美團面試官:講清楚MySQL結構體系,立馬發offer
故事
繼續和大家分享,我去上海美團面試遇到的技術問題,當時,回答的也是馬馬虎虎的,不能說不好,也不能說好,反正就是沒有給面試官一種爽的感覺。
害,很多東西都是,平時感覺還行,一旦到了面試的時候啥都想不起來。
雖然,本人搞Java開發快五年了(2017年),用過Oracle數據庫(銀行里的系統),但大多數時候都是使用MySQL數據庫,但是面對這個問題依然是一臉懵逼(硬著頭皮也扯了一些),還以為面試官要問索引、慢查詢、性能優化之類的(因為這些都是網上找點面試題背過了)。
今天我們就來聊聊MySQL的架構體系,盡管咱們是Java開發人員,但是在日常開發過程中也會經常和MySQL數據庫打交道。如果公司有DBA能干點事還稍微好點,如果是沒有DBA或者DBA沒什么卵用的情況下,我們還是很有必要了解MySQL的整個體系的,況且在面試中遇到了也是一個加分項。
想要知道一條SQL是怎么查詢的,只要對MySQL整個體系搞清楚了,才能說出個123。
所以于情于理,我們很有必要學習一下MySQL的架構體系的。
平時,我和小伙伴們聊天的時候,經常會把MySQL當做我們開發的一個軟件系統,既然是軟件系統,那么就有個架構圖,以及架構是如何分層的,每一層的功能是什么。
MySQL是什么?
- MySQL是一個關系型數據庫管理系統,由瑞典MySQL AB公司開發,目前屬于Oracle公司。
- MySQL是一種關聯數據庫管理系統,將數據保存在不同的表中,而不是將所有數據放在一個大倉庫內,這樣就增加了速度并提高了靈活性。
- MySQL是開源的,所以你不需要支付額外的費用。
- MySQL支持大型的數據庫,可以處理擁有上千萬條記錄的大型數據庫。
- MySQL使用標準的SQL數據語言形式。
- MySQL可以允許于多個系統上,并且支持多種語言,這些編程語言包括C、C++、Python、Java、Ped、PHP、Eifel、Ruby和TCL等。
- MySQL對PHP有很好的支持,PHP是目前最流行的Web開發語言。
- MySQL支持大型數據庫,支持5000萬條記錄的數據倉庫,32位系統表文件最大可支持4GB,64位系統支持最大的表文件為8TB。
- MySQL是可以定制的,采用了GPL協議,你可以修改源碼來開發自己的MySQL系統。
請注意MySQL拼寫,另外,很多人可能有疑問,為什么MySQL的logo是一條海豚?
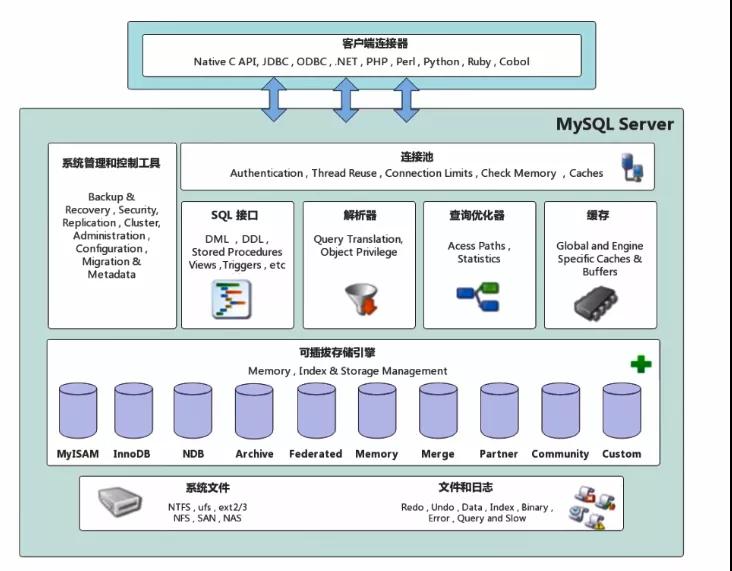
下面我們就來看看MySQL的整體架構圖。
MySQL架構圖
再來看看我們開發的系統架構圖:
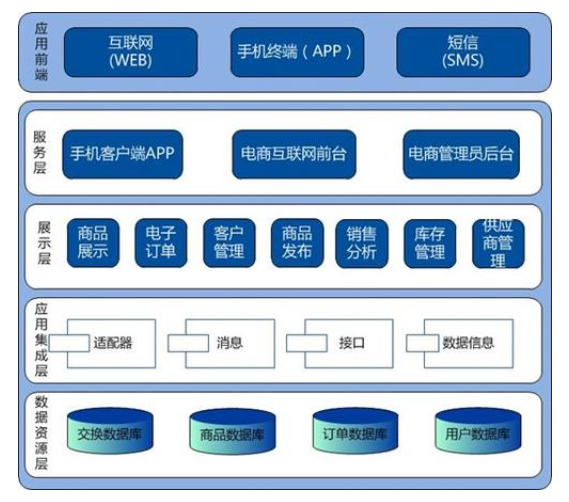
其實還是蠻相似的,都有分層的概念。既然我們開發的軟件系統能進行分層,那么MySQL能分層嗎?
答案是:能,下面我們就來聊聊MySQL的分層情況以及每一層的功能。
架構圖分層
上面的架構圖我們可以對其進行拆分,并做簡要的說明。
連接層

與客戶端打交道,上面已經寫明了能支持的的語言。客戶端的鏈接支持的協議很多,比如我們在 Java 開發中的 JDBC。
這一層是不是有點像我們項目中的網關層?如果對網關不熟悉,那我們可以理解我controller層。
服務層
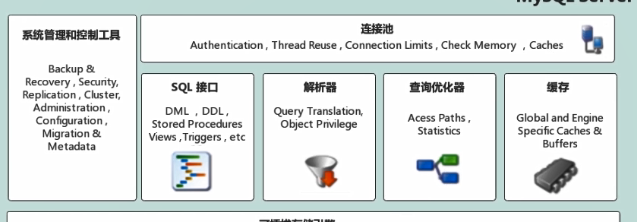
這一層,就相當于我們業務系統中的service層,大雜燴,相關業務的操作、代碼優化、緩存等都在這里面。
連接池
主要是負責存儲和管理客戶端與數據庫的鏈接,一個線程負責管理一個連接。自從引入了連接池以后,官方報道:當數據庫的連接數達到128后,使用連接池與沒有連接池的性能是提升了n倍(反正就是性能大大的提升了)。
連接建立完成后,就可以執行select語句了。執行邏輯就會先來到緩存模塊。
緩存
MySQL拿到一個查詢請求后,會先到查詢緩存看看,之前是不是執行過這條語句。之前執行過的語句及其結果會以key-value對的形式存儲在內存中。key是查詢的語句,value是查詢的結果。如果你的查詢能夠直接在這個緩存中找到key(命中),那么這個value就會被直接返回給客戶端。
如果在緩存中未命中,就會繼續后面的執行階段。執行完成后,執行結果會被存入查詢緩存中。這里可以看到,如果查詢命中緩存,MySQL不需要執行后面的復雜操作,就可以直接返回結果,這個效率會很高。
但是大多數情況下我會建議你不要使用查詢緩存,為什么呢?因為查詢緩存往往弊大于利。
查詢緩存的失效非常頻繁,只要有對一個表的某一條數據更新,這個表上所有的查詢緩存都會被清空。
因此可能很費勁地把結果存起來,還沒使用呢,就被一個更新全清空了。對于更新壓力大的數據庫來說,查詢緩存的命中率會非常低。除非你的業務就是有一張靜態表,很長時間才會更新一次。
比如:一個系統配置表,那這張表上的查詢才適合使用查詢緩存。
好在MySQL也提供了這種“按需使用”的方式。你可以將參數query_cache_type設置成DEMAND,這樣對于默認的SQL語句都不使用查詢緩存。
「注意」:MySQL 8.0版本直接將查詢緩存的整塊功能刪掉了,標志著MySQL8.0開始徹底沒有緩存這個功能了。
解析器
如果沒有命中查詢緩存,就要開始真正執行語句了。首先,MySQL需要知道你要做什么,因此需要對SQL語句做解析。
分析器先會做“詞法分析”。你輸入的是由多個字符串和空格組成的一條SQL語句,MySQL需要識別出里面的字符串分別是什么,代表什么。
做完了詞法分析以后,就要做“語法分析”。根據詞法分析的結果,語法分析器會根據語法規則,判斷你輸入的這個SQL語句是否滿足MySQL語法。
如果我們在拼寫SQL時候,少了或者寫錯了某個字母,,就會收到“You have an error in your SQL syntax”的錯誤提醒。
比如下面這個案例:
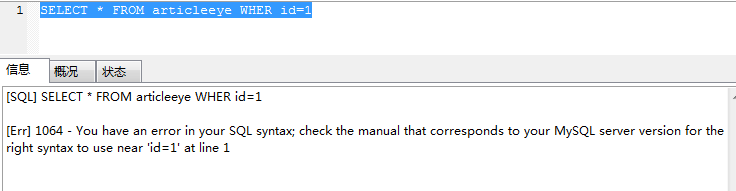
錯誤在于WHERE關鍵字中差了一個E。
同樣,我們使用的SQL如果某個字段不存在。
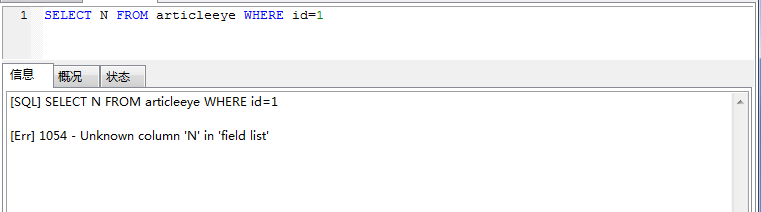
一般語法錯誤會提示第一個出現錯誤的位置,所以你要關注的是緊接“use near”的內容,僅供參考,有時候這個提示也不是非常靠譜。
經過分析器對SQL進行了分析,并且沒有報錯。那么此時就進入優化器中,對SQL進行優化。
優化器
優化器主要是在我們的數據庫表中,如果存在多個多個索引的時候,決定使用哪個索引;或者在一個語句有多表關聯(join)的時候,決定各個表的連接順序 。
比如說:
- SELECT a.id, b.id FROM t_user a join t_user_detail b WHERE a.id=b.user_id and a.user_name='田維常' and b.id=10001
它會在條件查詢上進行優化處理。
優化器處理完成過后,此時就已經確定了SQL的執行方案。然后繼續進入執行器中。
執行器
首先,肯定是要判斷權限,就是有沒有權限執行這條SQL。工作中可能會對某些客戶端進行權限控制。
比如說:生產環境中,對于大部分開發人員都只開查詢權限,沒有增刪改權限(部分小公司除外)。
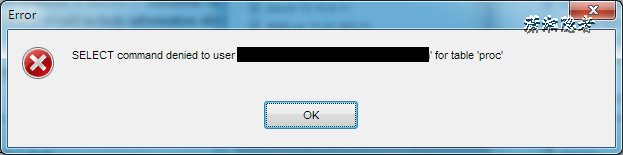
如果有權限,就打開表繼續執行。打開表的時候,執行器就會根據表的引擎定義,去使用這個引擎提供的接口。
存儲引擎層
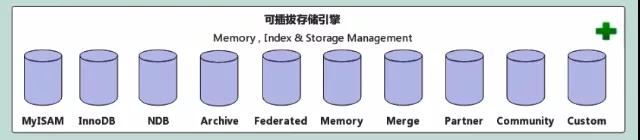
這一層,我們可以理解為我們業務系統中的持久層。
存儲引擎的概念是MySQL里面才有的,不是所有的關系型數據庫都有存儲引擎這個概念 。
數據庫存儲引擎是數據庫底層軟件組織,數據庫管理系統(DBMS)使用數據引擎進行創建、查詢、更新和刪除數據。不同的存儲引擎提供不同的存儲機制、索引技巧、鎖定水平等功能,使用不同的存儲引擎,還可以獲得特定的功能。現在許多不同的數據庫管理系統都支持多種不同的數據引擎。
因為在關系數據庫中數據的存儲是以表的形式存儲的,所以存儲引擎也可以稱為表類型(Table Type,即存儲和操作此表的類型)。
- MySQL5.5版本(mysql 版本 < 5.5版本) 以前,默認使用的存儲引擎是MyISAM 。
- MySQL5.5版本(mysql 版本 >= 5.5版本) 以后,默認使用的存儲引擎是InnoDB 。
下面對部分相對使用多的引擎進行一個對比:
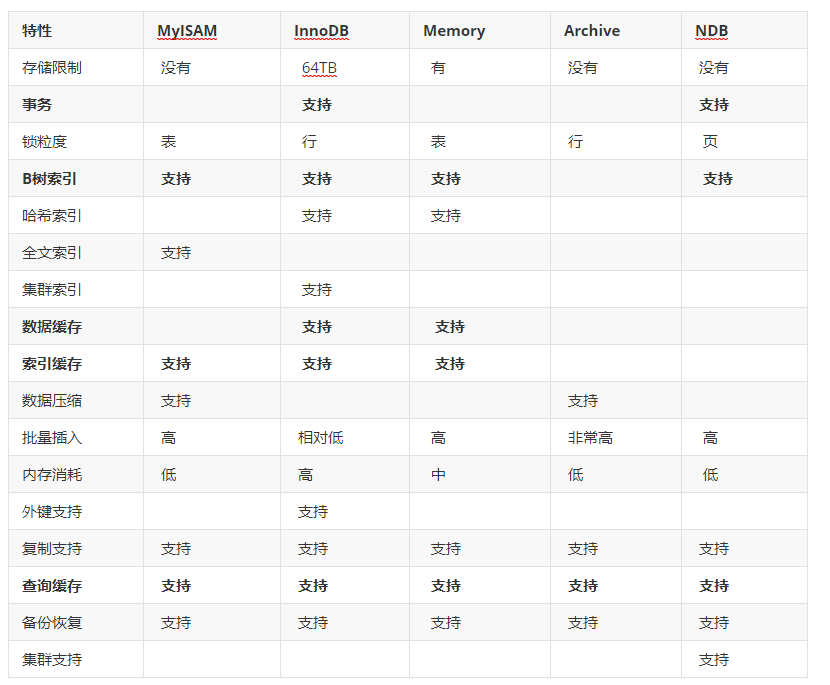
在實際項目中,大多數使用InnoDB,然后是MyISAM,至于其他存儲引擎使用的非常至少。
我們可以使用命令來查看MySQL 已提供什么存儲引擎 :
show engies;
也可以通過命令來查看 MySQL 當前默認的存儲引擎 :
show variables like '%storage_engine%';
MyISAM與 InnoDB引擎的區別
MySQL5.5 版本之前默認的存儲引擎就是 MyISAM 存儲引擎,MySQL 中比較多的系統表使用 MyISAM 存儲引擎,系統臨時表也會用到 MyISAM 存儲引擎,但是在 Mysql5.5 之后默認的存儲引擎就是 InnoDB 存儲引擎了。
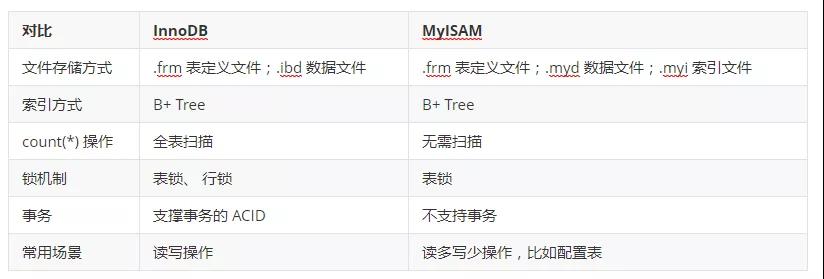
如何在兩種存儲引擎中進行選擇?
- 是否有事務操作?有,InnoDB。
- 是否存儲并發修改?有,InnoDB。
- 是否追求快速查詢,且數據修改較少?是,MyISAM。
- 是否使用全文索引?如果不引用第三方框架,可以選擇MyISAM,但是可以選用第三方框架和InnDB效率會更高。
InnoDB 存儲引擎主要有如下特點:
- 支持事務
- 支持 4 個級別的事務隔離
- 支持多版本讀
- 支持行級鎖
- 讀寫阻塞與事務隔離級別相關
- 支持緩存,既能緩存索引,也能緩存數據
- 整個表和主鍵以 Cluster 方式存儲,組成一顆平衡樹
當然也不是說 InnoDB 一定就是好的,在實際開發中,還是要根據具體的場景來選擇到底是使用 InnoDB 還是 MyISAM 。
MyIASM(該引擎在 5.5 前的 MySQL 數據庫中為默認存儲引擎)特點:
- MyISAM 沒有提供對數據庫事務的支持
- 不支持行級鎖和外鍵
- 由于 2,導致當執行 INSERT 插入或 UPDATE 更新語句時,即執行寫操作需要鎖定整個表,所以會導致效率降低
- MyISAM 保存了表的行數,當執行 SELECT COUNT(*) FROM TABLE 時,可以直接讀取相關值,不用全表掃描,速度快。
兩者區別:
- MyISAM 是非事務安全的,而 InnoDB 是事務安全的
- MyISAM 鎖的粒度是表級的,而 InnoDB 支持行級鎖
- MyISAM 支持全文類型索引,而 InnoDB 在 MySQL5.6 之前不支持全文索引,從 MySQL5.6 之后開始支持 FULLTEXT 索引了。
使用場景比較:
- 如果要執行大量 select 操作,應該選擇 MyISAM
- 如果要執行大量 insert 和 update 操作,應該選擇 InnoDB
- 大尺寸的數據集趨向于選擇 InnoDB 引擎,因為它支持事務處理和故障恢復。數據庫的大小決定了故障恢復的時間長短,InnoDB 可以利用事務日志進行數據恢復,這會比較快。主鍵查詢在 InnoDB 引擎下也會相當快,不過需要注意的是如果主鍵太長也會導致性能問題。
相對來說,InnoDB 在互聯網公司使用更多一些。
系統文件存儲層

這一層,我們同樣的可以理解為我們業務系統中的數據庫。
系統文件存儲層主要是負責將數據庫的數據和日志存儲在系統的文件中,同時完成與存儲引擎的之間的打交道,是文件的物理存儲層。
比如:數據文件、日志文件、pid文件、配置文件等。
數據文件
「db.opt文件」:記錄這個數據庫的默認使用的字符集和校驗規則。
「frm文件」:存儲于邊相關的元數據信息,包含表結構的定義信息等,每一張表都會有一個frm文件與之對應。
「MYD文件」:MyISAM存儲引擎專用的文件,存儲MyISAM表的數據信息,每一張MyISAM表都有有一個.MYD文件。
「MYI文件」:也是MyISAM存儲引擎專用的文件,存放MyISAM表的索引相關信息,每一張MyISAM表都有對應的.MYI文件。
「ibd文件和ibdata文件」:存放InnoDB的數據文件(包括索引)。InnoDB存儲引擎有兩種表空間方式:獨立表空間和共享表空間。
- 獨享表空間使用ibd文件來存放數據,并且每一張InnoDB表存在與之對應的.ibd文件。
- 共享表空間使用ibdata文件,所有表共同使用一個或者多個.ibdata文件。
「ibdata1文件」:系統表空間數據文件,存儲表元數據、Undo日志等。
「ib_logfile0、ib_logfile0文件」:Redo log日志文件。
日志文件
錯誤日志:默認是開啟狀態,可以通過命令查看:
- show variables like '%log_error%';
二進制日志binary log:記錄了對MySQL數據庫執行的更改操作,并且記錄了語句的發生時間、執行耗時;但是不記錄查詢select、show等不修改數據的SQL。主要用于數據庫恢復和數據庫主從復制。也是大家常說的binlog日志。
- show variables like '%log_log%';//查看是否開啟binlog日志記錄。
- show variables like '%binllog%';//查看參數
- show binary logs;//查看日志文件
慢查詢日志:記錄查詢數據庫超時的所有SQL,默認是10秒。
- show variables like '%slow_query%';//查看是否開啟慢查詢日志記錄。
- show variables '%long_query_time%';//查看時長
通用查詢日志:記錄一般查詢語句;
- show variables like '%general%';
配置文件
用于存放MySQL所有的配置信息的文件,比如:my.cnf、my.ini等。
「pid文件」
pid文件是mysqld應用程序在Linux或者Unix操作系統下的一個進程文件,和許多其他Linux或者Unix服務端程序一樣,該文件放著自己的進程id。
「socket文件」
socket文件也是Linux和Unix操作系統下才有的,用戶在Linux和Unix操作系統下客戶端連接可以不通過TCP/IP網絡而直接使用Unix socket來連接MySQL數據庫。
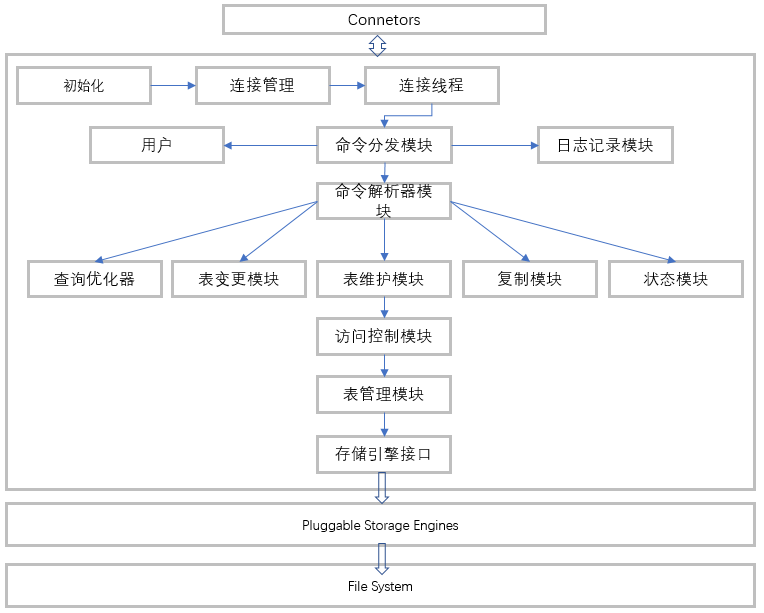
SQL查詢流程圖
總結
MySQL整個系統我們可以看成是我們日常開發的軟件系統,也有接入層,專門對接外面客戶端的,和我們系統的網關就很像,緩存也就類似我們業務代碼中使用的緩存,解析器可以理解為業務系統中參數解析以及參數校驗,優化層可以當做我們開發代碼優化的手段,然后存儲引擎就相當于我們的持久層,文件系統相當于整個業務系統中的數據庫。
可能比喻不是非常的恰當,但是希望大家能領略輕重的含義,目的只有一個,那就是讓大家能輕松掌握MySQL的整體情況。
本文轉載自微信公眾號「Java后端技術全棧 」,可以通過以下二維碼關注。轉載本文請聯系Java后端技術全棧 公眾號。