













關于多寫入點數據庫集群的一些想法
在分布式數據庫系統領域, 多主(多寫入點, Leader-less)是一個非常誘人的特性, 因為客戶端可以隨機請求任何一個節點. 這種可隨機選擇訪問點(寫入點)的特性, 使得系統的高可用唾手可得, 因為當客戶端發現某個節點出故障時, 更換另一個節點重試就可以了, 只要系統沒有完全宕機, 幾次重試之后一定成功, 也就可以達到百分之百高可用。
傳統的 Basic Paxos 常常被誤認為是 Leader-less 的, 也即多主, 但 Basic Paxos 只能用于確定一個實例的共識, 真正落地還需要結合日志復制狀態機, 如果復制組(多節點)不指定 Leader 的話, 那么就會出現爭取同一個位置的日志的情況, 也就是在嘗試達成這個位置的日志的共識時出現活鎖. 這種多節點爭取同一個位置的情況, 在實踐上將導致系統不可用, 因為, 通常自稱采用 Paxos 的多副本數據庫系統, 依然要顯式指定 Leader, 并不是真正 Leader-less 的.
借鑒 vector 時鐘和多復制組的思路(如 Multi Raft Group), 是可以避免多主沖突的, 因為, 不同的節點作為各自組的 Leader, 分別寫入不同的日志序列, 也就完全沒有爭取同一個位置的日志而導致沖突了.
以一個3節點的集群來舉例, 通過預先配置強制指定各為其主, 結構為:
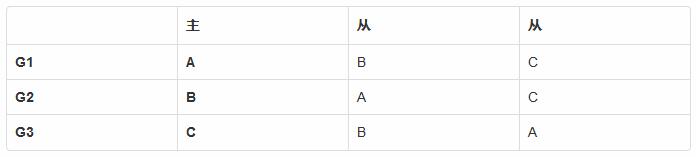
有復制組 G1, 成員節點是 {A, B, C} , 其中節點 A 是主. 類似的, 復制組 G2 和 G3 的主是 B, C. 當客戶端請求不同節點時, 將日志寫入不同復制組的日志序列, 因此不會產生沖突.
某一時刻, 所有節點的狀態是:
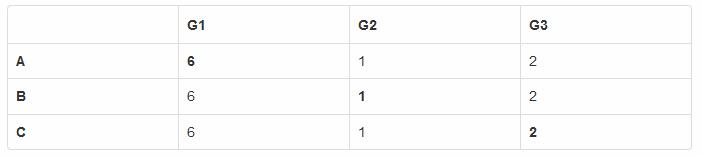
這個狀態表明, 復制組 G1 累計有 6 條日志, 復制組 G2 是 1 條, 復制組 G3 是 2 條.
到目前為此, 似乎一切順利, 寫入沒有沖突, 還能通過復制組形成多副本. 但是, 現實不是這樣的, 一個只能寫入的數據庫幾乎沒有任何用處, 數據庫必須支持讀取, 所以, 日志復制狀態機架構必須有狀態機, 也即這 3 條日志序列必須在所有節點 Apply 到各節點的狀態機實例中.
最簡單的方法是在各個節點上把 3 條日志序列合并成(Merge)一條日志序列, 通過某種算法保證所有節點上的合并結果一定是相同的, 例如按時間戳排序, 這樣才能保證狀態機一致(相同).
但是, 節點不能只依賴自己本地的 3 條日志序列合并, 在每一次合并時, 它需要獲取其它復制組的最新信息, 判斷自己本地的日志序列是不是足夠新. 自己作為 Leader 的那一條序列, 當然自己能確定, 但其它兩條不能, 需要詢問其它節點, 不能定死詢問 Leader, 因為需要容忍某個復制組的 Leader 宕機的情況.
所以, 針對其它復制組, 采取 Read Index 邏輯, 可以判斷是否最新. 并且在其它組 Leader 宕機的情況下, 將對應的日志序列從其它 Follower 那里補齊.
日志序列中可能包含非冪等的指令, 通過加入時間戳之后, 非冪等的指令可以變成冪等的.(需要文章論證). 以一個 key 為例, 狀態機中的 key-value 帶有初始化時間戳和最新更新時間戳 {reset_time, modify_time} . 當收到一條 incr 指令時, 指令中帶有時間戳, 與 key-value 中的 meta 信息比對之后, 就能知道 Apply 算法.
- if key.reset_time < op.time {
- value += 1
- } else {
- // 忽略在初始化之前的指令
- }
例如, 在 A 節點上針對 key 執行了 set 操作, 便會復位其 reset_time, 之后, 再收到其它節點的更早的 incr 指令時, 這個 incr 指令就不能修改狀態機了, 因為這個指令發生在復位之前.
各個節點的系統時鐘不同步沒關系, 因為一致性與系統時鐘沒有必然聯系(需要文章論證). 只要確保所有節點最終的結果是一致的(相同)的就行. 不要讓 A 節點先執行 set 再執行 incr, 而 B 節點先執行 incr 再執行 set 這種情況出現. 在這個例子中, 從上帝視角知道 incr 在 set 之前, 所以, A 節點先執行 set, 然后遇到 incr 指令時會忽略.
上面的時間戳比較要求不同的節點產生的時間戳不能相同, 可以把節點ID當作時間戳的最低位, 避免兩個時間戳相同.
對于 incr 操作, 初始化比較簡單, 但是, 對于 pop 這種非冪等性的操作, 并不是初始化, 很難解決. 本質上, 是一種回滾操作, 能實現, 但成本太大, 要討論起來真是夠多的.
不同的節點收到不是自己負責的日志序列的延遲不一定, 但是, 我們又不能等確保全部日志序列都收到之后再 Apply, 雖然等全部日志序列都到齊之后再 Apply 可以不需要回滾操作, 但等待行為不能容忍宕機(CAP 理論).
總結起來, 就是 沒有銀彈 . vector 時鐘看起來很美好, 但日志序列之間的相互依賴問題, 要么通過停止等待來解決, 要么通過回滾操作來解決, 否則無法保證多副本一致(相同). 但是, 某些操作的回滾成本太大.
注: 有一種技術叫 CRDT, 思想類似, 但是上面討論的問題依然存在.
考慮過這個問題:
- C 宕機, 但是它上面有一條日志還沒有復制到其它節點.
- A 和 B 各自合并日志序列之后 Apply 了, 兩者的狀態機一致, 沒問題.
這時, C 恢復, 那條日志得以復制出去, 這時, A 和 B 需要回滾, 然后重新合并, 再 Apply.
如果 C 在恢復之后, 給那條日志賦予新的時間戳, 那么也會有一種場景(C 宕機前日志已經復制出去了, 但它還沒知道結果), 同樣需要回滾, 因為別的節點可能已經 Apply 過那條日志了.













