云上資源編排的思與悟
一、背景
2018年7月9日,我通過校招加入阿里云,開啟了職業生涯。有幸參與了資源編排服務從1.0到2.0的全部設計、開發、測試工作,這對我了解云上服務起到了啟蒙作用。當然,本文源于我在設計開發過程中的思考和感悟。
在傳統軟件架構下,撇開業務層代碼,都需要部署計算節點、存儲資源、網絡資源,然后安裝、配置操作系統等。而云服務本質上是實現 IT 架構軟件化和 IT 平臺智能化,通過軟件的形式定義這些硬件資源,充分抽象并封裝其操作接口,任何資源均可直接調用相關 API 完成創建、刪除、修改、查詢等操作。
有賴于阿里云對資源的充分抽象以及高度統一的OpenAPI,這讓基于阿里云構建一套完整的 IT 架構并對各資源進行生命周期管理成為可能。客戶按需求提供資源模板,編排服務將會根據編排邏輯自動完成所有資源的創建和配置。
二、架構設計
伴隨著業務場景的增加和業務規模的指數級增長,原有架構逐漸暴露出租戶隔離粒度大、并發量小、服務依賴嚴重等問題,對于服務架構的重構迫在眉睫,其中最重要三個方面就是拓撲設計、并發模型設計和工作流設計。
1、架構設計
拓撲設計的核心問題是明確產品形態和用戶需求、解決數據通路問題。站在產品角度考慮的點包括:
- 資源所有者(服務資源[計費單元]、用戶資源)
- 資源訪問權限(隔離、授權)。站在用戶角度需要考慮的點包括: (1)服務類型(WebService型-需公網訪問、數據計算型-阿里云內網訪問);(2)數據打通(源數據、目的數據)。
資源所有者分為服務賬號和用戶賬號。資源屬于服務賬號的模式又叫做大賬號模式,該模式優點有: 1. 管控能力更強;2.計費更容易。但易成為瓶頸的點包括:1.資源配額;2. 依賴服務的接口流控。很顯然,全量資源托管是不現實的,比如VPC、VSwitch、SLB、SecurityGroup等資源客戶往往需要和其他系統打通,這部分資源通常是用戶提供的,而ECS實例則比較適合通過大賬號創建。
多租戶隔離在大賬號模式下是非常重要的問題。既要保證某一用戶的資源彼此可以相互訪問,又要保證多個客戶之間不能有越界行為。一個常見的例子是,所有用戶的ECS均開在同一個服務VPC內,同一個VPC內實例默認是可以相互訪問的,存在安全風險,因此在系統設計初期就需要考慮到相關問題的應對方案。
對于上述問題我們的設計是,ECS實例通過大賬號模式創建在服務賬號下的資源VPC內, 通過企業級安全組實現不同用戶實例的訪問隔離。涉及用戶數據(NAS、RDS等)訪問的操作時,需要用戶提供這些訪問點所在的VPC和Vswitch,通過在實例上創建ENI并綁定到用戶VPC上,實現對用戶數據的訪問。具體數據通路如圖所示。
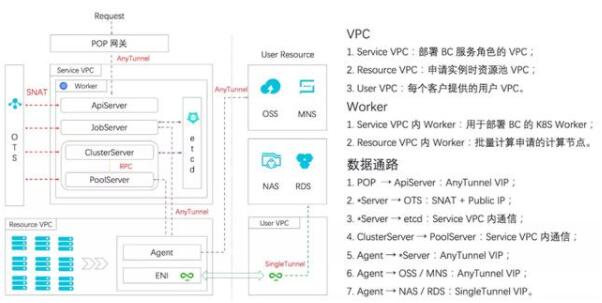
常見的服務架構
2、并發模型設計
模型設計的核心是解決高并發(High Concurrency)、高性能(High Performance)、高可用(High Availability)問題。
資源編排的高并發主要指標為QPS(Queries-per-second),對于動輒以分鐘為單位的資源編排邏輯而言,同步模型顯然不能支撐較高并發請求。資源編排的高性能主要指標為TPS(Transactions-per-second),在根據用戶資源模板編排資源的過程中,資源彼此間存在一定的依賴關系,線性地創建資源會導致大量時間處于忙等狀態,服務吞吐嚴重受限。資源編排的高可用主要指標為SLA(Service Level Agreement),在HA基礎上若能解耦CRUD對內部服務的依賴,在服務升級或發生異常時就可以減小對SLA的影響。
對于上述問題我們的設計是,在服務前端僅進行簡單的參數檢查后立即將用戶模板寫入持久化層,寫入成功后立即返回資源ID,已持久化的資源模板將被視為未處理完成的任務等待調度處理。隨后,我們周期性掃表探測任務,有序創建資源并同步其狀態,如遇資源狀態不滿足向下推進的條件則立即返回,經過多輪次處理,最終達到期望的狀態, 一個簡化的分布式模型如圖所示。
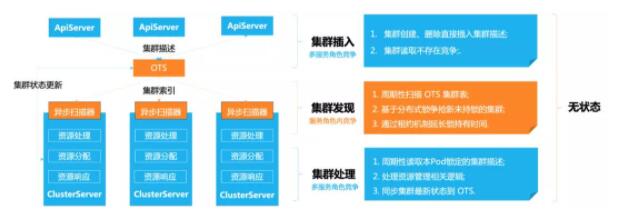
分布式并發模型
為了避免任務較多情況下的鎖爭搶問題,我們設計一套任務發現 + 租約續租的機制,一旦集群從數據庫池子中被某個節點爭搶到之后會被添加到該節點的調度池中并設定租約, 租約管理系統會對即將到期的租約進行續租(加鎖)。這樣可以確保一個集群在下一次服務被拉起前一直只被某個節點處理,如果服務重啟,則任務會因超時自動解鎖并被其他節點捕獲。
3、工作流設計
流程設計的核心是解決依賴問題。依賴問題包含兩種情況:前序資源的狀態不符合預期和資源本身狀態不符合預期。我們假設各資源的狀態只有可用和不可用,并且假定可用的資源不會跳轉到不可用狀態,最簡單的情況就是一個線性任務,如圖所示。考慮到部分子資源的編排工作可以并行,編排過程就可以看作是一個有向無環圖( DAG, Direct Acyclic Graph)任務。
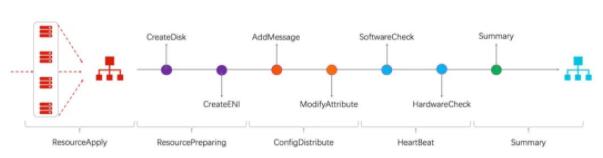
資源線性編排結構
世界不只是非黑即白,資源的狀態也是一樣,有向無環成為了美好的愿望,有向有環才符合真實世界的運行規律。對于這種情況,簡單的工作流很難覆蓋復雜的流程,只有進一步對工作流抽象,設計符合要求的有限狀態機(FSM, Finite State Machine)。有限狀態機說起來過于抽象,但ECS實例的狀態轉移大家都接觸過,下圖就是ECS實例的狀態轉移模型。
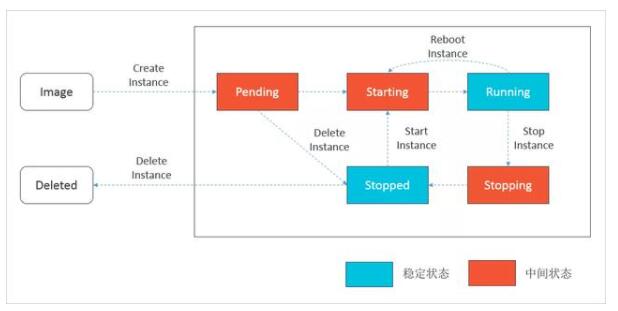
ECS實例狀態轉移模型
結合實際業務需求,我設計了如下圖所示的集群狀態轉移模型。該模型簡化了狀態轉移邏輯,有且僅有Running這一穩態,其他三種狀態(Rolling、Deleting、Error)均為中間態。處于中間態的資源會根據當前資源狀態嘗試向著穩態越遷,每次狀態越遷過程均按照一定的Workflow執行相關操作。

集群狀態轉移模型
從這時起,服務的整體架構和設計思路基本確立。
三、核心競爭力
資源(ECS)短缺問題日益嚴峻,加上粗粒度的擴縮容、升降配功能已不能滿足客戶的需求,資源池化(Resource Pooling)、自動伸縮(Auto Scaling)、滾動升級(Rolling Update)被提上日程并成為提升產品競爭力的一大利器。
1、資源池化
資源池化簡單來說就是提前預留某些資源以備不時之需,很顯然,資源池化的前提一定是大賬號模式。對開發者而言,線程池不是陌生的詞匯,但資源池卻相對比較遙遠,實際上,資源池解決的就是資源創建、刪除時間開銷很大以及庫存不可控的問題。當然, 池化資源另一個假設是,被池化的資源會被頻繁使用且可被回收利用(規格、配置相對單一)。
由于計算資源創建周期較長且經常被資源庫存等問題困擾,加之產品期望在業務上有所拓展,因此我們設計了如圖所示的資源池化模型并對多種計算資源進行抽象,提供了一套可以應對異構資源的處理邏輯。
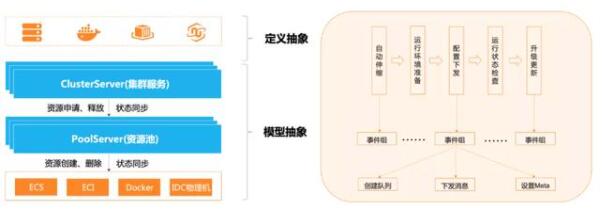
資源池化模型
資源池化可以大大縮短資源創建等待時間,解決庫存不足問題,另外,它可以幫上層使用到資源的服務解耦復雜的狀態轉移邏輯,對外提供的資源狀態可以精簡到Available和Unknown兩種,所得即可用。但不得不考慮的問題包括:
ECS實例的創建是否受用戶資源的限制(如用戶提供VSwitch會限制ECS可用區)。
如何解決資源閑置問題(成本問題)。
對于第一個問題,目前受制于VSwitch由客戶提供,暫時還沒有比較好的解法,只能盡量要求客戶提供的VSwitch覆蓋更多的可用區,如果VSwitch屬于服務賬號,就可以比較好規劃資源池建在哪個AZ。對于第二個問題,資源池本身也是一種資源,成本控制我們可以從接下來提到的自動伸縮上得到答案。
2、自動伸縮
云計算最大的吸引力就是降低成本,對資源而言,最大的好處就是可以按量付費。實際上,幾乎所有線上服務都有其峰谷,而自動伸縮解決的正是成本控制問題。它在客戶業務增長時增加ECS實例以保證算力,業務下降時減少ECS實例以節約成本,如圖所示。
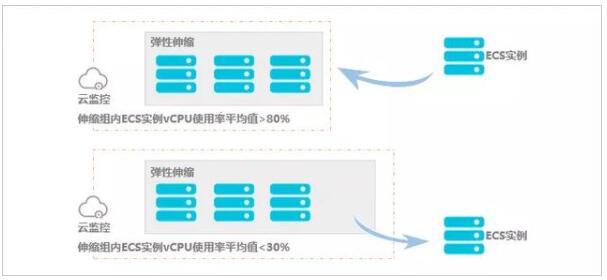
自動伸縮示意圖
我對自動伸縮的設計思路是,先對時間分片觸發定時任務,再對時間段內配置伸縮策略。伸縮策略也包含兩部分,一部分是最大ECS規模和最小ECS規模,它指定了該時間段內集群規模的浮動范圍,另一部分是監控指標、耐受度和步進規則,它提供了伸縮依據和標準。這里監控指標是比較有意思的點,除了采集云監控的CPU、Memory利用率外,還可以通過對ECS空閑、忙碌狀態的標記,計算出工作節點占比率,一旦超出耐受范圍,即可按步進大小觸發一次擴容或縮容事件。
3、滾動升級
客戶服務架構的修改往往涉及復雜的重建邏輯,在重建過程中不可避免的會影響服務質量,如何優雅平滑地做升降配成為了諸多客戶的剛需。滾動升級正是解決不停服、可調控的升降配問題的。
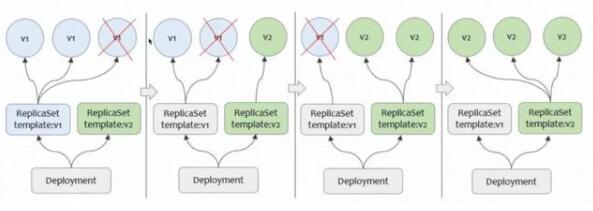
滾動升級示意圖
一次簡化的滾動升級過程如上圖所示。滾動升級的核心是對升級進行灰度,按照一定比例開出Standby資源直到它們可以順利服役,隨后再下線掉相應臺數的資源。經過多次滾動之后,使其全部資源更新到最新預期,通過冗余實現升級不停服。
四、可觀測性
服務可觀測性將來必將成為云服務的核心競爭力之一,它包括面向用戶的可觀測行和面向開發者的可觀測性兩部分。時至今日,仍然記得半夜被客戶電話支配的恐懼,仍記得對著海量日志調查問題的不知所措,仍記得客戶一通抱怨后毫無頭緒的茫然。
1、面向用戶
是的,我希望用戶在向我們反饋遇到的問題時,提供的信息是有效的,甚至是能直接指向病灶的。對用戶而言,能夠直接通過API獲取資源編排所處的階段以及各階段對應資源的狀態信息,確實能夠極大地提高用戶體驗。針對這個問題,我分析了系統處理流程, 設計了面向“階段 - 事件 - 狀態”的運行狀態收集器。
具體包括:對的業務流程進行拆分得到多個處理階段,對每個階段依賴的事件(資源及其狀態)進行整理,對每個事件可能出現的狀態做結構化定義(尤其是異常狀態)。一個典型的樣例如代碼樣例所示。
- [ { "Condition":"Launched", "Status":"True", "LastTransitionTime":"2021-06-17T18:08:30.559586077+08:00", "LastProbeTime":"2021-06-18T14:35:30.574196182+08:00" }, { "Condition":"Authenticated", "Status":"True", "LastTransitionTime":"2021-06-17T18:08:30.941994575+08:00", "LastProbeTime":"2021-06-18T14:35:30.592222594+08:00" }, { "Condition":"Timed", "Status":"True", "LastTransitionTime":"2021-06-17T18:08:30.944626198+08:00", "LastProbeTime":"2021-06-18T14:35:30.599628262+08:00" }, { "Condition":"Tracked", "Status":"True", "LastTransitionTime":"2021-06-17T18:08:30.947530873+08:00", "LastProbeTime":"2021-06-18T14:35:30.608807786+08:00" }, { "Condition":"Allocated", "Status":"True", "LastTransitionTime":"2021-06-17T18:08:30.952310811+08:00", "LastProbeTime":"2021-06-18T14:35:30.618390582+08:00" }, { "Condition":"Managed", "Status":"True", "LastTransitionTime":"2021-06-18T10:09:00.611588546+08:00", "LastProbeTime":"2021-06-18T14:35:30.627946404+08:00" }, { "Condition":"Scaled", "Status":"False", "LastTransitionTime":"2021-06-18T10:09:00.7172905+08:00", "LastProbeTime":"2021-06-18T14:35:30.74967891+08:00", "Errors":[ { "Action":"ScaleCluster", "Code":"SystemError", "Message":"cls-13LJYthRjnrdOYMBug0I54kpXum : destroy worker failed", "Repeat":534 } ] }]
代碼樣例:集群維度狀態收集
2、面向開發者
對開發者而言,可觀測性包含監控和日志兩部分,監控可以幫助開發者查看系統的運行狀態,而日志可以協助問題的排查和診斷。產品從基礎設施、容器服務、服務本身、客戶業務四個維度進行了監控和數據聚合,具體用到的組件如圖所示。
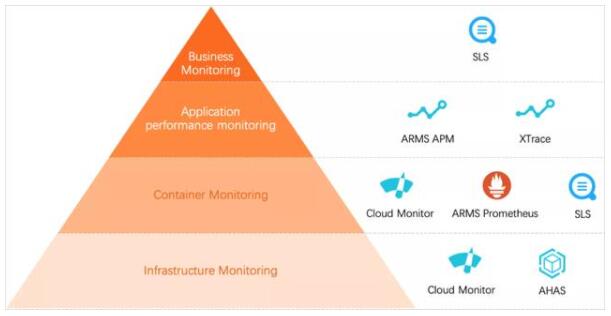
各級別監控、告警體系
基礎設施主要依托云監控(Cloud Monitor)追蹤CPU、Memory等使用率;容器服務主要依賴普羅米修斯(Prometheus)監控部署服務的K8S集群情況。對服務本身,我們在各個運行階段都接入了Trace用于故障定位;對最難處理的客戶業務部分,我們按通過SLS收集客戶使用情況,通過UserId和ProjectId進行數據聚合,并整理出普羅米修斯的DashBoard,可以快速分析某個用戶的使用情況。
除監控外,已接入云監控告警、普羅米修斯告警和SLS告警,系統、業務分別設置不同告警優先級,并整理了豐富的應急響應方案。
五、其他
從懵懂到能夠獨立負責資源編排服務的設計、開發工作,阿里云提供了寶貴的學習平臺。