













Oracle中索引位圖轉換的優勢
第一章 Oracle索引位圖轉換介紹
1.1 索引位圖轉換
首先介紹一下索引位圖轉換概念:
索引位圖轉換是優化器對目標表上的一個或多個目標索引執行位圖布爾運算。Oracle數據庫里有一個映射函數(Mapping Function),它可以實現B樹索引中ROWID和對應位圖索引中的位圖之間互相轉換。目的是對相同ROWID做AND、OR等連接運算。
當執行計劃中出現“BITMAP CONVERSION FROM/TO ROWIDS”、“BITMAP AND”,說明Oracle對應的索引將其中的ROWID轉換成了位圖,然后對轉換后的位圖執行了BITMAP AND(位圖按位與)布爾運算。最后將布爾運算的結果再次用映射函數轉換成了ROWID并回表得到最終的結果。
1.2 性能分析
根據我們以往的經驗,用映射函數將ROWID轉換成位圖,這期間可能訪問了多個索引,甚至一個索引會訪問N多次。然后在執行位圖布爾運算。最后再將運算結果轉換為ROWID并回表,這個過程在實際生產環境中的執行效率往往是有問題的,我們可以通過隱藏參數_b_tree_bitmap_plans禁掉該過程中從ROWID到位圖的轉換。
但實際上當我們看到“BITMAP CONVERSION FROM/TO ROWIDS”的執行計劃,一定代表著存在性能問題嗎?
下面我用一個案例來說明:
創建測試表結構如下:
- DROP TABLE T1 PURGE;
- CREATE TABLE T1 AS SELECT * FROM DBA_OBJECTS;
- CREATE INDEX IDX_T1_ID ON T1(OBJECT_ID);
- EXEC dbms_stats.gather_table_stats(ownname=>'SZT',tabname =>'T1');
第二章 實驗環境測試
實驗腳本如下:
- select * from (
- select * from t1 WHERE object_id>88500 or object_id in (1,2,3,4,5,6,7)
- order by object_id)
- where rownum<100;
目的是通過單個索引,將優化器走索引位圖轉換與否的執行效率比較。
2.1 比較執行效率
首先測試默認情況下的執行計劃:
- select * from (
- select * from t1 WHERE object_id>88500 or object_id in (1,2,3,4,5,6,7)
- order by object_id)
- where rownum<100;
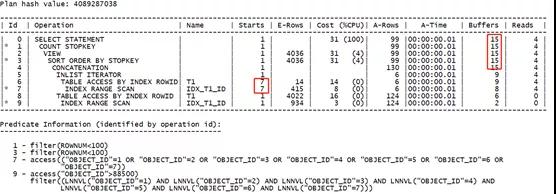
可以看到,優化器沒有對索引做位圖轉換,而是使用了OR擴展的方式。分別訪問兩部分的查詢條件,并對其中的IN條件使用IN-LIST迭代的方式獲取數據。
分析這樣的優勢:
IN條件中多個值會分別被訪問并與索引中的數據作比較,條件中的多個值也不會訪問索引多次,執行效率較高。通過邏輯讀部分也能確定。
通過HINT,嘗試讓優化器走出索引位圖轉換方式:
- select /*+ OUTLINE_LEAF(@"SEL$2") OUTLINE_LEAF(@"SEL$1")
- BITMAP_TREE(@"SEL$2" "T1"@"SEL$2" OR(1 1 ("T1"."OBJECT_ID") 2 ("T1"."OBJECT_ID") 3 ("T1"."OBJECT_ID") 4
- ("T1"."OBJECT_ID") 5 ("T1"."OBJECT_ID") 6 ("T1"."OBJECT_ID") 7 ("T1"."OBJECT_ID") 8 ("T1"."OBJECT_ID"))) */* from (
- select * from t1 WHERE object_id>88500 or object_id in (1,2,3,4,5,6,7)
- order by object_id)
- where rownum<100;
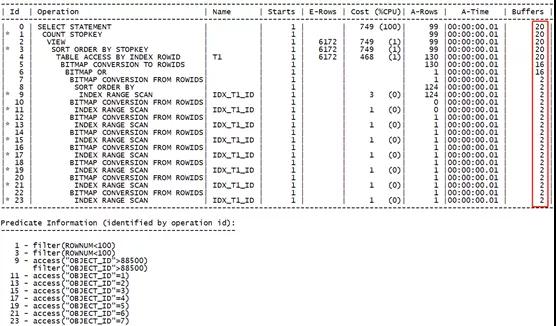
可以看到,每一次位圖訪問都只得到一個對應的IN條件值,且相同索引訪問多次每次都消耗固定的邏輯讀,據此分析當前場景下位圖索引轉換執行效率不佳。原因來自于索引的多次訪問。
我們查看相應表上的索引信息:

可以看到索引建立的原則就是唯一值與表數據1:1的情況。同時,由于采用了OBJECT_ID,其自增長特性,索引的聚簇因子比較小,屬于相對高效的索引。
得出結論:在聚簇因子較小時,通過OR擴展、IN-LIST迭代的方式其執行效率高于索引位圖轉換。且優化器也能準確評估COST成本。
但實際生產環境中,大部分索引的聚簇因子沒有這么高效。下面我們降低聚簇因子值及進行測試。
2.2 降低索引的聚簇因子:
讓我們重新創建新表。實驗腳本如下:
- CREATE TABLE T2 AS SELECT * FROM DBA_OBJECTS WHERE 1=2;
- insert into t2 select * from dba_objects order by dbms_random.value; --隨機插入
- CREATE INDEX IDX_T2_ID ON T1(OBJECT_ID);
- EXEC dbms_stats.gather_table_stats(ownname=>'SZT',tabname =>'T2');
通過打亂表數據的順序,降低聚簇因子值。

可以看到聚簇因子幾乎接近于表中數據行數,且索引葉子塊也有所增加。
2.2.1 比較執行效率
- select * from (
- select * from t2 WHERE object_id>88500 or object_id in (1,2,3,4,5,6,7)
- order by object_id)
- where rownum<100;
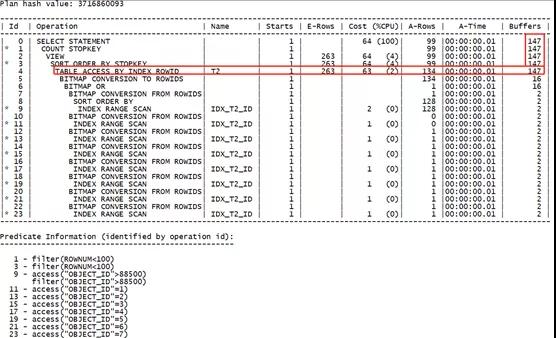
可以看到,默認情況下執行計劃變為了索引位圖轉換的形式。
分析其優勢:只進行了一次回表。
通過HINT讓優化器走回原有執行計劃:
- select * from (
- select /*+ USE_CONCAT(@"SEL$2" 8 OR_PREDICATES(1)) */ * from t2 WHERE object_id>88500 or object_id in (1,2,3,4,5,6,7)
- order by object_id)
- where rownum<100;
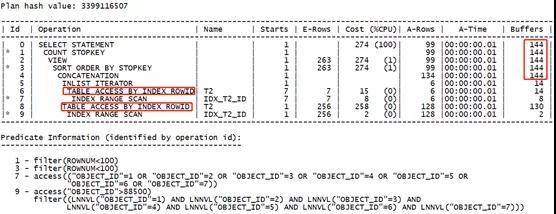
可以看到,由于回表了兩次,且聚簇因子較大,其消耗的邏輯讀已經逐漸接近于索引位圖轉換的方式了。
且分析其回表邏輯讀:
- 位圖形式:134行回表,消耗147-16=131。
- OR擴展:128行回表,消耗130-2=128。
回表的邏輯讀十分接近。
總結:
索引位圖轉換的優勢是減少回表次數。
OR擴展的優勢是其IN-LIST迭代部分消耗邏輯讀較低。
分析到此,我們已經基本明確不同方式的優劣了,但對實際的邏輯讀消耗對比還不夠確定。
下面讓我們增大查詢的條件范圍。
2.2.2 增大查詢條件范圍
- select * from (
- select * from t2 WHERE object_id>88450 or object_id in (1,2,3,4,5,6,7)
- order by object_id)
- where rownum<100;
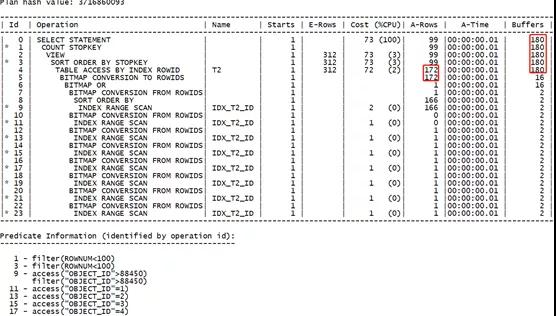
測試OR擴展:
- select /*+ USE_CONCAT(@"SEL$2" 8 OR_PREDICATES(1)) */* from (
- select * from t2 WHERE object_id>88450 or object_id in (1,2,3,4,5,6,7)
- order by object_id)
- where rownum<100;
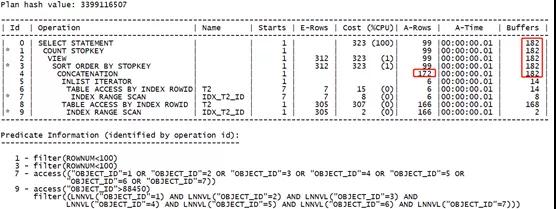
可以看到,當增大查詢范圍值后,兩種不同執行計劃其實際的消耗越來越接近了,最后通過索引位圖轉換的方式其執行效率甚至高于原有的OR擴展的形式。因此我們在判斷執行效率時,還是要具體情況具體分析。
分析回表的邏輯讀開銷:
- 位圖形式:172行回表,消耗180-16=164
- OR擴展:166行回表,消耗168-2=166
據此我們又可以確定,傳統的回表方式其實際的資源開銷高于索引位圖轉換后的回表方式。這又是索引位圖轉換的一大好處。
得出結論:
聚簇因子越大的索引,其越能在索引位圖轉換的方式中受益。因為其只需要回表一次。
索引位圖轉換后的回表,其消耗的資源開銷會低于傳統的回表方式。這也是索引位圖轉換的優勢之一。
第三章 總結
以上,我們通過3個測試例子,驗證的不同場景下的執行計劃表現。
關于開頭部分我們的疑問,可以很明確做答了。
1.索引位圖轉換和傳統的OR擴展、IN-LIST迭代等形式、其執行效率要具體情況具體分析。主要受影響于相關索引上的聚簇因子值。
2.索引位圖轉換的優勢是一次性統一回表,ROWID回表的開銷也會略低于傳統的形式。
3. IN-LIST迭代的優勢是對于IN后面條件多個值的訪問,其實際資源開銷較低。
墨天輪原文鏈接:https://www.modb.pro/db/25952(復制鏈接至瀏覽器或點擊文末閱讀原文查看)
關于作者
張程,云和恩墨SQL優化工程師,長期服務于金融、保險行業。現負責:公司Oracle、SQLServer、MySQL數據庫優化方面的技術工作;公司SQL審核軟件SQM的審核相關工作。熱衷于性能優化的學習與分享。











