













深入解析常見三次握手異常
本文轉載自微信公眾號「開發內功修煉」,作者張彥飛allen。轉載本文請聯系開發內功修煉公眾號。
大家好,我是飛哥!
在后端接口性能指標中一類重要的指標就是接口耗時。具體包括平均響應時間 TP90、TP99 耗時值等。這些值越低越好,一般來說是幾毫秒,或者是幾十毫秒。如果響應時間一旦過長,比如超過了 1 秒,在用戶側就能感覺到非常明顯的卡頓。如果長此以往,用戶可能就直接用腳投票,卸載我們的 App 了。
在正常情況下一次 TCP 連接耗時也就大約是一次 RTT 多一點。但事情不一定總是這么美好,總會有意外發生。在某些情況下,可能會導致連接耗時上漲、CPU 處理開銷增加、甚至是超時失敗。
今天飛哥就來說一下我在線上遇到過的那些 TCP 握手相關的各種異常情況。
一、客戶端 connect 異常
端口號和 CPU 消耗這二者聽起來感覺沒啥太大聯系。但我卻遭遇過因為端口號不足導致 CPU 消耗大幅上漲的情況。來聽飛哥分析分析為啥會出現這種問題!
客戶端在發起 connect 系統調用的時候,主要工作就是端口選擇(參見TCP連接中客戶端的端口號是如何確定的?)。
在選擇的過程中,有個大循環,從 ip_local_port_range 的一個隨機位置開始把這個范圍遍歷一遍,找到可用端口則退出循環。如果端口很充足,那么循環只需要執行少數幾次就可以退出。但假設說端口消耗掉很多已經不充足,或者干脆就沒有可用的了。那么這個循環就得執行很多遍。我們來看下詳細的代碼。
- //file:net/ipv4/inet_hashtables.c
- int __inet_hash_connect(...)
- {
- inet_get_local_port_range(&low, &high);
- remaining = (high - low) + 1;
- for (i = 1; i <= remaining; i++) {
- // 其中 offset 是一個隨機數
- port = low + (i + offset) % remaining;
- head = &hinfo->bhash[inet_bhashfn(net, port,
- hinfo->bhash_size)];
- //加鎖
- spin_lock(&head->lock);
- //一大段的選擇端口邏輯
- //......
- //選擇成功就 goto ok
- //不成功就 goto next_port
- next_port:
- //解鎖
- spin_unlock(&head->lock);
- }
- }
在每次的循環內部需要等待鎖,以及在哈希表中執行多次的搜索。注意這里的是自旋鎖,是一種非阻塞的鎖,如果資源被占用,進程并不會被掛起,而是會占用 CPU 去不斷嘗試獲取鎖。
但假設端口范圍 ip_local_port_range 配置的是 10000 - 30000, 而且已經用盡了。那么每次當發起連接的時候都需要把循環執行兩萬遍才退出。這時會涉及大量的 HASH 查找以及自旋鎖等待開銷,系統態 CPU 將會出現大幅度的上漲。
這是線上截取到的正常時的 connect 系統調用耗時,是 22 us(微秒)。
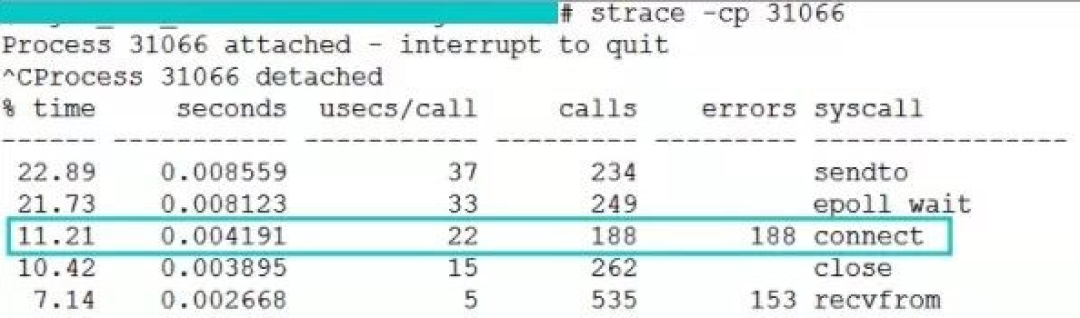
這個是我們一臺服務器在端口不足情況下 connect 開銷,是 2581 us(微秒)。
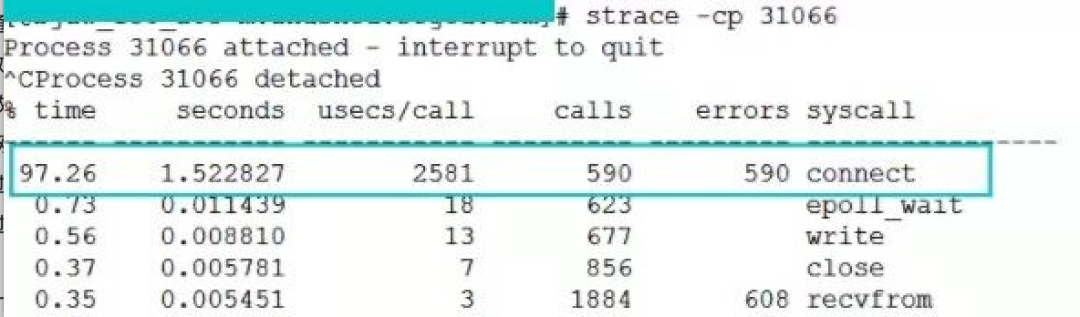
從上兩張圖中可以看出,異常情況下的 connect 耗時是正常情況下的 1000 多倍。雖然換算成毫秒只有 2 ms 多一點,但是要知道這消耗的全是 CPU 時間。
二、第一次握手丟包
服務器在響應來自客戶端的第一次握手請求的時候,會判斷一下半連接隊列和全連接隊列是否溢出。如果發生溢出,可能會直接將握手包丟棄,而不會反饋給客戶端。接下來我們分別來詳細看一下。
2.1 半連接隊列滿
我們來看下半連接隊列在何種情況下會導致丟包。
- //file: net/ipv4/tcp_ipv4.c
- int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb)
- {
- //看看半連接隊列是否滿了
- if (inet_csk_reqsk_queue_is_full(sk) && !isn) {
- want_cookie = tcp_syn_flood_action(sk, skb, "TCP");
- if (!want_cookie)
- goto drop;
- }
- //看看全連接隊列是否滿了
- ...
- drop:
- NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENDROPS);
- return 0;
- }
在上面代碼中,inet_csk_reqsk_queue_is_full 如果返回 true 就表示半連接隊列滿了,另外 tcp_syn_flood_action 判斷是否打開了內核參數 tcp_syncookies,如果未打開則返回 false。
- //file: net/ipv4/tcp_ipv4.c
- bool tcp_syn_flood_action(...)
- {
- bool want_cookie = false;
- if (sysctl_tcp_syncookies) {
- want_cookie = true;
- }
- return want_cookie;
- }
也就是說,如果半連接隊列滿了,而且 ipv4.tcp_syncookies 參數設置為 0,那么來自客戶端的握手包將 goto drop,意思就是直接丟棄!
SYN Flood 攻擊就是通過消耗光服務器上的半連接隊列來使得正常的用戶連接請求無法被響應。不過在現在的 Linux 內核里只要打開 tcp_syncookies,半連接隊列滿了仍然也還可以保證正常握手的進行。
2.2 全連接隊列滿
我們注意到當半連接隊列判斷通過以后,緊接著還有全連接隊列滿的相關判斷。如果這個條件成立,服務器對握手包的處理還是會 goto drop,丟棄了之。我們來看下源碼:
- //file: net/ipv4/tcp_ipv4.c
- int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb)
- {
- //看看半連接隊列是否滿了
- ...
- //看看全連接隊列是否滿了
- if (sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_young(sk) > 1) {
- NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
- goto drop;
- }
- ...
- drop:
- NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENDROPS);
- return 0;
- }
sk_acceptq_is_full 來判斷全連接隊列是否滿了,inet_csk_reqsk_queue_young 判斷的是有沒有 young_ack(未處理完的半連接請求)。
這段代碼可以看到,假如全連接隊列滿的情況下,且同時有 young_ack ,那么內核同樣直接丟掉該 SYN 握手包。
2.3 客戶端發起重試
假設說服務器側發生了全/半連接隊列溢出而導致的丟包。那么從轉換到客戶端視角來看就是 SYN 包沒有任何響應。
好在客戶端在發出握手包的時候,開啟了一個重傳定時器。如果收不到預期的 synack 的話,超時重傳的邏輯就會開始執行。不過重傳計時器的時間單位都是以秒來計算的,這意味著,如果有握手重傳發生,即使第一次重傳就能成功,那接口最快響應也是 1 s 以后的事情了。這對接口耗時影響非常的大。
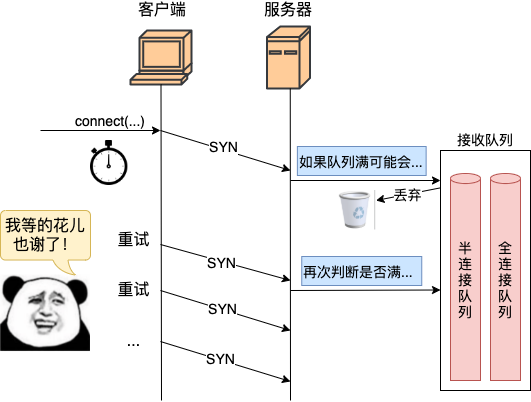
我們來詳細看下重傳相關的邏輯。服務器在 connect 發出 syn 后就開啟了重傳定時器。
- //file:net/ipv4/tcp_output.c
- int tcp_connect(struct sock *sk)
- {
- ...
- //實際發出 syn
- err = tp->fastopen_req ? tcp_send_syn_data(sk, buff) :
- tcp_transmit_skb(sk, buff, 1, sk->sk_allocation);
- //啟動重傳定時器
- inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
- inet_csk(sk)->icsk_rto, TCP_RTO_MAX);
- }
在定時器設置中傳入的 inet_csk(sk)->icsk_rto 是超時時間,該值初始的時候被設置為了 1 秒。
- //file:ipv4/tcp_output.c
- void tcp_connect_init(struct sock *sk)
- {
- //初始化為 TCP_TIMEOUT_INIT
- inet_csk(sk)->icsk_rto = TCP_TIMEOUT_INIT;
- ...
- }
- //file: include/net/tcp.h
- #define TCP_TIMEOUT_INIT ((unsigned)(1*HZ))
在一些老版本的內核,比如 2.6 里,重傳定時器的初始值是 3 秒。
- //內核版本:2.6.32
- //file: include/net/tcp.h
- #define TCP_TIMEOUT_INIT ((unsigned)(3*HZ))
如果能正常接收到服務器響應的 synack,那么客戶端的這個定時器會清除。這段邏輯在 tcp_rearm_rto 里。(tcp_rcv_state_process -> tcp_rcv_synsent_state_process -> tcp_ack -> tcp_clean_rtx_queue -> tcp_rearm_rto)
- //file:net/ipv4/tcp_input.c
- void tcp_rearm_rto(struct sock *sk)
- {
- inet_csk_clear_xmit_timer(sk, ICSK_TIME_RETRANS);
- }
如果服務器端發生了丟包,那么定時器到時后會進行回調函數 tcp_write_timer 中進行重傳。
其實不只是握手,連接狀態的超時重傳也是在這里完成的。不過這里我們只討論握手重傳的情況。
- //file: net/ipv4/tcp_timer.c
- static void tcp_write_timer(unsigned long data)
- {
- tcp_write_timer_handler(sk);
- ...
- }
- void tcp_write_timer_handler(struct sock *sk)
- {
- //取出定時器類型。
- event = icsk->icsk_pending;
- switch (event) {
- case ICSK_TIME_RETRANS:
- icsk->icsk_pending = 0;
- tcp_retransmit_timer(sk);
- break;
- ......
- }
- }
tcp_retransmit_timer 是重傳的主要函數。在這里完成重傳,以及下一次定時器到期時間的設置。
- //file: net/ipv4/tcp_timer.c
- void tcp_retransmit_timer(struct sock *sk)
- {
- ...
- //超過了重傳次數則退出
- if (tcp_write_timeout(sk))
- goto out;
- //重傳
- if (tcp_retransmit_skb(sk, tcp_write_queue_head(sk)) > 0) {
- //重傳失敗
- ......
- }
- //退出前重新設置下一次超時時間
- out_reset_timer:
- //計算超時時間
- if (sk->sk_state == TCP_ESTABLISHED ){
- ......
- } else {
- icsk->icsk_rto = min(icsk->icsk_rto << 1, TCP_RTO_MAX);
- }
- //設置
- inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS, icsk->icsk_rto, TCP_RTO_MAX);
- }
tcp_write_timeout 是判斷是否重試過多,如果是則退出重試邏輯。
tcp_write_timeout 的判斷邏輯其實也有點小復雜。對于 SYN 握手包主要是判斷依據是 net.ipv4.tcp_syn_retries,但其實并不是簡單對比次數,而是轉化成了時間進行對比。所以如果你在線上看到實際重傳次數和對應內核參數不一致也不用太奇怪。
接著在 tcp_retransmit_timer 重發了發送隊列里的頭元素。而且還設置了下一次超時的時間,為前一次的兩倍(右移操作相當于乘2)。
2.4 實際抓包結果
我們來看一個因為服務器端響應第一次握手丟包的握手過程抓包截圖。

通過該圖可以看到,客戶端在 1 s 以后進行了第一次握手重試。重試仍然沒有響應,那么接下來依次又分別在 3 s、7 s 15 s,31 s,63 s 等時間共重試了 6 次(我的 tcp_syn_retries 當時設置是 6)。
假如我們服務器上在第一次握手的時候出現了半/全連接隊列溢出導致的丟包,那么我們的接口響應時間將至少是 1 s 以上(在某些老版本的內核上,SYN 第一次的重試就需要等 3 秒),如果連續兩三次握手都失敗,那 7,8 秒就出去了。你想想這對用戶是不是影響很大。
三、第三次握手丟包
客戶端在收到服務器的 synack 響應的時候,就認為連接建立成功了,然后會將自己的連接狀態設置為 ESTABLISHED,發出第三次握手請求。但服務器在第三次握手的時候,還有可能會有意外發生。
- //file: net/ipv4/tcp_ipv4.c
- struct sock *tcp_v4_syn_recv_sock(struct sock *sk, ...)
- {
- //判斷接收隊列是不是滿了
- if (sk_acceptq_is_full(sk))
- goto exit_overflow;
- ...
- exit_overflow:
- NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
- ...
- }
從上述代碼可以看出,第三次握手時,如果服務器全連接隊列滿了,來自客戶端的 ack 握手包又被直接丟棄了。
想想也很好理解,三次握手完的請求是要放在全連接隊列里的。但是假如全連接隊列滿了,仍然三次握手也不會成功。
不過有意思的是,第三次握手失敗并不是客戶端重試,而是由客戶端來重發 synack。
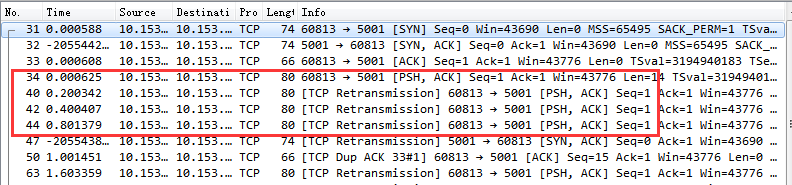
我們搞一個實際的 Case 來直接抓包看一下。我專門寫了個簡單的 Server 只 listen 不 accept,然后找個客戶端把它的連接隊列消耗光。這時候,再用另一個客戶端向它發起請求時的抓包結果。
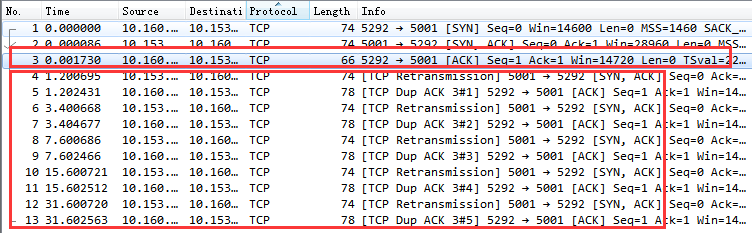
第一個紅框內是第三次握手,其實這個握手請求在服務器端以及被丟棄了。但是這時候客戶端并不知情,它一直傻傻地以為三次握手已經妥了呢。不過還好,這時在服務器的半連接隊列中仍然記錄著第一次握手時存的握手請求。
服務器等到半連接定時器到時后,向客戶端重新發起 synack ,客戶端收到后再重新回復第三次握手 ack。如果這期間服務器端全連接隊列一直都是滿的,那么服務器重試 5 次(受內核參數 net.ipv4.tcp_synack_retries 控制)后就放棄了。
在這種情況下大家還要注意另外一個問題。在實踐中,客戶端往往是以為連接建立成功就會開始發送數據,其實這時候連接還沒有真的建立起來。他發出去的數據,包括重試都將全部被服務器無視。直到連接真正建立成功后才行。
四、總結
衡量工程師是否優秀的標準之一就是看他能否有能力定位和處理線上發生的各種問題。連看似簡單的一個 TCP 三次握手,工程實踐中可能會有各種意外發生。如果對握手理解不深,那么很有可能無法處理線上出現的各種故障。
今天的文章主要是描述了端口不足、半連接隊列滿、全連接隊列滿時的情況,
當端口不充足的時候,會導致 connect 系統調用的時候過多地執行自旋鎖等待與 Hash 查找,會引起 CPU 開銷上漲。嚴重情況下會耗光 CPU,影響用戶業務邏輯的執行。出現這種問題處理起來方法有這么幾個。
通過調整 ip_local_port_range 來盡量加大端口范圍
盡量復用連接,使用長連接來削減頻繁的握手處理
第三個有用,但是不太推薦的是開啟 tcp_tw_reuse 和 tcp_tw_recycle
服務器端在第一次握手時可能會丟包, 在如下兩種情況下會發生。
半連接隊列滿,且 tcp_syncookies 為 0
全連接隊列滿,且有未完成的半連接請求
在這兩種情況下,客戶端視角來看和網絡斷了沒有區別,就是發出去的 SYN 包沒有任何反饋,然后等待定時器到時后重傳握手請求。第一次重傳時間是 1 s ,接下來的等待間隔是翻倍地增長,2 s,4 s,8 s ...。總的重傳次數由 net.ipv4.tcp_syn_retries 內核參數影響(注意我的用詞是影響,而不是決定)。
服務器在第三次握手時也可能會出問題,如果全連接隊列滿,仍將會發生丟包。不過第三次握手失敗時,只有服務器端知道(客戶端誤以為連接已經建立成功了)。服務器根據半連接隊列里的握手信息發起 synack 重試,重試次數由 net.ipv4.tcp_synack_retries 控制。
一旦你的線上出現了上面這些連接隊列溢出導致的問題,你的服務將會受到比較嚴重的影響。即使第一次重試就能夠成功,那你的接口響應耗時將直接上漲到 1 s(老版本上是 3 s)。如果重試上兩三次都沒有成功,Nginx 很有可能直接就報訪問超時失敗了。
正因為握手重試對我們服務影響很大,所以能深刻理解三次握手中的這些異常情況很有必要。再說說如果出現了丟包的問題,我們該如何應對。
方法1,打開 syncookie
在現代的 Linux 版本里,我們可以通過打開 tcp_syncookies 來防止過多的請求打滿半連接隊列包括 SYN Flood 攻擊,來解決服務器因為半連接隊列滿而發生的丟包。
方法2,加大連接隊列長度
在《為什么服務端程序都需要先 listen 一下?》中,我們討論過全連接隊列的長度是 min(backlog, net.core.somaxconn)半連接隊列長度是。半連接隊列長度有點小復雜,是 min(backlog, somaxconn, tcp_max_syn_backlog) + 1 再上取整到 2 的冪次,但最小不能小于16。
如果需要加大全/半連接隊列長度,請調節以上的一個或多個參數來達到目的。只要隊列長度合適,就能很大程序降低握手異常概率的發生。
方法3,盡快地 accept
另外這個雖然一般不會成為問題,但也要注意一下。你的應用程序應該盡快在握手成功之后通過 accept 把新連接取走。不要忙于處理其它業務邏輯而導致全連接隊列塞滿了。
方法4,盡量減少 TCP 連接的次數
如果上述方法都未能根治你的問題,那說明你的服務器上 TCP 連接請求太、太過于頻繁了。這個時候你應該思考下是否可以用長連接代替短連接,減少過于頻繁的三次握手。這個方法不但能解決握手出問題的可能,而且還順帶砍掉了三次握手的各種內存、CPU、時間上的開銷,對提升性能也有較大幫助。




















