf中讀取配置文件,有多種方式,常見的有:
配置文件使用絕對路徑指定,且在代碼中寫死絕對路徑;
配置文件使用絕對路徑,但在代碼中通過讀取本地配置文件獲取hdfs上配置文件的最終絕對路徑;
配置文件使用相對路徑,在客戶現場部署時需要確定執行作業的真正用戶身份,并上傳該配置文件到對應用戶的跟目錄下的特定路徑;