













從技術視角看大數據行業的發展趨勢
本文轉載自微信公眾號「明哥的IT隨筆」,作者IT明哥。轉載本文請聯系明哥的IT隨筆公眾號。
前言
大家好,我是明哥!
正所謂 “抬頭看天,低頭走路”,大數據從業者既要腳踏實地立足當前技術棧做出高效易用的大數據產品,又要仰望星空順應大數據的發展趨勢,做出有技術前瞻性能適應未來變化的大數據產品。
明哥前期發布了一篇名為 “從歷年 Gartner hype cycle 看大數據行業的發展歷史和趨勢” 的博文,在那篇博文中,明哥梳理了下歷年 Gartner hype cycle 中關于大數據的部分,并據此總結了大數據行業的發展歷史和趨勢,該篇博文可以算是從面到點從上到下的視角推論的大數據的發展趨勢。該博文鏈接如下:
從歷年 Gartner hype cycle 看大數據行業的發展歷史和趨勢
在這篇博文中,明哥將依托自己十四年 IT 從業經驗和六年大數據行業從業經驗的經歷,從自身的感觸和技術的視角,總結下大數據行業的發展趨勢,可以算是以從點到面從下到上的視角,對上文的一個呼應。
需要聲明下,明哥自身能力有限經歷有限,所以這里總結的行業趨勢僅僅是管中窺豹,遠遠達不到大而全,話說回來,能讓大家看后有所悟有所感,明哥就覺得可以了。
以下是正文。
趨勢一:大數據和云計算進一步深度融合,大數據擁抱云計算走向云原生化
關于該趨勢,明哥在前期發布過一篇博文,“大數據與云計算深度融合的趨勢體現在哪些方面?” 對該趨勢做了自己的解讀,這里再次簡要描述下。該博文鏈接如下:
大數據與云計算深度融合的趨勢體現在哪些方面?
云原生(Cloud Native)理念,本質上是一套“利用云計算技術為用戶降本增效”的最佳實踐與方法論。大數據擁抱云計算走向云原生化,體現在一下四個方面:
- 一是應用方的大數據平臺主動上云:使用大數據技術的業務應用建設方,不再自建數據中心,而是將大數據平臺搬到了云上,有的是在云廠商的 IaaS 層上自建大數據平臺(現在以這種方式在云上使用大數據的案例已經比較少了),有的直接使用云廠商提供的 PaaS 層大數據相關產品(aws 的 emr,阿里云的 e-MapReduce等),有的甚至直接使用云廠商推出的 SaaS層大數據相關產品(aws的redshift, 阿里云的maxcompute等),而且在上云的過程中,大家都很重視混合云和多云部署,避免 vendor-lockin;
- 二是云計算廠商在不斷推出云上托管的各種基于大數據服務,以吸引更多業務方上云:各大云廠商為了提高自己的市場競爭力,從而進一步鞏固和拓寬自己的市場地位,都在積極推出各種托管的大數據相關產品,有 s3/oss, emr/e-mapreduce,有 aws redshift, 有阿里云 maxcompute,還有各種云上數據庫,云上 serverless 形態的各種大數據服務等等,該名單還在不斷增長中。
- 三是各傳統大數據廠商已經轉向依托云來提供自己的產品和服務,如 elastic 很早就開始基于云交付自己的elk 技術棧了,如 spark 背后的商業公司 databricks 的大數據平臺和產品一直都是基于云來向客戶提供服務的(可以對接aws, gcp, azure等云平臺),如 cloudera 不斷探索改變自己的商業模式(從大數據三駕馬車的輝煌期,到業績下滑下的和 hortorworks的合并,再到主動改變商業模式基于云來交付自己的產品和服務,甚至數據中心版的大數據平臺都改名為了 cdp private cloud base),如 kafka 背后的商業公司 Confluent 也在基于云推廣自己的 Confluent Platform.
confluent platform and confluent cloud
- 四是各個具體的大數據組件都在主動改變自身架構,積極向云原生靠攏以“云化”:從理念層面講,大數據已經從最早的強調“數據本地性”和“移動數據不如移動計算”的理念,演進到了現在的強調“存儲計算分離”的理念。各個新推出的組件和框架主動擁抱云原生,如 pulsa,TiDB 等都是依托于存儲計算分離的云原生架構; 各個傳統的組件雖然有歷史包袱,也在不斷求新求變,如 flink/spark 都深度整合支持了 kubernetes 集群模式;如 kafka也在不斷探索如花云化:包括完全去掉zookeeper依賴,包括 Rebalance Protocol 的 Static Membership 等;正如古語所言,“順則昌不順則亡”,一些不適應云原生架構的技術組件,其市場正在不斷萎縮,如很多場景下,kubernetes 都替代了yarn, 對象存儲 oss/s3 等也在替代 hdfs (我們也注意到了apache 社區推出的 Ozone,該組件在對象存儲的基礎上,也融合推出了文件系統api,該組件的背后有很多原 hdfs 社區的 committer在貢獻代碼,在 cloudera 的 cdp 平臺中也內嵌支持了該組件)。下圖展示了 flink/spark跟 kubernetes 的深度整合:(注意不是簡單的使用 k8s operator 將 spark/flink 作業運行在 k8s 集群中,而是 native 的深度的整合)
- 大數據云與計算的深度融合是大勢所趨,其主要體現在以上四個方面,需要強調的是,這四個方面是相輔相成,互相促進的。
- 如應用方的大數據平臺上云的需求,促使了云計算廠商推出更好的托管的大數據增值服務;
- 而云計算廠商推出的更多更好的大數據增值服務,也反過來促使了更多的應用方大數據平臺上云;
- 如基礎設施上云的大趨勢,促使了具體的大數據組件調整自身架構從而云化(因為順則昌不順則亡);
- 而大數據具體組件云原生化的架構調整,也反過來促使了云計算廠商和大數據廠商能夠基于云基礎設施推出更多更好的大數據服務。
趨勢二:大數據與數據庫日益融合的趨勢
- 大數據與數據庫日益融合的趨勢,首先體現在大數據與數據庫的邊界本身就比較模糊:
- 如具有大數據基因的各種 NoSql 數據庫 MongoDB, es, Hbase 等也是數據庫生態的一部分;
- 如 greenPlum, Vertica 等 mpp 數據庫本身就是大數據生態的一部分;
- 如新型 NewSql 數據庫 TiDB, CockroachDB, OceanBase 更是橫跨數據庫生態與大數據生態。
- 大數據與數據庫日益融合的趨勢,也體現在大數據組件本身在技術上借用和參考了很多傳統數據庫的理念和技術,使得大數據組件越來越像存儲與計算分離的數據庫:
- 如各種大數據處理引擎都提供了對 sql 語法的支持:hive/spark/flink/presto sql;
- 如各種大數據處理引擎本身在對 sql 的解析和優化上經常使用的框架 calcite/antlr4 在實現細節上就參考了數據庫的實現;
- 如大數據參考數據庫對元數據的管理,抽象出了 catalog 的概念,各大數據處理引擎如 spark/flink 都有自己的各種 catalog 的實現;
- 如大數據處理引擎參考數據庫實現了對事務 acid 特性的支持,參考數據庫的 mvcc 機制實現了對并發讀寫和多版本控制的支持,具體的有 hive acid事務表,還有數據湖框架 delta lake/hudi/iceberg等。
- 大數據與數據庫日益融合的趨勢,還體現在數據庫也在不斷演變以適應大數據場景:數據庫從技術架構上來講,經歷了從早期的關系型數據庫 sql,到大數據初生時代的各種 Nosql,再到現在的各種 NewSql, 也經歷了從單機到讀寫分離再到集群化部署的趨勢;
最后有必要說明下,由于大數據和數據庫日益融合,依托數據庫的傳統數據倉庫 Data Warehouse 和依托大數據的數據湖 Data Lake,二者之間的界限也越來越模糊并日益融合了,有的廠商還特地引進了新的術語來描述這種新型架構并得到了業界更廣泛的認可和支持,該術語就是業界常說的湖倉一體的概念,即 Lake House。
趨勢三:大數據更加青睞存儲計算分離的架構
存儲與計算是對物理資源不同緯度的需求,存儲和計算分離的架構更加靈活,方便對存儲和計算獨立進行擴縮容,成本更優更具性價比。
- 大數據更加青睞存儲計算分離的架構,體現在大數據生態更加豐富,由不同的框架解決不同的問題:計算層面有 spark/flink/presto, 存儲層面有 hdfs/ozone/s3,數據管理層面有元數據管理的 hive catalog, 文件格式有 orc/parquet, 表格式 table format 有 hudi/iceberg/delta lake, 資源管理有 yarn/mesos/k8s等等;
- 大數據更加青睞存儲計算分離的架構,也體現在一些傳統的存儲引擎也在進一步細化架構,支持存儲與計算分離:如 NewSQL 數據庫 TidB,在底層分為計算層 TiDB/TiSpark,存儲層 TiKV/TiFlash,元數據層 PD; 如云原生消息系統 pulsa,在底層分為計算層 broker 和存儲層 bookkeeper; 如 hdfs 的進化版 Ozone在底層支持對象存儲;如消息系統 Kafka 也通過 tiered storage 支持本地存儲和遠端云端對象存儲;
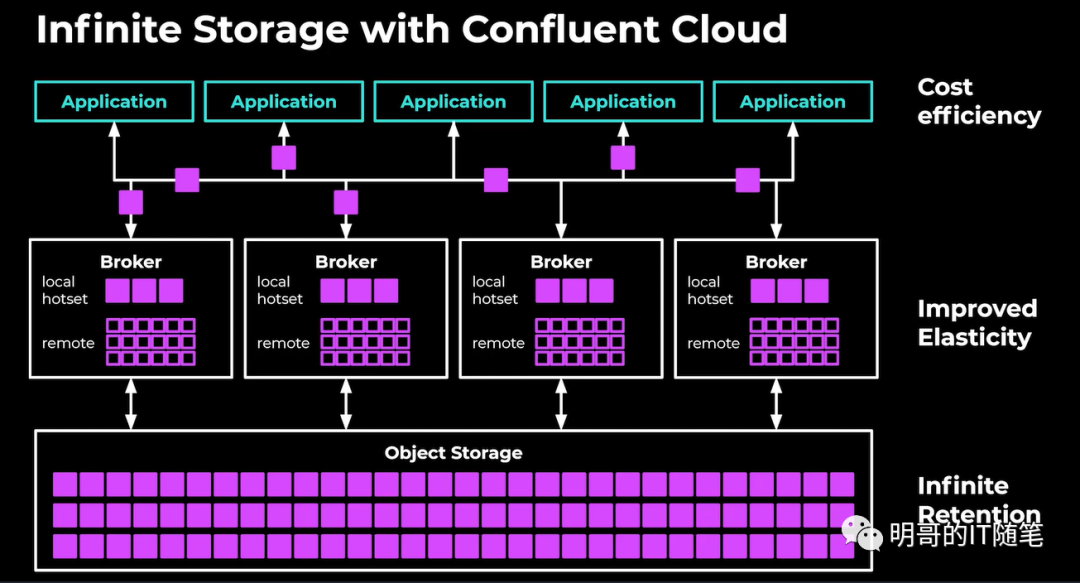
infinite storage with confluent cloud
大數據更加青睞存儲計算分離的架構,還體現在大數據集群整體在架構上也更靈活更適應存儲與計算分離,比如星環的大數據平臺 tdh 底層的 tos 云操作系統是基于k8s和docker的;再比如 Cloudear 的大數據平臺 dcp 的公有云版 cdp public cloud 和私有云版 cdp private cloud,兩者都是集群模式+容器模式,存儲依賴集群模式中的集群,而計算依賴容器模式中的容器,存儲有計算解耦可以獨自進行擴縮容。(私有云版在底層分為 cdp private cloud base 和 cdp private cloud plus,其中base是集群模式,和原來 cdh/hdp 的架構相同;plus是容器模式,底層依托 openShift (底層是k8s)實現跨云多云環境中的容器管理;)!
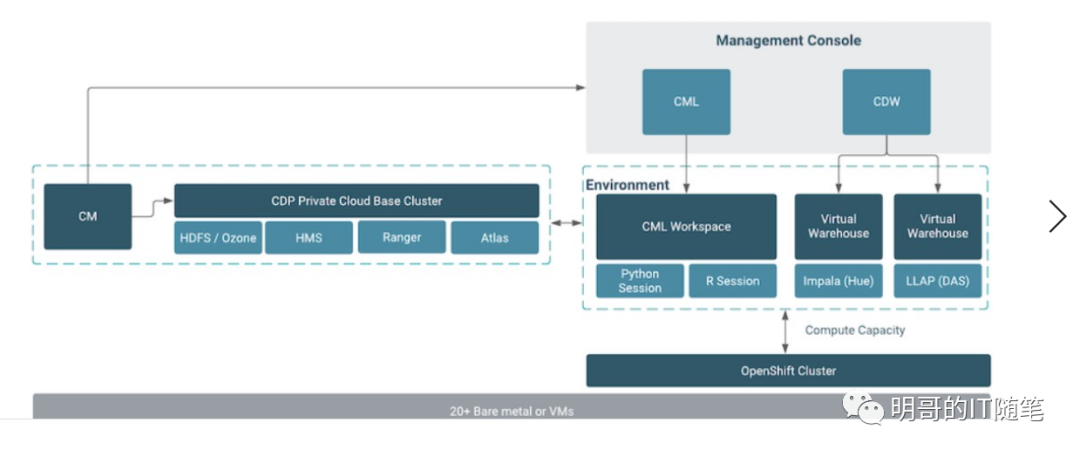
趨勢四:大數據更加青睞對象存儲
大數據為了進一步適應云原生化的大方向,在存儲上相比文件系統,更加青睞對象存儲。
對象存儲在性能上比不上文件系統,尤其是對文件和目錄的重命名 rename 操作上,以及對目錄的 list 操作上,(對象存儲沒有目錄樹的概念,所謂的目錄是抽象出來的;很多云廠商會限制對目錄的 list 操作的次數),但是對象存儲相比文件系統,在成本和擴展性上更有優勢,所以云廠商更青睞對象存儲。
當然了,大數據為適應對象存儲,自身在架構和技術上也在不斷演進,比如大數據的數據倉庫框架 hive 在擴展性上受到不少詬病,而其擴展性問題的一個原因,就是在對元數據的管理上只做到了目錄粒度而不是文件粒度,即 hive 在管理表和分區的元數據時,只記錄了表和分區對應的目錄,至于該目錄底層有哪些文件,是在計算時通過 list 掃描得到的,由于在對象存儲系統中 list 是比較昂貴的操作,所以在對接對象存儲時,hive 這樣處理顯然是不合適的。事實上,更適應云原生和對象存儲的框架如 Iceberg/Delta lake等,在元數據中都做到了文件的粒度而不是目錄的粒度。
關于文件系統和對象存儲的詳細對比,有興趣的小伙伴可以自行 google,明哥在這里不再贅述。
趨勢五:大數據和機器學習/人工智能日益融合
大數據和機器學習/人工智能日益融合的趨勢,體現在大數據需要AI上,也體現在AI需要大數據上。
- 一方面,大數據需要AI:
- 大數據的元數據管理需要AI: 當企業面對數據量大且種類繁多的數據資產時(大數據的 5V 包括 volume 和 variety),如何有效管理和使用這些數據以挖掘更大商業價值,就尤其需要數據治理和元數據管理了。元數據的范疇和概念在擴大化,元數據不再僅僅是數據管理人員事先提供的靜態的元數據,還包括利用機器學習可推導得出的動態發現的元數據。Gartner 推崇 Data Fabric 數據經緯的概念, 該概念尤其強調元數據管理和增強型數據管理,即主動利用機器學習驅動的元數據,快速提供來自于不同數據源的數據并自動化數據管理。這其中會更多地用到圖計算和知識圖譜,“Graphs form the foundation of data fabrics and knowledge graphs“,來幫助我們發現數據之間潛在的關聯關系。
- 大數據將我們從從BI時代帶到了AI時代, 對數據的分析也不再是BI時代簡單的統計分析和提供各種報表,而是AI時代更強調的綜合使用各種算法做 Augmented analytics 提供 data story等商業洞察;
- 在物聯網的各種邊緣設備 edge 上也更加提倡通過邊緣計算內嵌各種 ML 和 AI 模型,將基于AI的計算推到更靠近數據產生的地方,以提供更高的數據時效性,以減少數據傳輸,以挖掘更多應用場景等等。
- 另一方面,AI 也需要大數據:從事人工智能相關工作的小伙伴們,都知道 AI 有個三要素的概念,即:數據,算法,算力,其中數據的質量和數量,決定了模型好壞的上限;而好的算法和足夠的算力,可以推動模型的效果更逼近這個上限。
- 三要素中的數據作為 AI 的原材料,跟大數據有著密不可分的關系,正是大數系統提供了AI的數據原材料。在現階段,算法同學一般是從大數據系統中提取出來數據,存放在本地文件系統中,再進行模型的訓練;不過已經有一些大數據框架,著手于利用大數據系統中的數據直接進行模型訓練和模型部署與應用了,比如 spark mllib, koalas, flink ml;我們也看到,alluxio client 通過 fuse api 接口以本地文件的形式,直接提供大數據平臺中的數據給算法模型進行訓練,起到了數據橋梁的作用,減少了中間數據導出的繁瑣過程。
- 三要素中的算力,也可以依賴大數據的集群資源管理框架來提供,比如 yarn 在對 cpu 和 mem 資源管理的基礎上,已經擴展支持了對 gpu 資源的管理;
- 三要素中的算法,在很多大數據框架也直接提供了對常見算法的實現,比如 spark mllib, flink ml等。
趨勢六:大數據日益重視數據安全與數據治理
明哥覺得,現階段數據安全問題日益凸顯,有以下幾方面的原因:
- 一方面企業本身仍然面臨著傳統的各種內外部數據威脅,這點沒啥新意,我們就不再贅述;
- 另一方面,國家出臺了各種政策和法規需要遵守沒有重視數據合規性的企業會面臨政府的天價罰單,(我們看到前段時間滴滴上市前臨門一腳被叫停,就是處于數據安全)。
- 還有一點,就是在云環境下,安全問題更加凸顯。以往大數據都是在數據中心的內網運行,面臨的威脅少暴露出來的也不多;而當前隨著大數據上云的趨勢,大量云計算廠商推出了自己云上托管的大數據服務,云上應用案列越來越多,遭受的攻擊嘗試也越來越多,相應的被發現和暴露出來的安全漏洞問題也就越來越多。
在應對數據安全問題上,傳統的3A 即 authentication, authorization 和 audit 的概念仍然適用,encryption 加密算法也仍然使用,具體使的支撐框架常見的有 Kerberos, ldap, knox, ranger 和 sentry 等。
在數據治理上,前文提到,當企業面對數據量大且種類繁多的數據資產時(大數據的 5V 包括 volume 和 variety),如何有效管理和使用這些數據以挖掘更大商業價值,就尤其需要數據治理和元數據管理了。此時元數據的范疇和概念有擴大化的趨勢,元數據不再僅僅是數據管理人員事先提供的靜態的元數據,還包括利用機器學習可推導得出的動態發現的元數據。
在數據治理上,Gartner 推崇 Data Fabric 數據經緯的概念, 該概念尤其強調元數據管理和增強型數據管理,即主動利用機器學習驅動的元數據,快速提供來自于不同數據源的數據并自動化數據管理。這其中會更多地用到圖計算和知識圖譜,“Graphs form the foundation of data fabrics and knowledge graphs“,來幫助我們發現數據之間潛在的關聯關系。
數據治理的一些相關概念,包括元數據,主數據,數據血緣等,支撐框架包括 atlas,ranger 等。
趨勢七:大數據日益重視數據的時效性
大數據強調數據有熱度,數據價值具有時效性且隨著時間的推移價值會遞減,這是大家的共識,也是實時計算和準實時計算日益受到業界重視的原因,筆者沒有太多補充,不過我想指出一點,即實時計算究竟需要做到什么級別的實時,是在業務需求,現有技術能力,和運維復雜性之間的妥協,并不是一定總是要追求毫秒微妙級別的實時,很多時候秒級別分鐘級別甚至小時級別的延時,也是可以接受的。
業界這塊相關的概念有流批一體,仔細分析又包括存儲引擎層面的流批一體,計算框架層面的流批一體,以及業務代碼層面的流批一體。
在存儲引擎層面,離線批量處理場景一般使用文件系統結合數據庫;實時準實時流處理場景一般使用消息隊列結合數據庫。不過隨著數據湖倉概念的崛起,尤其是伴隨著 delta lake/hudi/iceberg 的崛起和 hive 實時化的進展,使用這些框架做流批一體的存儲的案列將會越來越多(當然對應的場景是分鐘級別的準實時的場景);隨著 kafka 支持tiered storage , 使用 kafka結合對象存儲并配置合適的 retention period 做流批一體的存儲的案例也會越來越多。
在計算框架層面,flink 和 spark 都支持流批一體,即同一個計算框架即支持用戶的流處理應用程序,也支持用戶的批處理應用程序。
在業務代碼層面的流批一體上,即同一套業務代碼,不做任何代碼層面的改動,僅僅通過配置不同的參數,就能提交做為流處理或批處理應用程序運行,目前看來似乎 FLINK SQL 走得最遠做得最好。


















