如何閱讀源碼 —— 以 Vetur 為例
本文轉載自微信公眾號「Tecvan」,作者范文杰 。轉載本文請聯系Tecvan公眾號。
我很早就意識到,能熟練、高效閱讀開源前端框架源碼是成為一個高級前端工程師必須具備的基本技能之一,所以在我職業生涯的最早期,就已經開始做了很多次相關的嘗試,但結果通常都以失敗告終,原因五花八門:
- 缺乏必要的背景知識,猶如閱讀天書
- 不理解項目架構、設計理念,始終不得要領
- 目標不夠聚焦,閱讀過程容易復雜化
- 容易陷入細節,在不重要的問題上糾結半天
- 容易追著分支流程跑,分散注意力
- 沒有及時記錄筆記和總結,沒有把知識碾碎、重組、內化成自己的東西
- 沒有處理過特別復雜問題的經歷,潛在的不自信心理
- 個人毅力、韌性不足,或者目標感不夠強烈,遇到困難容易放棄
- 等等
這個列表還可以繼續往下拉很長很長,總之既有我自己主觀認知上的限制又有切切實實的客觀原因。后來因為工作的契機硬著頭皮看完 Vue 和 mxGraph 的源碼,發現事情并沒有自己想象中那么困難,后來前前后后陸續看了很多框架源碼,包括 Webpack、Webpack-sources、Vite、Eslint、Babel、Vue-cli、Vuex、Uniapp、Lodash、Vetur、Echarts、Emmet 等等,愚鈍如我也慢慢摸索出了一些普適的方式方法,進而斗膽撰下這篇文章,不敢說授人以漁,但至少也該拋磚引玉吧。
所以這是一篇為哪些有意,或準備,或已經在閱讀前端框架源碼的同學而寫的文章,我會在這里拋出一些經過我個人多次實踐總結出來的閱讀技巧和原則,并結合 Vetur 源碼,具體地講解我在閱讀源碼的各個階段所思所想,希望能給讀者帶來一些啟發。
弄清楚目標
在介紹具體的技巧之前,有必要先跟讀者探討一下閱讀源碼的動機,想清楚到底需不需要通過這種方式提升自身技能,雖然學習優秀框架源碼確實有非常多不言自明的好處,但每個人的經驗、所處的語境、訴求、思維習慣不同,實際學習效果在不同個體或個體的不同時期必然存在極大的差異,這里面最大的變量一是經驗,二是目標,經驗因人而異,且很難在短時間內補齊,沒有太多討論空間;倒是目標方面值得盤道盤道。
第一層,先弄清楚為啥要閱讀源碼?可能的原因有很多,例如:
- 為了增進對框架的認知深度,提升個人能力
- 為了應對面試
- 為了解決當下某個棘手的 bug 或性能問題
- 基于某些原因,需要對框架做二次改造
- 反正閑著,也不知道該學點啥,試試唄。。。
- 好奇
這里面有一些很抽象,例如最后一個“好奇”;有一些很具體,例如“為了做二次改造”;還有一些在具體與抽象之間。按照 SMART 原則的說法,越具體、可衡量的目標越容易達成,如果讀者的目標還處在比較模棱兩可,不夠具體詳細的階段,那執行過程大概率會翻車,畢竟這是一件特別消耗精力與耐性的活兒。
對于這種情況,我的建議是不妨往更細節的層次再想一想,例如對于最后一點“好奇”,可以想想具體有哪些特性讓你特別神奇,值得花時間精力去細致地探索,放在 Vetur 語境下可以是“我想了解 Vetur 的 template 錯誤提示與 eslint 如何結合在一起,實現模板層面的錯誤提示功能”,這就很具體很容易衡量了。
第二層,讀者如果已經有了明確、具體、可衡量的目標,不妨在開始之前先自問幾個問題:
- 當下確實需要以閱讀源碼的方式增進自己對框架的認知深度嗎?有沒有一些更輕量級,迭代速度更快的學習方式?
- 你所選定的框架,其復雜度、技術難度是否與你當下的能力匹配?最好的狀態是你自認為踮踮腳就能夠到,過高,不具有可行性;過低,ROI 不值當。
如果經過這番推敲之后,必要性、可行性、相關性都與個人目標契合,那就沒啥可猶豫的。
第三層,需要辯證地去看待所謂“目標” —— 不是把整個項目完整讀完讀通才叫成功,如果能從一些語句、片段、局部模塊中習得新的設計思維、工具方法,甚至僅僅是命名規范都可以算作個人的一點進步,積少成多遠比拔苗助長靠譜的多。所以一開始沒必要把目標定的太高,能剛剛好滿足自身需求是最好的,過程中如果發現問題域的復雜度在不斷膨脹變大,持續投入很多時間卻始終沒有明顯成效的話,那建議果斷放棄或者請求外援,重新評估目標與可行性之后再做決定。
總之,這是一個預期管理的問題,我們可以多參考 SMART 原則,多從具體、可衡量、可行性、相關性幾個維度思考,不斷推敲是否需要做這件事;如何拆解目標,用目標反推計劃,不斷推進個人成功。
閱讀技巧
了解背景知識
「知識」是形成「理解」的必要條件,展開學習任何一個開源項目之前都有必要花點時間調研項目相關的基礎知識,漸進構建起一套屬于你自己的知識體系,這包括:
- 優質參考資料 —— 收集一波質量較高的學習資料,收集過程可以同步通讀一遍
- 框架是如何運行的 —— 也就是所謂的入口
- IO —— 框架如何與外部交互?它通常接受什么形態的運行參數?輸出什么形式的結果?
- 生態 —— 優秀的框架背后通常都帶有一套成熟的生態系統,例如 Vue,框架衍生品如何補齊框架本身的功能缺失?它們以何種方式,以什么樣的 IO 與主框架交互?遵循怎么樣的寫法規則?
- 如何斷點調試 —— 這幾乎是最有效的分析方法,斷點調試能夠幫助你細致地了解每一行代碼的作用。
注意,這里的目標是迅速構建起關于這個開源項目的抽象 —— 甚至不太準確的知識框架,有意思地避免陷入無盡的細節中,就像在閱讀一篇文章的時候,可以先看看目錄結構粗略地了解文章的信息框架,了解文章大概內容。
例如,我剛開始學習 Vetur 的時候只知道這是一個 VS Code 插件,但完全不了解插件怎么寫、怎么運行、怎么實現語言特性,所以我做的第一件事情是仔仔細細閱讀 VS Code 的官方文檔(所幸文檔非常齊全,不像某著名打包工具),學習關于插件開發的基本知識,包括:

進一步總結關于 VS Code 語言插件的要素:
- 「怎么寫插件」:通過 package.json 文件的 contributes 、main 等屬性,聲明插件的功能與入口
- 「怎么運行」:開發階段使用 F5 啟動調試
- 「怎么編寫語言特性」:使用 「詞法高亮、Language API、Language Server Protocol」 三類技術實現
VS Code 領域的知識量還是很龐大的,學習背景知識并梳理成這種高度結構化、高度抽象的腦圖能夠給你一個更高層、全面的視角,理想狀態下,后續實際分析源碼的時候這些骨架脈絡能夠讓你非常本能地映射到某一個切面的知識點,事半功倍。
六步循環分析
接下來,我會介紹一套我常用的分析流程:
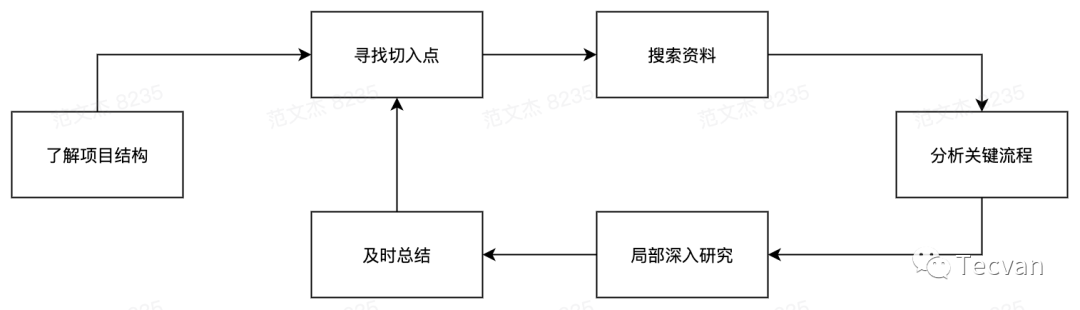
整體分為六個步驟:
- 理解項目結構
- 尋找合適的切入點
- 就著切入點查閱文章資料
- 就著切入點分析代碼流程
- 局部深入研究
- 及時總結
之后,再繼續設定切入點,重復執行上述流程直到透徹地理解了問題
這是一套在 「總-分-總」 視角之間反復橫跳最終構建出完整視角的方法論,重點就在于告訴讀者在什么階段應該關注什么,忽略什么,輸入什么,輸出什么,我個人就是按照這個方法慢慢摸索出包括 Webpack、Babel、Vue、Vetur、mxGraph 在內的各種開源框架的實現原理。
理解項目結構
剛開始閱讀源碼的時候,相信大多數人都會很懵逼,無從下手,這是因為讀者對項目缺乏一個必要的框架性認知,不了解程序的入口在哪里、關鍵組件有哪些、各個文件夾有什么作用等,遇到問題無法迅速推測實現路徑。
所以,閱讀源碼的第一個步驟,應該是先花點時間粗淺地分析、理解項目的組織結構。所幸一個值得深入閱讀學習的開源項目,通常都會有較強的整體性與一致性,我們只需要梳理出三條線索:
- 分析項目入口
- 分析項目依賴了哪些基礎工具,包括編譯工具,如 webpack、Typescript、babel;基礎庫,如 lodash、tapable、snabbdom。
- 將項目中重要文件夾、文件逐一列舉出來,理解它們如何按照依賴關系組成一個整體的架構。
放在 vetur 語境下,我們在上面“了解背景知識”一節已經了解到 VS Code 插件需要在 package.json 文件通過 contributes 等屬性聲明插件的配置信息,所以這幾個問題都能在 package.json 文件找到答案。
入口分析
首先,需要識別出 Vetur 應用的入口,這一步的作用是幫助我們理解 Vetur 是如何向 VS Code 貢獻新特性的。分析 vetur 的 package.json 發現有三種直接指向到文件的配置項:
- contributes.languages 指定語言配置文件
- contributes.grammars 指定語法配置文件
- "main": "./dist/vueMain.js" 指定插件執行入口
三個入口分別實現三種不同的語言特性功能,略顯復雜,這里有必要分別展開了解一下。
探索 contributes.languages 配置
逐個講解,contributes.languages 配置信息指向到 ./languages/***-language-configuration.json 文件,如:
- {
- // ...
- "contributes": {
- "languages": [
- {
- "id": "vue",
- "configuration": "./languages/vue-language-configuration.json"
- },
- {
- "id": "vue-html",
- "configuration": "./languages/vue-html-language-configuration.json"
- }
- // ...
- ]
- }
- // ...
- }
這里回過頭翻一下 VS Code 對 [contributes.languages](https://code.visualstudio.com/api/references/contribution-points#contributes.languages) 的解釋(感謝資源豐富的 VS Code 社區):
Contribute definition of a language. This will introduce a new language or enrich the knowledge VS Code has about a language.
大意是說 contributes.languages 配置項的作用主要是增進 VS Code 對具體語言的理解,至于怎么增強呢?繼續打開配置項中的 ./languages/vue-language-configuration.json 文件:
- {
- "comments": {
- // symbol used for single line comment. Remove this entry if your language does not support line comments
- "lineComment": "//",
- // symbols used for start and end a block comment. Remove this entry if your language does not support block comments
- "blockComment": [
- "/*",
- "*/"
- ]
- },
- // ...
- }
文件中定義了行內 comment、塊級 comment、括號、折疊等語言規則的配置,規則都很簡單直白,篇幅關系這里不展開。
回顧一下探索步驟:
- 翻閱參考資料,理解 contributes.languages 配置的作用
- 打開對應入口文件,猜測各個配置項的作用
- 繼續翻閱參考資料,或者修改配置,驗證猜想
探索 contributes.grammars 配置
contributes.grammars 項包含諸多指向到 ./syntaxes/vue-xxx.json 的配置信息,形如:
- {
- "contributes": {
- "grammars": [
- {
- "language": "vue",
- "scopeName": "source.vue",
- "path": "./syntaxes/vue-generated.json",
- "embeddedLanguages": {
- "text.html.basic": "html",
- // ...
- }
- },
- {
- "language": "vue-postcss",
- "scopeName": "source.css.postcss",
- "path": "./syntaxes/vue-postcss.json"
- }
- // ...
- ]
- }
- }
同樣的,我們先查一下官網對 [contributes.grammars](https://code.visualstudio.com/api/references/contribution-points#contributes.grammars) 配置項的解釋:
Contribute a TextMate grammar to a language. You must provide the language this grammar applies to, the TextMate scopeName for the grammar and the file path.
這段描述略微復雜,大意是開發者可以通過 grammars 屬性提供關于語言的 TextMate 形式的語法描述,grammars 配置項包含三個屬性:
- language:語言的名稱
- scopeName:語言的分類,與 TextMate scopeName 同義,可用于嵌套語法定義
- path:語言的詞法規則文件
這里面 path 屬性指向一個內容更復雜的配置文件 ./syntaxes/vue-xxx.json,我們可以接著打開其中任意一個文件,關鍵內容結構如下:
- {
- "name": "Vue HTML",
- "scopeName": "text.html.vue-html",
- "fileTypes": [],
- "uuid": "ca2e4260-5d62-45bf-8cf1-d8b5cc19c8f8",
- "patterns": [
- // ...
- {
- "name": "meta.tag.any.html",
- "begin": "(<)([A-Z][a-zA-Z0-9:-]*)(?=[^>]*></\\2>)",
- "beginCaptures": {
- "1": {
- "name": "punctuation.definition.tag.begin.html"
- },
- "2": {
- "name": "support.class.component.html"
- }
- }
- }
- ],
- "repository": {
- // ...
- }
- }
按照 Syntax Highlight Guide(https://zjsms.com/e7E5Jdq/) 一節的說法這里面最重要的是 patterns 屬性,而 patterns 屬性最關鍵的功能就是以正則語句表達語言的詞法分析規則,并分配詞法對應的 name 命名,詳細的配置規則還可以繼續參考 TextMate 官網,這里大致理解作用即可,先不展開深究。
探索 main 配置
接著往下看,第三個值得關注的是 main 屬性,在 vetur 中對應的值為:
- "main": "./dist/vueMain.js"
VS Code 官網對 main 屬性的解釋非常精簡:「The entry point to your extension」,也就是插件的入口,通常需要指向到可執行的 JS 文件,插件啟動時 VS Code 會執行這個入口文件導出的 activate 方法,內容框架大致為:
- import vscode from 'vscode';
- export async function activate(context: vscode.ExtensionContext) {
- // ... 啟動邏輯
- }
在 Vetur 中,activate 函數定義在 client/vueMain.ts 文件,分析源碼可知該函數主要完成如下事項:
- 調用 registerXXXCommands 方法注冊一系列命令
- 調用 initializeLanguageClient 方法初始化 LSP Client 對象
這兩個操作具體的作用,我們先按下不表,后面再展開。
小結
對入口的分析就到這里了,我們先總結、記錄下關鍵信息:
- Vetur 本質上是一個 VS Code 插件,所有配置 —— 包括入口都記錄在 package.json 文件中
- Vetur 包含三種啟動入口:
- contributes.languages:定義一些簡單的語言基本配置,包括怎么折疊,怎么注釋
- contributes.grammars:定義了一套基于 TextMate 引擎的詞法規則,用于實現代碼高亮
- main:定義了插件的啟動入口,入口中注冊了一系列命令,同時創建了基于 LSP 協議的 Language Client 對象,而 LSP 協議用于實現如代碼補全、錯誤診斷、跳轉定義等高級特性
到這里,雖然我們還是不了解 Vetur 的實現細節,但是對 Vetur 的背景知識與項目結構應該已經有了一個比較基礎的認知,已經能大致識別哪些功能由哪些模塊實現。
OK,這里先保持好這個模模糊糊的認知就行了,不要花太多時間。
基礎依賴分析
接下來,需要梳理一下 Vetur 的基礎依賴,這一步的作用是幫助我們理解 Vetur 可能用到哪些基礎技術,比如用到哪些工程化工具、怎么編譯、怎么檢查代碼等。
- Vetur 的 package.json 文件主要包含三類信息:
- VS Code 插件配置信息,大體上在上一節都有描述,這里不展開
工程化命令,核心有:
- watch:對應命令為 rollup -c rollup.config.js -w ,由此可以推斷 Vetur 基于 Rollup 實現構建
- compile:功能與 watch 相似
- lint:對應命令為 tslint -c tslint.json **.ts ,由此可以推斷 Vetur 基于 tslint 實現代碼檢查
項目的 devDependencies 依賴,主要包含 typescript、tslint、rollup、vscode-languageclient、husky、mocha、vscode-test、prettier
那么,從這些信息我們基本可以推斷出如下信息:
- Vetur 使用 Rollup + typescript 等工具執行構建工作,按常理執行 yarn watch 命令應該就能啟動一個持續的構建工作進程
- Vetur 使用 tslint 實現代碼檢查,配合 huscky + prettier 完成格式化工作
- Vetur 使用 mocha + vscode-test 實現自動化測試
文件結構
接著,還需要稍微展開看看 Vetur 的文件結構,這一步能夠一定程度上幫助我們理解 Vetur 的代碼架構及要素,推測各種特性是在什么位置實現的。Vetur 的文件結構大致上如下:
- vetur
- ├─ .vscode
- │ ├─ ...
- ├─ build
- │ ├─ ...
- ├─ client
- │ ├─ client.ts
- │ ├─ commands
- │ │ ├─ ...
- │ ├─ grammar.ts
- │ ├─ ...
- ├─ languages
- │ ├─ vue-html-language-configuration.json
- │ ├─ ...
- ├─ scripts
- │ ├─ build_grammar.ts
- │ └─ tsconfig.json
- ├─ server
- │ ├─ .gitignore
- │ ├─ .mocharc.yml
- │ ├─ .npmrc
- │ ├─ bin
- │ │ └─ vls
- │ ├─ package.json
- │ ├─ rollup.config.js
- │ ├─ src
- │ │ ├─ ...
- ├─ syntaxes
- │ ├─ markdown-vue.json
- │ ├─ pug
- │ │ ├─ ...
- │ ├─ ...
- │ └─ vue.yaml
- ├─ test
- │ ├─ ...
- ├─ vti
- │ ├─ README.md
- │ ├─ bin
- │ │ └─ vti
- │ ├─ package.json
- │ ├─ rollup.config.js
- │ ├─ src
- │ │ ├─ ...
- │ ├─ tsconfig.json
- │ └─ yarn.lock
- ├─ tsconfig.options.json
- ├─ package.json
- ├─ ...
- └─ yarn.lock
其中,比較關鍵的有:
- client:VS Code 插件的入口代碼,package.json 文件中 main 字段會指向這個目錄的產物
- server:LSP 架構中的 Server 端,上述 client 會通過 LSP 協議與這個 server 目錄通信
- syntaxes:Vetur 的詞法規則文件夾,內部包含許多 JSON 格式,符合 TextMate 規則的詞法聲明
- languages:Vetur 提供的語言配置信息,規則比較簡單,了解作用即可,不必深入
- vti:按 vti/bin/vti 文件可以推斷,這里是 Vetur 的命令行工具,不在主流程內可以先忽略
- docs:按內容可以推斷這是 Vetur 的介紹文檔,此處可忽略
- build:構建命令,package.json 文件的 script 命令有一些會指向這個目錄,可以忽略
- 一系列基礎配置文件,包括 tsconfig.json 、package.json 等,可先忽略
我們還可以繼續往下探索各個子目錄的內容,但是注意淺嘗輒止即可,后面隨著源碼閱讀的深入,讀者對各個目錄的理解應該會不斷迭代增長,現在沒必要花太多時間。
小結
回顧一下,我們首先學習了一些背景知識,之后花了一些時間分析項目的入口、基礎依賴、文件結構,到這里我們基本上可以推斷出:
- Vetur 是一個語言插件,所以必然是使用 「詞法高亮、Language API、Language Server Protocol」 三類技術實現核心邏輯的,而 package.json 文件中的 contributes 配置項的內容也恰好驗證了這一點
- 「詞法高亮」 相關的代碼集中在 syntaxes 文件夾
- 「Language Server Protocol」 相關的代碼集中在 client 與 server 文件夾
- 可以用 yarn watch 命令持續構建,配合 F5 快捷鍵啟動調試
這些信息是后續分析源碼的必要條件,而這個過程跟學習一門新語言很類似,讀者可以回想一下最開始學習 JavaScript 的時候,有經驗的學習者不會一上來馬上深入諸如原型、變量提升、事件循環等語言細節,而是先以更高層、更抽象的視角學習 JavaScript 語言的基本骨架,包括函數、循環語句、分支判斷語句、對象等,從而構建起一個抽象的結構化認知,后續再慢慢填充細節,有點自頂向下的味道。
設定切入點
在對項目背景與結構有基本了解之后,我們可以正式開始分析源碼了。首先,讀者要找到一個匹配自身狀態和需求的切入點,本質上就是將大目標拆解成一系列小目標,將大問題拆解成一系列更具體的小問題,然后帶著具體問題更聚焦地去看代碼。
所謂切入點可以直接對標到框架的具體功能,或者某些底層機制的實現上,以 Vetur 為例,它實現了諸多輔助開發 Vue SFC 組件的特性,包括代碼補全、錯誤診斷、代碼高亮、跳轉到定義、hover 提示等等,這里面任意一個展開來都有大量可以挖掘的空間,如果從一開始就漫無目的瞎逛亂看那鐵定是看不出個所以然的,鑒于我的目標就是想通過 Vetur 學習 VS Code 插件的開發套路,所以選擇了一個看起來比較簡單的特性:「代碼補全」 作為第一個切入點,后續的學習經歷證明這是一個非常合適的點,不復雜但是已經能幫我窺見 Vetur 的核心工作機制,以此類推后面分析其它高級特性如代碼高亮、代碼補全等,基本上就是很輕車熟路的狀態了。
如果你有一些更明確的目的,比如解決某個具體的 bug,那你應該會更容易 get 到當下最需要做的事情;如果始終抓不到要點,那么建議先回到前面“了解背景知識”或“理解項目結構”的步驟,繼續探索一些上下文信息,再試試問自己:我接下來到底應該先了解哪些具體功能的實現邏輯?
記住,這并不是一錘子買賣,如果你在后續的分析過程中發現這個切入點變得越來越復雜,超出最開始的預期,不要有心理負擔,這再正常不過了,而且反而側面表現出你對問題域有越來越少的理解了,可以回過頭來重新調整目標,找一個更小的切入點。
善用搜索引擎
定下切入點后,首先要做的不是打開代碼咔咔就干,而應該首先試試在社區搜索相關的資料,畢竟自媒體時代了,很多開源框架的知識已經被無數人吃透、捏碎、重組成各種維度的文章,順著這些文章的思路去理解源碼會比完全靠自己摸索效率高很多。
列舉幾種我常用的搜索渠道:
- 谷歌 and 百度一類的搜索引擎,體感上谷歌的搜索質量會好很多,不過有一定的英語門檻
- 開源項目的官網、社區、wiki、github 等官方渠道,通常都會有比較不錯的資料
- Segmentfault、知乎、掘金、公眾號等垂直社區
- 國外的 Medium/StackOverflow 社區,質量極高,很多大佬在上面活躍
假如搜了一通找不到答案,可以試試不同的關鍵詞組合,我經常用的關鍵詞有:
- Xxx 源碼解析
- Xxx 原理
- 如何實現 xxx
假如還是找不到,還可以試試換一個意思接近的關鍵詞,繞點彎路。總之就是想盡辦法找到有用的,適合當下問題的信息,幫助讀者更快更平滑地深入研究源碼,這一步對新手尤為重要。