













聊聊K8s的 Nginx Ingress 調優

概述
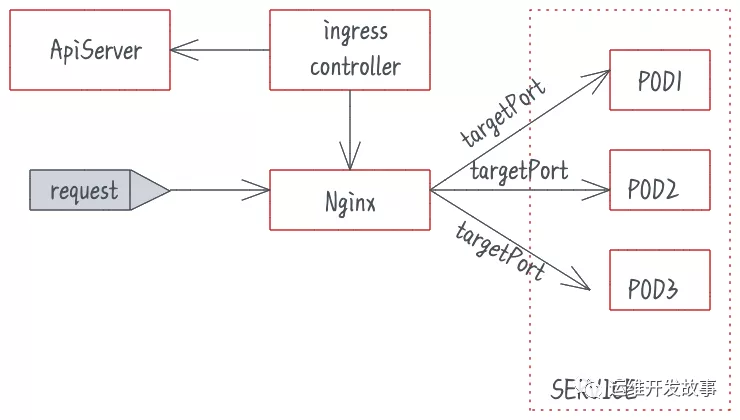
Nginx Ingress Controller 基于 Nginx 實現了 Kubernetes Ingress API,Nginx 是公認的高性能網關,但如果不對其進行一些參數調優,就不能充分發揮出高性能的優勢。Nginx Ingress工作原理:
內核參數調優
我們先看看通過內核的哪些參數能夠提高Ingress的性能。保證在高并發環境下,發揮Ingress的最大性能。
調大全連接隊列的大小
TCP 全連接隊列的最大值取決于 somaxconn 和 backlog 之間的最小值,也就是 min(somaxconn, backlog)。在高并發環境下,如果隊列過小,可能導致隊列溢出,使得連接部分連接無法建立。要調大 Nginx Ingress 的連接隊列,只需要調整 somaxconn 內核參數的值即可,但我想跟你分享下這背后的相關原理。Nginx 監聽 socket 時沒有讀取 somaxconn,而是有自己單獨的參數配置。在 nginx.conf 中 listen 端口的位置,還有個叫 backlog 參數可以設置,它會決定 nginx listen 的端口的連接隊列大小。
- server {
- listen 80 backlog=1024;
- ...
backlog 是 listen(int sockfd, int backlog) 函數中的 backlog 大小,Nginx 默認值是 511,可以通過修改配置文件設置其長度;還有 Go 程序標準庫在 listen 時,默認直接讀取 somaxconn 作為隊列大小。就是說,即便你的 somaxconn 配的很高,nginx 所監聽端口的連接隊列最大卻也只有 511,高并發場景下可能導致連接隊列溢出。所以在這個在 Nginx Ingress 中, Nginx Ingress Controller 會自動讀取 somaxconn 的值作為 backlog 參數寫到生成的 nginx.conf 中: https://github.com/kubernetes/ingress-nginx/blob/controller-v0.34.1/internal/ingress/controller/nginx.go#L592 也就是說,Nginx Ingress 的連接隊列大小只取決于 somaxconn 的大小,這個值在 Nginx Ingress 默認為 4096,建議給 Nginx Ingress 設為 65535:
- sysctl -w net.core.somaxconn=65535
擴大源端口范圍
根據《linux中TCP三次握手與四次揮手介紹及調優》的介紹,我們知道客戶端會占用端口。在高并發場景會導致 Nginx Ingress 使用大量源端口與upstream建立連接。源端口范圍是在內核參數 net.ipv4.ip_local_port_range 中調整的。在高并發環境下,端口范圍過小容易導致源端口耗盡,使得部分連接異常。Nginx Ingress 創建的 Pod 源端口范圍默認是 32768-60999,建議將其擴大,調整為 1024-65535:
- sysctl -w net.ipv4.ip_local_port_range="1024 65535"
TIME_WAIT
根據《linux中TCP三次握手與四次揮手介紹及調優》的介紹,我們知道客戶端會占用端口。當在 netns 中 TIME_WAIT 狀態的連接就比較多的時候,源端口就會被長時間占用。因為而 TIME_WAIT 連接默認要等 2MSL 時長才釋放,當這種狀態連接數量累積到超過一定量之后可能會導致無法新建連接。所以建議給 Nginx Ingress 開啟 TIME_WAIT 復用,即允許將 TIME_WAIT 連接重新用于新的 TCP 連接:
- sysctl -w net.ipv4.tcp_tw_reuse=1
減小FIN_WAIT2狀態的參數 net.ipv4.tcp_fin_timeout 的時間和減小TIME_WAIT 狀態的參數net.netfilter.nf_conntrack_tcp_timeout_time_wait的時間 ,讓系統盡快釋放它們所占用的資源。
- sysctl -w net.ipv4.tcp_fin_timeout=15
- sysctl -w net.netfilter.nf_conntrack_tcp_timeout_time_wait=30
調大增大處于 TIME_WAIT 狀態的連接數
Nginx一定要關注這個值,因為它對你的系統起到一個保護的作用,一旦端口全部被占用,服務就異常了。tcp_max_tw_buckets 能幫你降低這種情況的發生概率,爭取補救時間。在只有 60000 多個端口可用的情況下,配置為:
- sysctl -w net.ipv4.tcp_max_tw_buckets = 55000
調大最大文件句柄數
Nginx 作為反向代理,對于每個請求,它會與 client 和 upstream server 分別建立一個連接,即占據兩個文件句柄,所以理論上來說 Nginx 能同時處理的連接數最多是系統最大文件句柄數限制的一半。系統最大文件句柄數由 fs.file-max 這個內核參數來控制,默認值為 838860,建議調大:
- sysctl -w fs.file-max=1048576
配置示例
給 Nginx Ingress Controller 的 Pod 添加 initContainers 來設置內核參數:
- initContainers:
- - name: setsysctl
- image: busybox
- securityContext:
- privileged: true
- command:
- - sh
- - -c
- - |
- sysctl -w net.core.somaxconn=65535
- sysctl -w net.ipv4.ip_local_port_range="1024 65535"
- sysctl -w net.ipv4.tcp_max_tw_buckets = 55000
- sysctl -w net.ipv4.tcp_tw_reuse=1
- sysctl -w fs.file-max=1048576
- sysctl -w net.ipv4.tcp_fin_timeout=15
- sysctl -w net.netfilter.nf_conntrack_tcp_timeout_time_wait=30
應用層配置調優
除了內核參數需要調優,Nginx 本身的一些配置也需要進行調優,下面我們來詳細看下。
調高 keepalive 連接最大請求數
keepalive_requests指令用于設置一個keep-alive連接上可以服務的請求的最大數量,當最大請求數量達到時,連接被關閉。默認是100。這個參數的真實含義,是指一個keep alive建立之后,nginx就會為這個連接設置一個計數器,記錄這個keep alive的長連接上已經接收并處理的客戶端請求的數量。如果達到這個參數設置的最大值時,則nginx會強行關閉這個長連接,逼迫客戶端不得不重新建立新的長連接。
簡單解釋一下:QPS=10000時,客戶端每秒發送10000個請求(通常建立有多個長連接),每個連接只能最多跑100次請求,意味著平均每秒鐘就會有100個長連接因此被nginx關閉。同樣意味著為了保持QPS,客戶端不得不每秒重新新建100個連接。因此,就會發現有大量的TIME_WAIT的socket連接(即使此時keep alive已經在client和nginx之間生效)。因此對于QPS較高的場景,非常有必要加大這個參數,以避免出現大量連接被生成再拋棄的情況,減少TIME_WAIT。
如果是內網 Ingress,單個 client 的 QPS 可能較大,比如達到 10000 QPS,Nginx 就可能頻繁斷開跟 client 建立的 keepalive 連接,然后就會產生大量 TIME_WAIT 狀態連接。我們應該盡量避免產生大量 TIME_WAIT 連接,所以,建議這種高并發場景應該增大 Nginx 與 client 的 keepalive 連接的最大請求數量,在 Nginx Ingress 的配置對應 keep-alive-requests,可以設置為 10000,參考: https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/configmap/#keep-alive-requests 同樣的,Nginx 與 upstream 的 keepalive 連接的請求數量的配置是 upstream-keepalive-requests,參考: https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/configmap/#upstream-keepalive-requests
但是,一般情況應該不必配此參數,如果將其調高,可能導致負載不均,因為 Nginx 與 upstream 保持的 keepalive 連接過久,導致連接發生調度的次數就少了,連接就過于 "固化",使得流量的負載不均衡。
調高 keepalive 最大空閑連接數
Nginx 針對 upstream 有個叫 keepalive 的配置,它不是 keepalive 超時時間,也不是 keepalive 最大連接數,而是 keepalive 最大空閑連接數。當這個數量被突破時,最近使用最少的連接將被關閉。
簡單解釋一下:有一個HTTP服務,作為upstream服務器接收請求,響應時間為100毫秒。如果要達到10000 QPS的性能,就需要在nginx和upstream服務器之間建立大約1000條HTTP連接。nginx為此建立連接池,然后請求過來時為每個請求分配一個連接,請求結束時回收連接放入連接池中,連接的狀態也就更改為idle。我們再假設這個upstream服務器的keepalive參數設置比較小,比如常見的10. A、假設請求和響應是均勻而平穩的,那么這1000條連接應該都是一放回連接池就立即被后續請求申請使用,線程池中的idle線程會非常的少,趨近于零,不會造成連接數量反復震蕩。B、顯示中請求和響應不可能平穩,我們以10毫秒為一個單位,來看連接的情況(注意場景是1000個線程+100毫秒響應時間,每秒有10000個請求完成),我們假設應答始終都是平穩的,只是請求不平穩,第一個10毫秒只有50,第二個10毫秒有150:
- 下一個10毫秒,有100個連接結束請求回收連接到連接池,但是假設此時請求不均勻10毫秒內沒有預計的100個請求進來,而是只有50個請求。注意此時連接池回收了100個連接又分配出去50個連接,因此連接池內有50個空閑連接。
- 然后注意看keepalive=10的設置,這意味著連接池中最多容許保留有10個空閑連接。因此nginx不得不將這50個空閑連接中的40個關閉,只留下10個。
- 再下一個10個毫秒,有150個請求進來,有100個請求結束任務釋放連接。150 - 100 = 50,空缺了50個連接,減掉前面連接池保留的10個空閑連接,nginx不得不新建40個新連接來滿足要求。
C、同樣,如果假設相應不均衡也會出現上面的連接數波動情況。
它的默認值為 32,在高并發下場景下會產生大量請求和連接,而現實世界中請求并不是完全均勻的,有些建立的連接可能會短暫空閑,而空閑連接數多了之后關閉空閑連接,就可能導致 Nginx 與 upstream 頻繁斷連和建連,引發 TIME_WAIT 飆升。在高并發場景下可以調到 1000,參考: https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/configmap/#upstream-keepalive-connections
網關超時
ingress nginx 與 upstream pod 建立 TCP 連接并進行通信,其中涉及 3 個超時配置,我們也相應進行調優。proxy-connect-timeout 選項 設置 nginx 與 upstream pod 連接建立的超時時間,ingress nginx 默認設置為 5s,由于在nginx 和業務均在內網同機房通信,我們將此超時時間縮短一些,比如3秒。參考:https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/configmap/#proxy-connect-timeout
proxy-read-timeout 選項設置 nginx 與 upstream pod 之間讀操作的超時時間,ingress nginx 默認設置為 60s,當業務方服務異常導致響應耗時飆漲時,異常請求會長時間夯住 ingress 網關,我們在拉取所有服務正常請求的 P99.99 耗時之后,將網關與 upstream pod 之間讀寫超時均縮短到 3s,使得 nginx 可以及時掐斷異常請求,避免長時間被夯住。參考:https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/configmap/#proxy-read-timeout
https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/configmap/#proxy-send-timeout
調高單個 worker 最大連接數
max-worker-connections 控制每個 worker 進程可以打開的最大連接數,默認配置是 16384。在高并發環境建議調高,比如設置到 65536,這樣可以讓 nginx 擁有處理更多連接的能力,參考: https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/configmap/#max-worker-connections
優化重試機制
nginx 提供了默認的 upstream 請求重試機制,默認情況下,當 upstream 服務返回 error 或者超時,nginx 會自動重試異常請求,并且沒有重試次數限制。由于接入層 nginx 和 ingress nginx 本質都是 nginx,兩層 nginx 都啟用了默認的重試機制,異常請求時會出現大量重試,最差情況下會導致集群網關雪崩。接入層 nginx 一起解決了這個問題:接入層 nginx 必須使用 proxy_next_upstream_tries 嚴格限制重試次數,ingress nginx 則使用 proxy-next-upstream="off"直接關閉默認的重試機制。參考:https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/configmap/#proxy-next-upstream
開啟 brotli 壓縮
參考: https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/configmap/#enable-brotli
壓縮是時間換空間的通用方法。用cpu時間來換取大量的網絡帶寬,增大吞吐量。Brotli是Google開發的一種壓縮方法,于2015年發布。我們常用的壓縮算法是 gzip(Ingress-nginx也是默認使用gzip),據說brotli要比gzip高出20%至30%的壓縮率。默認的壓縮算法是gzip,壓縮級別為1,如需要啟用brotli,需要配置以下三個參數:
- enable-brotli: true 或 false,是否啟用brotli壓縮算法
- brotli-level: 壓縮級別,范圍1~11,默認為4,級別越高,越消耗CPU性能。
- brotli-types: 由brotli即時壓縮的MIME類型
配置示例
Nginx 全局配置通過 configmap 配置(Nginx Ingress Controller 會 watch 并自動 reload 配置):
- apiVersion: v1
- kind: ConfigMap
- metadata:
- name: nginx-ingress-controller
- data:
- keep-alive-requests: "10000"
- upstream-keepalive-connections: "200"
- max-worker-connections: "65536"
- proxy-connect-timeout: "3"
- proxy-read-timeout: "3"
- proxy-send-timeout: "3"
- proxy-next-upstream: "off"
- enable-brotli: "true"
- brotli-level: "6"
- brotli-types: "text/xml image/svg+xml application/x-font-ttf image/vnd.microsoft.icon application/x-font-opentype application/json font/eot application/vnd.ms-fontobject application/javascript font/otf application/xml application/xhtml+xml text/javascript application/x-javascript text/plain application/x-font-truetype application/xml+rss image/x-icon font/opentype text/css image/x-win-bitmap"
參考資料
優化nginx-ingress-controller并發性能:
https://cloud.tencent.com/developer/article/1537695
Nginx Ingress 配置參考:
https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/configmap/
Tuning NGINX for Performance:
https://www.nginx.com/blog/tuning-nginx/
ngx_http_upstream_module 官方文檔:
http://nginx.org/en/docs/http/ngx_http_upstream_module.html
本文轉載自微信公眾號「運維開發故事」,可以通過以下二維碼關注。轉載本文請聯系運維開發故事公眾號。



























