













KubeDL 加入 CNCF Sandbox,加速 AI 產業云原生化
2021 年 6 月 23 日,云原生計算基金會(CNCF)宣布通過全球 TOC 投票接納 KubeDL 成為 CNCF Sandbox 項目。KubeDL 是阿里開源的基于 Kubernetes 的 AI 工作負載管理框架,取自"Kubernetes-Deep-Learning"的縮寫,希望能夠依托阿里巴巴的場景,將大規模機器學習作業調度與管理的經驗反哺社區。
項目地址:http://kubedl.io
項目介紹
隨著 TensorFlow, PyTorch,XGBoost 等主流 AI 框架的不斷成熟,和以 GPU/TPU 為代表的多種AI異構計算芯片的井噴式涌現,人工智能正快速進入“大規模工業化”落地的階段。從算法工程師著手設計第一層神經網絡結構,到最終上線服務于真實的應用場景,除 AI 算法的研發外還需要大量基礎架構層面的系統支持,包括數據收集和清理、分布式訓練引擎、資源調度與編排、模型管理,推理服務調優,可觀測等。如以下經典圖例所展示,眾多系統組件的協同組成了完整的機器學習流水線。
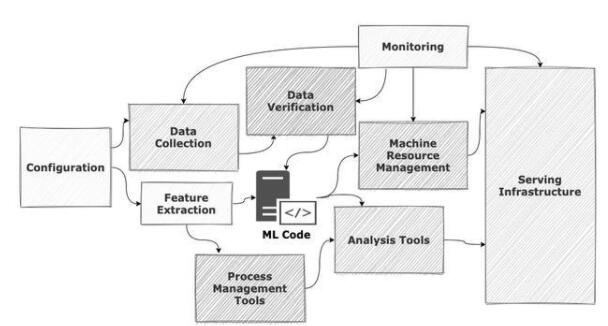
與此同時,以 Kubernetes 為代表的云原生技術蓬勃發展,通過優秀的抽象和強大的可擴展性,將應用層與 IaaS(Infrastructure as a Service)層的基礎設施完美解耦:應用能夠以“云”的范式按需使用資源,無需關注底層基礎設施的復雜性,從而解放生產力并專注于自身領域的創新。
Kubernetes 的出現解決了云資源如何高效交付的問題,但對于 AI 這類本身具備高度復雜性的工作負載還無法做到很好地原生支持,如何整合各類框架的差異并保留其通用性,同時圍繞 AI 工作負載的運行時去建設一系列完善的周邊生態及工具,業界還在不斷探索與嘗試。在實踐中,我們發現了 AI 負載運行在 Kubernetes 生態中面臨著如下挑戰:
機器學習框架百花齊放,各自有不同的優化方向和適用場景,但在分布式訓練作業的生命周期管理上又存在著諸多共性,同時針對一些高級特性也有相同的訴求(如網絡模式,鏡像代碼分離,元數據持久化,緩存加速等)。為每類框架的負載單獨實現 operater,各自獨立進程無法共享 state,缺乏全局視角,使得全局 Job 層面的調度以及隊列機制難以實現。此外,不利于功能的抽象和復用,在代碼層面存在重復勞動。
原生 Kubernetes 無法滿足離線任務多樣的調度需求。Kubernetes 面向 Pod 調度的模型天然適用于微服務等 Long Running 的工作負載,但針對離線任務的高吞吐,Gang Scheduling 調度(All-Or-Nothing),Elastic Capacity 等多種調度訴求,社區演進出了多種調度方案。以機器學習分布式訓練作業調度場景中極為常見的Gang Scheduling為例,社區目前就有YuniKorn,Volcano,Coscheduling 等調度器實現,提供不同的交互協議,我們需要有插件化的手段來啟用對應的調度協議。同時,像 PS/worker 這類根據業務特有屬性,不同 role 之間有啟動依賴的 DAG 編排訴求,需要在控制器中實現;
分布式訓練的結果往往以模型作為 output,并存儲在分布式文件系統中如(阿里云 OSS/NAS),但如何從訓練作業的視角去管理模型,像容器鏡像那樣成為AI服務的“不可變基礎設施”并實現簡單且清晰的版本管理與追溯,業界還缺乏最佳實踐。同時,“訓練”與“推理”兩個階段相對獨立,算法科學家視角中的“訓練->模型->推理”機器學習流水線缺乏斷層,而“模型”作為兩者的中間產物正好能夠充當那個“承前啟后”的角色;
分布式訓練尚能大力出奇跡,但推理服務的規格配置卻是一個精細活。顯存量、 CPU 核數、BatchSize、線程數等變量都可能影響推理服務的質量。純粹基于資源水位的容量預估無法反映業務的真實資源需求,因為某些引擎如 TensorFlow 會對顯存進行預占。理論上存在一個服務質量與資源效能的最優平衡點,但它就像黑暗中的幽靈,明知道它的存在卻難以琢磨。隨著 GPU 虛擬化技術的成熟,這個平衡點的價值越來越凸顯,更優的規格能顯著提供單 GPU 卡的部署密度,節約大量的成本。
推理服務本身是一種特殊的 long running 微服務形態,除了基礎的 deployment 外,針對不同的推理場景還欠缺一些實例與流量的管理策略,如:
1) 算法科學家通常會同時部署兩個甚至多個不同版本的模型實例進行 A/B Test 以驗證最佳的服務效果,需要基于權重的精細化流量控制;
2) 能夠根據流量請求水平和當前推理服務的 metrics 來自動觸發實例的擴縮,在充分保障服務可用性的前提下最小化資源成本等等。
KubeDL
針對上述難題,阿里巴巴云原生,集群管理和 PAI 團隊將管理大規模機器學習工作負載的經驗沉淀為通用的運行時管理框架——KubeDL,涵蓋分布式訓練,模型管理,推理服務等機器學習流水線的各階段,使工作負載能夠高效地運行在 Kubernetes 之上。
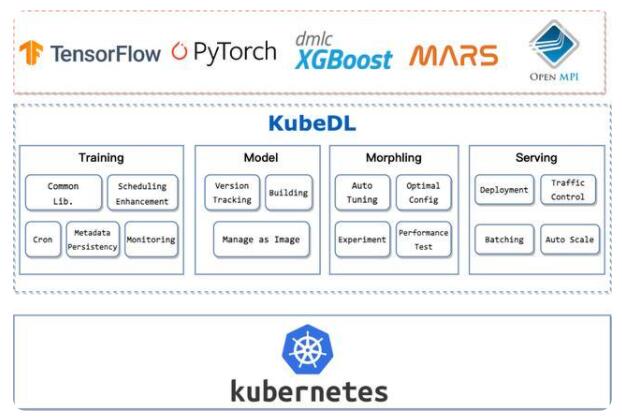
1、分布式訓練
KubeDL 支持了主流的機器學習分布式訓練框架(TensorFlow / PyTorch / MPI / XGBoost / Mars 等),其中 Mars 是阿里巴巴計算平臺開源的基于張量的大規模數據計算框架,能夠分布式地加速 numpy,pandas 等數據處理框架的效率,幫助 Mars 作業以更 native 的方式集成進云原生大數據生態中。
我們將各類訓練作業生命周期管理中的共同部分進行抽象,成為一層通用的運行時庫,被各分布式訓練作業控制器復用,同時用戶也可以在此基礎上快速擴展出自定義的 workload 控制器并復用現有的能力。借助聲明式 API 與 Kubernetes 網絡/存儲模型,KubeDL 能夠進行計算資源的申請/回收,各 Job Role 之間的服務發現與通信,運行時的 Fail-over 等,算法模型的開發者只需聲明好此次訓練依賴的 Job Role 及各自的副本數,計算資源/異構資源數量等,然后提交任務。另外,我們針對訓練領域的痛點也做了諸多的特性設計來提升訓練的效率與體驗:
不同的訓練框架往往包含不同的 Job Role,如 TensorFlow 中的 PS/Chief/Worker 和 PyTorch 中的 Master/Worker,Role 與 Role 之間往往隱含著依賴關系,如 Worker 依賴 Master 啟動之后才能正常開始計算,錯亂的啟動順序不僅容易造成資源長時間空轉,甚至可能引發 Job 直接失敗。KubeDL 設計了基于 DAG(Direct Acyclic Graph)的調度編排控制流,很好地解決了 Role 之間的啟動依賴順序,并能夠靈活擴展。
大模型的訓練時長往往受制于計算節點間的通信效率,RDMA 等高性能網絡技術的應用將極大地提升了數據的傳輸速度,但這些定制網絡往往需要計算節點使用 Hostnetwork 進行互相通信,同時有些時候由于環境限制無法提供基于 Service 模式的服務發現機制。這就需要作業管理引擎能夠支持 Host 網絡模式下的服務發現機制,處理好各計算節點的網絡端口分配,并與各訓練框架的特性結合來處理節點 Fail-over 后的網絡連通性,KubeDL 支持了 Host 網絡模式下的高性能分布式訓練。
Gang Scheduling 是分布式訓練作業調度場景中的常見需求,組成單個訓練作業的一簇 Pod 往往要求同時被調度,避免在集群容量緊張時因作業間的資源競爭出現活鎖,但 Kubernetes 強大的可擴展性也使得不同的調度器實現了不同的 Gang Scheduling 協議,如 YuniKorn, KubeBatch 等。為了避免與具體調度器實現的耦合,適應不同用戶環境的差異,KubeDL 將 Gang Scheduling 的協議實現插件化,按需啟用對應的插件即可與調度器相互協作,實現作業的批量調度。
Job 是一次性的,但在實際的生產應用中我們經常會遇到反復訓練/定時訓練的場景,如每日拉取某一時間區間的離線表并進行數據清洗以及模型的 Re-train,KubeDL 提供了一類單獨的工作負載—Cron 來處理定時的訓練請求,并支持任意類型的訓練作業(如 TFJob,PyTorchJob 等),用戶可以提交 cron tab 風格的定時命令及作業模板,并在 Cron 資源的狀態中追蹤訓練作業的歷史及當前進行中的作業。
針對海量離線作業元數據需要長時間保存(Job CRD 被刪除后元數據即從 etcd 銷毀)的訴求,KubeDL 還內置了元數據的持久化,實時監聽 Job/Pod/Events 等資源對象的變化,轉化成對應的 Databse Schema Object 并持久化到存儲后端中。存儲后端的設計也是插件化的,用戶可以根據自己的線上環境來實現存儲插件并在部署時 enable。在 KubeDL 中 Job/Pod 默認支持了 Mysql 的存儲協議,以及將 Events 收集到阿里云 SLS 服務中。
同時我們還提供了管控套件:KubeDL-Dashboard,用戶不需要去理解 Kubernetes 的眾多 API 并在各種 kubectl 命令中掙扎,即可界面化地上手簡單易用的機器學習作業。持久化的元數據也可以直接被 Dashboard 消費使用。Dashboard 提供了簡單的作業提交、作業管理、事件/日志查看、集群資源視圖等功能,以極低的學習門檻幫助機器學習用戶上手實驗。
2、推理服務規格調優
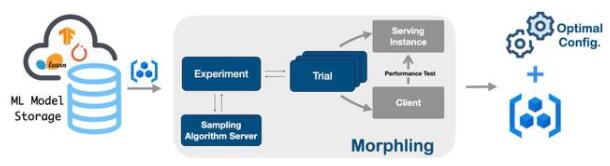
GPU 虛擬化與分時復用技術的發展和成熟,讓我們有機會在一塊 GPU 上同時運行多個推理服務,顯著降低成本。然而如何為推理服務選擇合適的 GPU 資源規格,尤其是不可壓縮的顯存資源,成為一個關鍵難題。一方面,頻繁的模型迭代讓算法工程師無暇去精確估計每個模型的資源需求,流量的動態變化也讓資源評估變得不準確,因此他們傾向于配置較多的 GPU 資源冗余,在穩定性和效率之間選擇犧牲后者,造成大量浪費;另一方面,由于 Tensorflow 等機器學習框架傾向于占滿所有空閑的顯存,站在集群管理者的角度,根據顯存的歷史用量來估計推理業務的資源需求也非常不準確。在 KubeDL-Morphling 這個組件中我們實現了推理服務的自動規格調優,通過主動壓測的方式,對服務在不同資源配置下進行性能畫像,最終給出最合適的容器規格推薦。畫像過程高度智能化:為了避免窮舉方式的規格點采樣,我們采用貝葉斯優化作為畫像采樣算法的內部核心驅動,通過不斷細化擬合函數,以低采樣率(<20%)的壓測開銷,給出接近最優的容器規格推薦結果。
3、模型管理與推理服務
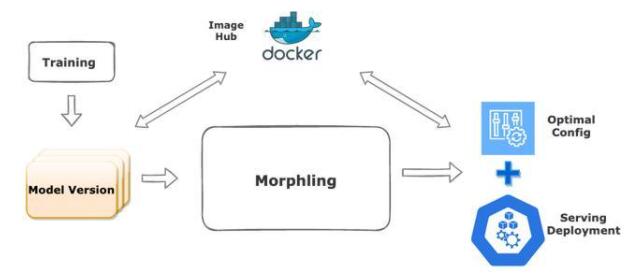
模型是訓練的產物,是計算與算法結合后的濃縮精華,通常收集與維護模型的方式是托管在云存儲上,通過組織文件系統的方式來實現統一管理。這樣的管理方式依賴于嚴格的流程規范與權限控制,沒有從系統層面實現模型管理的不可變,而容器鏡像的誕生解決的就是 RootFS 的構建-分發-不可變等問題,KubeDL 將兩者進行結合,實現了基于鏡像的模型管理。訓練成功結束后,通過 Job Spec 中指定的 ModelVersion 會自動觸發模型鏡像的構建。用戶可以在 ModelVersion.Spec 中約定模型的存儲路徑,目標的鏡像 Registry 等基本信息,將每次的訓練輸出 Push 到對應的鏡像倉庫。
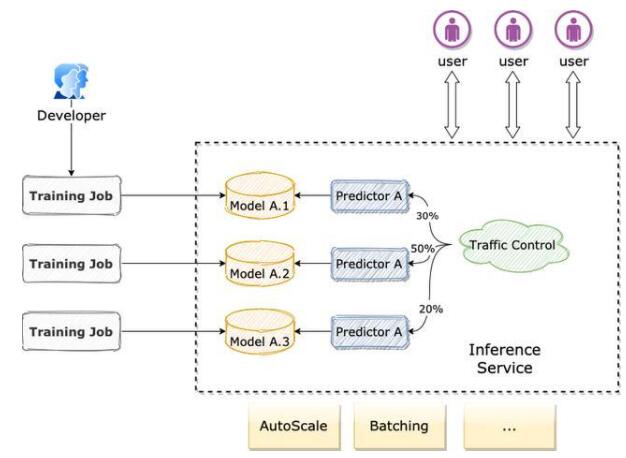
同時鏡像作為訓練的輸出,以及推理服務的輸入,很好地串聯起了兩個階段,也借此實現了分布式訓練->模型構建與管理->推理服務部署的完整機器學習流水線。KubeDL 提供了 Inference 資源對象提供推理服務的部署與運行時控制,一個完整的 Inference 服務可以由單個或多個 Predictor 組成,每個 Predictor 對應前序訓練輸出的模型,模型會被自動拉取并掛載到主容器 Volume 中。當多個不同模型版本的 Predictor 并存時,可以根據分配的權重進行流量的分發與控制,達到 A/B Test 的對照實驗效果,后續我們還會在 Batching 批量推理和 AutoScale 上針對推理服務場景做更多的探索。
KubeDL 分布式訓練在公有云上的實踐
PAI-DLC

隨著云計算的深入人心以及越來越多的業務都用云原生的方式進行,阿里云計算平臺 PAI 機器學習團隊推出了 DLC(Deep Learning Cloud)這一深度學習平臺產品。DLC 采用全新的云原生架構,底層采用 Kubernetes 作為資源底座支持,而訓練部分全面采用 KubeDL 進行管理,是 KubeDL 在深度學習云計算場景中的大規模實踐。
DLC 在阿里集團內部內廣泛支撐了眾多的業務,包括淘系安全部達摩院的圖像視頻、自然語言、語音、多模態理解、自動駕駛等眾多業務部門的深度學習計算需求。在服務于深度學習驅動的前沿業務生產中,PAI 團隊在框架和平臺建設方面積累了許多的經驗,沉淀了兼容社區(eg,TensorFlow/PyTorch)并且具有鮮明特色的大規模工業界實踐過的框架平臺能力,如萬億規模參數的M6模型的訓練、工業級圖神經網絡系統 Graph-Learn、極致資源管理和復用能力等等。
如今,PAI-DLC 的能力也在全面擁抱公有云,為開發者和企業提供的云原生一站式的深度學習訓練平臺,一個靈活、穩定、易用和高性能的機器學習訓練環境,以及全面支持支持多種社區和 PAI 深度優化的算法框架,高性能且穩定的運行超大規模分布式深度學習任務,為開發者和企業降本增效。
公有云的 DLC 作為阿里巴巴集團機器學習平臺最佳實踐的透出,在產品細節、框架優化、平臺服務等方面都吸取了工程實踐中的寶貴的經驗。除此之外,DLC 產品在設計之初就充分考量了公有云場景中的獨特屬性,提供了競價實例、自動 Fail-Over、彈性擴縮等功能,為客戶努力降低 AI 算力成本。
進一步的,DLC 也與 PAI 的其他公有云產品相結合,比如說服務于算法工程師建模的 DSW、服務于企業級 AI 全流程的、自動化的 AutoML、在線推理服務 EAS 等,打造全流程的 AI 標桿性產品。


















