













Golang | 是返回Struct還是返回Struct的指針
當我們定義一個函數時,是返回結構體呢,還是返回指向結構體的指針呢?
對于這個問題,我想大部分人的回答,肯定都是返回指針,因為這樣可以避免結構體的拷貝,使代碼的效率更高,性能更好。
但真的是這樣嗎?
在回答這個問題之前,我們先寫幾個示例,來確定一些基本事實:
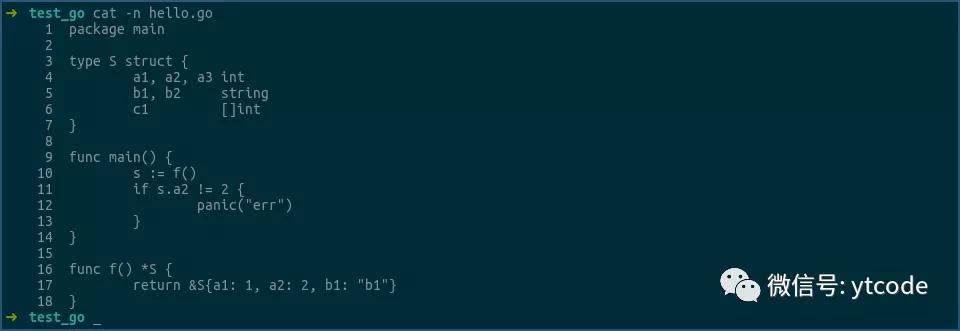
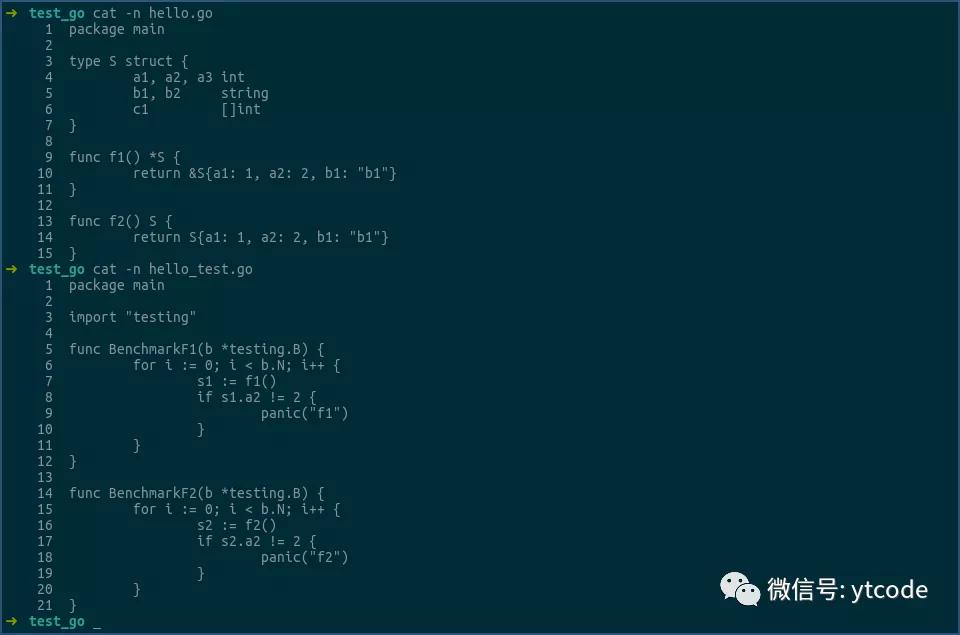
上圖中,函數f返回的是結構體S的指針,即一個地址,這個可以通過其匯編來確認:
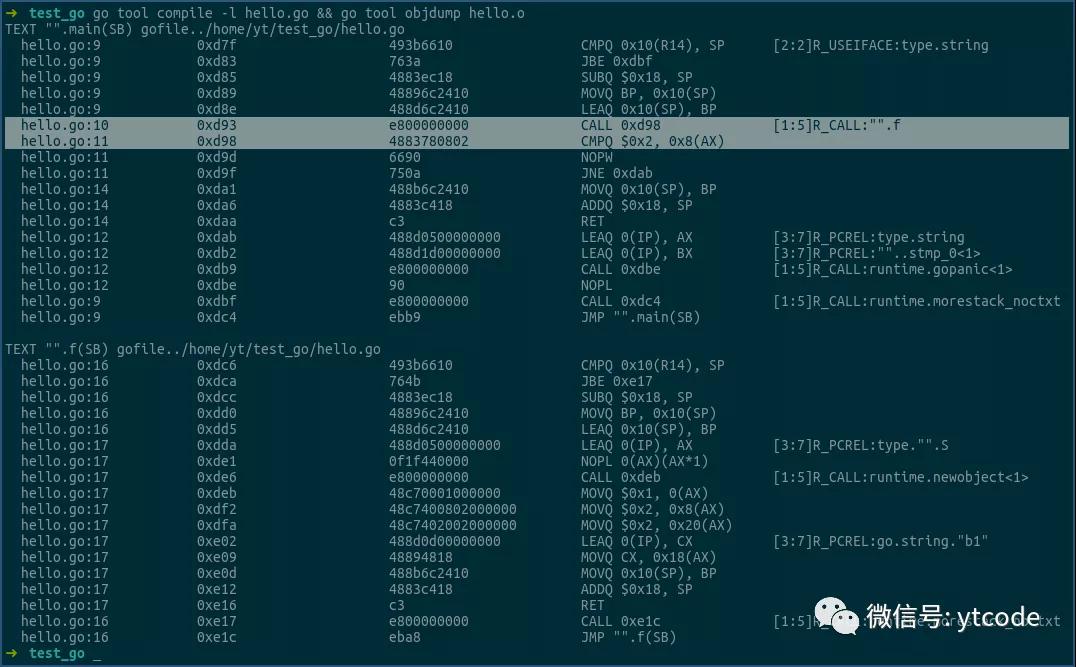
看上圖中的選中行。
第一行是調用函數f,其結果,即結構體S的指針,或結構體S的地址,是放到ax寄存器中返回的。
第二行用0x8(ax),即ax中的地址加8的形式,來獲得結構體S中a2字段的值,然后將該值和0x2相比,以進行后續邏輯。
由此可見,返回結構體指針的形式,確實是只傳遞了一個地址。
我們再來看下返回結構體的情況:
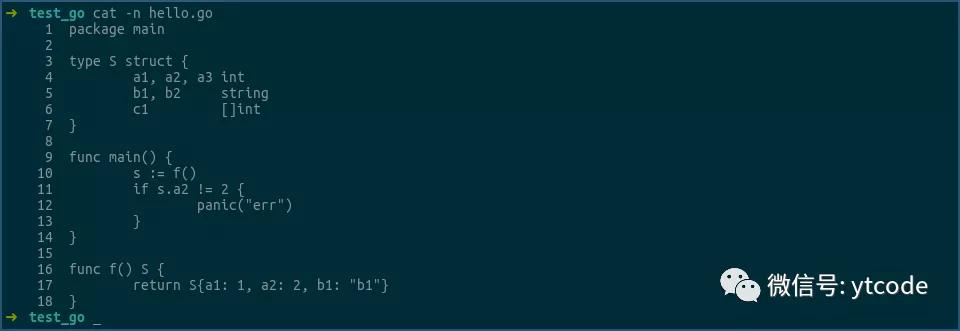
這次函數f返回的是S,而不是*S,看看這樣寫其匯編是什么樣子:
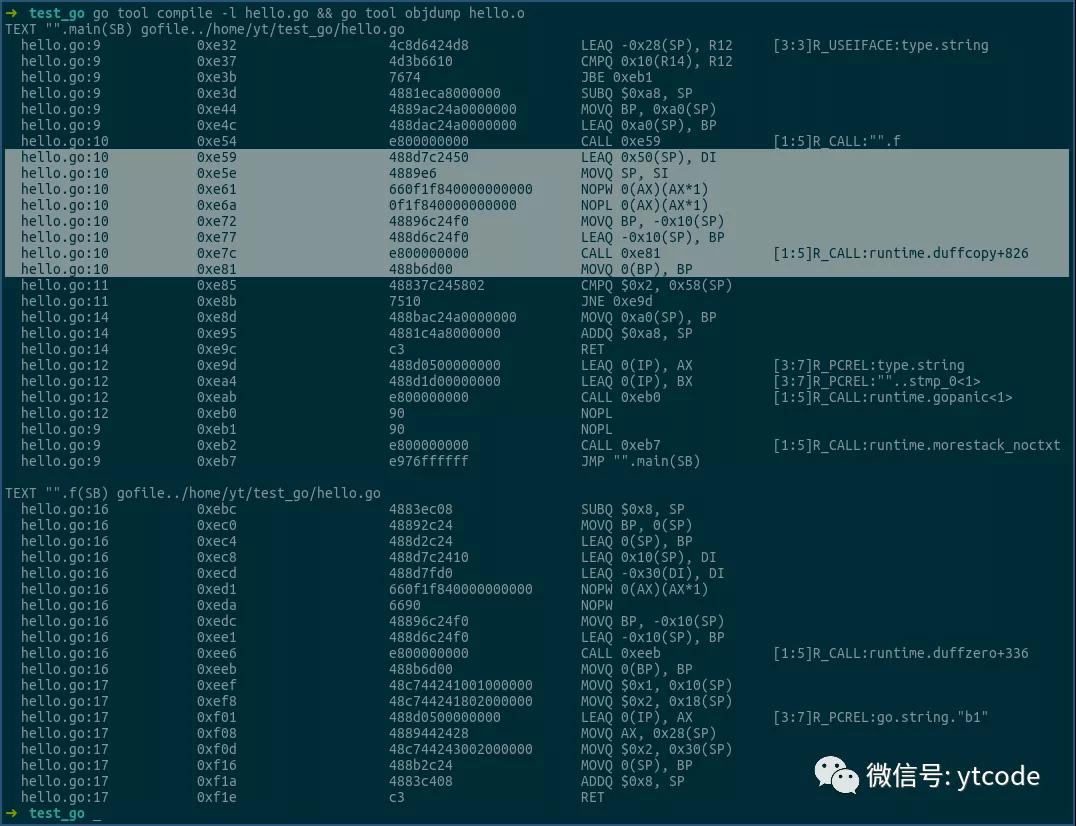
上圖main函數的匯編中,通過調用函數f,初始化了main函數棧中,0x0(sp)到0x50(sp)的內存段,該內存段共有80個字節,正好對應于結構體S的大小。
在函數f返回后,sp寄存器存放的,正是函數f初始化的結構體S的地址。
接著,我們看上圖中的選中行,該段邏輯通過runtime.duffcopy函數,將棧中內存段0x0(sp)到0x50(sp)的值,拷貝到了內存段0x50(sp)到0xa0(sp)的部分,即將函數f初始化的結構體S,從內存地址0x0(sp),拷貝到了0x50(sp)。
然后,通過0x58(sp),即sp中的地址加上0x58的形式,獲得拷貝后的結構體S中,a2字段的值,最后將其和0x2比較,以進行后續邏輯。
由上可見,當函數返回結構體時,確實存在著一次結構體的拷貝操作。
對比以上兩個示例我們看到,返回指針的確會更好些,因為這樣節省了一次結構體的拷貝操作。
但這樣性能就真的更好嗎?
寫個benchmark測試下:
執行看下結果:

這兩個benchmark的時間幾乎是相等的,其結果并不像我們預料的那樣,返回指針的形式會更快些。
為什么呢?
看下這兩個benchmark對應的匯編:

它們居然都被優化成了空跑for循環了,難怪這兩個測試耗時是一樣的。
加上編譯器指令//go:noinline,防止f1/f2函數被內聯,進而被過度優化:

如上圖的第9行和第14行。
再來看下測試程序的匯編,確保以上操作是有效的。
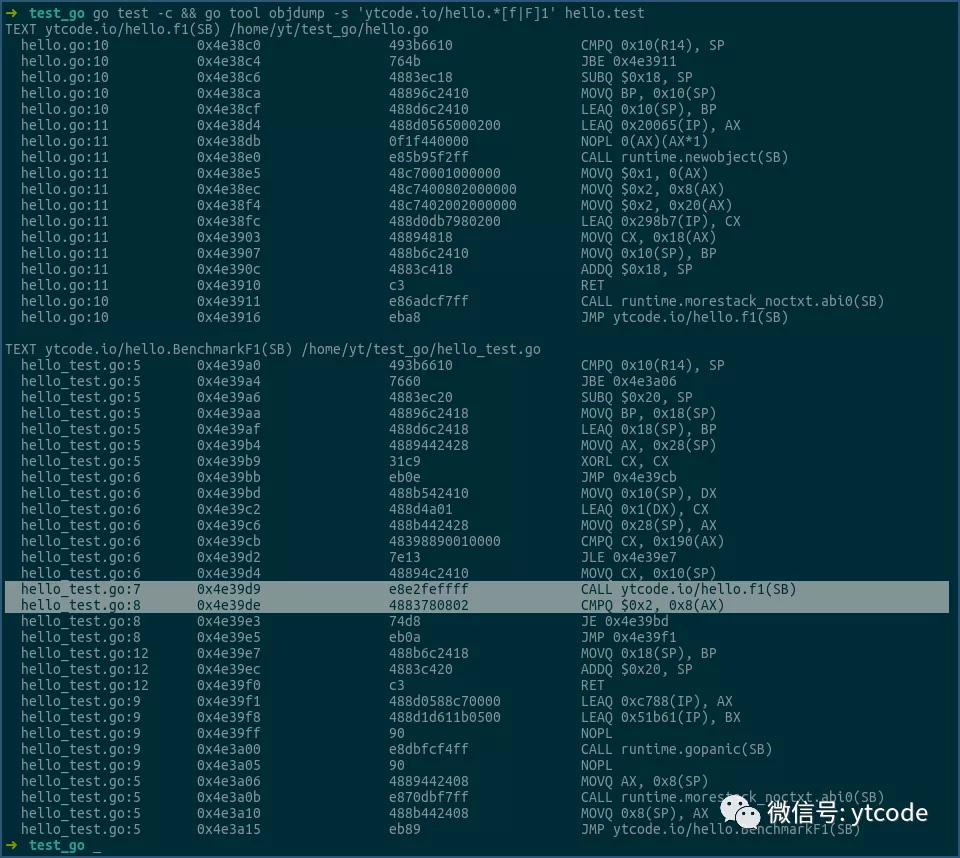
先看下函數f1及其對應的benchmark:
再看下函數f2及其對應的benchmark:
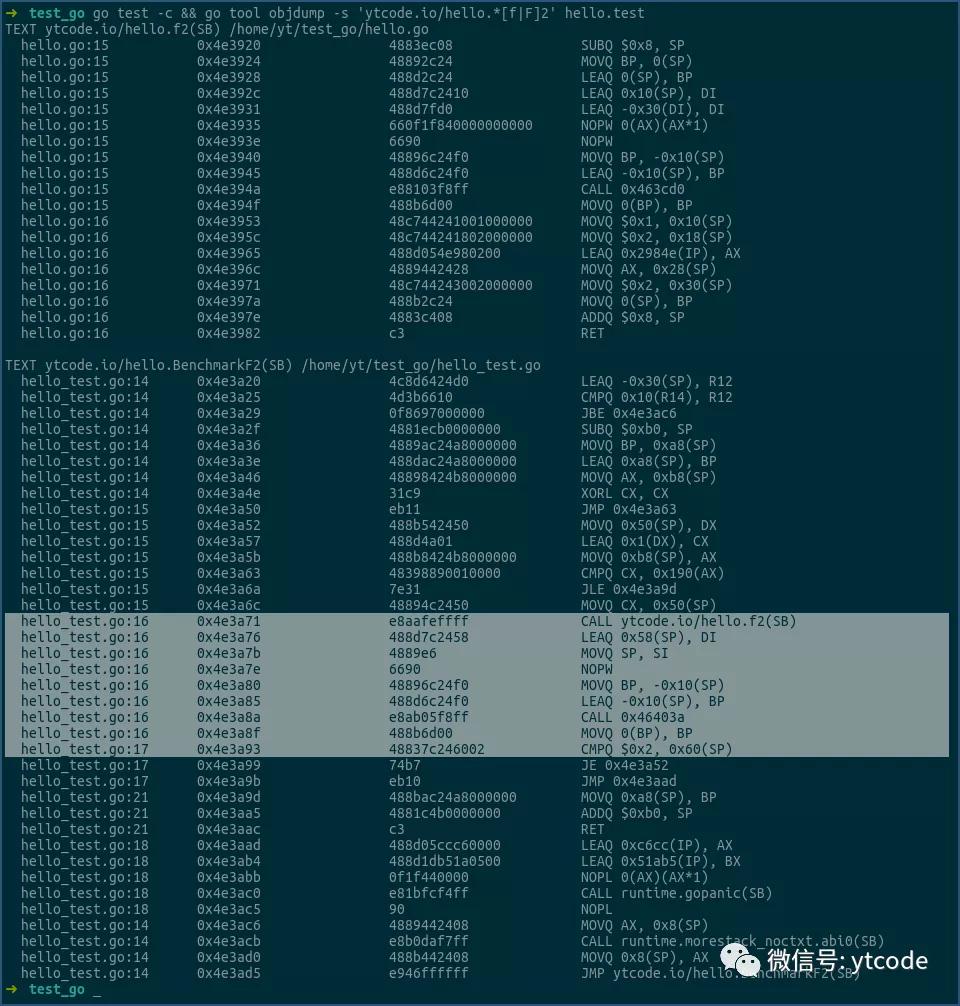
這次這兩個都沒有問題。
再來跑下benchmark:

這次結果顯示,f2函數,即返回結構體形式,比f1函數,即返回指針的形式,居然快了將近5倍,意不意外?
這是為什么呢?
其實在上圖中,就有一些線索。
看BenchmarkF1那行,其最后兩列顯示,每次調用f1函數,都會有一次堆內存分配操作,其分配內存的大小為80字節,正好對應于結構體S的大小,也就是說,f1函數中結構體S的內存,都是在堆上分配的。
而在BenchmarkF2中,就沒有發生堆內存的分配操作,f2函數中的結構體S,都是在棧上分配的。
這個也可以通過上面展示的,f1/f2函數的匯編代碼看到。
f1函數的匯編是通過runtime.newobject在堆上分配內存的,而f2函數則是直接就在棧上把內存分配好了,并沒有調用runtime.newobject函數。
那為什么在堆上分配內存,會比在棧上分配內存慢這么多呢?
有兩點原因,一是在堆上分配內存的函數runtime.newobject,其本身邏輯就比較復雜,二是堆上分配的內存,后期還要通過gc來對其進行內存回收,這些邏輯加起來,遠比在棧上分配內存,外加一次拷貝操作要耗時的多。
有關go內存是在堆上分配的,還是在棧上分配的,這個是在編譯過程中,通過逃逸分析來確定的,其主體思想是:
假設有變量v,及指向v的指針p,如果p的生命周期大于v的生命周期,則v的內存要在堆上分配。
其實逃逸分析的具體邏輯,遠比上面說的復雜,如果有興趣研究代碼,可以從下面開始入手:
當然,我們也可以在編譯時,通過加上-m參數,來讓編譯器告訴我們,一個變量到底是分配在堆上,還是在棧上:
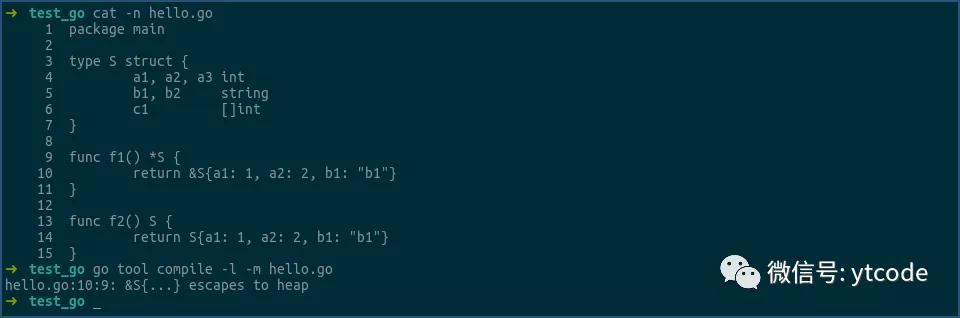
看上圖,f1函數中的&S{...}逃逸到了堆上,即是在堆上分配的。
以上是對80字節大小的結構體,返回指針和返回值情況的比較,那如果結構體字節數更小或更大會怎么樣呢?
經過測試,1MiB字節以下,返回結構體都更有優勢。
那返回指針的方式是不是沒用了呢?也不是,如果你最終的結構體,就是要存放到堆里,比如要存放到全局的map里,那返回指針優勢就更大些,因為其省去了返回結構體時的拷貝操作。
就這些,希望對你有所幫助。
本文轉載自微信公眾號「卯時卯刻」,可以通過以下二維碼關注。轉載本文請聯系卯時卯刻公眾號。























