Transformer又出新變體∞-former:無限長期記憶,任意長度上下文
在過去的幾年里,Transformer 幾乎統治了整個 NLP 領域,還跨界到計算機視覺等其他領域。但它也有弱點,比如不擅長處理較長上下文,因為計算復雜度會隨著上下文長度的增長而增長,這使其難以有效建模長期記憶。為了緩解這一問題,人們提出了多種 Transformer 變體,但它們的記憶容量都是有限的,不得不拋棄較早的信息。
在一篇論文中,來自 DeepMind 等機構的研究者提出了一種名為 ∞-former 的模型,它是一種具備無限長期記憶(LTM)的 Transformer 模型,可以處理任意長度的上下文。

論文鏈接:https://arxiv.org/pdf/2109.00301.pdf
通過利用連續空間注意力機制來處理長期記憶,∞-former 的注意力復雜度可以獨立于上下文長度。因此,它能夠借助一個固定的算力開銷建模任意長度的上下文并保持「粘性記憶(sticky memories)」。
在一個綜合排序任務上進行的實驗證明了∞-former 能夠保留來自長序列的信息。此外,研究者還進行了語言建模的實驗,包括從頭開始訓練一個模型以及對一個預訓練的語言模型進行微調,這些實驗顯示了無限長期記憶的優勢。
不過,和其他很多 Transformer 變體的論文一樣,這篇論文的標題也引發了一些吐槽:
∞-former:一種擁有無限記憶的 Transformer
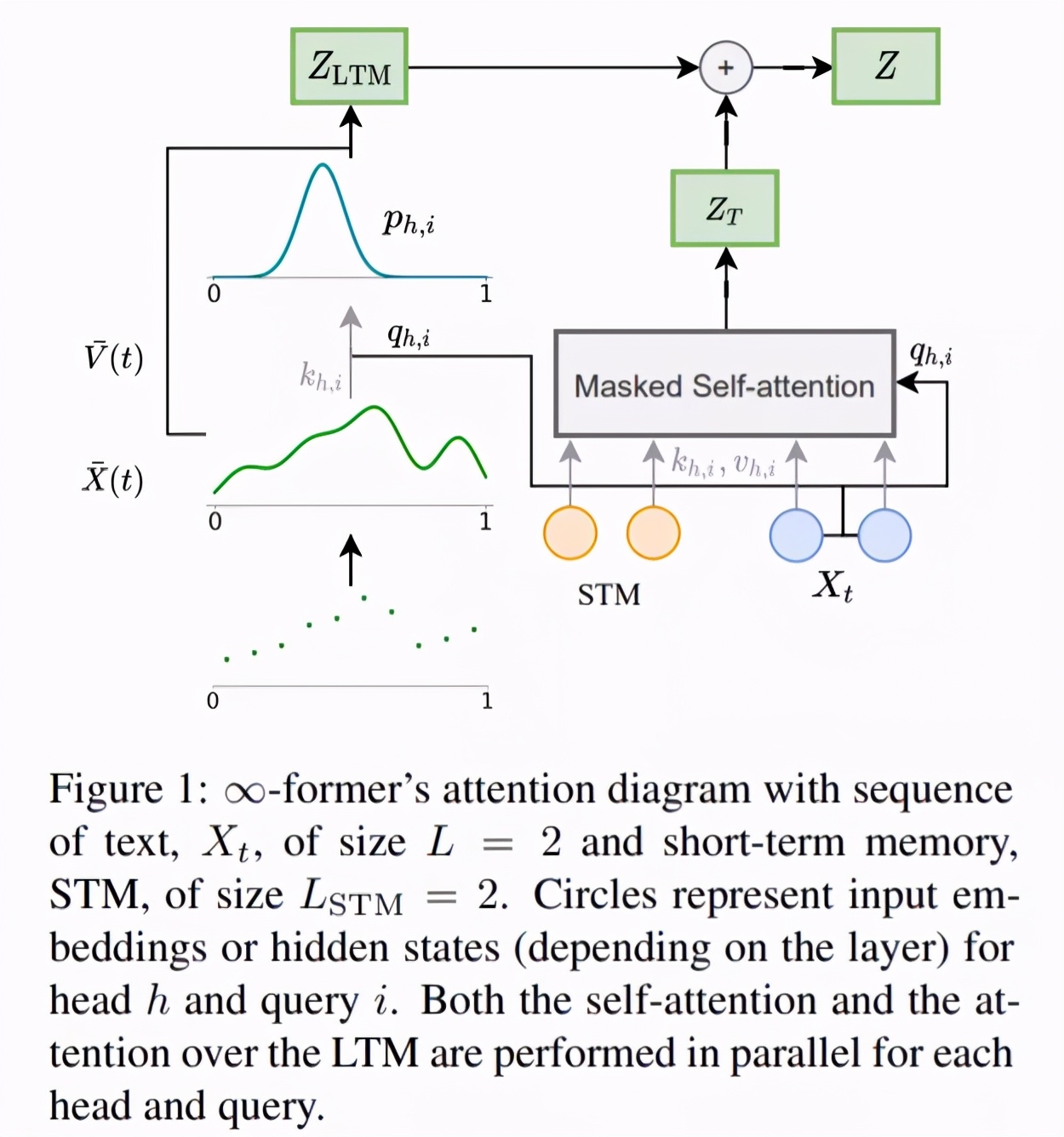
為了使模型能夠處理長程上下文,研究者提出用一個連續 LTM 來擴展原始 transformer,這個 LTM 存儲前面步驟的輸入嵌入和隱藏狀態。他們還考慮了有兩種記憶的可能性:LTM 和 STM(短期記憶),類似于 transformer-XL 的記憶。∞-former 的整體架構如下圖 1 所示。
為了讓新模型的 LTM 達到無限的程度,研究者使用了一個連續空間注意力框架(參見《 Sparse and Continuous Attention Mechanisms 》),它在適用于記憶的信息單元數量(基函數)和這些單元的表示粒度之間進行了權衡。在這一框架中,輸入序列被表征為一個連續信號,表示為徑向基函數的一個線性組合。這種表征有兩個顯著的優勢:1)上下文可以用 N 個基函數來表示,N 小于上下文中 token 的數量,降低了注意力復雜度;2)N 可以是固定的,這使得在記憶中表征無限長度的上下文成為可能(如圖 2 所示),代價是損失 resolution,但不增加其注意力復雜度,O(L^2 + L × N),其中的 L 對應 transformer 序列長度。

為了緩解損失較早記憶 resolution 的問題。研究者引入了「粘性記憶」的概念,將 LTM 新信號中的較大空間歸于之前記憶信號的相關區域。這是一種強制重要信息在 LTM 中持續存在的過程,使得模型可以在不損失相關信息的情況下更好地捕捉長上下文,類似于大腦中的長時程增強和突觸可塑性。
實驗結果
為了檢驗∞-former 能否建模長上下文,研究者首先針對一個綜合任務進行了實驗,包括把 token 按其在一個長序列中的頻率進行排序,結果如下:
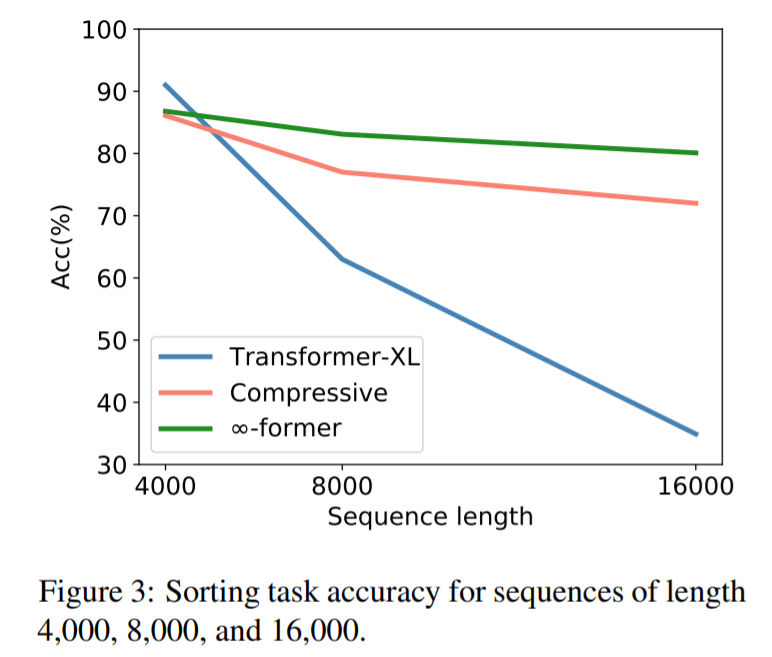
從圖中可以看出,在序列長度為 4000 的時候,transformerXL 的準確率要略高于 compressive transformer 和 ∞-former。這是因為 transformerXL 幾乎可以在記憶中保存整個完整序列。但隨著序列長度的增加,transformerXL 的準確率迅速下降,compressive transformer 和 ∞-former 變化較小。這表明∞-former 更擅長建模長序列。
接下來,他們又進行了語言建模實驗,包括:1)從頭訓練一個模型;2)微調一個預訓練語言模型。
第一個語言建模實驗的結果如下表 1 所示。從中可以看出,利用長期記憶擴展模型確實會帶來更好的困惑度結果,而且使用粘性記憶也可以在一定程度上降低困惑度。
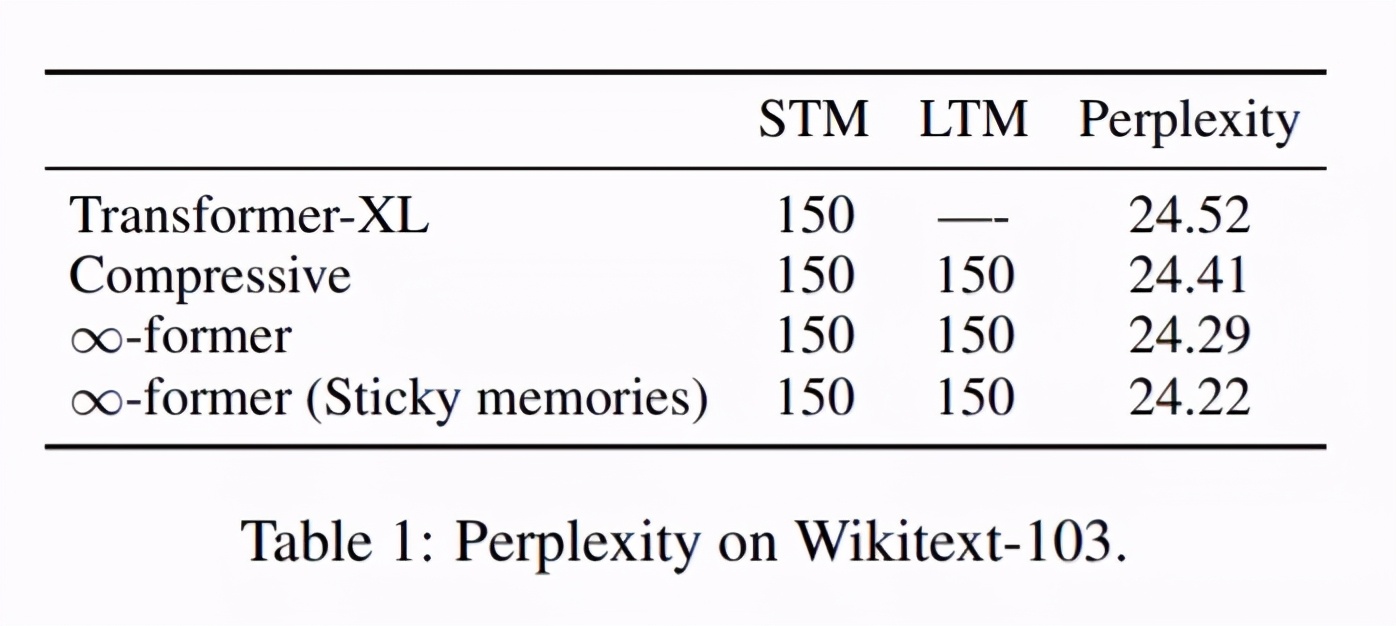
第二個語言建模實驗的結果如下表 2 所示。該結果表明,通過簡單地將長期記憶添加至 GPT-2 并進行微調,模型在 Wikitext-103 和 PG19 上的困惑度都會降低。這表明∞-former 具有多種用途:既可以從頭開始訓練模型,也可以用于改進預訓練模型。