













一個(gè)95分位延遲要求5ms的場景,如何做性能優(yōu)化
本文轉(zhuǎn)載自微信公眾號(hào)「薯?xiàng)l的編程修養(yǎng)」,作者程序員薯?xiàng)l。轉(zhuǎn)載本文請聯(lián)系薯?xiàng)l的編程修養(yǎng)公眾號(hào)。
組內(nèi)的數(shù)據(jù)系統(tǒng)在承接一個(gè)業(yè)務(wù)需求時(shí)無法滿足性能需求,于是針對這個(gè)場景做了一些優(yōu)化,在此寫篇文章做記錄。
業(yè)務(wù)場景是這樣:調(diào)用方一次獲取某個(gè)用戶的幾百個(gè)特征(可以把特征理解為屬性),特征以 redis hash 的形式存儲(chǔ)在持久化 KV 數(shù)據(jù)庫中,特征數(shù)據(jù)以天級(jí)別為更新粒度。要求 95 分位的延遲在 5ms 左右。
這個(gè)數(shù)據(jù)系統(tǒng)屬于無狀態(tài)的服務(wù),為了增大吞吐量和降低延遲,從存儲(chǔ)和代碼兩方面進(jìn)行優(yōu)化。
存儲(chǔ)層面
存儲(chǔ)層面,一次調(diào)用一個(gè)用戶的三百個(gè)特征原方案是用 redis hash 做表,每個(gè) field 為用戶的一個(gè)特征。由于用戶單個(gè)請求會(huì)獲取幾百個(gè)特征,即使用hmget做合并,存儲(chǔ)也需要去多個(gè) slot 中獲取數(shù)據(jù),效率較低,于是對數(shù)據(jù)進(jìn)行歸一化,即:把 hash 表的所有 filed 打包成一個(gè) json 格式的 string,舉個(gè)例子:
- // 優(yōu)化前的特征為 hash 格式
- hash key : user_2837947
- 127.0.0.1:6379> hgetall user_2837947
- 1) "name" // 特征1
- 2) "薯?xiàng)l" // 特征1的值
- 3) "age" // 特征2
- 4) "18" // 特征2的值
- 5) "address" // 特征3
- 6) "China" // 特征3的值
- // 優(yōu)化后的特征為 string json格式
- string key: user_2837947
- val:
- {
- "name":"薯?xiàng)l",
- "age":18,
- "address":"China"
- }
特征進(jìn)行打包后解決了一次請求去多個(gè) slot 獲取數(shù)據(jù)時(shí)延較大的問題。但是這樣做可能帶來新的問題:若 hash filed 過多,string 的 value 值會(huì)很大。目前想到的解法有兩種,一種是按照類型將特征做細(xì)分,比如原來一個(gè) string 里面有 300 的字段,拆分成 3 個(gè)有 100 個(gè)值的 string 類型。第二種是對 string val 進(jìn)行壓縮,在數(shù)據(jù)存儲(chǔ)時(shí)壓縮存儲(chǔ),讀取數(shù)據(jù)時(shí)在程序中解壓縮。這兩種方法也可以結(jié)合使用。
如果這樣仍不能滿足需求,可以在持久化 KV 存儲(chǔ)前再加一層緩存,緩存失效時(shí)間根據(jù)業(yè)務(wù)特點(diǎn)設(shè)置,這樣程序交互的流程會(huì)變成這樣:
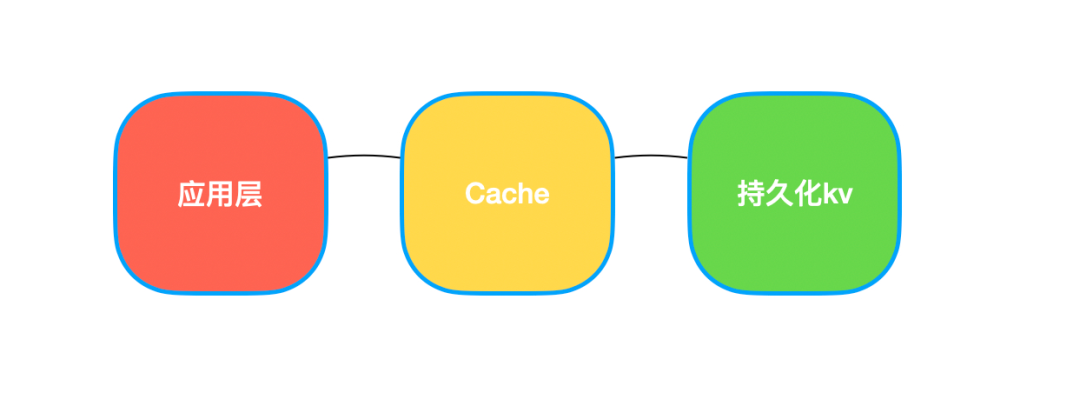
代碼層面
接著來優(yōu)化一下代碼。首先需要幾個(gè)工具去協(xié)助我們做性能優(yōu)化。首先是壓測工具,壓測工具可以模擬真實(shí)流量,在預(yù)估的 QPS 下觀察系統(tǒng)的表現(xiàn)情況。發(fā)壓時(shí)注意漸進(jìn)式加壓,不要一下次壓得太死。
然后還需要 profiler 工具。Golang 的生態(tài)中相關(guān)工具我們能用到的有 pprof 和 trace。pprof 可以看 CPU、內(nèi)存、協(xié)程等信息在壓測流量進(jìn)來時(shí)系統(tǒng)調(diào)用的各部分耗時(shí)情況。而 trace 可以查看 runtime 的情況,比如可以查看協(xié)程調(diào)度信息等。本次優(yōu)化使用 壓測工具+pprof 的 CPU profiler。
下面來看一下 CPU 運(yùn)行耗時(shí)情況:
右側(cè)主要是 runtime 部分,先忽略
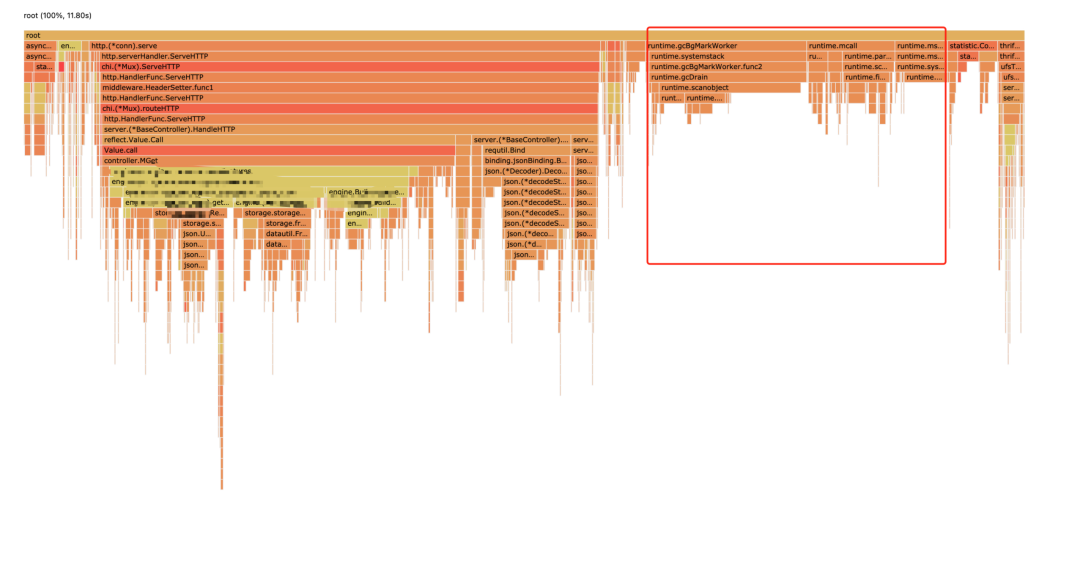
火焰圖中圈出來的大平頂山都是可以優(yōu)化的地方,
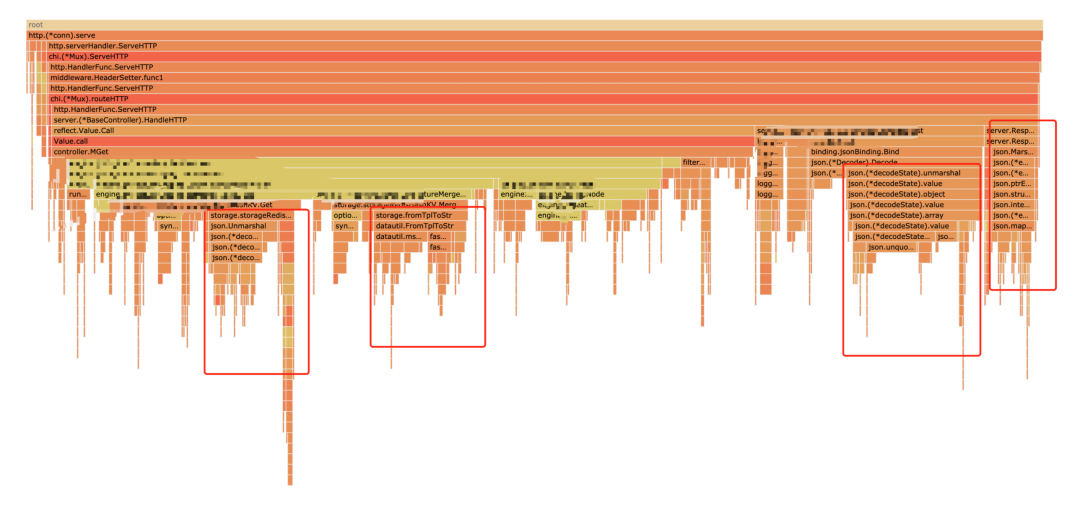
這里的三座平頂山的主要都是json.Marshal和json.Unmarshal操作引起的,對于 json 的優(yōu)化,有兩種思路,一種是換個(gè)高性能的 json 解析包 ,另一種是根據(jù)業(yè)務(wù)需求看能否繞過解析。下面分別來介紹:
高性能解析包+一點(diǎn)黑科技
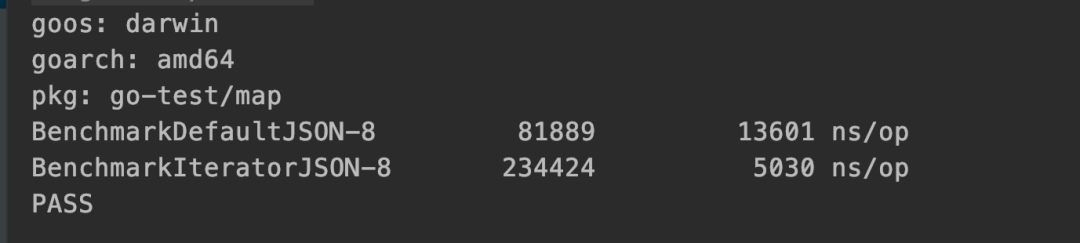
這里使用了陶師傅的包github.com/json-iterator/go。看了他的 benchmark 結(jié)果,比 golang 原生庫還是要快很多的。自己再寫個(gè)比較符合我們場景的Benchmark看陶師傅有沒有騙我們:
- package main
- import (
- "encoding/json"
- jsoniter "github.com/json-iterator/go"
- "testing"
- )
- var s = `{....300多個(gè)filed..}`
- func BenchmarkDefaultJSON(b *testing.B) {
- for i := 0; i < b.N; i++ {
- param := make(map[string]interface{})
- _ = json.Unmarshal([]byte(s), ¶m)
- }
- }
- func BenchmarkIteratorJSON(b *testing.B) {
- for i := 0; i < b.N; i++ {
- param := make(map[string]interface{})
- var json = jsoniter.ConfigCompatibleWithStandardLibrary
- _ = json.Unmarshal([]byte(s), ¶m)
- }
- }
運(yùn)行結(jié)果:
這個(gè)包易用性也很強(qiáng),在原來 json 代碼解析的上面加一行代碼就可以了:
- var json = jsoniter.ConfigCompatibleWithStandardLibrary
- err = json.Unmarshal(datautil.String2bytes(originData), &fieldMap
還有一個(gè)可以優(yōu)化的地方是string和[]byte之間的轉(zhuǎn)化,我們在代碼里用的參數(shù)類型是string,而 json 解析接受的參數(shù)是[]byte,所以一般在json解析時(shí)需要進(jìn)行轉(zhuǎn)化:
- err = json.Unmarshal([]byte(originData), &fieldMap)
那么string轉(zhuǎn)化為[]byte發(fā)生了什么呢。
- package main
- func main(){
- a := "string"
- b := []byte(a)
- println(b)
- }
我們用匯編把編譯器悄悄做的事抓出來:
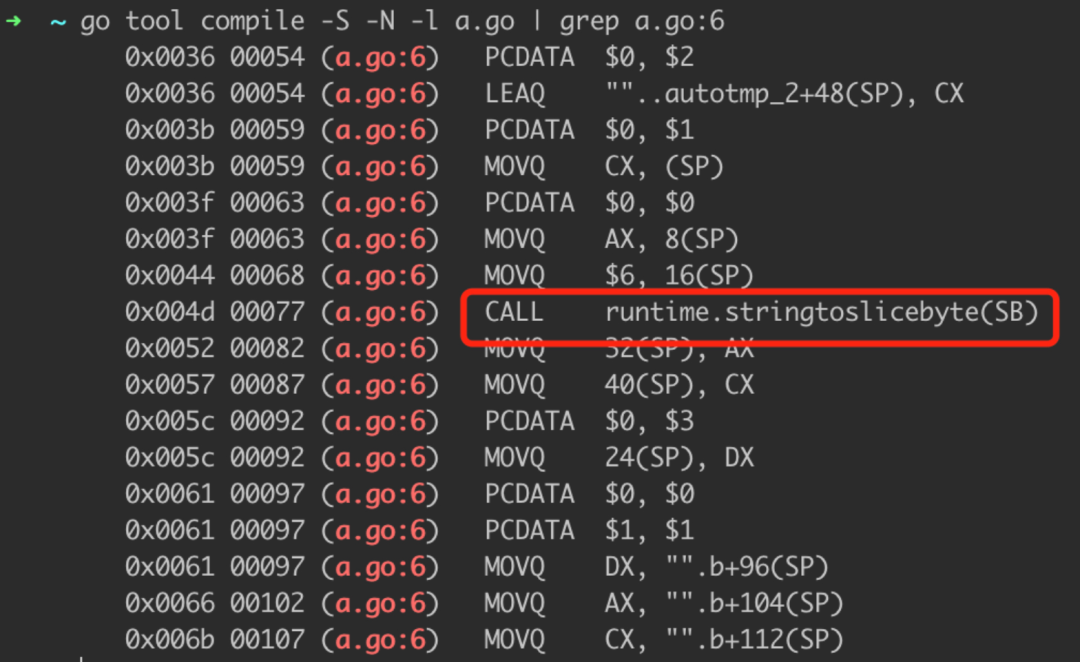
來看一下這個(gè)函數(shù)做了啥:
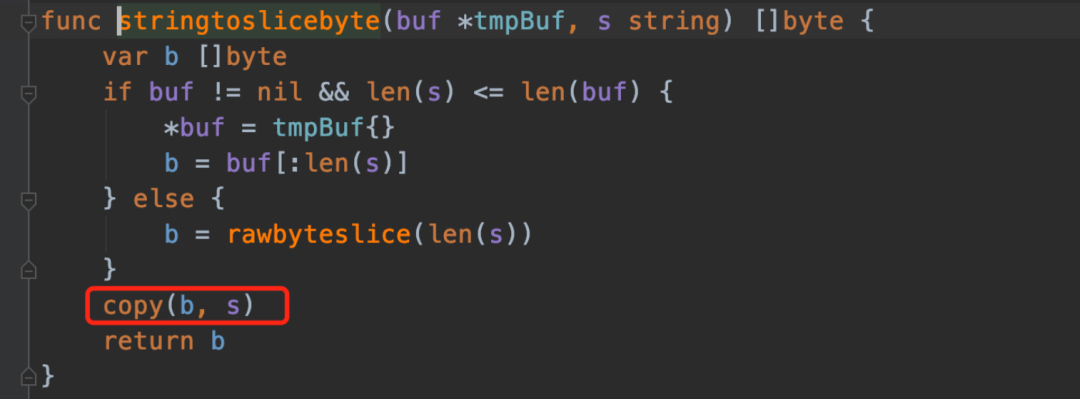
這里底層會(huì)發(fā)生拷貝現(xiàn)象,我們可以拿到[]byte和string的底層結(jié)構(gòu)后,用黑科技去掉拷貝過程:
- func String2bytes(s string) []byte {
- x := (*[2]uintptr)(unsafe.Pointer(&s))
- h := [3]uintptr{x[0], x[1], x[1]}
- return *(*[]byte)(unsafe.Pointer(&h))
- }
- func Bytes2String(b []byte) string {
- return *(*string)(unsafe.Pointer(&b))
- }
下面寫 benchmark 看一下黑科技好不好用:
- package main
- import (
- "strings"
- "testing"
- )
- var s = strings.Repeat("hello", 1024)
- func testDefault() {
- a := []byte(s)
- _ = string(a)
- }
- func testUnsafe() {
- a := String2bytes(s)
- _ = Bytes2String(a)
- }
- func BenchmarkTestDefault(b *testing.B) {
- for i := 0; i < b.N; i++ {
- testDefault()
- }
- }
- func BenchmarkTestUnsafe(b *testing.B) {
- for i := 0; i < b.N; i++ {
- testUnsafe()
- }
- }
運(yùn)行速度,內(nèi)存分配上效果都很明顯,黑科技果然黑:

加 cache,空間換時(shí)間
項(xiàng)目中有一塊代碼負(fù)責(zé)處理 N 個(gè)請求中的參數(shù)。代碼如下:
- for _, item := range items {
- var params map[string]string
- err := json.Unmarshal([]byte(items[1]), ¶ms)
- if err != nil {
- ...
- }
- }
在這個(gè)需要優(yōu)化的場景中,上游在單次請求獲取某個(gè)用戶300多個(gè)特征,如果用上面的代碼我們需要json.Unmarshal300多次,這是個(gè)無用且非常耗時(shí)的操作,可以加 cache 優(yōu)化一下:
- paramCache := make(map[string]map[string]string)
- for _, item := range items {
- var params map[string]string
- tmpParams, ok := cacheDict[items[1]]
- // 沒有解析過,進(jìn)行解析
- if ok == false {
- err := json.Unmarshal([]byte(items[1]), ¶ms)
- if err != nil {
- ...
- }
- cacheDict[items[1]] = params
- } else {
- // 解析過,copy出一份
- // 這里的copy是為了預(yù)防并發(fā)問題
- params = DeepCopyMap(tmpParams)
- }
- }
這樣理論上不會(huì)存在任何的放大現(xiàn)象,讀者朋友如果有批處理的接口,代碼中又有類似這樣的操作,可以看下這里是否有優(yōu)化的可能性。
- for {
- dosomething()
- }
替換耗時(shí)邏輯
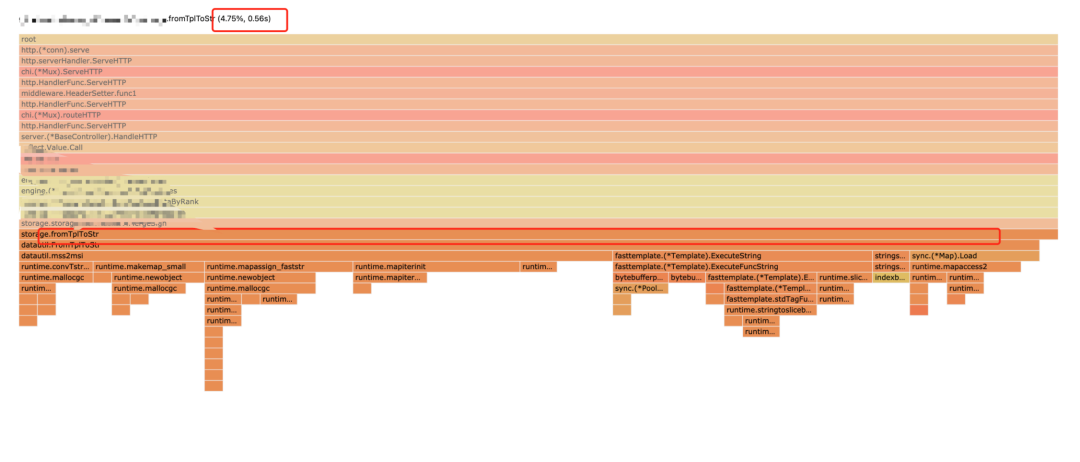
火焰圖中的 TplToStr 模板函數(shù)同樣占到了比較大的 CPU 耗時(shí),此函數(shù)的功能是把用戶傳來的參數(shù)和預(yù)制的模板拼出一個(gè)新的 string 字符串,比如:
- 入?yún)ⅲ篢pl: shutiao_test_{{user_id}} user_id: 123478
- 返回:shutiao_test_123478
在我們的系統(tǒng)中,這個(gè)函數(shù)根據(jù)模板和用戶參數(shù)拼出一個(gè) flag,根據(jù)這個(gè) flag 是否相同作為某個(gè)操作的標(biāo)記。這個(gè)拼模板是一個(gè)非常耗時(shí)的操作,這塊可以直接用字符串拼接去代替模板功能,比如:
- 入?yún)ⅲ篢pl: shutiao_test_{{user_id}} user_id: 123478
- 返回:shutiao_test_user_id_123478
優(yōu)化完之后,火焰圖中已經(jīng)看不到這個(gè)函數(shù)的平頂山了,直接節(jié)省了 5%的 CPU 的調(diào)用百分比。
prealloc
還發(fā)現(xiàn)一些 growslice 占得微量 cpu 耗時(shí),本以為預(yù)分配可以解決問題,但做 benchmark 測試發(fā)現(xiàn) slice 容量較小時(shí)是否做預(yù)分配在性能上差異不大:

- package main
- import "testing"
- func test(m *[]string) {
- for i := 0; i < 300; i++ {
- *m = append(*m, string(i))
- }
- }
- func BenchmarkSlice(b *testing.B) {
- for i := 0; i < b.N; i++ {
- b.StopTimer()
- m := make([]string, 0)
- b.StartTimer()
- test(&m)
- }
- }
- func BenchmarkCapSlice(b *testing.B) {
- for i := 0; i < b.N; i++ {
- b.StopTimer()
- m := make([]string, 300)
- b.StartTimer()
- test(&m)
- }
- }

對于代碼中用到的 map 也可以做一些預(yù)分配,寫 map 時(shí)如果能確認(rèn)容量盡量用 make 函數(shù)對容量進(jìn)行初始化。

- package main
- import "testing"
- func test(m map[string]string) {
- for i := 0; i < 300; i++ {
- m[string(i)] = string(i)
- }
- }
- func BenchmarkMap(b *testing.B) {
- for i := 0; i < b.N; i++ {
- b.StopTimer()
- m := make(map[string]string)
- b.StartTimer()
- test(m)
- }
- }
- func BenchmarkCapMap(b *testing.B) {
- for i := 0; i < b.N; i++ {
- b.StopTimer()
- m := make(map[string]string, 300)
- b.StartTimer()
- test(m)
- }
- }
這個(gè)優(yōu)化還是比較有效的:

異步化
接口流程中有一些不影響主流程的操作完全可以異步化,比如:往外發(fā)送的統(tǒng)計(jì)工作。在 golang 中異步化就是起個(gè)協(xié)程。
總結(jié)一下套路:
代碼層面的優(yōu)化,是 us 級(jí)別的,而針對業(yè)務(wù)對存儲(chǔ)進(jìn)行優(yōu)化,可以做到 ms 級(jí)別的,所以優(yōu)化越靠近應(yīng)用層效果越好。對于代碼層面,優(yōu)化的步驟是:
壓測工具模擬場景所需的真實(shí)流量
pprof 等工具查看服務(wù)的 CPU、mem 耗時(shí)
鎖定平頂山邏輯,看優(yōu)化可能性:異步化,改邏輯,加 cache 等
局部優(yōu)化完寫 benchmark 工具查看優(yōu)化效果
整體優(yōu)化完回到步驟一,重新進(jìn)行 壓測+pprof 看效果,看 95 分位耗時(shí)能否滿足要求(如果無法滿足需求,那就換存儲(chǔ)吧~。
另外推薦一個(gè)不錯(cuò)的庫,這是 Golang 布道師 Dave Cheney 搞的用來做性能調(diào)優(yōu)的庫,使用起來非常方便:https://github.com/pkg/profile,可以看 pprof和 trace 信息。有興趣讀者可以了解一下。




















