MySQL讀多寫少設(shè)計方案 - 分庫分表還能這么做?
本文轉(zhuǎn)載自微信公眾號「JerryCodes」,作者KyleJerry。轉(zhuǎn)載本文請聯(lián)系JerryCodes公眾號。
通過主從復(fù)制的技術(shù)把數(shù)據(jù)復(fù)制多份,讀操作只讀取從數(shù)據(jù)庫中的數(shù)據(jù),這樣就增強了抵抗大量并發(fā)讀請求的能力,提升了數(shù)據(jù)庫的查詢性能。這時,你的系統(tǒng)架構(gòu)如下:
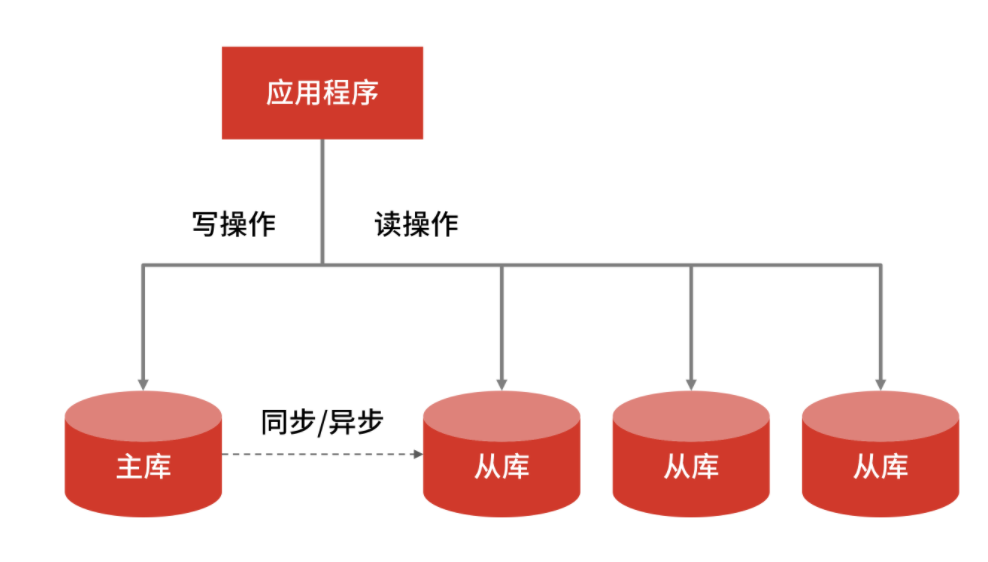
- 系統(tǒng)架構(gòu)圖
- 案例背景
如何確定分庫還是分表?
何時分表
何時分庫
垂直拆分
Range(范圍分片)
- 如何解決數(shù)據(jù)查詢問題?
- 總結(jié)
案例背景
假設(shè)在這樣的背景下,面試官出了一道考題:
公司現(xiàn)有業(yè)務(wù)不斷發(fā)展,流量劇增,交易數(shù)量突破了千萬訂單,但是訂單數(shù)據(jù)還是單表存儲,主從分離后,雖然減少了緩解讀請求的壓力,但隨著寫入壓力增加,數(shù)據(jù)庫的查詢和寫入性能都在下降,這時你要怎么設(shè)計架構(gòu)?
這個問題可以歸納為:數(shù)據(jù)庫寫入請求量過大,導(dǎo)致系統(tǒng)出現(xiàn)性能與可用性問題。
要想解決該問題,你可以對存儲數(shù)據(jù)做分片,常見的方式就是對數(shù)據(jù)庫做“分庫分表”,在實現(xiàn)上有三種策略:垂直拆分、水平拆分、垂直水平拆分。
這么回答真的可以嗎?
雖然分庫分表技術(shù)方案很常見,但是在面試中回答好并不簡單。因為面試官不會單純浮于表面問你“分庫分表的思路”,而是會站在業(yè)務(wù)場景中,當數(shù)據(jù)出現(xiàn)寫多讀少時,考察你做分庫分表的整體設(shè)計方案和技術(shù)實現(xiàn)的落地思路。一般會涉及這樣幾個問題:
什么場景該分庫?什么場景該分表?
復(fù)雜的業(yè)務(wù)如何選擇分片策略?
如何解決分片后的數(shù)據(jù)查詢問題?
如何確定分庫還是分表?
針對“如何確定分庫還是分表?”的問題,你要結(jié)合具體的場景。
何時分表
當數(shù)據(jù)量過大造成事務(wù)執(zhí)行緩慢時,就要考慮分表,因為減少每次查詢數(shù)據(jù)總量是解決數(shù)據(jù)查詢緩慢的主要原因。你可能會問:“查詢可以通過主從分離或緩存來解決,為什么還要分表?”但這里的查詢是指事務(wù)中的查詢和更新操作。
何時分庫
為了應(yīng)對高并發(fā),一個數(shù)據(jù)庫實例撐不住,即單庫的性能無法滿足高并發(fā)的要求,就把并發(fā)請求分散到多個實例中去(這種應(yīng)對高并發(fā)的思路我之前也說過)。
總的來說,分庫分表使用的場景不一樣:分表是因為數(shù)據(jù)量比較大,導(dǎo)致事務(wù)執(zhí)行緩慢;分庫是因為單庫的性能無法滿足要求。
如何選擇分片策略?在明確分庫分表的場景后,面試官一般會追問“怎么進行分片?”換句話說就是按照什么分片策略對數(shù)據(jù)庫進行分片?
垂直拆分
垂直拆分是根據(jù)數(shù)據(jù)的業(yè)務(wù)相關(guān)性進行拆分。比如一個數(shù)據(jù)庫里面既存在商品數(shù)據(jù),又存在訂單數(shù)據(jù),那么垂直拆分可以把商品數(shù)據(jù)放到商品庫,把訂單數(shù)據(jù)放到訂單庫。一般情況,垂直拆庫常伴隨著系統(tǒng)架構(gòu)上的調(diào)整。
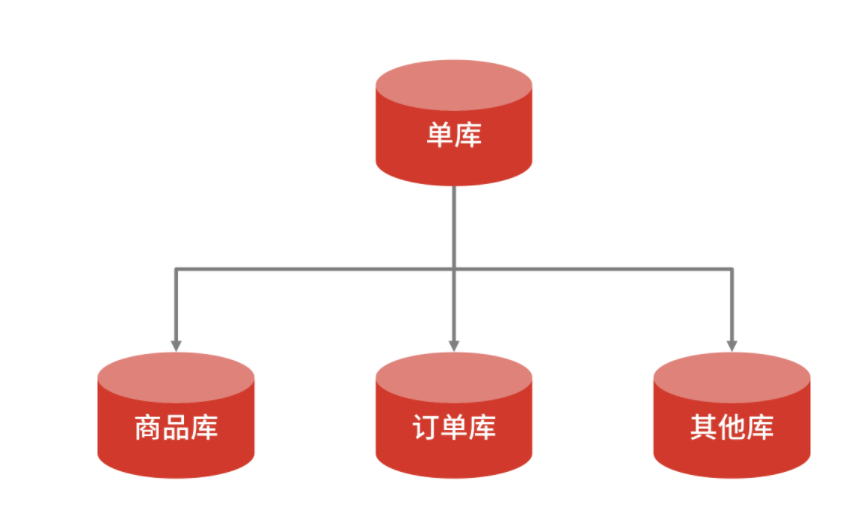
垂直拆分
比如在對做系統(tǒng)“微服務(wù)”改造時,將原本一個單體系統(tǒng)拆分成多個子系統(tǒng),每個系統(tǒng)提供單獨的服務(wù),那么隨著應(yīng)用層面的拆分帶來的也有數(shù)據(jù)層面的拆分,將一個主庫的數(shù)據(jù)表,拆分到多個獨立的子庫中去。
對數(shù)據(jù)庫進行垂直拆分最常規(guī),優(yōu)缺點也很明顯。
垂直拆分可以把不同的業(yè)務(wù)數(shù)據(jù)進行隔離,讓系統(tǒng)和數(shù)據(jù)更為“純粹”,更有助于架構(gòu)上的擴展。但它依然不能解決某一個業(yè)務(wù)的數(shù)據(jù)大量膨脹的問題,一旦系統(tǒng)中的某一個業(yè)務(wù)庫的數(shù)據(jù)量劇增,比如商品系統(tǒng)接入了一個大客戶的供應(yīng)鏈,對于商品數(shù)據(jù)的存儲需求量暴增,在這個時候,就要把數(shù)據(jù)拆分到多個數(shù)據(jù)庫和數(shù)據(jù)表中,也就是對數(shù)據(jù)做水平拆分。
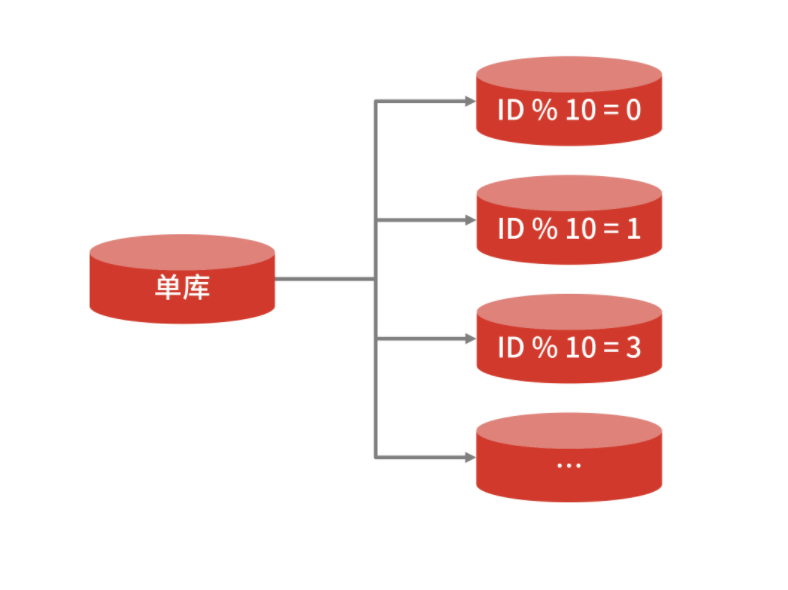
水平拆分
垂直拆分隨架構(gòu)改造而拆分,關(guān)注點在于業(yè)務(wù)領(lǐng)域,而水平拆分指的是把單一庫表數(shù)據(jù)按照規(guī)則拆分到多個數(shù)據(jù)庫和多個數(shù)據(jù)表中,比如把單表 1 億的數(shù)據(jù)按 Hash 取模拆分到 10 個相同結(jié)構(gòu)的表中,每個表 1 千萬的數(shù)據(jù)。并且拆分出來的表,可以分別存放到不同的物理數(shù)據(jù)庫中,關(guān)注點在于數(shù)據(jù)擴展。
Range(范圍分片)
是按照某一個字段的區(qū)間來拆分,最好理解的就是按照時間字段分片,比如可以把一個月的數(shù)據(jù)放入一張表中,這樣在查詢時就可以根據(jù)時間先定位數(shù)據(jù)存儲在哪個表里面,再按照查詢條件來查詢。
但是按時間字段進行范圍分片的場景并不多,因為會導(dǎo)致數(shù)據(jù)分布不均,畢竟不是每個月的銷量都是平均的。所以常見的 Range 分片是按照字段類型,比如按照商品的所屬品類進行分片。這樣與 Hash 分片不同的是,Range 分片就可以加入對于業(yè)務(wù)的預(yù)估。
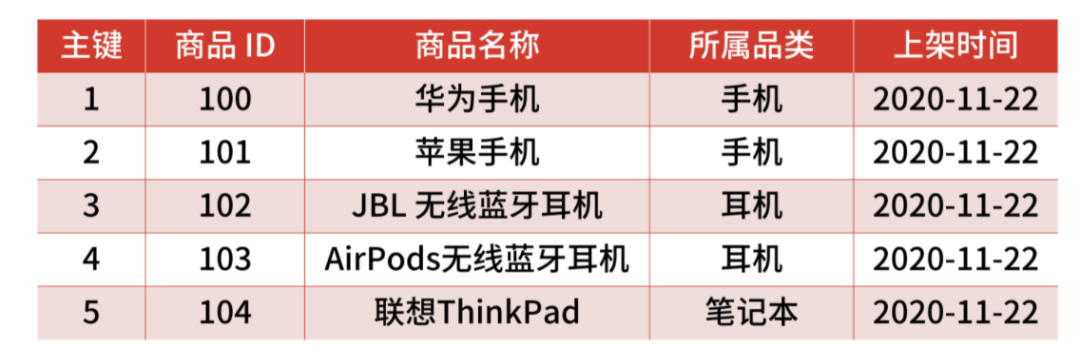
Range 分片
但是同樣的,由于不同“商品品類”的業(yè)務(wù)熱點不同,對于商品數(shù)據(jù)存儲也會存在熱點數(shù)據(jù)問題,這個時候處理的手段有兩個。
1、垂直擴展
由于 Range 分片是按照業(yè)務(wù)特性進行的分片策略,所以可以對熱點數(shù)據(jù)做垂直擴展,即提升單機處理能力。在業(yè)務(wù)發(fā)展突飛猛進的初期,建議使用“增強單機硬件性能”的方式提升系統(tǒng)處理能力,因為此階段,公司的戰(zhàn)略往往是發(fā)展業(yè)務(wù)搶時間,“增強單機硬件性能”是最快的方法。
2、分片元數(shù)據(jù)
單機性能總是有極限的,互聯(lián)網(wǎng)分布式架構(gòu)設(shè)計高并發(fā)終極解決方案還是水平擴展,所以結(jié)合業(yè)務(wù)的特性,就需要在 Range 的基礎(chǔ)上引入“分片元數(shù)據(jù)”的概念:分片的規(guī)則記錄在一張表里面,每次執(zhí)行查詢的時候,先去表里查一下要找的數(shù)據(jù)在哪個分片中。
這種方式的優(yōu)點是靈活性高,并且分片規(guī)則可以隨著業(yè)務(wù)發(fā)展隨意改動。比如當某個分片已經(jīng)是熱點了,那就可以把這個分片再拆成幾個分片,或者把這個分片的數(shù)據(jù)移到其他分片中去,然后修改一下分片元數(shù)據(jù)表,就可以在線完成數(shù)據(jù)的再分片了。
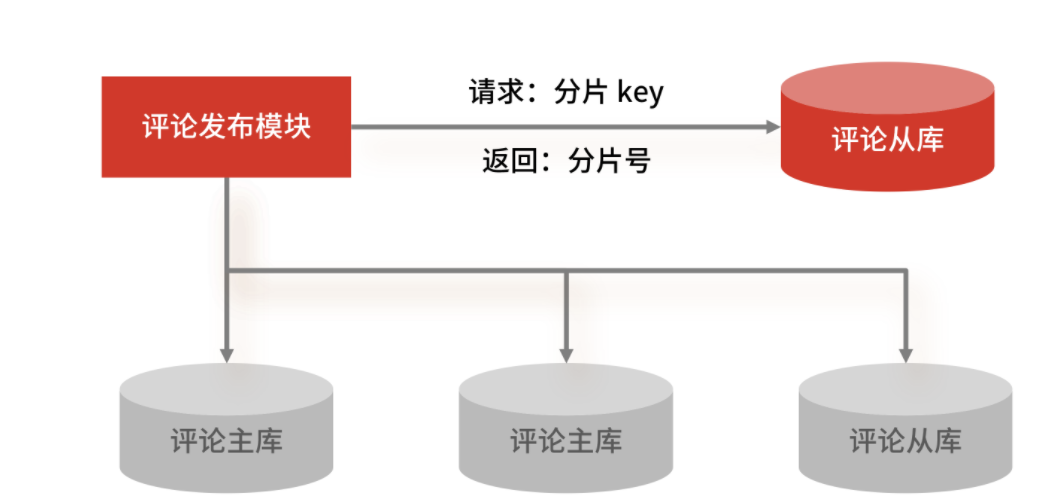
分片元數(shù)據(jù)
但你要注意,分片元數(shù)據(jù)本身需要做高可用。方案缺點是實現(xiàn)起來復(fù)雜,需要二次查詢,需要保證分片元數(shù)據(jù)服務(wù)的高可用。不過分片元數(shù)據(jù)表可以通過緩存進行提速。
垂直水平拆分,是綜合垂直和水平拆分方式的一種混合方式,垂直拆分把不同類型的數(shù)據(jù)存儲到不同庫中,再結(jié)合水平拆分,使單表數(shù)據(jù)量保持在合理范圍內(nèi),提升性能。
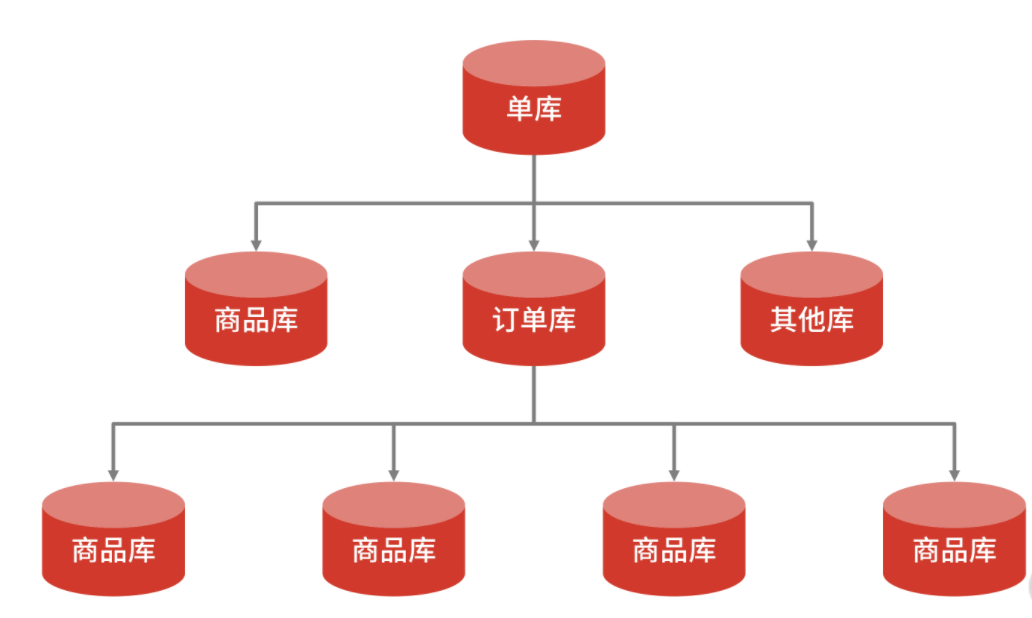
垂直水平拆分
如何解決數(shù)據(jù)查詢問題?
分庫分表引入的另外一個問題就是數(shù)據(jù)查詢的問題(比較常見),比如面試官會問類似的問題:
在未分庫分表之前,我們查詢數(shù)據(jù)總數(shù)時,可以直接通過 SQL 的 count() 命令,現(xiàn)在數(shù)據(jù)分片到多個庫表中,如何解決呢?
解題思路很多,你可以考慮其他的存儲方案,比如聚合查詢使用頻繁時,可以將聚合查詢的數(shù)據(jù)同步到 ES 中,或者將計數(shù)的數(shù)據(jù)單獨存儲在一張表里。如果是每日定時生成的統(tǒng)計類報表數(shù)據(jù),也可以將數(shù)據(jù)同步到 HDFS 中,然后用一些大數(shù)據(jù)技術(shù)來生成報表。
總結(jié)
總的來說,在面對數(shù)據(jù)庫容量瓶頸和寫請求并發(fā)量大時,你可以選擇垂直分片和水平分片:
垂直分片一般隨著業(yè)務(wù)架構(gòu)拆分來進行;
水平分片通常按照 Hash(哈希分片)取模和 Range(范圍分片)進行,并且,通常的形態(tài)是垂直拆分伴隨著水平拆分,即先按照業(yè)務(wù)垂直拆分后,再根據(jù)數(shù)據(jù)量的多少決定水平分片。
Hash 分片在互聯(lián)網(wǎng)中應(yīng)用最為廣泛,簡單易實現(xiàn),可以保證數(shù)據(jù)非常均勻地分布到多個分片,但其過濾掉了業(yè)務(wù)屬性,不能根據(jù)業(yè)務(wù)特性進行調(diào)整。而 Range 分片卻能預(yù)估業(yè)務(wù),更高效地掃描數(shù)據(jù)記錄(Hash 分片由于數(shù)據(jù)被打散,掃描操作的 I/O 開銷更大)。
除了 Hash 分片和 Range 分片,更為靈活的方式是基于分片元數(shù)據(jù)。