一行預處理代碼,讓你的CV模型更強
圖像預處理的一個重要操作就是resize,把不同大小的圖像縮放到同一尺寸,但目前用到的resize技術仍然是老舊的,無法根據數據變換。Google Research提出一個可學習的resizer,只需在預處理部分略作修改,即可提升CV模型性能!
神經網絡要求輸入的數據的大小在每個mini-batch中是統一的,所以在做視覺任務的時候,一個重要的預處理步驟就是image resize,把它們調整到統一的大小進行訓練。
通常縮放(image down-scaling)后的圖像不會太大,因為如果分辨率過高會導致訓練過程中模型占用的內存急劇上升,并且過高的分辨率也會導致訓練速度和推理速度過慢。雖然近年來GPU的性能逐漸提升,但標準的輸入圖像仍然是224 × 224。
在大多數情況下,經過處理的圖像的最終尺寸非常小,例如早期的deepfake生成的圖片只有80 × 80的分辨率。
在人臉數據集中,因為人臉很少有是正方形的,一張圖片中的像素會浪費比較多的空間,可用的圖像數據就更少了。

目前最常用的圖像大小調整方法包括最近鄰(nearest neighbor)、雙線性(bilinear)和雙三次(bicubic)。這些resize方法的速度很快,可以靈活地集成在訓練和測試框架中。
但這些傳統方法是在深度學習成為視覺識別任務的主流解決方案之前幾十年發展起來的,所以并不是特別適合新時代的深度學習模型。
Google Research提出了一種新的方法,通過改進數據集中的圖像在預處理階段縮放的方式,來提高基于圖像的計算機視覺訓練流程的效率和準確性。

圖像大小對任務訓練精度的影響并沒有在模型訓練中受到很大關注。為了提高效率,CV研究人員通常將輸入圖像調整到相對較小的空間分辨率(例如224x224) ,并在此分辨率下進行訓練和推理。
研究人員想到,這些resizer是否限制了訓練網絡的任務性能呢?
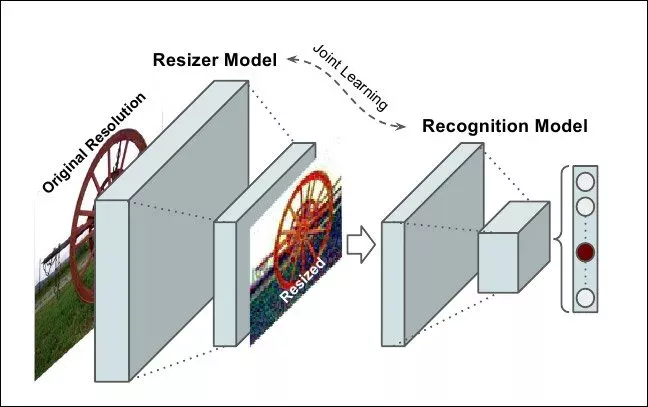
通過一個簡單的實驗就可以證明當這些傳統的resizer被可學習的resizer替代后,可以顯著提高性能。
傳統的resizer通常可以生成更好的視覺上的縮放圖像,可學習的resizer對人來說可能不是特別容易看清楚。

文中提出的resizer模型架構如下圖所示:
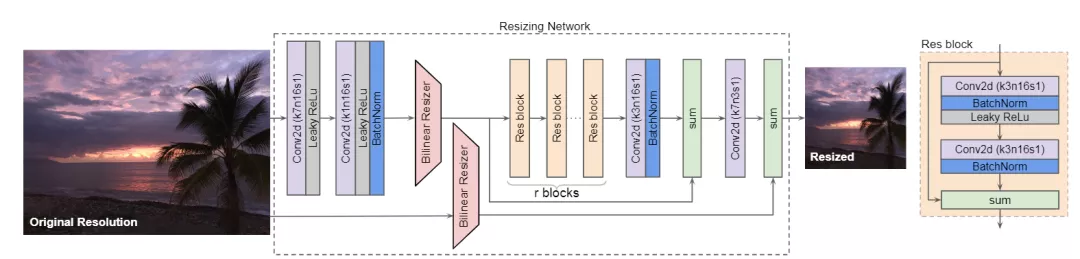
它主要包括了兩個重要的特性:(1) 雙線性特征調整大小(bilinear feature resizing),以及(2)跳過連接(skip connection),該連接可容納雙線性調整大小的圖像和CNN功能的組合。
第一個特性考慮到以原始分辨率計算的特征與模型的一致性。跳過連接可以簡化學習過程,因為重定大小器模型可以直接將雙線性重定大小的圖像傳遞到基線任務中。
與一般的編碼器-解碼器架構不同,這篇論文中所提出的體系結構允許將圖像大小調整為任何目標大小和縱橫比。并且可學習的resizer性能幾乎不依賴于雙線性重定器的選擇,這意味著它可以直接替換其他現成的方法。
并且這個的resizer模型相對較輕量級,不會向基線任務添加大量可訓練參數,這些CNN明顯小于其他基線模型。
論文中的實驗主要分為三個部分。
1、分類性能。
將使用雙線性調整器訓練的模型和輸出調整分辨率224×224稱為默認基線。結果表明,在224×224分辨率的模型中,性能最好,使用文中提出的resizer訓練的網絡對性能有所提升。
與默認基線相比,DenseNet-121和MobileNet-v2基線分別顯示出最大和最小的增益。對于Inception-v2、DenseNet-121和ResNet-50,提出的resizer的性能優于具有類似雙線性重定器。
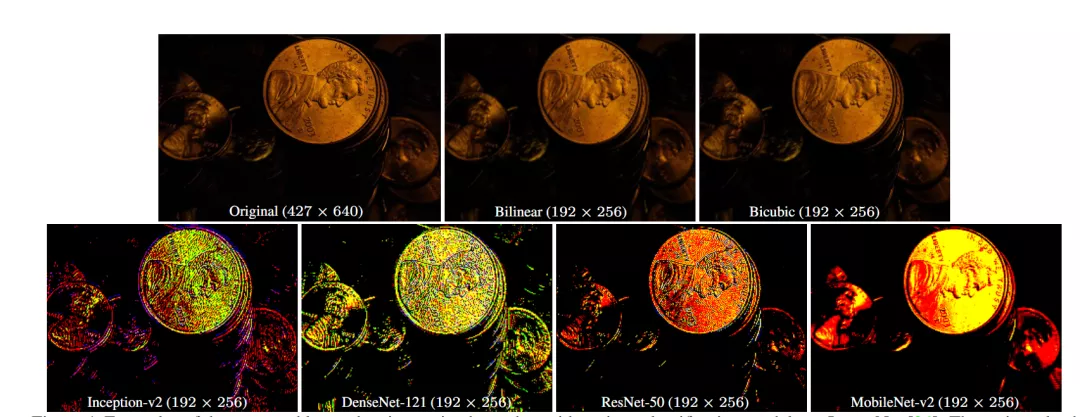
2、質量評估
研究人員使用3種不同的基線模型對AVA數據集進行訓練。基線模型根據ImageNet上預先訓練的權重進行初始化,并在AVA數據集上進行微調。resizer權重是隨機初始化的。在這組實驗中,使用雙三次resizer為基線方法。通過平均基本真實分數和平均預測分數之間的相關性來衡量性能,相關性的評價采用使用皮爾遜線性相關系數(PLCC)和斯皮爾曼秩相關系數(SRCC)。
與基線模型相比,存在確定性的改進。此外,對于Inception-v2和DenseNet-121型號,文中提出的resizer性能優于雙三次resizer。在更高的失敗率下,對于學習型resizer來說,EfficientNet似乎是一個更難有所提升的基線模型。

3、泛化性
首先使用與resizer的默認基線不同的目標基線聯合微調的可學習resizer。然后,度量目標基線在底層任務上的性能。可以觀察到,對大約4個epoch的訓練數據進行微調足以使resizer適應目標模型。這個驗證是一個合理的指標,能夠表明經過訓練的resizer對各種體系結構的通用性如何。
由分類和IQA結果可知,每列顯示resizer模型的初始化檢查點,每行表示一個目標基線。這些結果表明,經過最少次的微調,就可以為一個基線訓練的resizer可以有效地用于開發另一個基線的resizer。
在某些情況下,如DenseNet和MobileNet模型,微調的resizer實際上超過了通過隨機初始化獲得的分類性能。對于IQA的EffectiveNet模型也有同樣的觀察結果。
最后研究人員指出,這些實驗專門針對圖像識別任務進行了優化,并且在測試中,他們的 CNN驅動的可學習的resizer能夠在這類任務中降低錯誤率。
未來也許考慮在其他圖像任務中訓練image resizer。