













GaussDB Hash表分布列選擇原則及數(shù)據(jù)傾斜檢測(cè)
本文轉(zhuǎn)載自微信公眾號(hào)「數(shù)據(jù)和云」,作者宋俊卓 。轉(zhuǎn)載本文請(qǐng)聯(lián)系數(shù)據(jù)和云公眾號(hào)。
GaussDB如果采用分布式部署模式,則可以根據(jù)數(shù)據(jù)量以及用途定義兩種不同分布方式的表,分別為復(fù)制表(Replication)和哈希(Hash)表。
復(fù)制表(Replication)是將表中的全量數(shù)據(jù)在集群的每一個(gè)DN實(shí)例上保留一份,主要適用于數(shù)據(jù)量較小的表。這種存儲(chǔ)方式的優(yōu)點(diǎn)是每個(gè)DN上都有此表的全量數(shù)據(jù),在Join操作中可以避免數(shù)據(jù)重分布操作,從而減小網(wǎng)絡(luò)開(kāi)銷(xiāo)。缺點(diǎn)是每個(gè)DN都保留了表的完整數(shù)據(jù),造成數(shù)據(jù)的冗余。一般情況下只有較小的維度表才會(huì)定義為Replication表。
哈希(Hash)表是將表中某一個(gè)或幾個(gè)字段進(jìn)行hash運(yùn)算后,生成對(duì)應(yīng)的hash值,根據(jù)DN實(shí)例與哈希值的映射關(guān)系獲得該元組的目標(biāo)存儲(chǔ)位置。對(duì)于Hash分布表,在讀/寫(xiě)數(shù)據(jù)時(shí)可以利用各個(gè)節(jié)點(diǎn)的IO資源,大大提升表讀/寫(xiě)速度。一般情況下大表定義為Hash表。
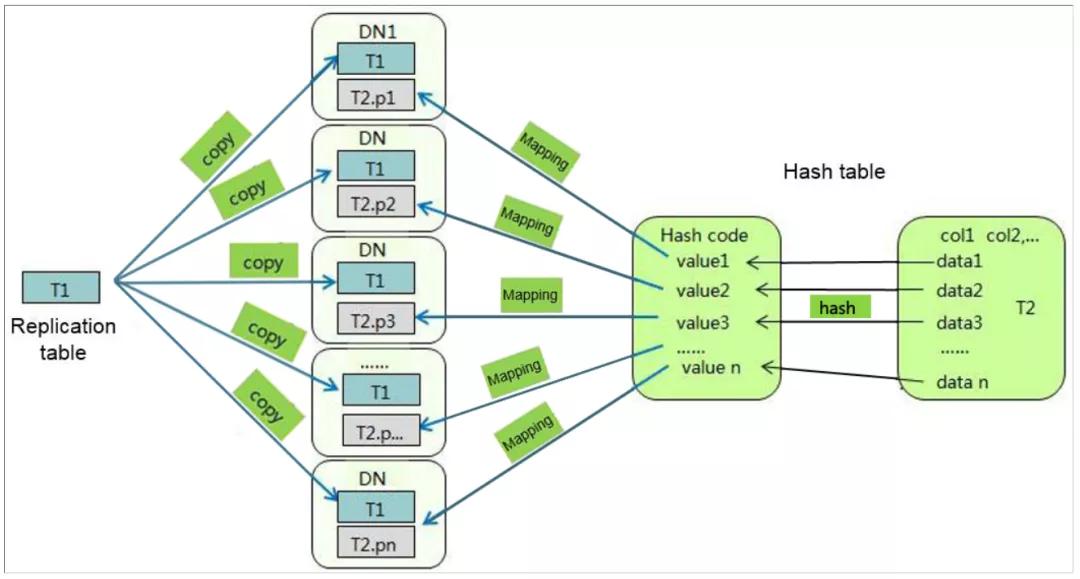
Hash分布表的分布列選取至關(guān)重要,需要滿(mǎn)足以下原則:
(1)列值應(yīng)比較離散,以便數(shù)據(jù)能夠均勻分布到各個(gè)DN。例如,考慮選擇表的主鍵為分布列,如在人員信息表中選擇身份證號(hào)碼為分布列。
(2)在滿(mǎn)足第一條原則的情況下盡量不要選取存在常量filter的列。例如,表dwcjk相關(guān)的部分查詢(xún)中出現(xiàn)dwcjk的列zqdh存在常量的約束(例如zqdh=’000001’),那么就應(yīng)當(dāng)盡量不用zqdh做分布列。
(3)在滿(mǎn)足前兩條原則的情況下,考慮選擇查詢(xún)中的連接條件為分布列,以便Join任務(wù)能夠下推到DN中執(zhí)行,且減少DN之間的通信數(shù)據(jù)量。
(4)一般不建議新增一列專(zhuān)門(mén)用作分布列,尤其不建議新增一列且用SEQUENCE的值來(lái)填充做為分布列,因?yàn)镾EQUENCE可能會(huì)帶來(lái)性能瓶頸和不必要的維護(hù)成本。
對(duì)于Hash分布表策略,如果分布列選擇不當(dāng),可能導(dǎo)致數(shù)據(jù)傾斜,查詢(xún)時(shí)出現(xiàn)部分DN的I/O短板,從而影響整體查詢(xún)性能。因此在采用Hash分布表策略之后需對(duì)表的數(shù)據(jù)進(jìn)行數(shù)據(jù)傾斜性檢查,以確保數(shù)據(jù)在各個(gè)DN上是均勻分布的。
GaussDB中提供了1個(gè)視圖pgxc_get_table_skewness,可以查詢(xún)數(shù)據(jù)庫(kù)中所有schema下的表在各個(gè)DN的分布情況以及傾斜率,雖然可以通過(guò)schemaname和tablename查詢(xún)指定表的傾斜情況,但該視圖查詢(xún)時(shí)耗時(shí)較長(zhǎng),僅適用于數(shù)據(jù)量較小的表(10W以下),尤其不建議不增加條件查詢(xún)所有表的數(shù)據(jù)傾斜情況。該視圖各個(gè)字段說(shuō)明如下:

除此之外,可以使用函數(shù)table_skewness()和table_distribution()查詢(xún)指定表的數(shù)據(jù)傾斜情況。在使用table_skewness()時(shí),如果不指定具體字段,默認(rèn)查詢(xún)當(dāng)前分布列的數(shù)據(jù)傾斜程度,則該函數(shù)可以用來(lái)評(píng)估表的其他字段分布傾斜情況。同樣,當(dāng)表的數(shù)據(jù)量巨大時(shí),這兩個(gè)函數(shù)查詢(xún)耗時(shí)都比較長(zhǎng)。因此對(duì)于一張數(shù)據(jù)量較大的表,一般使用如下語(yǔ)句查詢(xún)其數(shù)據(jù)傾斜情況:
- select xc_node_id, count(1) from tablename group by xc_node_id order by xc_node_id desc;
如果需要查詢(xún)數(shù)據(jù)庫(kù)中傾斜的表,除了使用上面提到的視圖pgxc_get_table_skewness,還可以通過(guò)排查各個(gè)DN實(shí)例數(shù)據(jù)存儲(chǔ)目錄的大小以及數(shù)據(jù)文件來(lái)找出傾斜的表,這也是實(shí)際應(yīng)用中比較常用的方法。
具體方法及步驟如下:
(1)在所有節(jié)點(diǎn)上執(zhí)行df –h查看各個(gè)DN數(shù)據(jù)目錄使用率是否有接近,找到使用率明顯較大的磁盤(pán)目錄。
(2)通過(guò) cm_ctl query –Cvd 確認(rèn)該磁盤(pán)節(jié)點(diǎn)對(duì)應(yīng)的DN實(shí)例(如上一步檢查為slave磁盤(pán)占用率過(guò)大,則需要查看與該備實(shí)例對(duì)應(yīng)的主實(shí)例磁盤(pán)使用情況),確認(rèn)DN實(shí)例端口號(hào)。可通過(guò)以下方式查詢(xún)DN實(shí)例端口號(hào):
- select * from pgxc_node;
- 或者
- cat DN實(shí)例數(shù)據(jù)目錄/postgresql.conf |grep Port
(3)進(jìn)入實(shí)例base目錄,執(zhí)行du -ak | sort -nr | more查找文件大小為1GB,且文件前綴數(shù)字ID相同的文件,查找相同文件數(shù)量最多的文件,記錄其ID值及其所在文件目錄ID值。
(4)通過(guò)gsql連接DN實(shí)例,并通過(guò)文件目錄ID確認(rèn)表所屬數(shù)據(jù)庫(kù)。
- select oid,* from pg_database where oid='1642599';
(5)切換至該數(shù)據(jù)庫(kù),通過(guò)文件的ID確認(rèn)表名稱(chēng),執(zhí)行如下SQL:
- select relname from pg_class where relfilenode = 3308672;
(6)根據(jù)表名稱(chēng)進(jìn)一步確認(rèn)該表所屬schema,執(zhí)行如下SQL:
- SELECT n.nspname as "Schema",
- c.relname as "Name"
- FROM pg_catalog.pg_class c
- LEFT JOIN pg_catalog.pg_namespace n
- ON n.oid = c.relnamespace
- WHERE relname = 'insured';
(7)通過(guò)gsql連接CN實(shí)例,最后再通過(guò)table_skewness()函數(shù)進(jìn)行核實(shí)確認(rèn)。












