













JVM深度剖析:一文詳解JVM是如何實現反射的?
反射是 Java 語言中一個相當重要的特性,它允許正在運行的 Java 程序觀測,甚至是修改程序的動態行為。
舉例來說,我們可以通過 Class 對象枚舉該類中的所有方法,我們還可以通過Method.setAccessible(位于 java.lang.reflect 包,該方法繼承自 AccessibleObject)繞過 Java 語言的訪問權限,在私有方法所在類之外的地方調用該方法。
反射在 Java 中的應用十分廣泛。開發人員日常接觸到的 Java 集成開發環境(IDE)便運用了這一功能:每當我們敲入點號時,IDE 便會根據點號前的內容,動態展示可以訪問的字段或者方法。
另一個日常應用則是 Java 調試器,它能夠在調試過程中枚舉某一對象所有字段的值。
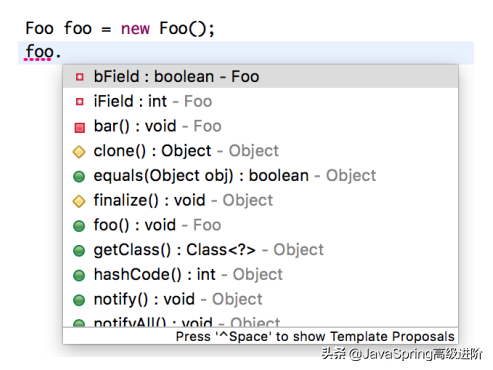
(圖中 eclipse 的自動提示使用了反射)
在 Web 開發中,我們經常能夠接觸到各種可配置的通用框架。為了保證框架的可擴展性,它們往往借助 Java 的反射機制,根據配置文件來加載不同的類。舉例來說,Spring 框架的依賴反轉(IoC),便是依賴于反射機制。
然而,我相信不少開發人員都嫌棄反射機制比較慢。甚至是甲骨文關于反射的教學網頁[1],也強調了反射性能開銷大的缺點。
反射調用的實現
首先,我們來看看方法的反射調用,也就是 Method.invoke,是怎么實現的。
- public final class Method extends Executable {
- ...
- public Object invoke(Object obj, Object... args) throws ... {
- ... //權限檢查
- MethodAccessor ma = methodAccessor;
- if (ma == null) {
- ma = acquireMethodAccessor();
- }
- return ma.invoke(obj, args);
- }
- }
如果你查閱 Method.invoke 的源代碼,那么你會發現,它實際上委派給MethodAccessor 來處理。MethodAccessor 是一個接口,它有兩個已有的具體實現:一個通過本地方法來實現反射調用,另一個則使用了委派模式。為了方便記憶,我便用“本地實現”和“委派實現”來指代這兩者。
每個 Method 實例的第一次反射調用都會生成一個委派實現,它所委派的具體實現便是一個本地實現。本地實現非常容易理解。當進入了 Java 虛擬機內部之后,我們便擁有了Method 實例所指向方法的具體地址。這時候,反射調用無非就是將傳入的參數準備好,然后調用進入目標方法。
- // v0版本
- import java.lang.reflect.Method;
- public class Test {
- public static void target(int i) {
- new Exception("#" + i).printStackTrace();
- }
- public static void main(String[] args) throws Exception {
- Class<?> klass = Class.forName("Test");
- Method method = klass.getMethod("target", int.class);
- method.invoke(null, 0);
- }
- }
- #不同版本的輸出略有不同,這里我使用了Java 10。
- $ java Test
- java.lang.Exception: #0
- at Test.target(Test.java:5)
- at java.base/jdk.internal.reflect.NativeMethodAccessorImpl .invoke0(Native Methoa t java.base/jdk.internal.reflect.NativeMethodAccessorImpl. .invoke(NativeMethodAt java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.i .invoke(Delegatin
- java.base/java.lang.reflect.Method.invoke(Method.java:564)
- t Test.main(Test.java:131
為了方便理解,我們可以打印一下反射調用到目標方法時的棧軌跡。在上面的 v0 版本代碼中,我們獲取了一個指向 Test.target 方法的 Method 對象,并且用它來進行反射調用。在 Test.target 中,我會打印出棧軌跡。
可以看到,反射調用先是調用了 Method.invoke,然后進入委派實現(DelegatingMethodAccessorImpl),再然后進入本地實現(NativeMethodAccessorImpl),最后到達目標方法。
這里你可能會疑問,為什么反射調用還要采取委派實現作為中間層?直接交給本地實現不可以么?
其實,Java 的反射調用機制還設立了另一種動態生成字節碼的實現(下稱動態實現),直接使用 invoke 指令來調用目標方法。之所以采用委派實現,便是為了能夠在本地實現以及動態實現中切換。
- //動態實現的偽代碼,這里只列舉了關鍵的調用邏輯,其實它還包括調用者檢測、參數檢測的字節碼。
- package jdk.internal.reflect;
- public class GeneratedMethodAccessor1 extends ... {
- @Overrides
- public Object invoke(Object obj, Object[] args) throws ... {
- Test.target((int) args[0]);
- return null;
- }
- }
動態實現和本地實現相比,其運行效率要快上 20 倍。這是因為動態實現無需經過 Java到 C++ 再到 Java 的切換,但由于生成字節碼十分耗時,僅調用一次的話,反而是本地實現要快上 3 到 4 倍。
考慮到許多反射調用僅會執行一次,Java 虛擬機設置了一個閾值 15(可以通過-Dsun.reflect.inflationThreshold= 來調整),當某個反射調用的調用次數在 15 之下時,采用本地實現;當達到 15 時,便開始動態生成字節碼,并將委派實現的委派對象切換至動態實現,這個過程我們稱之為 Inflation。
為了觀察這個過程,我將剛才的例子更改為下面的 v1 版本。它會將反射調用循環 20 次。
- // v1版本
- import java.lang.reflect.Method;
- public class Test {
- public static void target(int i) {
- new Exception("#" + i).printStackTrace();
- }
- public static void main(String[] args) throws Exception {
- Class<?> klass = Class.forName("Test");
- Method method = klass.getMethod("target", int.class);
- for (int i = 0; i < 20; i++) {
- method.invoke(null, i);
- }
- }
- }
- #使用-verbose:class打印加載的類
- $ java -verbose:class Test
- ...
- java.lang.Exception: #14
- at Test.target(Test.java:5)
- at java.base/jdk.internal.reflect.NativeMethodAccessorImpl .invoke0(Native Methoat java.base/jdk.internal.reflect.NativeMethodAccessorImpl .invoke(NativeMethodAat java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl .invoke(Delegatinat java.base/java.lang.reflect.Method.invoke(Method.java:564)
- at Test.main(Test.java:12)
- [0.158s][info][class,load] ...
- ...
- [0.160s][info][class,load] jdk.internal.reflect.GeneratedMethodAccessor1 source: __JVM_Djava.lang.Exception: #15
- at Test.target(Test.java:5)
- at java.base/jdk.internal.reflect.NativeMethodAccessorImpl .invoke0(Native Methodat java.base/jdk.internal.reflect.NativeMethodAccessorImpl .invoke(NativeMethodAcat java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl .invoke(Delegatingat java.base/java.lang.reflect.Method.invoke(Method.java:564)
- at Test.main(Test.java:12)
- java.lang.Exception: #16
- at Test.target(Test.java:5)
- at jdk.internal.reflect.GeneratedMethodAccessor1 .invoke(Unknown Source)
- at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl .invoke(Delegatingat java.base/java.lang.reflect.Method.invoke(Method.java:564)
- at Test.main(Test.java:12)
- ...
可以看到,在第 15 次(從 0 開始數)反射調用時,我們便觸發了動態實現的生成。這時候,Java 虛擬機額外加載了不少類。其中,最重要的當屬GeneratedMethodAccessor1(第 30 行)。并且,從第 16 次反射調用開始,我們便切換至這個剛剛生成的動態實現(第 40 行)。
反射調用的 Inflation 機制是可以通過參數(-Dsun.reflect.noInflation=true)來關閉的。這樣一來,在反射調用一開始便會直接生成動態實現,而不會使用委派實現或者本地實現。
反射調用的開銷
下面,我們便來拆解反射調用的性能開銷。
在剛才的例子中,我們先后進行了 Class.forName,Class.getMethod 以及Method.invoke 三個操作。其中,Class.forName 會調用本地方法,Class.getMethod則會遍歷該類的公有方法。如果沒有匹配到,它還將遍歷父類的公有方法。可想而知,這兩個操作都非常費時。
值得注意的是,以 getMethod 為代表的查找方法操作,會返回查找得到結果的一份拷貝。因此,我們應當避免在熱點代碼中使用返回 Method 數組的 getMethods 或者getDeclaredMethods 方法,以減少不必要的堆空間消耗。
在實踐中,我們往往會在應用程序中緩存 Class.forName 和 Class.getMethod 的結果。因此,下面我就只關注反射調用本身的性能開銷。
為了比較直接調用和反射調用的性能差距,我將前面的例子改為下面的 v2 版本。它會將反射調用循環二十億次。此外,它還將記錄下每跑一億次的時間。
我將取最后五個記錄的平均值,作為預熱后的峰值性能。(注:這種性能評估方式并不嚴謹,我會在專欄的第三部分介紹如何用 JMH 來測性能。)
在我這個老筆記本上,一億次直接調用耗費的時間大約在 120ms。這和不調用的時間是一致的。其原因在于這段代碼屬于熱循環,同樣會觸發即時編譯。并且,即時編譯會將對Test.target 的調用內聯進來,從而消除了調用的開銷。
- // v2版本
- mport java.lang.reflect.Method;
- public class Test {
- public static void target(int i) {
- //空方法
- }
- public static void main(String[] args) throws Exception {
- Class<?> klass = Class.forName("Test");
- Method method = klass.getMethod("target", int.class);
- long current = System.currentTimeMillis();
- for (int i = 1; i <= 2_000_000_000; i++) {
- if (i % 100_000_000 == 0) {
- long temp = System.currentTimeMillis();
- System.out.println(temp - current);
- current = temp;
- }
- method.invoke(null, 128);
- }
- }
- }
下面我將以 120ms 作為基準,來比較反射調用的性能開銷。
由于目標方法 Test.target 接收一個 int 類型的參數,因此我傳入 128 作為反射調用的參數,測得的結果約為基準的 2.7 倍。我們暫且不管這個數字是高是低,先來看看在反射調用之前字節碼都做了什么。
- aload_2 //加載Method對象
- aconst_null //反射調用的第一個參數null
- iconst_1
- anewarray Object //生成一個長度為1的Object數組
- dup
- iconst_0
- sipush 128
- invokestatic Integer.valueOf //將128自動裝箱成Integer73: aastore //存入Object數組中
- invokevirtual Method.invoke //反射調用
這里我截取了循環中反射調用編譯而成的字節碼。可以看到,這段字節碼除了反射調用外,還額外做了兩個操作。
- 由于 Method.invoke 是一個變長參數方法,在字節碼層面它的最后一個參數會是Object 數組(感興趣的同學私下可以用 javap 查看)。Java 編譯器會在方法調用處生成一個長度為傳入參數數量的 Object 數組,并將傳入參數一一存儲進該數組中。
- 由于 Object 數組不能存儲基本類型,Java 編譯器會對傳入的基本類型參數進行自動裝箱。
這兩個操作除了帶來性能開銷外,還可能占用堆內存,使得 GC 更加頻繁。(如果你感興趣的話,可以用虛擬機參數 -XX:+PrintGC 試試。)那么,如何消除這部分開銷呢?
關于第二個自動裝箱,Java 緩存了 [-128, 127] 中所有整數所對應的 Integer 對象。當需要自動裝箱的整數在這個范圍之內時,便返回緩存的 Integer,否則需要新建一個 Integer對象。
因此,我們可以將這個緩存的范圍擴大至覆蓋 128(對應參數-Djava.lang.Integer.IntegerCache.high=128),便可以避免需要新建 Integer 對象的場景。
或者,我們可以在循環外緩存 128 自動裝箱得到的 Integer 對象,并且直接傳入反射調用中。這兩種方法測得的結果差不多,約為基準的 1.8 倍。
現在我們再回來看看第一個因變長參數而自動生成的 Object 數組。既然每個反射調用對應的參數個數是固定的,那么我們可以選擇在循環外新建一個 Object 數組,設置好參數,并直接交給反射調用。改好的代碼可以參照文稿中的 v3 版本。
- // v3版本
- import java.lang.reflect.Method;
- public class Test {
- public static void target(int i) {
- //空方法
- }
- public static void main(String[] args) throws Exception {
- Class<?> klass = Class.forName("Test");
- Method method = klass.getMethod("target", int.class);
- Object[] arg = new Object[1];
- //在循環外構造參數數組
- arg[0] = 128;
- long current = System.currentTimeMillis();
- for (int i = 1; i <= 2_000_000_000; i++) {
- if (i % 100_000_000 == 0) {
- long temp = System.currentTimeMillis();
- System.out.println(temp - current);
- current = temp;
- }
- method.invoke(null, arg);
- }
- }
- }
測得的結果反而更糟糕了,為基準的 2.9 倍。這是為什么呢?
如果你在上一步解決了自動裝箱之后查看運行時的 GC 狀況,你會發現這段程序并不會觸發 GC。其原因在于,原本的反射調用被內聯了,從而使得即時編譯器中的逃逸分析將原本新建的 Object 數組判定為不逃逸的對象。
如果一個對象不逃逸,那么即時編譯器可以選擇棧分配甚至是虛擬分配,也就是不占用堆空間。具體我會在本專欄的第二部分詳細解釋。
如果在循環外新建數組,即時編譯器無法確定這個數組會不會中途被更改,因此無法優化掉訪問數組的操作,可謂是得不償失。
到目前為止,我們的最好記錄是 1.8 倍。那能不能再進一步提升呢?
剛才我曾提到,可以關閉反射調用的 Inflation 機制,從而取消委派實現,并且直接使用動態實現。此外,每次反射調用都會檢查目標方法的權限,而這個檢查同樣可以在 Java 代碼里關閉,在關閉了這兩項機制之后,也就得到了我們的 v4 版本,它測得的結果約為基準的1.3 倍。
- // v4版本
- import java.lang.reflect.Method;
- //在運行指令中添加如下兩個虛擬機參數:
- // -Djava.lang.Integer.IntegerCache.high=128
- // -Dsun.reflect.noInflation=true
- public class Test {
- public static void target(int i) {
- //空方法
- }
- public static void main(String[] args) throws Exception {
- Class<?> klass = Class.forName("Test");
- Method method = klass.getMethod("target", int.class);
- method.setAccessible(true);
- //關閉權限檢查
- long current = System.currentTimeMillis();
- for (int i = 1; i <= 2_000_000_000; i++) {
- if (i % 100_000_000 == 0) {
- long temp = System.currentTimeMillis();
- System.out.println(temp - current);
- current = temp;
- }
- method.invoke(null, 128);
- }
- }
- }
到這里,我們基本上把反射調用的水分都榨干了。接下來,我來把反射調用的性能開銷給提回去。
首先,在這個例子中,之所以反射調用能夠變得這么快,主要是因為即時編譯器中的方法內聯。在關閉了 Inflation 的情況下,內聯的瓶頸在于 Method.invoke 方法中對MethodAccessor.invoke 方法的調用。
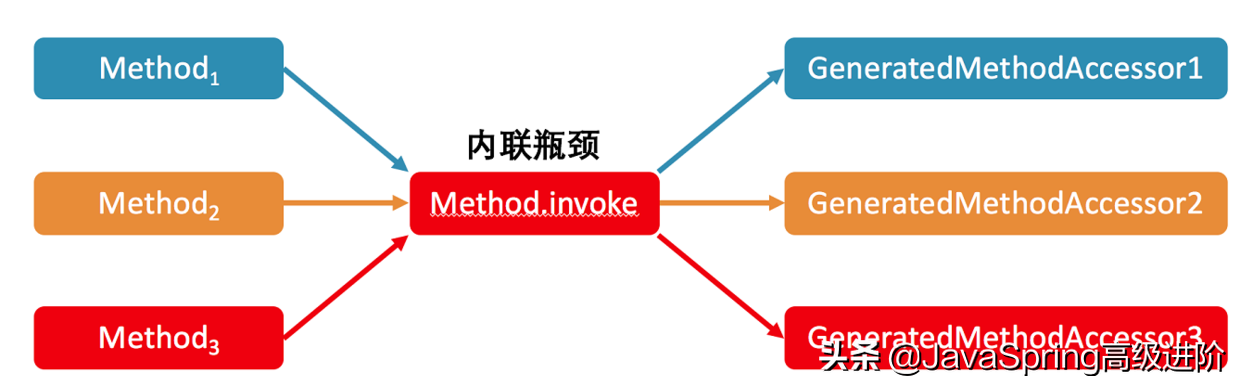
我會在后面的文章中介紹方法內聯的具體實現,這里先說個結論:在生產環境中,我們往往擁有多個不同的反射調用,對應多個 GeneratedMethodAccessor,也就是動態實現。
由于 Java 虛擬機的關于上述調用點的類型 profile(注:對于 invokevirtual 或者invokeinterface,Java 虛擬機會記錄下調用者的具體類型,我們稱之為類型 profile)無法同時記錄這么多個類,因此可能造成所測試的反射調用沒有被內聯的情況。
- // v5版本
- import java.lang.reflect.Method;
- public class Test {
- public static void target(int i) {
- //空方法
- }
- public static void main(String[] args) throws Exception {
- Class<?> klass = Class.forName("Test");
- Method method = klass.getMethod("target", int.class);
- method.setAccessible(true);
- //關閉權限檢查
- polluteProfile();
- long current = System.currentTimeMillis();
- for (int i = 1; i <= 2_000_000_000; i++) {
- if (i % 100_000_000 == 0) {
- long temp = System.currentTimeMillis();
- System.out.println(temp - current);
- current = temp;
- }
- method.invoke(null, 128);
- }
- }
- public static void polluteProfile() throws Exception {
- Method method1 = Test.class.getMethod("target1", int.class);
- Method method2 = Test.class.getMethod("target2", int.class);
- for (int i = 0; i < 2000; i++) {
- method1.invoke(null, 0);
- method2.invoke(null, 0);
- }
- }
- public static void target1(int i) {
- }
- public static void target2(int i) {
- }
- }
在上面的 v5 版本中,我在測試循環之前調用了 polluteProfile 的方法。該方法將反射調用另外兩個方法,并且循環上 2000 遍。
而測試循環則保持不變。測得的結果約為基準的 6.7 倍。也就是說,只要誤擾了Method.invoke 方法的類型 profile,性能開銷便會從 1.3 倍上升至 6.7 倍。
之所以這么慢,除了沒有內聯之外,另外一個原因是逃逸分析不再起效。這時候,我們便可以采用剛才 v3 版本中的解決方案,在循環外構造參數數組,并直接傳遞給反射調用。這樣子測得的結果約為基準的 5.2 倍。
除此之外,我們還可以提高 Java 虛擬機關于每個調用能夠記錄的類型數目(對應虛擬機參數 -XX:TypeProfileWidth,默認值為 2,這里設置為 3)。最終測得的結果約為基準的2.8 倍,盡管它和原本的 1.3 倍還有一定的差距,但總算是比 6.7 倍好多了。
總結與實踐
在默認情況下,方法的反射調用為委派實現,委派給本地實現來進行方法調用。在調用超過15 次之后,委派實現便會將委派對象切換至動態實現。這個動態實現的字節碼是自動生成的,它將直接使用 invoke 指令來調用目標方法。
方法的反射調用會帶來不少性能開銷,原因主要有三個:變長參數方法導致的 Object 數組,基本類型的自動裝箱、拆箱,還有最重要的方法內聯。
本文的實踐環節,你可以將最后一段代碼中 polluteProfile 方法的兩個 Method 對象,都改成獲取名字為“target”的方法。請問這兩個獲得的 Method 對象是同一個嗎(==)?他們 equal 嗎(.equals(…))?對我們的運行結果有什么影響?
- import java.lang.reflect.Method;
- public class Test {
- public static void target(int i) {
- //空方法
- }
- public static void main(String[] args) throws Exception {
- Class<?> klass = Class.forName("Test");
- Method method = klass.getMethod("target", int.class);
- method.setAccessible(true);
- //關閉權限檢查
- polluteProfile();
- long current = System.currentTimeMillis();
- for (int i = 1; i <= 2_000_000_000; i++) {
- if (i % 100_000_000 == 0) {
- long temp = System.currentTimeMillis();
- System.out.println(temp - current);
- current = temp;
- }
- method.invoke(null, 128);
- }
- }
- public static void polluteProfile() throws Exception {
- Method method1 = Test.class.getMethod("target", int.class);
- Method method2 = Test.class.getMethod("target", int.class);
- for (int i = 0; i < 2000; i++) {
- method1.invoke(null, 0);
- method2.invoke(null, 0);
- }
- }
- public static void target1(int i) {
- }
- public static void target2(int i) {
- }
- }

















