













面試 | 十分鐘聊透Spark
本文轉載自微信公眾號「大數據技術與數倉」,作者西貝。轉載本文請聯系大數據技術與數倉公眾號。
Spark是一個快速的大數據處理引擎,在實際的生產環境中,應用十分廣泛。目前,Spark仍然是大數據開發非常重要的一個工具,所以在面試的過程中,Spark也會是被重點考察的對象。對于初學者而言,面對繁多的Spark相關概念,一時會難以厘清頭緒,對于使用Spark開發的同學而言,有時候也會對這些概念感到模糊。本文主要梳理了幾個關于Spark的比較重要的幾個概念,在面試的過程中如果被問到Spark相關的問題,具體可以從以下幾個方面展開即可,希望對你有所幫助。本文主要包括以下內容:
- 運行架構
- 運行流程
- 執行模式
- 驅動程序
- 共享變量
- 寬依賴窄依賴
- 持久化
- 分區
- 綜合實踐案例
組成
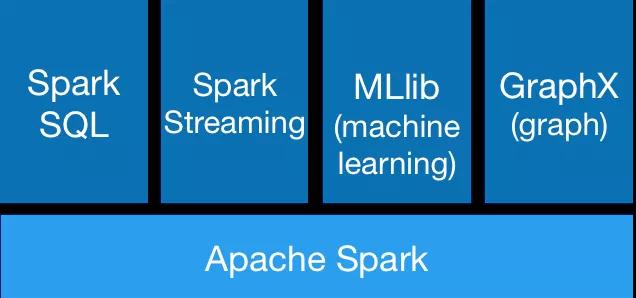
Spark棧包括SQL和DataFrames,MLlib機器學習, GraphX和SparkStreaming。用戶可以在同一個應用程序中無縫組合使用這些庫。
架構
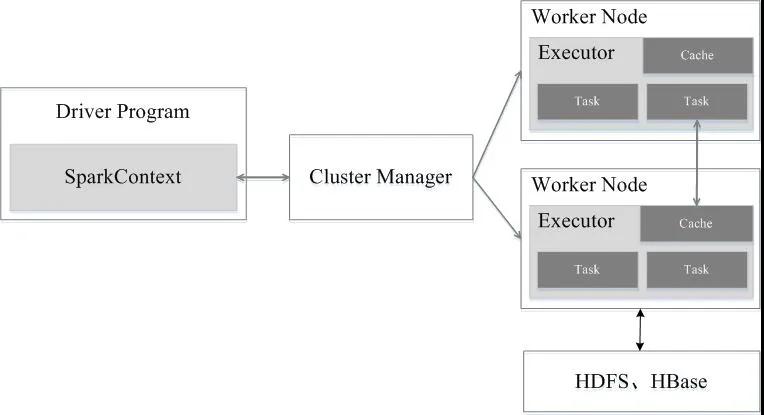
Spark運行架構包括集群資源管理器(Cluster Manager)、運行作業任務的工作節點(Worker Node)、每個應用的任務控制節點(Driver)和每個工作節點上負責具體任務的執行進程(Executor)。其中,集群資源管理器可以是Spark自帶的資源管理器,也可以是YARN或Mesos等資源管理框架。
運行流程

- 當一個Spark應用被提交時,首先需要為這個應用構建起基本的運行環境,即由任務控制節點(Driver)創建一個SparkContext,由SparkContext負責和資源管理器(Cluster Manager)的通信以及進行資源的申請、任務的分配和監控等。SparkContext會向資源管理器注冊并申請運行Executor的資源;
- 資源管理器為Executor分配資源,并啟動Executor進程,Executor運行情況將隨著“心跳”發送到資源管理器上;
- SparkContext根據RDD的依賴關系構建DAG圖,DAG圖提交給DAG調度器(DAGScheduler)進行解析,將DAG圖分解成多個“階段”(每個階段都是一個任務集),并且計算出各個階段之間的依賴關系,然后把一個個“任務集”提交給底層的任務調度器(TaskScheduler)進行處理;Executor向SparkContext申請任務,任務調度器將任務分發給Executor運行,同時,SparkContext將應用程序代碼發放給Executor;
- 任務在Executor上運行,把執行結果反饋給任務調度器,然后反饋給DAG調度器,運行完畢后寫入數據并釋放所有資源。
MapReduce VS Spark
與Spark相比,MapReduce具有以下缺點:
- 表達能力有限
- 磁盤IO開銷大
- 延遲高
- 任務之間的銜接涉及IO開銷
- 在前一個任務執行完成之前,其他任務就無法開始,難以勝任復雜、多階段的計算任務
與MapReduce相比,Spark具有以下優點:具體包括兩個方面
- 一是利用多線程來執行具體的任務(Hadoop MapReduce采用的是進程模型),減少任務的啟動開銷;
- 二是Executor中有一個BlockManager存儲模塊,會將內存和磁盤共同作為存儲設備,當需要多輪迭代計算時,可以將中間結果存儲到這個存儲模塊里,下次需要時,就可以直接讀該存儲模塊里的數據,而不需要讀寫到HDFS等文件系統里,因而有效減少了IO開銷;或者在交互式查詢場景下,預先將表緩存到該存儲系統上,從而可以提高讀寫IO性能。
驅動程序(Driver)和Executor
運行main函數的驅動程序進程位于集群中的一個節點上,負責三件事:
- 維護有關 Spark 應用程序的信息。
- 響應用戶的程序或輸入。
- 跨Executor分析、分配和調度作業。
驅動程序進程是絕對必要的——它是 Spark 應用程序的核心,并在應用程序的生命周期內維護所有相關信息。
Executor負責實際執行驅動程序分配給他們的任務。這意味著每個Executor只負責兩件事:
- 執行驅動程序分配給它的代碼。
- 向Driver節點匯報該Executor的計算狀態
分區
為了讓每個 executor 并行執行工作,Spark 將數據分解成稱為partitions 的塊。分區是位于集群中一臺物理機器上的行的集合。Dataframe 的分區表示數據在執行期間如何在機器集群中物理分布。
如果你有一個分區,即使你有數千個Executor,Spark 的并行度也只有一個。如果你有很多分區但只有一個執行器,Spark 仍然只有一個并行度,因為只有一個計算資源。
執行模式:Client VS Cluster VS Local
執行模式能夠在運行應用程序時確定Driver和Executor的物理位置。
有三種模式可供選擇:
- 集群模式(Cluster)。
- 客戶端模式(Client)。
- 本地模式(Local)。
集群模式 可能是運行 Spark 應用程序最常見的方式。在集群模式下,用戶將預編譯的代碼提交給集群管理器。除了啟動Executor之外,集群管理器會在集群內的工作節點(work)上啟動驅動程序(Driver)進程。這意味著集群管理器負責管理與 Spark 應用程序相關的所有進程。
客戶端模式 與集群模式幾乎相同,只是 Spark 驅動程序保留在提交應用程序的客戶端節點上。這意味著客戶端機器負責維護 Spark driver 進程,集群管理器維護 executor 進程。通常將這個節點稱之為網關節點。
本地模式可以被認為是在你的計算機上運行一個程序,spark 會在同一個 JVM 中運行驅動程序和執行程序。
RDD VS DataFrame VS DataSet
RDD
一個RDD是一個分布式對象集合,其本質是一個只讀的、分區的記錄集合。每個RDD可以分成多個分區,不同的分區保存在不同的集群節點上(具體如下圖所示)。RDD是一種高度受限的共享內存模型,即RDD是只讀的分區記錄集合,所以也就不能對其進行修改。只能通過兩種方式創建RDD,一種是基于物理存儲的數據創建RDD,另一種是通過在其他RDD上作用轉換操作(transformation,比如map、filter、join等)得到新的RDD。
- 基于內存
RDD是位于內存中的對象集合。RDD可以存儲在內存、磁盤或者內存加磁盤中,但是,Spark之所以速度快,是基于這樣一個事實:數據存儲在內存中,并且每個算子不會從磁盤上提取數據。
- 分區
分區是對邏輯數據集劃分成不同的獨立部分,分區是分布式系統性能優化的一種技術手段,可以減少網絡流量傳輸,將相同的key的元素分布在相同的分區中可以減少shuffle帶來的影響。RDD被分成了多個分區,這些分區分布在集群中的不同節點。
- 強類型
RDD中的數據是強類型的,當創建RDD的時候,所有的元素都是相同的類型,該類型依賴于數據集的數據類型。
- 懶加載
Spark的轉換操作是懶加載模式,這就意味著只有在執行了action(比如count、collect等)操作之后,才會去執行一些列的算子操作。
- 不可修改
RDD一旦被創建,就不能被修改。只能從一個RDD轉換成另外一個RDD。
- 并行化
RDD是可以被并行操作的,由于RDD是分區的,每個分區分布在不同的機器上,所以每個分區可以被并行操作。
- 持久化
由于RDD是懶加載的,只有action操作才會導致RDD的轉換操作被執行,進而創建出相對應的RDD。對于一些被重復使用的RDD,可以對其進行持久化操作(比如將其保存在內存或磁盤中,Spark支持多種持久化策略),從而提高計算效率。
DataFrame
DataFrame代表一個不可變的分布式數據集合,其核心目的是讓開發者面對數據處理時,只關心要做什么,而不用關心怎么去做,將一些優化的工作交由Spark框架本身去處理。DataFrame是具有Schema信息的,也就是說可以被看做具有字段名稱和類型的數據,類似于關系型數據庫中的表,但是底層做了很多的優化。創建了DataFrame之后,就可以使用SQL進行數據處理。
用戶可以從多種數據源中構造DataFrame,例如:結構化數據文件,Hive中的表,外部數據庫或現有RDD。DataFrame API支持Scala,Java,Python和R,在Scala和Java中,row類型的DataSet代表DataFrame,即Dataset[Row]等同于DataFrame。
DataSet
DataSet是Spark 1.6中添加的新接口,是DataFrame的擴展,它具有RDD的優點(強類型輸入,支持強大的lambda函數)以及Spark SQL的優化執行引擎的優點。可以通過JVM對象構建DataSet,然后使用函數轉換(map,flatMap,filter)。值得注意的是,Dataset API在Scala和 Java中可用,Python不支持Dataset API。
另外,DataSet API可以減少內存的使用,由于Spark框架知道DataSet的數據結構,因此在持久化DataSet時可以節省很多的內存空間。
共享變量
Spark提供了兩種類型的共享變量:廣播變量和累加器。廣播變量(Broadcast variables)是一個只讀的變量,并且在每個節點都保存一份副本,而不需要在集群中發送數據。累加器(Accumulators)可以將所有任務的數據累加到一個共享結果中。
廣播變量
廣播變量允許用戶在集群中共享一個不可變的值,該共享的、不可變的值被持計劃到集群的每臺節點上。通常在需要將一份小數據集(比如維表)復制到集群中的每臺節點時使用,比如日志分析的應用,web日志通常只包含pageId,而每個page的標題保存在一張表中,如果要分析日志(比如哪些page被訪問的最多),則需要將兩者join在一起,這時就可以使用廣播變量,將該表廣播到集群的每個節點。具體如下圖所示:
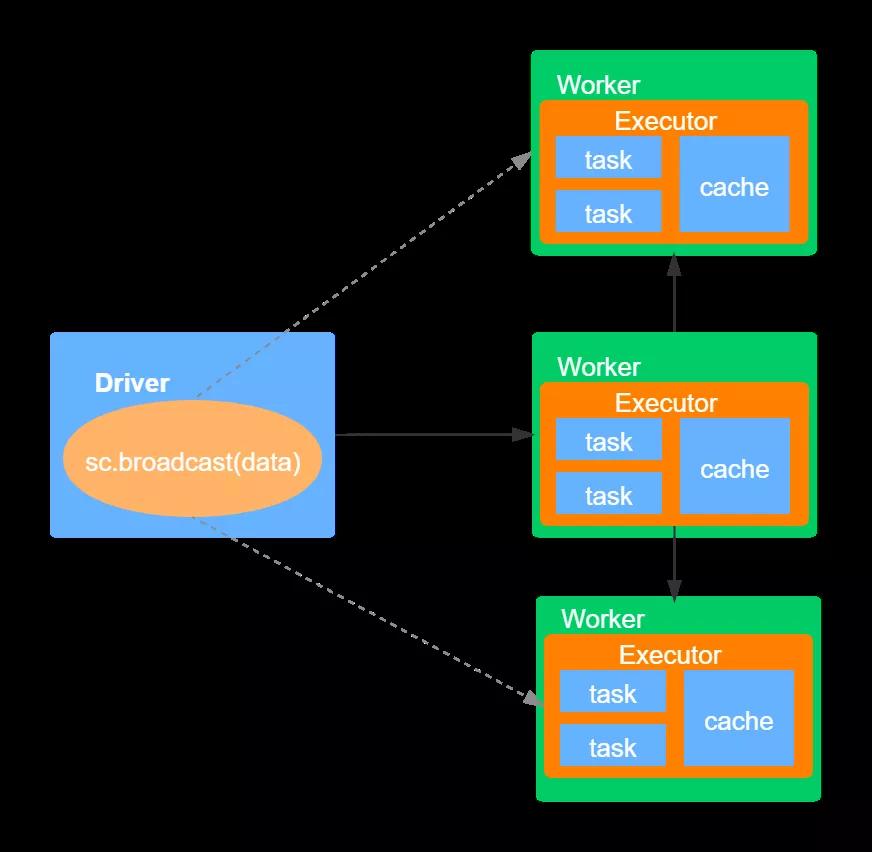
如上圖,首先Driver將序列化對象分割成小的數據庫,然后將這些數據塊存儲在Driver節點的BlockManager上。當ececutor中執行具體的task時,每個executor首先嘗試從自己所在節點的BlockManager提取數據,如果之前已經提取的該廣播變量的值,就直接使用它。如果沒有找到,則會向遠程的Driver或者其他的Executor中提取廣播變量的值,一旦獲取該值,就將其存儲在自己節點的BlockManager中。這種機制可以避免Driver端向多個executor發送數據而造成的性能瓶頸。
累加器
累加器(Accumulator)是Spark提供的另外一個共享變量,與廣播變量不同,累加器是可以被修改的,是可變的。每個transformation會將修改的累加器值傳輸到Driver節點,累加器可以實現一個累加的功能,類似于一個計數器。Spark本身支持數字類型的累加器,用戶也可以自定義累加器的類型。
寬依賴和窄依賴
RDD中不同的操作會使得不同RDD中的分區產不同的依賴,主要有兩種依賴:寬依賴和窄依賴。寬依賴是指一個父RDD的一個分區對應一個子RDD的多個分區,窄依賴是指一個父RDD的分區對應與一個子RDD的分區,或者多個父RDD的分區對應一個子RDD分區。
窄依賴會被劃分到同一個stage中,這樣可以以管道的形式迭代執行。寬依賴所依賴的分區一般有多個,所以需要跨節點傳輸數據。從容災方面看,兩種依賴的計算結果恢復的方式是不同的,窄依賴只需要恢復父RDD丟失的分區即可,而寬依賴則需要考慮恢復所有父RDD丟失的分區。
DAGScheduler會將Job的RDD劃分到不同的stage中,并構建一個stage的依賴關系,即DAG。這樣劃分的目的是既可以保障沒有依賴關系的stage可以并行執行,又可以保證存在依賴關系的stage順序執行。stage主要分為兩種類型,一種是ShuffleMapStage,另一種是ResultStage。其中ShuffleMapStage是屬于上游的stage,而ResulStage屬于最下游的stage,這意味著上游的stage先執行,最后執行ResultStage。
持久化
方式
在Spark中,RDD采用惰性求值的機制,每次遇到action操作,都會從頭開始執行計算。每次調用action操作,都會觸發一次從頭開始的計算。對于需要被重復使用的RDD,spark支持對其進行持久化,通過調用persist()或者cache()方法即可實現RDD的持計劃。通過持久化機制可以避免重復計算帶來的開銷。值得注意的是,當調用持久化的方法時,只是對該RDD標記為了持久化,需要等到第一次執行action操作之后,才會把計算結果進行持久化。持久化后的RDD將會被保留在計算節點的內存中被后面的行動操作重復使用。
Spark提供的兩個持久化方法的主要區別是:cache()方法默認使用的是內存級別,其底層調用的是persist()方法。
持久化級別的選擇
Spark提供的持久化存儲級別是在內存使用與CPU效率之間做權衡,通常推薦下面的選擇方式:
- 如果內存可以容納RDD,可以使用默認的持久化級別,即MEMORY_ONLY。這是CPU最有效率的選擇,可以使作用在RDD上的算子盡可能第快速執行。
- 如果內存不夠用,可以嘗試使用MEMORY_ONLY_SER,使用一個快速的序列化庫可以節省很多空間,比如 Kryo 。
tips:在一些shuffle算子中,比如reduceByKey,即便沒有顯性調用persist方法,Spark也會自動將中間結果進行持久化,這樣做的目的是避免在shuffle期間發生故障而造成重新計算整個輸入。即便如此,還是推薦對需要被重復使用的RDD進行持久化處理。
coalesce VS repartition
repartition算法對數據進行了shuffle操作,并創建了大小相等的數據分區。coalesce操作合并現有分區以避免shuffle,除此之外coalesce操作僅能用于減少分區,不能用于增加分區。
值得注意的是:使用coalesce在減少分區時,并沒有對所有數據進行了移動,僅僅是在原來分區的基礎之上進行了合并而已,所以效率較高,但是可能會引起數據傾斜。
綜合案例
一種數倉技術架構
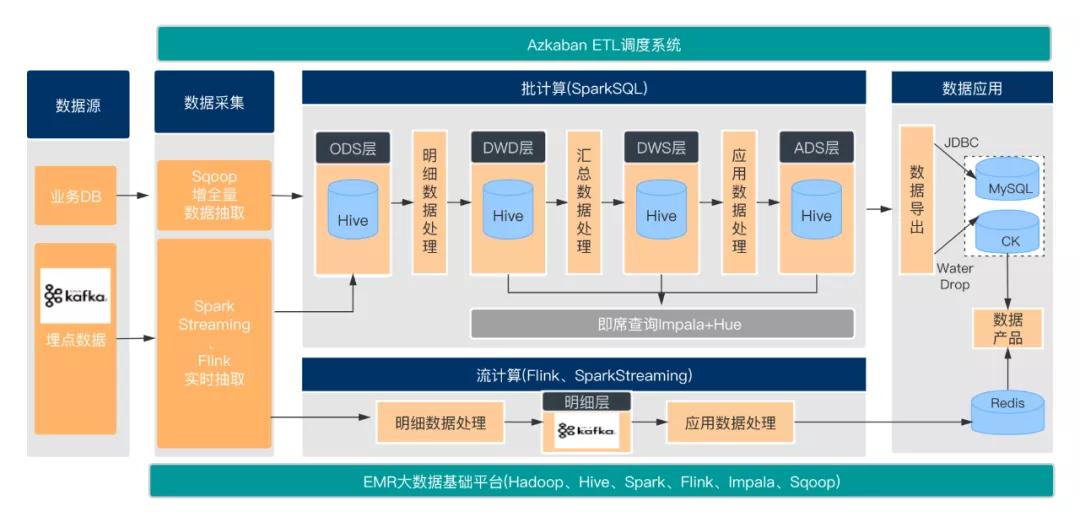
SparkStreaming實時同步
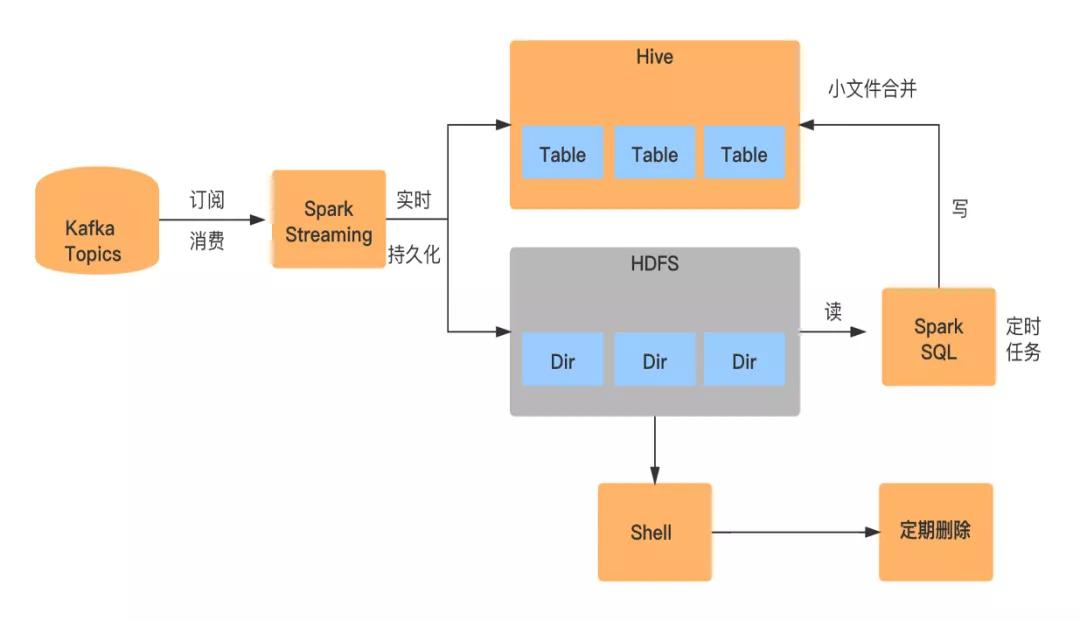
- 訂閱消費:
SparkStreaming消費kafka埋點數據
- 數據寫入:
將解析的數據同時寫入HDFS上的某個臨時目錄下及Hive表對應的分區目錄下
- 小文件合并:
由于是實時數據抽取,所以會生成大量的小文件,小文件的生成取決于SparkStreaming的Batch Interval,比如一分鐘一個batch,那么一分鐘就會生成一個小文件
基于SparkSQL的批處理
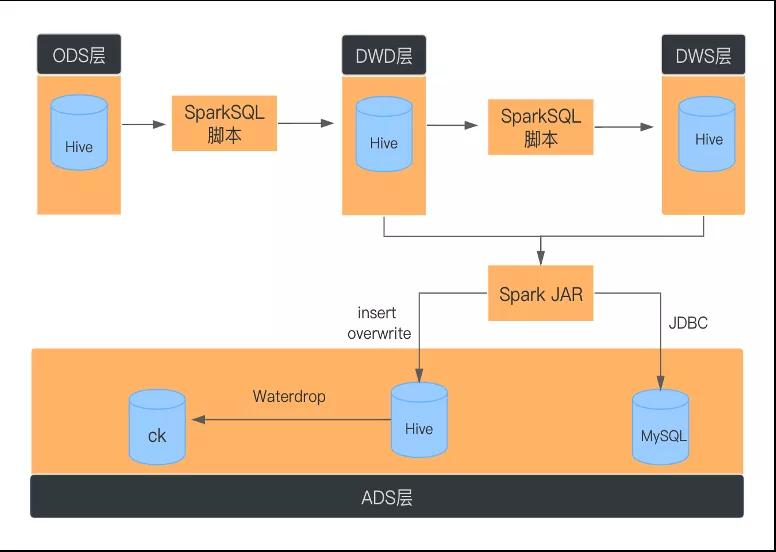
- ODS層到DWD層數據去重
SparkStreaming數據輸出是At Least Once,可能會存在數據重復。在ODS層到DWD層進行明細數據處理時,需要對數據使用row_number去重。
- JDBC寫入MySQL
數據量大時,需要對數據進行重分區,并且為DataSet分區級別建立連接,采用批量提交的方式。
- 使用DISTRIBUTE BY子句避免生成大量小文件
spark.sql.shuffle.partitions的默認值為200,會導致以下問題
- 對于較小的數據,200是一個過大的選擇,由于調度開銷,通常會導致處理速度變慢,同時會造成小文件的產生。
- 對于大數據集,200很小,無法有效利用集群中的資源
使用 DISTRIBUTE BY cast( rand * N as int) 這里的N是指具體最后落地生成多少個文件數。
手動維護offset至HBase
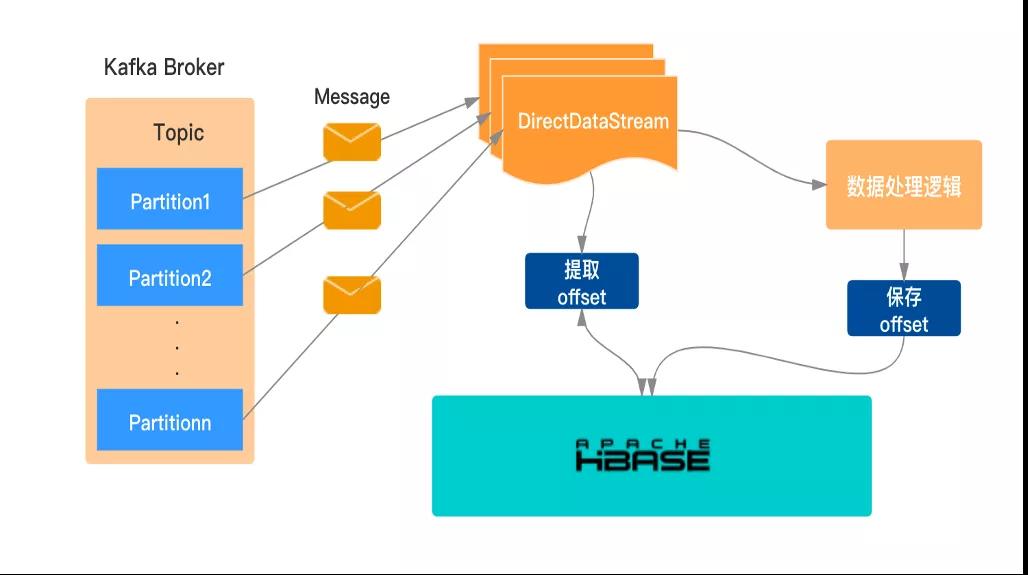
當作業發生故障或重啟時,要保障從當前的消費位點去處理數據,單純的依靠SparkStreaming本身的機制是不太理想,生產環境中通常借助手動管理來維護kafka的offset。
流應用監控告警
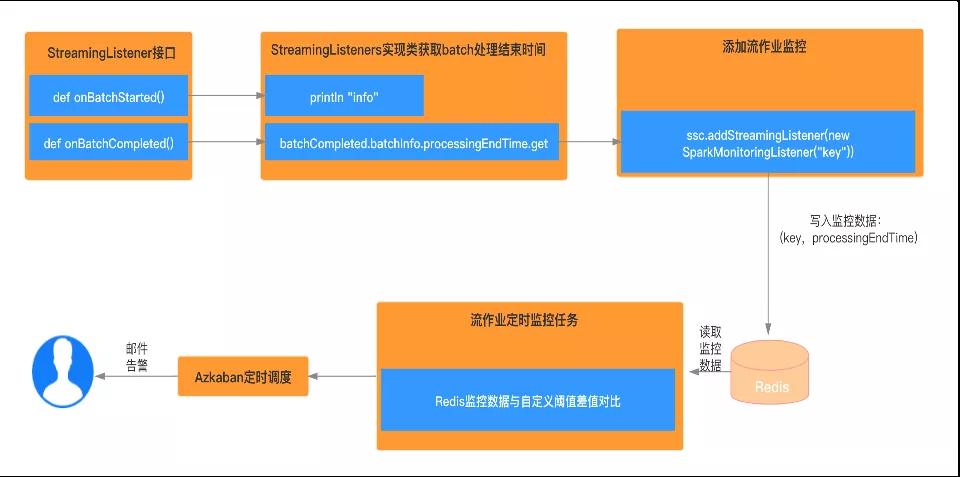
- 實現StreamingListener 接口,重寫onBatchStarted與onBatchCompleted方法
- 獲取batch執行完成之后的時間,寫入Redis,數據類型的key為自定義的具體字符串,value是batch處理完的結束時間
- 加入流作業監控
- 啟動定時任務監控上述步驟寫入redis的kv數據,一旦超出給定的閾值,則報錯,并發出告警通知
- 使用Azkaban定時調度該任務






















