













Linux 編輯器之神 vim 的 IO 存儲原理
故事起因
無意間用 vim 打開了一個 10 G 的文件,改了一行內容,:w 保存了一下,慢的我喲,耗費的時間夠泡幾杯茶了。這引起了我的好奇,vim 打開和保存究竟做了啥?
vim — 編輯器之神
vim 號稱編輯器之神,以極其強大的擴展性和功能聞名。vi/vim 作為標準的編輯器存在于 Linux 的幾乎每一種發行版里。vim 的學習曲線比較陡峭的,前期必須有一個磨煉的過程。
vim 是一個終端編輯器,在可視化的編輯器橫行的今天,為什么 vim 還如此重要?
因為有些場景非它不可,比如線上服務器終端,除 vi/vim 這種終端編輯器,你別無選擇。
vim 的歷史很悠久,Github 有個文檔歸納了 vim 的歷史進程:vim 歷史,Github 開源代碼:代碼倉庫。
筆者今天不講 vim 的用法,這種文章網上隨便搜一大把。筆者將從 vim 的存儲 IO 原理的角度來剖析下 vim 這個神器。
思考幾個小問題,讀者如果感興趣,可以繼續往下讀哦:
- vim 編輯文件的原理是啥,用了啥黑科技嗎?
- vim 打開一個 10G 的大型文件,為什么這么慢,里面做了啥?
- vim 修改一個 10G 的大型文件,:w 保存的時候,感覺更慢了?為什么?
- vim 好像會產生多余的文件?~ 文件 ?.swp 文件 ?都是做啥的呢?
劃重點:由于 vim 的功能過于強大,一篇分享根本說不完,本篇文章聚焦 IO,從存儲的角度剖析 vim 原理。
vim 的 io 原理
聲明,系統和 Vim 版本如下:
操作系統版本:Ubuntu 16.04.6 LTSVIM 版本:VIM - Vi IMproved 8.2 (2019 Dec 12, compiled Jul 25 2021 08:44:54)測試文件名:test.txt
vim 就是一個二進制程序而已。讀者朋友也可以 Github 下載,編譯,自己調試哦,效果更佳。
一般使用 vim 編輯文件很簡單,只需要 vim 后面跟文件名即可:
- vim test.txt
這樣就打開了文件,并且可以進行編輯。這個命令敲下去,一般情況下,我們就能很快在終端很看到文件的內容了。
這個過程發生了什么?先明確下,vim test.txt 到底是啥意思?
本質就是運行一個叫做 vim 的程序,argv[1] 參數是 test.txt 嘛。跟你以前寫的 helloworld 程序沒啥不一樣,只不過 vim 這個程序可以終端人機交互。
所以這個過程無非就是一個進程初始化的過程,由 main 開始,到 main_loop(后臺循環監聽)。
1 vim 進程初始化
vim 有一個 main.c 的入口文件,main 函數就定義在這里。首先會做一下操作系統相關的初始化( mch 是 machine 的縮寫):
- mch_early_init();
然后會,做一下賦值參數,全局變量的初始化:
- /*
- * Various initialisations shared with tests.
- */
- common_init(¶ms);
舉個例子 test.txt 這樣的參數必定要賦值到全局變量中,因為以后是要經常使用的。
另外類似于命令的 map 表,是靜態定義好了的:
- static struct cmdname
- {
- char_u *cmd_name; // name of the command
- ex_func_T cmd_func; // function for this command
- long_u cmd_argt; // flags declared above
- cmd_addr_T cmd_addr_type; // flag for address type
- } cmdnames [] = {
- EXCMD(CMD_write, "write", ex_write,
- EX_RANGE|EX_WHOLEFOLD|EX_BANG|EX_FILE1|EX_ARGOPT|EX_DFLALL|EX_TRLBAR|EX_CMDWIN|EX_LOCK_OK,
- ADDR_LINES),
- }
劃重點::w,:write,:saveas 這樣的 vim 命令,其實是對應到定義好的 c 回調函數:ex_write 。 ex_write 函數是數據寫入的核心函數。再比如,:quit 對應 ex_quit ,用于退出的回調。
換句話說,vim 里面支持的類似 :w ,的命令,其實在初始化的時候就確定了。人為的交互只是輸入字符串,vim 進程從終端讀到字符串之后,找到對應的回調函數,執行即可。再來,會初始化一些 home 目錄,當前目錄等變量。
- init_homedir(); // find real value of $HOME
- // 保存交互參數
- set_argv_var(paramp->argv, paramp->argc);
配置一下跟終端窗口顯示相關的東西,這部分主要是一些終端庫相關的:
- // 初始化終端一些配置
- termcapinit(params.term); // set terminal name and get terminal
- // 初始化光標位置
- screen_start(); // don't know where cursor is now
- // 獲取終端的一些信息
- ui_get_shellsize(); // inits Rows and Columns
再來會加載 .vimrc 這樣的配置文件,讓你的 vim 與眾不同。
- // Source startup scripts.
- source_startup_scripts(¶ms);
還會加載一些 vim 插件 source_in_path ,使用 load_start_packages 加載 package 。
下面這個就是第一個交互了,等待用戶敲下 enter 鍵:
- wait_return(TRUE);
我們經常看見的:“Press ENTER or type command to continue“ 就是在這里執行的。確認完,就說明你真的是要打開文件,并顯示到終端了。
怎么打開文件?怎么顯示字符到終端屏幕?
這一切都來自于 create_windows 這個函數。名字也很好理解,就是初始化的時候創建終端窗口來著。
- /*
- * Create the requested number of windows and edit buffers in them.
- * Also does recovery if "recoverymode" set.
- */
- create_windows(¶ms);
這里其實涉及到兩個方面:
- 把數據讀出來,讀到內存;
- 把字符渲染到終端;
怎么把數據從磁盤上讀出來,就是 IO。怎么渲染到終端這個我們不管,這個使用的是 termlib 或者 ncurses 等終端編程庫來實現的,感興趣的可以了解下。
這個函數會調用到我們的第一個核心函數:open_buffer ,這個函數做兩個時間:
- create memfile:創建一個 memory + .swp 文件的抽象層,讀寫數據都會過這一層;
- read file:讀原始文件,并解碼(用于顯示到屏幕);
函數調用棧:
- -> readfile
- -> open_buffer
- -> create_windows
- -> vim_main2
- -> main
真正干活的是 readfile 這個函數,吐槽一下,readfile 是一個 2533 行的函數。。。。。。
readfile 里面會擇機創建 swp 文件(以前有的話,可以用于恢復數據),調用的是 ml_open_file 這個函數,文件創建好之后,size 占用 4k,里面主要是一些特定的元數據(用來恢復數據用的)。
劃重點:.{文件名}.swp 這個隱藏文件是有格式的,前 4k 為 header,后面的內容也是按照一個個block 組織的。
再往后走,會調用到 read_eintr 這個函數,讀取數據的內容:
- vlong
- read_eintr(int fd, void *buf, size_t bufsize)
- {
- long ret;
- for (;;) {
- ret = vim_read(fd, buf, bufsize);
- if (ret >= 0 || errno != EINTR)
- break;
- }
- return ret;
- }
這是一個最底層的函數,是系統調用 read 的一個封裝,讀出來之后。這里回答了一個關鍵問題:vim 的存儲原理是啥?
劃重點:本質上調用 read,write,lseek 這樣樸素的系統調用,而已。
readfile 會把二進制的數據讀出來,然后進行字符轉變編碼(按照配置的模式),編碼不對就是亂碼嘍。每次都是按照一個固定 buffer 讀數據的,比如 8192 。
劃重點:readfile 會讀完文件。這就是為什么當 vim 打開一個超大文件的時候,會非常慢的原因。
這里提一點題外話:memline 這個封裝是文件之上的,vim 修改文件是修改到內存 buffer ,vim 按照策略來 sync memfile 到 swp 文件,一個是防止丟失未保存的數據,第二是為了節省內存。
mf_write 把內存數據寫到文件。在 .test.txt.swp 中的就是這樣的數據結構:
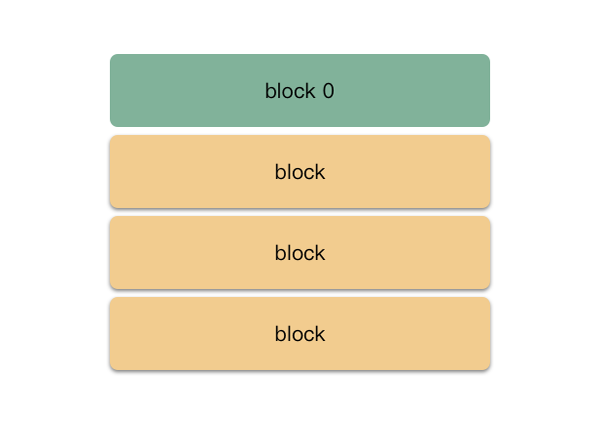
block 0 的 header 主要標識:
- vim 的版本;
- 編輯文件的路徑;
- 字符編碼方式;
這里實現提一個重要知識點:swp 文件里存儲的是 block,block 的管理是以一個樹形結構進行管理的。block 有 3 種類型:
- block0:頭部 4k ,主要是存儲一些文件的元數據,比如路徑,編碼模式,時間戳等等;
- pointer block:樹形內部節點;
- data block:樹形葉子節點,存儲用戶數據;
2 敲下 :w 背后的原理
進程初始化我們講完了,現在來看下 :w 觸發的調用吧。用戶敲下 :w 命令觸發 ex_write 回調(初始化的時候配置好的)。所有的流程皆在 ex_write ,我們來看下這個函數做了什么。
先撇開代碼實現來說,用戶敲下 :w 命令其實只是想保存修改而已。
那么第一個問題?用戶的修改在哪里?
在 memline 的封裝,只要沒執行過 :w 保存,那么用戶的修改就沒修改到原文件上(注意哦,沒保存之前,一定沒修改原文件哦),這時候,用戶的修改可能在內存,也可能在 swp 文件。存儲的數據結構為 block 。所以,:w 其實就是把 memline 里面的數據刷到用戶文件而已。怎么刷?
重點步驟如下(以 test.txt 舉例):
- 創建一個 backup 文件( test.txt~ ),把原文件拷貝出來;
- 把原文件 test.txt truancate 截斷為 0,相當于清空原文件數據;
- 從 memline (內存 + .test.txt.swp)拷貝數據,重新寫入原文件 test.txt;
- 刪除備份文件 test.txt~;
以上就是 :w 做的所有事情了,下面我們看下代碼。
觸發的回調是 ex_write ,核心的函數是 buf_write ,這個函數 1987 行。
在這函數,會使用 mch_open 創建一個 backup 文件,名字后面帶個 ~ ,比如 test.txt~ ,
- bfd = mch_open((char *)backup
拿到 backup 文件的句柄,然后拷貝數據(就是一個循環嘍), 每 8K 操作一次,從 test.txt 拷貝到 test.txt~ ,以做備份。
劃重點:如果是 test.txt 是超大文件,那這里就慢了哦。
backup 循環如下:
- // buf_write
- while ((write_info.bw_len = read_eintr(fd, copybuf, WRITEBUFSIZE)) > 0)
- {
- if (buf_write_bytes(&write_info) == FAIL)
- // 如果失敗,則終止
- // 否則直到文件結束
- }
- }
我們看到,干活的是 buf_write_bytes ,這是 write_eintr 的封裝函數,其實也就是系統調用 write 的函數,負責寫入一個 buffer 的數據到磁盤文件。
- long write_eintr(int fd, void *buf, size_t bufsize) {
- long ret = 0;
- long wlen;
- while (ret < (long)bufsize) {
- // 封裝的系統調用 write
- wlen = vim_write(fd, (char *)buf + ret, bufsize - ret);
- if (wlen < 0) {
- if (errno != EINTR)
- break;
- } else
- ret += wlen;
- }
- return ret;
- }
backup 文件拷貝完成之后,就可以準備動原文件了。
思考:為什么要先文件備份呢?
留條后路呀,搞錯了還有的恢復,這個才是真正的備份文件。
修改原文件之前的第一步,ftruncate 原文件到 0,然后,從 memline (內存 + swp)中拷貝數據,寫回原文件。
劃重點:這里又是一次文件拷貝,超大文件的時候,這里可能巨慢哦。
- for (lnum = start; lnum <= end; ++lnum)
- {
- // 從 memline 中獲取數據,返回一個內存 buffer( memline 其實就是內存和 swap 文件的一個封裝)
- ptr = ml_get_buf(buf, lnum, FALSE) - 1;
- // 將這個內存 buffer 寫到原文件
- if (buf_write_bytes(&write_info) == FAIL)
- {
- end = 0; // write error: break loop
- break;
- }
- // ...
- }
劃重點:vim 并不是調用 pwrite/pread 這樣的調用來修改原文件,而是把整個文件清空之后,copy 的方式來更新文件。漲知識了。
這樣就完成了文件的更新啦,最后只需要刪掉 backup 文件即可。
- // Remove the backup unless 'backup' option is set or there was a
- // conversion error.
- mch_remove(backup);
這個就是我們數據寫入的完整流程啦。是不是沒有你想的那么簡單!
簡單小結下:當修改了 test.txt 文件,調用 :w 寫入保存數據的時候發生了什么?
- 人機交互,:w 觸發調用 ex_write 回調函數,于 do_write -> buf_write 完成寫入 ;
- 具體操作是:先備份一個 test.txt~ 文件出來(全拷貝);
- 接著,原文件 test.txt 截斷為 0,從 memline( 即 內存最新數據 + .test.txt.swap 的封裝)拷貝數據,寫入 test.txt (全拷貝) ;
數據組織結構
之前講的太細節,我們從數據組織的角度來解釋下。vim 針對用戶對文件的修改,在原文件之上,封裝了兩層抽象:memline,memfile 。分別對應文件 memline.c ,memfile.c 。
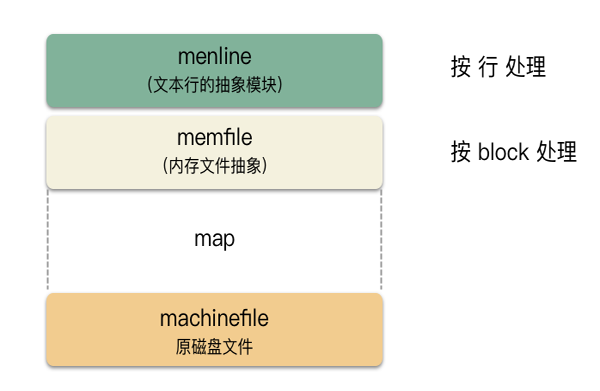
先說 memline 是啥?
對應到文本文件中的每一行,memline 是基于 memfile 的。
memline 基于 memfile,那 memfile 又是啥?
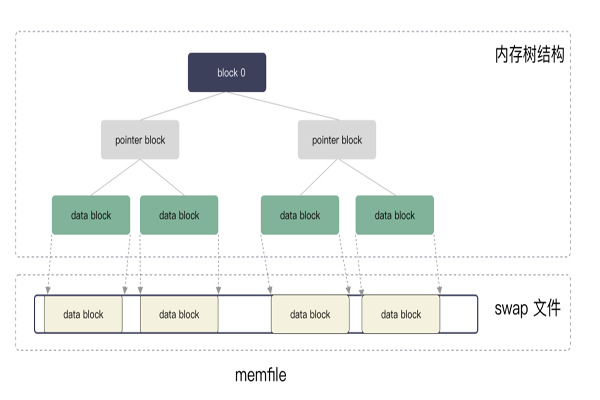
這個是一個虛擬內存空間的實現,vim 把整個文本文件映射到內存中,通過自己管理的方式。這里的單位為 block,memfile 用二叉樹的方式管理 block 。block 不定長,block 由 page 組成,page 為定長 4k 大小。
這是一個典型虛擬內存的實現方案,編輯器的修改都體現為對 memfile 的修改,修改都是修改到 block 之上,這是一個線性空間,每個 block 對應到文件的要給位置,有 block number 編號,vim 通過策略會把 block 從內存中換出,寫入到 swp 文件,從而節省內存。這就是 swap 文件的名字由來。
block 區分 3 種類型:
- block 0 塊:樹的根,文件元數據;
- pointer block:樹的分支,指向下一個 block;
- data block:樹的葉子節點,存儲用戶數據;
swap 文件組織:
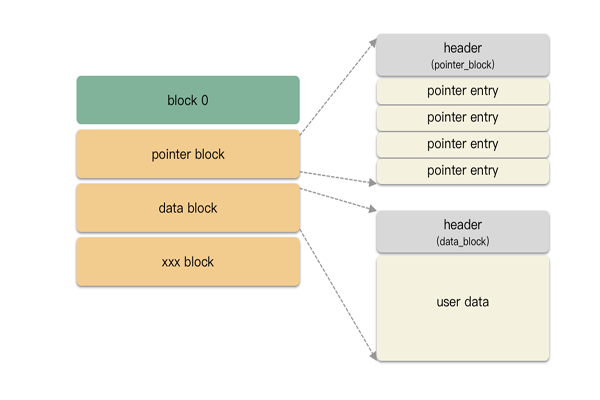
block 0 是特殊塊,結構體占用 1024 個字節內存,寫到文件是按照 1 個page 對齊的,所以是 4096 個字節。如下圖:
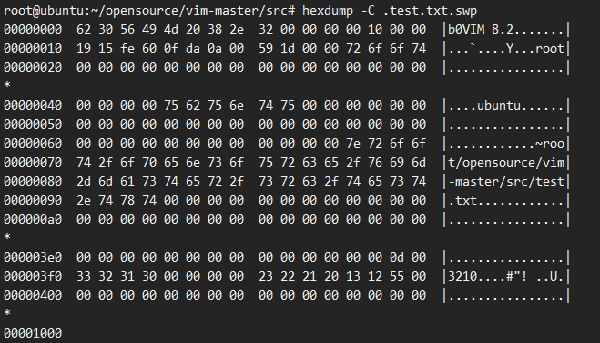
block 其他兩種類型:
- pointer 類型:這個是中間的分支節點,指向 block 的;
- data 類型:這個是葉子節點;
- #define DATA_ID (('d' << 8) + 'a') // data block id
- #define PTR_ID (('p' << 8) + 't') // pointer block id
這個 ID 相當于魔數,在 swp 文件中很容易識別出來,比如在下面的文件中第一個 4k 存儲的是 block0,第二個 4k 存儲的是 pointer 類型的 block。

第三,第四個 4k 存儲的是一個 data 類型的 block ,里面存儲了原文件數據。
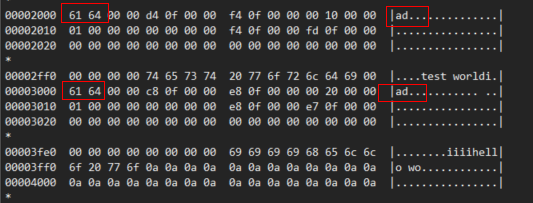
當用戶修改一行的時候,對應到 memline 的一個 line 的修改,對應到這行 line 在哪個 block 的修改,從而定期的刷到 swap 文件。
vim 特殊的文件 ~ 和 .swp ?
假設原文件名稱:test.txt 。
1 test.txt~ 文件
test.txt~ 文件估計很多人都沒見過,因為消失的太快了。這個文件在修改原文件之前生成,修改原文件之后刪除。作用于只存在于 buf_write ,是為了安全備份的。
劃重點:test.txt~ 和 test.txt 本質是一樣的,沒有其他特定格式,是用戶數據。
讀者朋友試試 vim 一個 10 G的文件,然后改一行內容,:w 保存,應該很容易發現這個文件(因為備份和回寫時間巨長 )。
2 .test.txt.swp 文件
這個文件估計絕大多數人都見過,.swp 文件生命周期存在于整個進程的生命周期,句柄是一直打開的。很多人認為 .test.txt.swp 是備份文件,其實準確來講并不是備份文件,這是為了實現虛擬內存空間的交換文件,test.txt~ 才是真正的備份文件。swp 是 memfile 的一部分,前面 4k 為 header 元數據,后面的為 一個個 4k 的數據行封裝。和用戶數據并不完全對應。
memfile = 內存 + swp 才是最新的數據。
思考解答
1 vim 存儲原理是啥?
沒啥,就是用的 read,write 這樣的系統調用來讀寫數據而已。
2 vim 的過程有兩種冗余的文件?
test.txt~ :是真正的備份文件,誕生于修改原文件之前,消失于修改成功之后;.test.txt.swp :swap 文件,由 block 組成,里面可能由用戶未保存的修改,等待:w 這種調用,就會覆蓋到原文件;
3 vim 編輯超大文件的時候為什么慢?
一般情況下,你能直觀感受到,慢在兩個地方:
- vim 打開的時候;
- 修改了一行內容,:w 保存的時候;
先說第一個場景:vim 一個 10G 的文件,你的直觀感受是啥?
我的直觀感受是:命令敲下之后,可以去泡杯茶,等茶涼了一點,差不多就能看到界面了。為什么?
在進程初始化的時候,初始化窗口之前,create_windows -> open_buffer 里面調用 readfile 會把整個文件讀一遍(完整的讀一遍),在屏幕上展示編碼過的字符。
劃重點:初始化的時候,readfile 會把整個文件讀一遍。 10 G的文件,你可想而知有多慢。我們可以算一下,按照單盤硬件 100 M/s 的帶寬來算,也要 102 秒的時間。
再說第二個場景:喝了口茶,改了一個單詞,:w 保存一下,媽呀,命令敲下之后,又可以去泡杯茶了?為什么?
- 先拷貝出一個 10G 的 test.txt~ 備份文件,102 秒就過去了;
- test.txt 截斷為 0,再把 memfile( .test.txt.swp )拷貝回 test.txt ,數據量 10 G,102 秒過去了(第一次可能更慢哦);
4 vim 編輯大文件的時候,會有空間膨脹?
是的,vim 一個 test.txt 10 G 的文件,會存在某個時刻,需要 >=30 G 的磁盤空間。
- 原文件 test.txt 10 G
- 備份文件 test.txt~ 10G
- swap 文件 .test.txt.swp >10G
總結
- vim 編輯文件并不沒有用黑魔法,還是用的 read,write,樸實無華;
- vim 編輯超大文件,打開很慢,因為會讀一遍文件( readfile ),保存的時候很慢,因為會讀寫兩遍文件(backup 一次,memfile 覆蓋寫原文件一次);
- memfile 是 vim 抽象的一層虛擬存儲空間(物理上由內存 block 和 swp 文件組成)對應一個文件的最新修改,存儲單元由 block 構成。:w 保存的時候,就是從 memfile 讀,寫到原文件的過程;
- memline 是基于 memfile 做的另一層封裝,把用戶的文件抽象成“行”的概念;
- .test.txt.swp 文件是一直 open 的,memfile 會定期的交換數據進去,以便容災恢復;
- test.txt~ 文件才是真正的備份文件,誕生于 :w 覆蓋原文件之前,消失于成功覆寫原文件之后;
- vim 基本都是整個文件的處理,并不是局部處理,大文件的編輯根本不適合 vim ,話說回來,正經人誰會用 vim 編輯 10 G 的文件?vim 就是個文本編輯器呀;
- 一個 readfile 函數 2533 行,一個 buf_write 函數 1987 行代碼。。。不是我打擊各位的積極性,這。。。反正我不想再看見它了。。。
后記
對于 vim 的好奇讓筆者擼了一遍源碼,學習了下其中的 IO 知識,不想被動輒幾千行一個的函數教育了一番。我再也不想擼它了。。你學 fei 了嗎?






















