













聯邦遷移學習最新進展:計算和傳輸如何“限制”模型性能?

本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
人工智能系統需要依賴大量數據,然而數據的流轉過程以及人工智能模型本身都有可能泄漏敏感隱私數據。
例如,在數據流轉的任意階段,惡意攻擊者可以對匿名數據集發起攻擊,從而竊取數據;
例如,在數據發布階段,惡意攻擊者可以使用身份重識別對匿名數據集發起攻擊,從而竊取隱私信息......
學界針對上述隱私泄露問題提出了多種針對性的保護方法,基于差分隱私和同態加密的聯邦學習是一種常見的隱私保護方法。
聯邦學習在 2015 年提出,其能在不暴露用戶數據的條件下進行多方機器學習模型的訓練,以期保護隱私信息。
但由谷歌所提出的聯邦學習,不僅必須保證數據集特征空間一致,且引入噪聲對模型精確度造成影響,此外,還存在部分敏感信息傳遞等問題,這些不足限制了聯邦學習在實際生產中的應用前景。
2018年,聯邦遷移學習理論被提出。該理論中,訓練所使用的多個數據集,無需保證特征空間的一致。另外,該理論使用同態加密替代差分隱私對隱私數據進行保護。這些改進為聯邦學習在金融、醫療等場景中的應用帶來了極大的便利。但是聯邦遷移學習在實際使用中暴露出了嚴重的性能缺陷。
針對這個問題,來自于香港科技大學、星云Clustar以及鵬城實驗室的研究人員聯合發表了《量化評估聯邦遷移學習(Quantifying the Performance of Federated Transfer Learning)》。該論文通過對聯邦遷移學習框架進行研究,提出了聯邦學習在實際應用中所面臨的性能方面的挑戰,并給出了相應優化方案。

論文作者:敬清賀,王偉儼,張駿雪,田晗,陳凱
編譯: 程孝典(星云Clustar軟件工程師)
論文:https://arxiv.org/abs/1912.12795
性能方面的挑戰主要包括:
1、聯邦遷移學習的性能瓶頸主要來自于計算和傳輸;
2、跨進程通信和內存拷貝是當前聯邦遷移學習實現的主要性能瓶頸;
3、不同的參與方往往位于相距較遠的兩個站點中,只能通過高延遲的廣域網傳輸數據,因此耗時也遠高于分布式機器學習。
一、聯邦遷移學習簡介
聯邦學習理論基于查分隱私對數據進行保護,若干數據持有者可以在原始數據不離開本地的前提下實現聯合模型訓練。但是最初的聯邦學習體系中,參與者之間必須保證數據的特征空間完全相同。舉例說明,如果A公司持有的數據包含用戶性別、年齡、年收入等信息,則B公司的數據也必須包含這些信息,才能和A公司進行聯邦學習。除此之外,該體系還存在噪聲對模型精確度造成影響、仍存在部分敏感信息傳遞等問題,這就限制了聯邦學習在實際生產中的應用前景。
為了擺脫這一系列限制,聯邦遷移學習(Federated Transfer Learning)于2018年被提出。在該理論中,訓練所使用的多個數據集,無需保證特征空間的一致。另外,該理論使用同態加密替代差分隱私對隱私數據進行保護。這些改進為聯邦學習對金融、醫療等場景中的應用帶來了極大的便利。但是聯邦遷移學習在實際使用中遭遇了嚴重的性能不足問題。
聯邦遷移學習的典型工作流程如圖一所示,其中需要三個不同的參與者:Guest、Host和Arbiter。其中Guest和Host是數據持有者,同時也負責主要的數值計算和加密工作;Arbiter在計算開始前生成密鑰,并發送至Host和Guest,此外,Arbiter負責訓練過程中的梯度聚合以及收斂檢查。如果Host和Guest所持有的數據中樣本不同而特征相同,這種聯邦遷移學習被稱為同構的或橫向的(homogeneous);如果雙方數據集樣本相同而特征不同,則稱聯邦遷移學習為異構的或縱向的(heterogeneous)。
在訓練過程中,Host和Guest首先使用本地數據進行初步計算,并對計算結果進行加密,這些中間結果可以被用于梯度和損失的計算。接下來,雙方將加密結果發送至Arbiter進行聚合,Arbiter對密文進行解密后,返回給Host和Guest,雙方使用接收的數值更新本地模型。聯邦遷移學習需要重復此訓練過程,直至模型收斂。
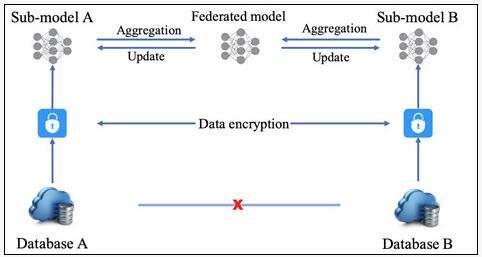
圖一:聯邦遷移學習工作流程
二、聯邦遷移學習性能分析
從聯邦遷移學習的工作流程中,可以發現它和分布式機器學習在一些方面上十分相似,二者均包含多個持有不同數據的工作節點,且均根據聚合的結果更新模型。但是,兩種體系之間存在相當明顯的區別:在分布式機器學習中,參數服務器(parameter server)是中心調度節點,負責將數據和計算分配到不同的工作節點中從而優化訓練性能;在聯邦遷移學習中,不同的數據持有者對本方工作節點和數據都有著完全獨立的管理,除此之外,聯邦遷移學習中所使用的同態加密,將極大地增加計算和數據傳輸時間。
因此,和分布式機器學習相比,聯邦遷移學習是一種復雜度更高的系統,也可以認為分布式機器學習性能是衡量聯邦遷移學習性能的合適指標。近年來,有關分布式機器學習的方案設計以及性能優化的研究十分火熱,而聯邦遷移學習則鮮有人踏足。量化分布式機器學習和聯邦遷移學習的性能差距,對聯邦遷移學習的性能優化,具有啟發性的借鑒和參考價值。
圖二為分布式機器學習和聯邦遷移學習在使用相同數據集訓練相同模型的性能對比圖。圖(a)代表模型訓練端到端性能對比,根據測試結果,兩種系統的運行時間差距在18倍以上。根據分布式機器學習中的經驗,計算和數據傳輸往往是系統運行中時間占比最高的兩個部分,因此圖(b)和圖(c)又分別展示了兩種系統在計算和數據傳輸中的耗時對比,結果顯示,聯邦遷移學習的這兩段耗時,均在分布式機器學習的20倍左右,這也證實了聯邦遷移學習的性能瓶頸主要來自于計算和傳輸。因此,接下來,我們將分別從這兩個方面對聯邦遷移學習的時間開銷進行分析。
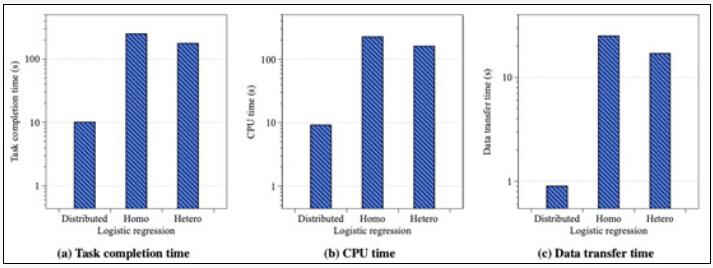
圖二:分布式機器學習和聯邦遷移學習(包括橫向和縱向)的性能對比
三、計算開銷分析
1、性能分析
為了進行深入的分析,我們將計算時間劃分為兩個部分:模型訓練(數值計算)和額外操作(包括跨進程通信和內存拷貝等),如圖三所示。我們從測試中發現,訓練任務的端到端時間開銷中,僅有18%左右的時間用于數值計算,而絕大部分的時間都花費在了內存拷貝等額外工作中。
具體說明額外操作,聯邦遷移學習的底層實現中需要使用不同編語言以實現不同的功能,而跨語言環境的數據交換和內存拷貝耗時較長,如Python和Java虛擬機(JVM)之間的數據傳遞。此外,聯邦遷移學習底層需要開啟多個進程,分別管理任務創建、數據傳遞等工作,而跨進程通信同樣開銷巨大。總的來說,跨進程通信和內存拷貝是當前聯邦遷移學習實現的主要性能瓶頸。
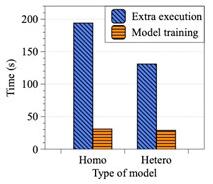
圖三:模型訓練時間和額外時間開銷對比
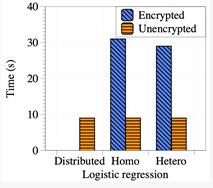
圖四:加密運算對模型訓練時間的影響
而在模型訓練時間中,一個較為明顯的時間開銷就是同態加密。聯邦遷移學習中所使用的部分同態加密將原本的浮點運算擴展為數千位大整數之間的運算,這顯然大幅降低了運算性能。因此,圖四對比了密態模型訓練與純明文模型訓練的運行時間。測試結果顯示同態加密運算為模型訓練過程引入了超過兩倍的額外時間開銷。因此,加速同態加密運算是優化聯邦遷移學習性能的可行方案。
2、優化方案
從降低額外開銷的角度,可以借鑒Unix domain socket或者JTux等以實現更高效率的跨進程通信。同時,使用JVM本地內存,可以有效提升跨環境內存拷貝速度。
從加速數值計算的角度,可以通過使用高性能計算硬件實現高吞吐率的同態加密運算。現如今以GPU和FPGA為代表的計算硬件設備,由于其充足的計算、存儲和通信資源,可以高并發地處理大部分數值計算。通過大幅降低同態加密開銷,可以有效提升模型訓練整體性能。
四、數據傳輸開銷分析
1、性能分析
除了計算開銷的明顯上漲,聯邦遷移學習中增長接近20倍的數據傳輸開銷也值得注意。造成該現象的原因主要有三個:首先,在計算開銷中,同態加密運算大大提升了數據位寬,這不僅增加了計算時間,也大幅增加了需要傳輸的總數據量,從而對數據傳輸時間造成了影響;其次,與傳統的機器學習算法相比,聯邦遷移學習中為了保護數據隱私,增加了不同參與方之間的數據交換,頻繁的數據傳輸必然帶來總傳輸時間的上升;最后,分布式機器學習往往部署在密集的數據中心網絡中,數據傳輸延時非常低,因此跨節點通信帶來的開銷也相對較低,而反觀聯邦遷移學習,在實際應用中,不同的參與方往往位于相距較遠的兩個站點中,只能通過高延遲的廣域網傳輸數據,因此耗時也遠高于分布式機器學習,如圖四所示,當我們將聯邦遷移學習的不同參與方部署在世界各地的數據中心網絡中時,數據帶寬較低,數據傳輸延遲將占到整體運行時間的30%以上,造成十分嚴重的影響。
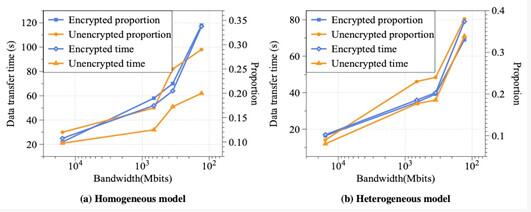
圖四:當參與方部署在不同地理位置時,數據傳輸時間以及在端到端運行時間中的占比
2、優化方案
在跨站點多方數據交換中,網絡質量扮演著重要的角色,而密集的通信很容易造成網絡擁塞,因此,探索網絡擁塞控制技術以提升數據傳輸性能是一種可行的解決方案。以PCC算法為代表的擁塞控制算法,可以通過細粒度的擁塞控制規則優化長距離數據傳輸的網絡性能,進而提升聯邦遷移學習的整體性能。
五、總結
作為機器學習在隱私計算中的拓展延伸,聯邦遷移學習對打破數據孤島,實現數據的更高價值有極其重要的作用。但是和所有的安全計算系統類似,性能和安全之間的平衡難以把控。現有的聯邦遷移學習系統框架還遠無法滿足實際生產中的性能需求。通過深入的性能分析,計算、內存拷貝以及數據傳輸等環節中的開銷問題,都是聯邦遷移學習的端到端性能惡化的重要原因。為了實現聯邦遷移學習在更多場景中的落地,結合多樣的解決方案對各個環節進行針對性優化不可或缺。




















