這一次,徹底搞懂 GPU 和CSS 硬件加速
從 cpu 聊
起cpu (central process) 是計(jì)算機(jī)的大腦,它提供了一套指令集,我們寫的程序最終會(huì)通過(guò) cpu 指令來(lái)控制的計(jì)算機(jī)的運(yùn)行。
cpu 會(huì)對(duì)指令進(jìn)行譯碼,然后通過(guò)邏輯電路執(zhí)行該指令。整個(gè)執(zhí)行的流程分為了多個(gè)階段,叫做流水線。指令流水線包括取指令、譯碼、執(zhí)行、取數(shù)、寫回五步,這是一個(gè)指令周期。cpu 會(huì)不斷的執(zhí)行指令周期來(lái)完成各種任務(wù)。
指令和數(shù)據(jù)都會(huì)首先加載到內(nèi)存中,在程序運(yùn)行時(shí)依次取到 cpu 里。cpu 訪問(wèn)內(nèi)存雖然比較快,但比起 cpu 執(zhí)行速度來(lái)說(shuō)還是比較慢的,為了緩解這種速度矛盾,cpu 設(shè)計(jì)了 3 級(jí)緩存,也就是 L1、L2、L3 的緩存。
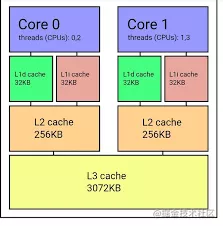
如圖,多核 cpu 各核心都有自有獨(dú)立的 L1、L2 緩存,然后共享 L3 緩存,這 3 級(jí)緩存容量是逐漸遞增的,但是速度是逐漸下降的,但是也會(huì)比訪問(wèn)內(nèi)存快一些。
有了這 3 級(jí)緩存以后,cpu 執(zhí)行速度和訪問(wèn)內(nèi)存速度的矛盾就可以得到緩解,不需要一直訪問(wèn)內(nèi)存,cpu 每次會(huì)加載一個(gè)緩存行,也就是 64 字節(jié)大小的數(shù)據(jù)到緩存中。這樣訪問(wèn)臨近的數(shù)據(jù)的時(shí)候就可以直接訪問(wèn)緩存。
從內(nèi)存中把數(shù)據(jù)和指令加載到 cpu 的緩存中,然后通過(guò)控制器控制指令的譯碼、執(zhí)行,通過(guò)運(yùn)算器進(jìn)行運(yùn)算,之后把結(jié)果寫回內(nèi)存。這就是 cpu 的工作流程。
cpu 每個(gè)核只有一個(gè)線程,也就是單控制流、單數(shù)據(jù)流。這樣的架構(gòu)導(dǎo)致 cpu 在一些場(chǎng)景下效率是不高的,比如 3d 渲染的場(chǎng)景。
3d 渲染流程
3d 的渲染首先是建立 3d 的模型,它由一系列三維空間中的頂點(diǎn)構(gòu)成,3 個(gè)頂點(diǎn)構(gòu)成一個(gè)三角形,然后所有的頂點(diǎn)構(gòu)成的三角形拼接起來(lái)就是 3d 模型。

頂點(diǎn)、三角形,這是 3d 的基礎(chǔ)。3d 引擎首先要計(jì)算頂點(diǎn)數(shù)據(jù),確定 3d 圖形的形狀。之后還要對(duì)每個(gè)面進(jìn)行貼圖,可以在每個(gè)三角形畫上不同的紋理。
3d 圖形要顯示在二維的屏幕上就要做投影,這個(gè)投影的過(guò)程叫做光柵化。(光柵是一種光學(xué)儀器,在這里就代表 3d 投影到 2d 屏幕的過(guò)程)
光柵化要計(jì)算 3d 圖形投影到屏幕的每一個(gè)像素的顏色,計(jì)算完所有的像素之后會(huì)寫到顯存的幀緩沖區(qū),完成了一幀的渲染,之后會(huì)繼續(xù)這樣計(jì)算下一幀。
也就是說(shuō),3d 渲染的流程是:
- 計(jì)算頂點(diǎn)數(shù)據(jù),構(gòu)成 3d 的圖形
- 給每個(gè)三角形貼圖,畫上紋理
- 投影到二維的屏幕,計(jì)算每個(gè)像素的顏色(光柵化)
- 把一幀的數(shù)據(jù)寫入顯存的幀緩沖區(qū)
頂點(diǎn)的數(shù)量是非常龐大的,而 cpu 只能順序的一個(gè)個(gè)計(jì)算,所以處理這種 3d 渲染會(huì)特別費(fèi)勁,于是就出現(xiàn)了專門用于這種 3d 數(shù)據(jù)的并行計(jì)算的硬件,也就是 GPU。
GPU 的構(gòu)成
和 cpu 的一個(gè)一個(gè)數(shù)據(jù)計(jì)算不同,gpu 是并行的,有成百上千個(gè)核心用于并行計(jì)算。
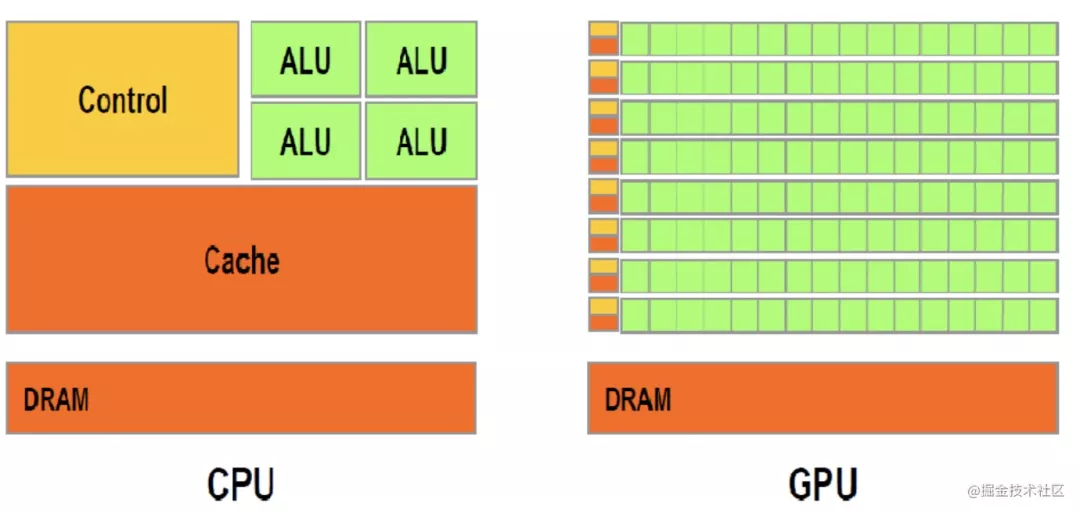
gpu 也是有著指令、譯碼、執(zhí)行的流程,只不過(guò),每個(gè)指令會(huì)并行執(zhí)行 n 個(gè)計(jì)算,是單控制流多數(shù)據(jù)流的,而 cpu 是單控制流單數(shù)據(jù)流。
所以,對(duì)于 3d 渲染這種要計(jì)算成萬(wàn)個(gè)頂點(diǎn)數(shù)據(jù)和像素點(diǎn)的場(chǎng)景,GPU 會(huì)比 CPU 高效很多。
但是,gpu 全是優(yōu)點(diǎn)么?也不是。
cpu 和 gpu 的區(qū)別
cpu 是通用的,能夠執(zhí)行各種邏輯和運(yùn)算,而 gpu 則是主要是用于并行計(jì)算大批量的重復(fù)任務(wù),不能處理復(fù)雜邏輯。
如上圖,cpu 中控制器和緩存占據(jù)了很大一部分,而 gpu 中這兩部分則很少,但是有更多的核心用于計(jì)算。
兩者對(duì)比的話,cpu 相當(dāng)于一個(gè)大學(xué)生,能夠解決各種難題,但是計(jì)算 1 萬(wàn)個(gè)加法就沒(méi)那么快,而 gpu 就像一幫小學(xué)生,解決不了難題,但是計(jì)算加法這種就很快,因?yàn)槿硕唷?/p>
也就是說(shuō)如果邏輯復(fù)雜,那么只能用 cpu,如果只是計(jì)算量大,并且每個(gè)計(jì)算都比較重復(fù),那就比較適合 gpu。
3d 的渲染中有大量這種重復(fù)卻簡(jiǎn)單的計(jì)算,比如頂點(diǎn)數(shù)據(jù)和光柵化的像素?cái)?shù)據(jù),通過(guò) gpu 就可以并發(fā)的一次計(jì)算成百上千個(gè)。
opengl、webgl、css 硬件加速
顯卡中集成了 gpu,提供了驅(qū)動(dòng),使用 gpu 能力需要使用驅(qū)動(dòng)的 api。gpu 的 api 有一套開(kāi)源標(biāo)準(zhǔn)叫做 opengl,有三百多個(gè)函數(shù),用于各種圖形的繪制。(在 windows 下有一套自己的標(biāo)準(zhǔn)叫做 DirectX)
我們?cè)诰W(wǎng)頁(yè)中繪制 3d 圖形是使用 webgl 的 api,而瀏覽器在實(shí)現(xiàn) webgl 的時(shí)候也是基于 opengl 的 api,最終會(huì)驅(qū)動(dòng) gpu 進(jìn)行渲染。
css 大部分樣式還是通過(guò) cpu 來(lái)計(jì)算的,但 css 中也有一些 3d 的樣式和動(dòng)畫的樣式,計(jì)算這些樣式同樣有很多重復(fù)且大量的計(jì)算任務(wù),可以交給 gpu 來(lái)跑。
瀏覽器在處理下面的 css 的時(shí)候,會(huì)使用 gpu 渲染:
- transform
- opacity
- filter
- will-change
瀏覽器是把內(nèi)容分到不同的圖層分別渲染的,最后合并到一起,而觸發(fā) gpu 渲染會(huì)新建一個(gè)圖層,把該元素樣式的計(jì)算交給 gpu。
opacity 需要改變每個(gè)像素的值,符合重復(fù)且大量的特點(diǎn),會(huì)新建圖層,交給 gpu 渲染。transform 是動(dòng)畫,每個(gè)樣式值的計(jì)算也符合重復(fù)且大量的特點(diǎn),也默認(rèn)會(huì)使用 gpu 加速。同理 fiter 也是一樣。
這里要注意的是 gpu 硬件加速是需要新建圖層的,而把該元素移動(dòng)到新圖層是個(gè)耗時(shí)操作,界面可能會(huì)閃一下,所以最好提前做。will-change 就是提前告訴瀏覽器在一開(kāi)始就把元素放到新的圖層,方便后面用 gpu 渲染的時(shí)候,不需要做圖層的新建。
當(dāng)然,有的時(shí)候我們想強(qiáng)制觸發(fā)硬件渲染,就可以通過(guò)上面的屬性,比如
- will-change: transform;
或者
- transform:translate3d(0, 0, 0);
chrome devtools 可以看到是 cpu 渲染還是 gpu 渲染,打開(kāi) rendering 面板,勾選 layer borders,會(huì)發(fā)現(xiàn)藍(lán)色和黃色的框。藍(lán)色的是 cpu 渲染的,而黃色的是 gpu 渲染的。
比如這段文字,現(xiàn)在沒(méi)有單獨(dú)一個(gè)圖層:
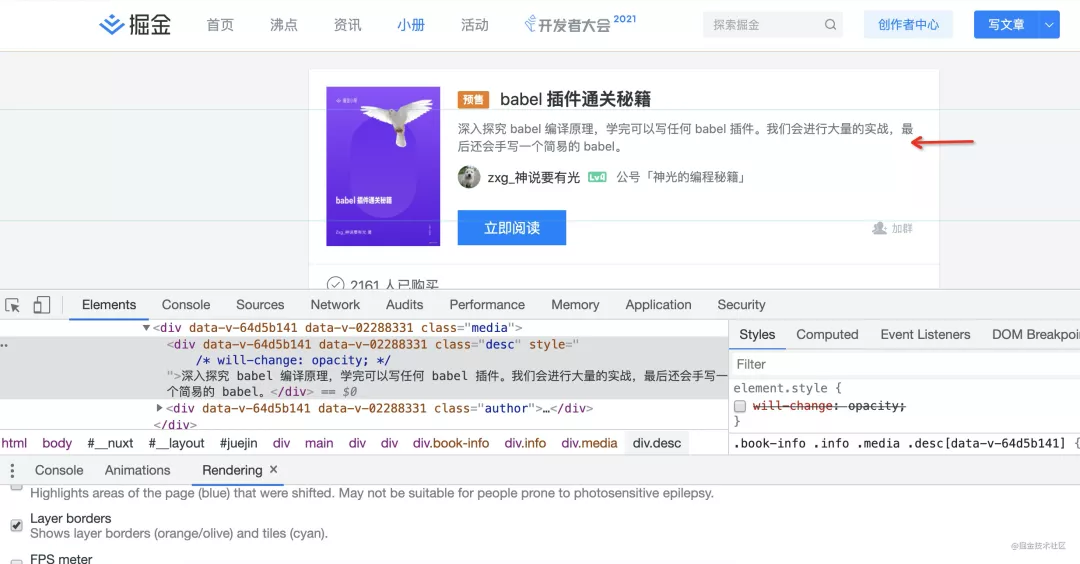
添加一個(gè) will-change: transform 的屬性,瀏覽器會(huì)新建圖層來(lái)渲染該元素,然后使用 gpu 渲染:
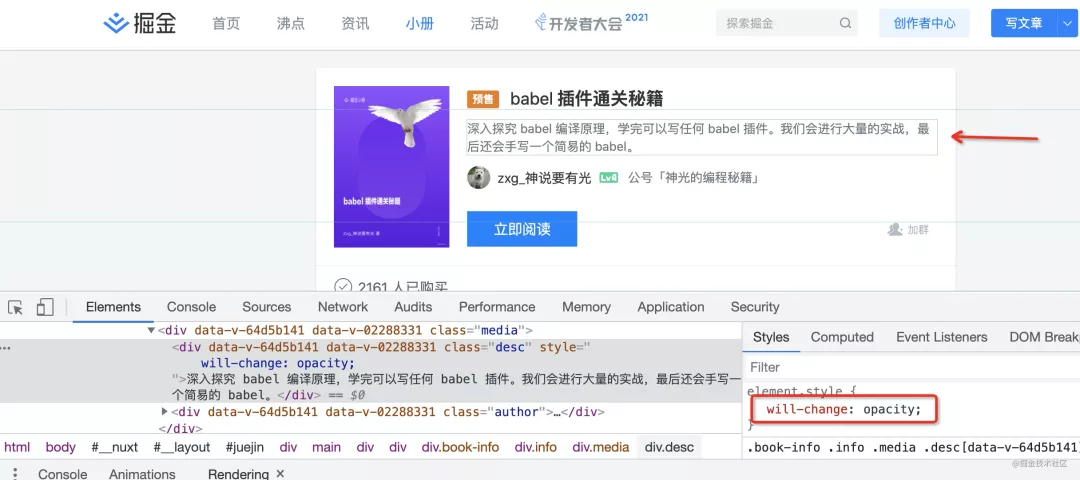
gpu 硬件加速能減輕 cpu 壓力,使得渲染更流暢,但是也會(huì)增加內(nèi)存的占用,對(duì)于 transform、opacity、filter 默認(rèn)會(huì)開(kāi)啟硬件加速。其余情況,建議只在必要的時(shí)候用。
opencl 和神經(jīng)網(wǎng)絡(luò)
重復(fù)且大量的計(jì)算任務(wù)只有 3d 渲染一種場(chǎng)景么?
不是的,AI 領(lǐng)域的機(jī)器學(xué)習(xí)也很典型,它的特點(diǎn)是大量的神經(jīng)元需要計(jì)算,但是每個(gè)計(jì)算都比較簡(jiǎn)單,也很適合用 gpu 來(lái)跑。
現(xiàn)在的 gpu 不只是能跑圖形渲染,也提供了一些編程能力,這部分 api 有 opencl 標(biāo)準(zhǔn)。可以通過(guò) gpu 的并行計(jì)算能力來(lái)跑一些有大量計(jì)算但是沒(méi)有很多邏輯的的任務(wù),會(huì)比 cpu 效率更高。
總結(jié)
cpu 提供了指令集,會(huì)不斷的執(zhí)行取指令、譯碼、執(zhí)行、取數(shù)、寫回的指令周期,控制著計(jì)算機(jī)的運(yùn)轉(zhuǎn)。
cpu 計(jì)算的速度比較快,而訪問(wèn)內(nèi)存比較慢,為了緩和兩者的矛盾,引入了 L1、L2、L3 的多級(jí)緩存體系,L1、L2、L3 是容器逐漸變大,訪問(wèn)速度逐漸變慢的關(guān)系,但還是比訪問(wèn)內(nèi)存快。內(nèi)存會(huì)通過(guò)一個(gè)緩存行(64 字節(jié))的大小為單位來(lái)讀入緩存,供 cpu 訪問(wèn)。
3d 渲染的流程是計(jì)算每一個(gè)頂點(diǎn)的數(shù)據(jù),連成一個(gè)個(gè)三角形,然后進(jìn)行紋理貼圖,之后計(jì)算投影到二維屏幕的每一個(gè)像素的顏色,也就是光柵化,最后寫入顯存幀緩沖區(qū),這樣進(jìn)行一幀幀的渲染。
cpu 的計(jì)算是一個(gè)個(gè)串行執(zhí)行的,對(duì)于 3d 渲染這種涉及大量頂點(diǎn)、像素要計(jì)算的場(chǎng)景就不太合適,于是出現(xiàn)了 gpu。
gpu 可以并行執(zhí)行大量重復(fù)的計(jì)算,有成百上千個(gè)計(jì)算單元,相比 cpu 雖然執(zhí)行不了復(fù)雜邏輯,但是卻能執(zhí)行大量重復(fù)的運(yùn)算。提供了 opengl 的標(biāo)準(zhǔn) api。
css 中可以使用 gpu 加速渲染來(lái)減輕 cpu 壓力,使得頁(yè)面體驗(yàn)更流暢,默認(rèn) transform、opacity、filter 都會(huì)新建新的圖層,交給 gpu 渲染。對(duì)于這樣的元素可以使用 will-change: 屬性名; 來(lái)告訴瀏覽器在最開(kāi)始就把該元素放到新圖層渲染。
gpu 的并行計(jì)算能力不只是 3d 渲染可以用,機(jī)器學(xué)習(xí)也有類似的場(chǎng)景,可以通過(guò) opencl 的 api 來(lái)控制 gpu 進(jìn)行計(jì)算。
gpu 和前端的關(guān)系還是挺密切的,不管是 webgl,還是 css 硬件加速,或者網(wǎng)頁(yè)的性能都與之相關(guān)。希望這篇文章能夠幫大家了解 gpu 的原理和應(yīng)用。