書寫高質量SQL的建議
作者:報之瓊瑤
今天列舉了一些關于優化 SQL 的建議,多數是實際開發中總結出來的,希望對大家有幫助。
1、避免混亂的邏輯
反例:(統計用戶數量)
- List<User> users = userMapper.selectAll();
- return users.size();
正例:
- int count = userMapper.countUser("select count(*) from user");
- return count;
2、select one 如果已知結果只有一條, 使用limit 1
反例:(查找nickname = 報之瓊瑤 的用戶)
- select id, nickname from t where nickname = '報之瓊瑤'
正例:
- select id, nickname from t where nickname = '報之瓊瑤' limit 1
理由:
- 加上limit1,只要找到了對應的一條記錄, 就不會繼續向下掃描了,效率會大大提高。limit1適用于查詢結果為1條(也可能為0)會導致全表掃描的的SQL語句。
- 如果條件列上有索引就不用limit 1,如主鍵查詢 id = 1
3、盡量避免在where子句中使用or來連接條件
反例:(查找name = 張三 或者 法外狂徒 的用戶)
- select id,name from t where name = '張三' or name = '法外狂徒'
正例:
- select id,name from t where name = '張三'
- union all
- select id,name from t where name = '法外狂徒'
理由:
使用or將導致引擎放棄使用索引而進行全表掃描
4、優化like關鍵字
like常用于模糊查詢, 不恰當的編碼會導致索引失效
反例:
- select userId,name from user where userId like '%123'
正例:
- select userId,name from user where userId like '123%'
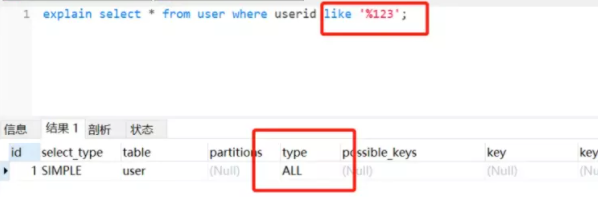
%123, 百分號在前不走索引
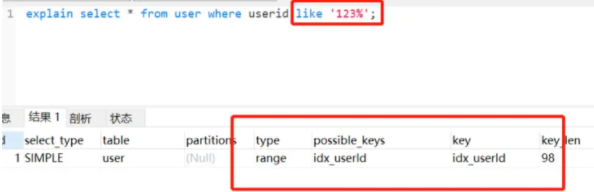
123%,百分號在后走索引
但是也會存在百分號在后不走索引的情況,mysql的innodb存儲引擎最終執行哪種方法都是基于成本計算的, 通過比較全表掃描和二級索引比較再回表查詢
可以通過
INFORMATION_SCHEMA.OPTIMIZER_TRACE來分析查詢過程

trace字段json復制出來即可分析
5、查詢SQL盡量不要使用select *,而是select具體字段, 不要返回用不到的任何字段。
反例:(統計用戶數量)
- select * from t
正例:
- select id, name, tel from t
理由:
- 妨礙優化器選擇更優的執行計劃,比如說索引掃描
- 增刪字段可能導致代碼崩潰
6、盡量避免在索引列上使用mysql的內置函數
反例:
- select * from user where date_add(create_time,Interval 5 day) >=now()
正例:
- select * from user where create_time >= date_add(now(), interval - 5 day)

不走索引
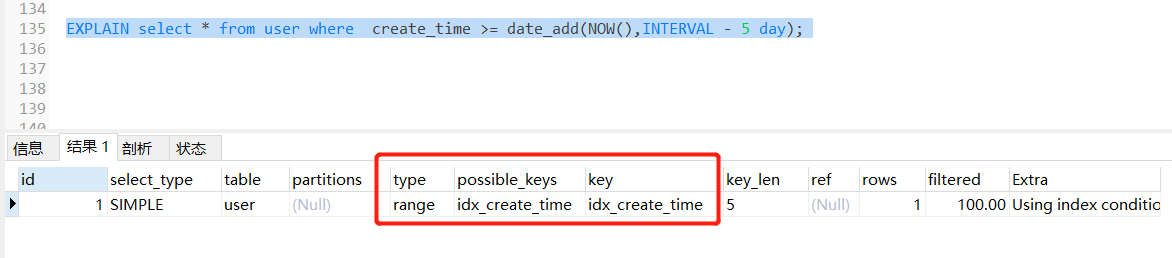
走索引
7、應盡量避免在 where 子句中對字段進行表達式操作,這將導致系統放棄使用索引而進行全表掃
反例: (對字段user_age進行運算操作, 不走索引)
- select * from user where user_age - 1 = 2
正例: (走索引)
- select * from user where user_age = 3
責任編輯:華軒
來源:
今日頭條