美團(tuán)面試:請手寫一個快排,被我懟了!
面試官:我們繼續(xù)來聊聊關(guān)于數(shù)據(jù)結(jié)構(gòu)與算法,你能寫一個快速排序?(說話的同時,把我簡歷反過來,遞給我一支筆,意思就是叫我在自己的簡歷背后寫)
菜鳥我:什么意思?這里寫嗎?(指著簡歷)
面試官:嗯
菜鳥我:不會
面試官:好吧,今天面試就到這里
菜鳥我:(心里很火,勞資的簡歷,想在勞資簡歷上寫代碼?)沙雕
面試官:(回頭看了一眼,一臉懵逼)
想想自己還是太年輕了,換著是現(xiàn)在就不是這樣了。寫就寫嘛,反正不就是一張紙而已。圖片
其實,快排說簡單嘛,估計很多人也手寫不出來,說難嗎也有很多人你能現(xiàn)場手寫幾種方式。
菜鳥我,當(dāng)年還是能手寫一種,畢竟面試前我剛好刻意的準(zhǔn)備過“默寫快排”。
下面,我們就來分析分析----快速排序。
背景
來自百科:
快速排序由C. A. R. Hoare在1962年提出。它的基本思想是:通過一趟排序?qū)⒁判虻臄?shù)據(jù)分割成獨立的兩部分,其中一部分的所有數(shù)據(jù)都比另外一部分的所有數(shù)據(jù)都要小,然后再按此方法對這兩部分?jǐn)?shù)據(jù)分別進(jìn)行快速排序,整個排序過程可以[遞歸]進(jìn)行,以此達(dá)到整個數(shù)據(jù)變成有序序列。
這概念理解起來 還是蠻費勁兒的。
可以這么理解:
快速排序是冒泡排序的改進(jìn)版,整個過程就在拆拆補補,東拆西補或西拆東補,一邊拆一邊補,直到所有元素達(dá)到有序狀態(tài)。
核心思想:
先從數(shù)列中取出一個數(shù)作為基準(zhǔn)數(shù),然后進(jìn)行大小分區(qū);
分區(qū)過程,將比這個數(shù)大的數(shù)全放到它的右邊,小于或等于它的數(shù)全放到它的左邊;
再對左右區(qū)間重復(fù)第二步,直到各區(qū)間只有一個數(shù),排序完成。
實現(xiàn)案例
下面先通過圖文形式一步一步進(jìn)行拆解。
拿[4,1,6,2,9,3]這個數(shù)組舉例。
第一遍遍歷:
- 先進(jìn)行拆分 [4,1,6,2,9,3] 選擇元素 4 作為軸心點
- 檢查是否 1 < 4 (軸心點)
- 檢查是否 6 < 4 (軸心點)
- 檢查是否 2 < 4 (軸心點)
- 2 < 4 (軸心點) 是為真,將指數(shù)2和 存儲指數(shù) 6 進(jìn)行交換
- 檢查是否 9 < 4 (軸心點)
- 檢查是否 3 < 4 (軸心點)
- 3 < 4 (軸心點) 為真,將指數(shù)3和存儲指數(shù)6 進(jìn)行交換
- 將軸心點4和存儲指數(shù)3進(jìn)行交換
- 此時軸心點4左邊全部小于4,右邊大于4
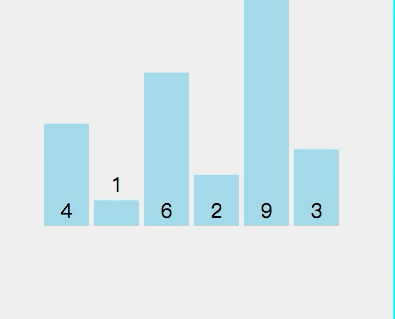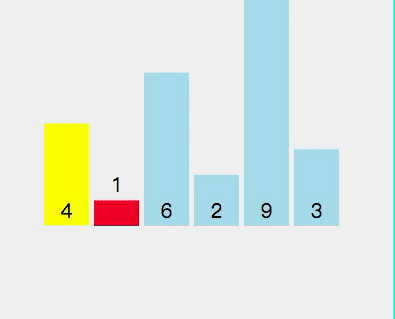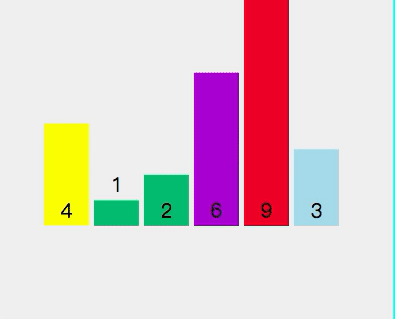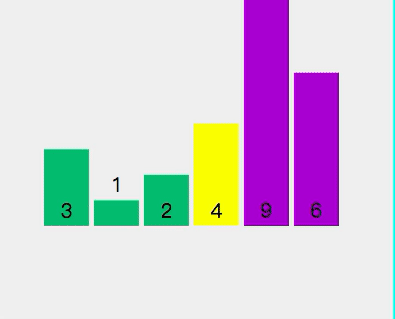
目前數(shù)組順序為[3,1,2,4,9,6]。
下一步:
- 先將左邊先排好序
- 選擇元素 3 作為軸心點
- 檢查是否 1 < 3 (軸心點)
- 檢查是否 2 < 3 (軸心點)
- 將軸心點 3和存儲指數(shù)值 2進(jìn)行交換
- 現(xiàn)在軸心點已經(jīng)在排序過后的位置
- 進(jìn)行拆分 [2,1] 選擇 2 作為軸心點
- 檢查是否 1 < 2 (軸心點)
- 左邊遍歷完成,將軸心點2和存儲指數(shù)1 進(jìn)行交換
右邊同理……避免視覺疲勞就不一一描述了,可看下面動態(tài)演示圖。
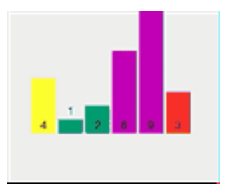
2. 快速排序法全流程
3.代碼實現(xiàn)
下面,我們使用Java語言來實現(xiàn)前面的快排案例:
- import java.util.Arrays;
- public class QuickSortDemo {
- //四個步驟:
- //1.比較startIndex和endIndex,更喜歡理解為校驗
- //2.找出基準(zhǔn)
- //3.左邊部分排序
- //4.右邊排序
- public static void quickSort(int[] arr, int startIndex, int endIndex) {
- if (startIndex < endIndex) {
- //找出基準(zhǔn)
- int partition = partition(arr, startIndex, endIndex);
- //分成兩邊遞歸進(jìn)行
- quickSort(arr, startIndex, partition - 1);
- quickSort(arr, partition + 1, endIndex);
- }
- }
- //找基準(zhǔn)
- private static int partition(int[] arr, int startIndex, int endIndex) {
- int pivot = arr[startIndex];
- int left = startIndex;
- int right = endIndex;
- //等于就沒有必要排序
- while (left != right) {
- while (left < right && arr[right] > pivot) {
- right--;
- }
- while (left < right && arr[left] <= pivot) {
- left++;
- }
- //找到left比基準(zhǔn)大,right比基準(zhǔn)小,進(jìn)行交換
- if (left < right) {
- swap(arr, left, right);
- }
- }
- //第一輪完成,讓left和right重合的位置和基準(zhǔn)交換,返回基準(zhǔn)的位置
- swap(arr, startIndex, left);
- return left;
- }
- //兩數(shù)交換
- public static void swap(int[] arr, int i, int j) {
- int temp = arr[i];
- arr[i] = arr[j];
- arr[j] = temp;
- }
- public static void main(String[] args) {
- int[] a = {3, 1, 2, 4, 9, 6};
- quickSort(a, 0, a.length - 1);
- //輸出結(jié)果
- System.out.println(Arrays.toString(a));
- }
- }
輸出結(jié)果:
- [1, 2, 3, 4, 6, 9]
代碼實現(xiàn),建議結(jié)合前面的動圖,理解起來就更簡單了。
快排寫法還有幾種,感興趣的可以自行查找一下,另外也可以看看維基百科中,快排是怎么介紹的。
4.復(fù)雜度分析
時間復(fù)雜度:
最壞情況就是每一次取到的元素就是數(shù)組中最小/最大的,這種情況其實就是冒泡排序了(每一次都排好一個元素的順序)
這種情況時間復(fù)雜度就好計算了,就是冒泡排序的時間復(fù)雜度:T[n] = n * (n-1) = n^2 + n;
最好情況下是O(nlog2n),推導(dǎo)過程如下:
(遞歸算法的時間復(fù)雜度公式:T[n] = aT[n/b] + f(n) )
https://img2018.cnblogs.com/blog/1258817/201903/1258817-20190326191158640-601403776.png
所以平均時間復(fù)雜度為O(nlog2n)
空間復(fù)雜度:
快速排序使用的空間是O(1)的,也就是個常數(shù)級;而真正消耗空間的就是遞歸調(diào)用了,因為每次遞歸就要保持一些數(shù)據(jù):
最優(yōu)的情況下空間復(fù)雜度為:O(log2n);每一次都平分?jǐn)?shù)組的情況
最差的情況下空間復(fù)雜度為:O( n );退化為冒泡排序的情況
所以平均空間復(fù)雜度為O(log2n)
5. 快速排序法總結(jié)
默認(rèn)取第一個元素為軸心點(軸心點的確認(rèn)區(qū)分了 “快速排序法”和“隨機(jī)排序法”)兩種算法,而隨機(jī)排序則隨機(jī)rand一個元素為軸心點;
如果兩個不相鄰元素交換,可以一次交換消除多個逆序,加快排序進(jìn)程。
后記
最后再說說,其實你覺得快速排序在工作中有用嗎?工作近十年的我真的沒用過,但我知道這個快排的思路。如果面試前不準(zhǔn)備,我反正是肯定寫不出來的,你呢?