HDFS 底層交互原理,看這篇就夠了
前言
大家好,我是林哥!
HDFS全稱是 Hadoop Distribute File System,是 Hadoop最重要的組件之一,也被稱為分步式存儲之王。本文主要從 HDFS 高可用架構組成、HDFS 讀寫流程、如何保證可用性以及高頻面試題出發,提高大家對 HDFS 的認識,掌握一些高頻的 HDFS 面試題。本篇文章概覽如下圖:
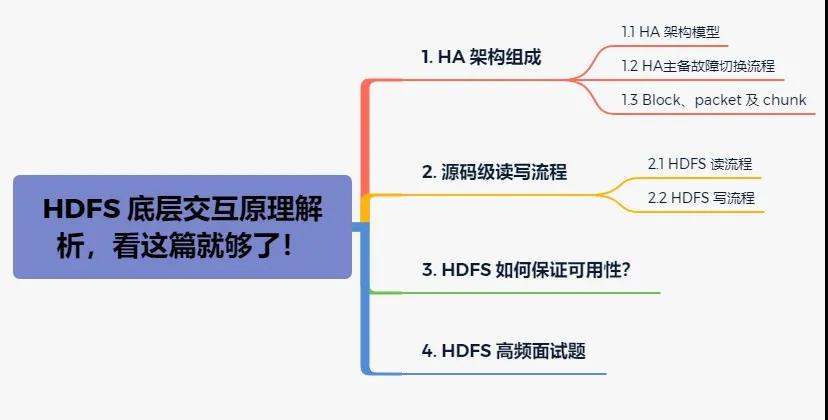
本篇文章概覽
1.HA 架構組成
1.1HA架構模型
在 HDFS 1.X 時,NameNode 是 HDFS 集群中可能發生單點故障的節點,集群中只有一個 NameNode,一旦 NameNode 宕機,整個集群將處于不可用的狀態。
在 HDFS 2.X 時,HDFS 提出了高可用(High Availability, HA)的方案,解決了 HDFS 1.X 時的單點問題。在一個 HA 集群中,會配置兩個 NameNode ,一個是 Active NameNode(主),一個是 Stadby NameNode(備)。主節點負責執行所有修改命名空間的操作,備節點則執行同步操作,以保證與主節點命名空間的一致性。HA 架構模型如下圖所示:
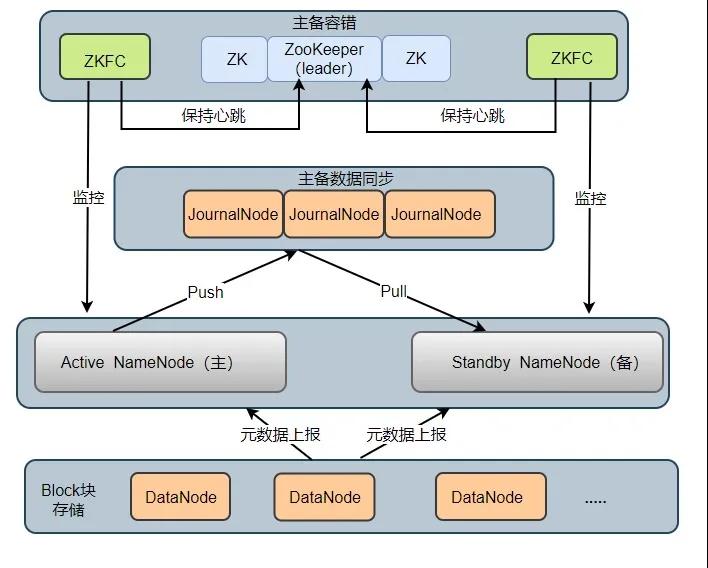
HA 架構組成2
HA 集群中所包含的進程的職責各不相同。為了使得主節點和備用節點的狀態一致,采用了 Quorum Journal Manger (QJM)方案解決了主備節點共享存儲問題,如圖 JournalNode 進程,下面依次介紹各個進程在架構中所起的作用:
- Active NameNode:它負責執行整個文件系統中命名空間的所有操作;維護著數據的元數據,包括文件名、副本數、文件的 BlockId 以及 Block 塊所對應的節點信息;另外還接受 Client 端讀寫請求和 DataNode 匯報 Block 信息。
- Standby NameNode:它是 Active NameNode 的備用節點,一旦主節點宕機,備用節點會切換成主節點對外提供服務。它主要是監聽 JournalNode Cluster 上 editlog 變化,以保證當前命名空間盡可能的與主節點同步。任意時刻,HA 集群只有一臺 Active NameNode,另一個節點為 Standby NameNode。
- JournalNode Cluster: 用于主備節點間共享 editlog 日志文件的共享存儲系統。負責存儲 editlog 日志文件, 當 Active NameNode 執行了修改命名空間的操作時,它會定期將執行的操作記錄在 editlog 中,并寫入 JournalNode Cluster 中。Standby NameNode 會一直監聽 JournalNode Cluster 上 editlog 的變化,如果發現 editlog 有改動,備用節點會讀取 JournalNode 上的 editlog 并與自己當前的命名空間合并,從而實現了主備節點的數據一致性。
注意:QJM 方案是基于 Paxos 算法實現的,集群由 2N + 1 JouranlNode 進程組成,最多可以容忍 N 臺 JournalNode 宕機,宕機數大于 N 臺,這個算法就失效了!
- ZKFailoverController: ZKFC 以獨立進程運行,每個 ZKFC 都監控自己負責的 NameNode,它可以實現 NameNode 自動故障切換:即當主節點異常,監控主節點的 ZKFC 則會斷開與 ZooKeeper 的連接,釋放分步式鎖,監控備用節點的 ZKFC 進程會去獲取鎖,同時把備用 NameNode 切換成 主 NameNode。
- ZooKeeper: 為 ZKFC 進程實現自動故障轉移提供統一協調服務。通過 ZooKeeper 中 Watcher 監聽機制,通知 ZKFC 異常NameNode 下線;保證同一時刻只有一個主節點。
- DataNode: DataNode 是實際存儲文件 Block 塊的地方,一個 Block 塊包含兩個文件:一個是數據本身,一個是元數據(數據塊長度、塊數據的校驗和、以及時間戳),DataNode 啟動后會向 NameNode 注冊,每 6 小時同時向主備兩個 NameNode 上報所有的塊信息,每 3 秒同時向主備兩個 NameNode 發送一次心跳。
DataNode 向 NameNode 匯報當前塊信息的時間間隔,默認 6 小時,其配置參數名如下:
- <property>
- <name>dfs.blockreport.intervalMsec</name>
- <value>21600000</value>
- <description>Determines block reporting interval in
- milliseconds.</description>
- </property>
1.2HA主備故障切換流程
HA 集群剛啟動時,兩個 NameNode 節點狀態均為 Standby,之后兩個 NameNode 節點啟動 ZKFC 進程后會去 ZooKeeper 集群搶占分步式鎖,成功獲取分步式鎖,ZooKeeper 會創建一個臨時節點,成功搶占分步式鎖的 NameNode 會成為 Active NameNode,ZKFC 便會實時監控自己的 NameNode。
HDFS 提供了兩種 HA 狀態切換方式:一種是管理員手動通過DFSHAAdmin -faieover執行狀態切換;另一種則是自動切換。下面分別從兩種情況分析故障的切換流程:
1.主 NameNdoe 宕機后,備用 NameNode 如何升級為主節點?
當主 NameNode 宕機后,對應的 ZKFC 進程檢測到 NameNode 狀態,便向 ZooKeeper 發生刪除鎖的命令,鎖刪除后,則觸發一個事件回調備用 NameNode 上的 ZKFC
ZKFC 得到消息后先去 ZooKeeper 爭奪創建鎖,鎖創建完成后會檢測原先的主 NameNode 是否真的掛掉(有可能由于網絡延遲,心跳延遲),掛掉則升級備用 NameNode 為主節點,沒掛掉則將原先的主節點降級為備用節點,將自己對應的 NameNode 升級為主節點。
2.主 NameNode 上的 ZKFC 進程掛掉,主 NameNode 沒掛,如何切換?
ZKFC 掛掉后,ZKFC 和 ZooKeeper 之間 TCP 鏈接會隨之斷開,session 也會隨之消失,鎖被刪除,觸發一個事件回調備用 NameNode ZKFC,ZKFC 得到消息后會先去 ZooKeeper 爭奪創建鎖,鎖創建完成后也會檢測原先的主 NameNode 是否真的掛掉,掛掉則升級 備用 NameNode 為主節點,沒掛掉則將主節點降級為備用節點,將自己對應的 NameNode 升級為主節點。
1.3Block、packet及chunk 概念
在 HDFS 中,文件存儲是按照數據塊(Block)為單位進行存儲的,在讀寫數據時,DFSOutputStream使用 Packet 類來封裝一個數據包。每個 Packet 包含了若干個 chunk 和對應的 checksum。
- Block: HDFS 上的文件都是分塊存儲的,即把一個文件物理劃分為一個 Block 塊存儲。Hadoop 2.X/3.X 默認塊大小為 128 M,1.X 為 64M.
- Packet: 是 Client 端向 DataNode 或 DataNode 的 Pipline 之間傳輸數據的基本單位,默認 64 KB
- Chunk: Chunk 是最小的單位,它是 Client 向 DataNode 或 DataNode PipLine 之間進行數據校驗的基本單位,默認 512 Byte ,因為用作校驗,所以每個 Chunk 需要帶有 4 Byte 的校驗位,實際上每個 Chunk 寫入 Packtet 的大小為 516 Byte。
2.源碼級讀寫流程
2.1HDFS 讀流程
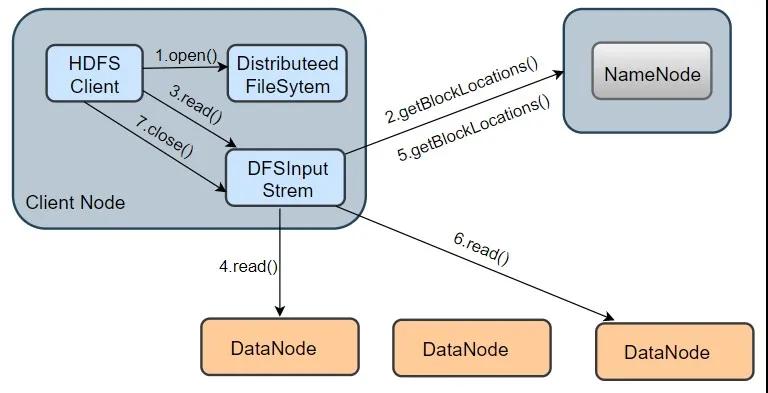
HDFS讀流程
我們以從 HDFS 讀取一個 information.txt 文件為例,其讀取流程如上圖所示,分為以下幾個步驟:
1.打開 information.txt 文件:首先客戶端調用 DistributedFileSystem.open() 方法打開文件,這個方法在底層會調用DFSclient.open() 方法,該方法會返回一個 HdfsDataInputStream 對象用于讀取數據塊。但實際上真正讀取數據的是 DFSInputStream ,而 HdfsDataInputStream 是 DFSInputStream 的裝飾類(new HdfsDataInputStream(DFSInputStream))。
2.從 NameNode 獲取存儲 information.txt 文件數據塊的 DataNode 地址:即獲取組成 information.txt block 塊信息。在構造輸出流 DFSInputStream 時,會通過調用 getBlockLocations() 方法向 NameNode 節點獲取組成 information.txt 的 block 的位置信息,并且 block 的位置信息是按照與客戶端的距離遠近排好序。
3.連接 DataNode 讀取數據塊: 客戶端通過調用 DFSInputStream.read() 方法,連接到離客戶端最近的一個 DataNode 讀取 Block 塊,數據會以數據包(packet)為單位從 DataNode 通過流式接口傳到客戶端,直到一個數據塊讀取完成;DFSInputStream會再次調用 getBlockLocations() 方法,獲取下一個最優節點上的數據塊位置。
4.直到所有文件讀取完成,調用 close() 方法,關閉輸入流,釋放資源。
從上述流程可知,整個過程最主要涉及到 open()、read()兩個方法(其它方法都是在這兩個方法的調用鏈中調用,如getBlockLocations()),下面依次介紹這2個方法的實現。
注:本文是以 hadoop-3.1.3 源碼為基礎!
- open()方法
事實上,在調用 DistributedFileSystem.open()方法時,底層調用的是 DFSClient.open()方法打開文件,并構造 DFSInputStream 輸入流對象。
- public DFSInputStream open(String src, int buffersize, boolean verifyChecksum)
- throws IOException {
- //檢查DFSClicent 的運行狀況
- checkOpen();
- // 從 namenode 獲取 block 位置信息,并存到 LocatedBlocks 對象中,最終傳給 DFSInputStream 的構造方法
- try (TraceScope ignored = newPathTraceScope("newDFSInputStream", src)) {
- LocatedBlocks locatedBlocks = getLocatedBlocks(src, 0);
- //調用 openInternal 方法,獲取輸入流
- return openInternal(locatedBlocks, src, verifyChecksum);
- }
- }
整個 open()方法分為兩部分:
第一部分是,調用 checkOpen()方法檢查 DFSClient 的運行狀況,調用getLocateBlocks()方法,獲取 block 的位置消息
第二部分是,調用openInternal()方法,獲取輸入流。
- openInternal( )方法
- private DFSInputStream openInternal(LocatedBlocks locatedBlocks, String src,
- boolean verifyChecksum) throws IOException {
- if (locatedBlocks != null) {
- //獲取糾刪碼策略,糾刪碼是 Hadoop 3.x 的新特性,默認不啟用糾刪碼策略
- ErasureCodingPolicy ecPolicy = locatedBlocks.getErasureCodingPolicy();
- if (ecPolicy != null) {
- //如果用戶指定了糾刪碼策略,將返回一個 DFSStripedInputStream 對象
- //DFSStripedInputStream 會將數據邏輯字節范圍的請求轉換為存儲在 DataNode 上的內部塊
- return new DFSStripedInputStream(this, src, verifyChecksum, ecPolicy,
- locatedBlocks);
- }
- //如果未指定糾刪碼策略,調用 DFSInputStream 的構造方法,并且返回該 DFSInputStream 的對象
- return new DFSInputStream(this, src, verifyChecksum, locatedBlocks);
- } else {
- throw new IOException("Cannot open filename " + src);
- }
- }
- DFSInputStream 構造方法
- DFSInputStream(DFSClient dfsClient, String src, boolean verifyChecksum,
- LocatedBlocks locatedBlocks) throws IOException {
- this.dfsClient = dfsClient;
- this.verifyChecksum = verifyChecksum;
- this.src = src;
- synchronized (infoLock) {
- this.cachingStrategy = dfsClient.getDefaultReadCachingStrategy();
- }
- this.locatedBlocks = locatedBlocks;
- //調用 openInfo 方法,參數:refreshLocatedBlocks,是否要更新 locateBlocks 屬性。
- openInfo(false);
- }
構造方法做了2件事:
第一部分是初始化 DFSInputStream 屬性,其中 verifyChecksum 含義是:讀取數據時是否進行校驗,cachingStrategy,指的是緩存策略。
第二部分,調用 openInfo()方法。
思考:為甚么要更新最后一個數據塊長度?
因為可能會有這種情況出現,當客戶端在讀取文件時,最后一個文件塊可能還在構建的狀態(正在被寫入),Datanode 還未上報最后一個文件塊,那么 namenode 所保存的數據塊長度有可能小于 Datanode實際存儲的數據塊長度,所以需要與 Datanode 通信以確認最后一個數據塊的真實長度。
獲取到 DFSInputStream 流對象后,并且得到了文件的所有 Block 塊的位置信息,接下來調用read()方法,從 DataNode 讀取數據塊。
注:在openInfo() 方法
在openInfp()中,會從 namenode 獲取當前正在讀取文件的最后一個數據塊的長度 lastBlockBeingWrittenLength,如果返回的最后一個數據塊的長度為 -1 ,這是一種特殊情況:即集群剛重啟,DataNode 可能還沒有向 NN 進行完整的數據塊匯報,這時部分數據塊位置信息還獲取不到,也獲取不到這些塊的長度,則默認會重試 3 次,默認每次等待 4 秒,重新去獲取文件對應的數據塊的位置信息以及最后數據塊長度;如果最后一個數據塊的長度不為 -1,則表明,最后一個數據塊已經是完整狀態。
- read()方法
- public synchronized int read(@Nonnull final byte buf[], int off, int len)
- throws IOException {
- //驗證輸入的參數是否可用
- validatePositionedReadArgs(pos, buf, off, len);
- if (len == 0) {
- return 0;
- }
- //構造字節數組作為容器
- ReaderStrategy byteArrayReader =
- new ByteArrayStrategy(buf, off, len, readStatistics, dfsClient);
- //調用 readWithStrategy()方法讀取數據
- return readWithStrategy(byteArrayReader);
- }
當用戶代碼調用read()方法時,其底層調用的是 DFSInputStream.read()方法。該方法從輸入流的 off 位置開始讀取,讀取 len 個字節,然后存入 buf 字節數組中。源碼中構造了一個 ByteArrayStrategy 對象,該對象封裝了 5 個屬性,分別是:字節數組 buf,讀取到的字節存入該字節數組;off,讀取的偏移量;len,將要讀取的目標長度;readStatistics,統計計數器,客戶端。最后通過調用 readWithStrategy()方法去讀取文件數據塊的數據。
總結:HDFS 讀取一個文件,調用流程如下:(中間涉及到的部分方法未列出)
usercode 調用 open() ---> DistributedFileSystem.open() ---> DFSClient.open() ---> 返回一個 DFSInputStream 對象給 DistributedFileSystem ---> new hdfsDataInputStream(DFSInputStream) 并返回給用戶;
usercode 調用 read() ---> 底層DFSIputStream.read() ---> readWithStrategy(bytArrayReader)
2.2HDFS 寫流程
介紹完 HDFS 讀的流程,接下來看看一個文件的寫操作的實現。從下圖中可以看出,HDFS 寫流程涉及的方法比較多,過程也比較復雜。
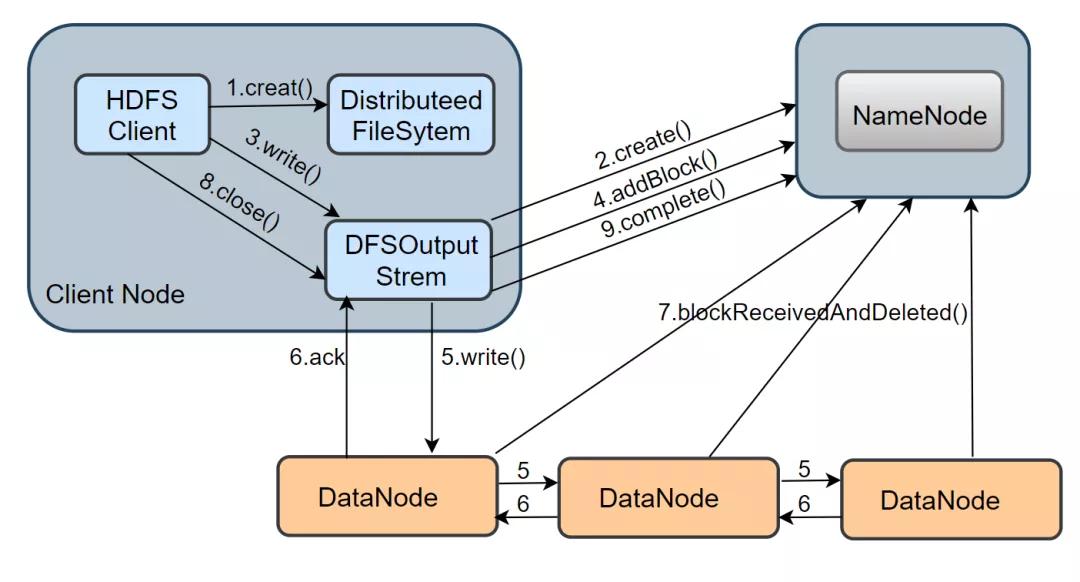
1.在 namenode 創建文件: 當 client 寫一個新文件時,首先會調用 DistributeedFileSytem.creat() 方法,DistributeFileSystem 是客戶端創建的一個對象,在收到 creat 命令之后,DistributeFileSystem 通過 RPC 與 NameNode 通信,讓它在文件系統的 namespace 創建一個獨立的新文件;namenode 會先確認文件是否存在以及客戶端是否有權限,確認成功后,會返回一個 HdfsDataOutputStream 對象,與讀流程類似,這個對象底層包裝了一個 DFSOutputStream 對象,它才是寫數據的真正執行者。
2.建立數據流 pipeline 管道: 客戶端得到一個輸出流對象,還需要通過調用 ClientProtocol.addBlock()向 namenode 申請新的空數據塊,addBlock( ) 會返回一個 LocateBlock 對象,該對象保存了可寫入的 DataNode 的信息,并構成一個 pipeline,默認是有三個 DataNode 組成。
3.通過數據流管道寫數據: 當 DFSOutputStream調用 write()方法把數據寫入時,數據會先被緩存在一個緩沖區中,寫入的數據會被切分成多個數據包,每當達到一個數據包長度(默認65536字節)時,
DFSOutputStream會構造一個 Packet 對象保存這個要發送的數據包;新構造的 Packet 對象會被放到 DFSOutputStream維護的 dataQueue 隊列中,DataStreamer 線程會從 dataQueue 隊列中取出 Packet 對象,通過底層 IO 流發送到 pipeline 中的第一個 DataNode,然后繼續將所有的包轉到第二個 DataNode 中,以此類推。發送完畢后,
這個 Packet 會被移出 dataQueue,放入 DFSOutputStream 維護的確認隊列 ackQueue 中,該隊列等待下游 DataNode 的寫入確認。當一個包已經被 pipeline 中所有的 DataNode 確認了寫入磁盤成功,這個數據包才會從確認隊列中移除。
4.關閉輸入流并提交文件: 當客戶端完成了整個文件中所有的數據塊的寫操作之后,會調用 close() 方法關閉輸出流,客戶端還會調用 ClientProtoclo.complete( ) 方法通知 NameNode 提交這個文件中的所有數據塊,
NameNode 還會確認該文件的備份數是否滿足要求。對于 DataNode 而言,它會調用 blockReceivedAndDelete() 方法向 NameNode 匯報,NameNode 會更新內存中的數據塊與數據節點的對應關系。
從上述流程來看,整個寫流程主要涉及到了 creat()、write()這些方法,下面著重介紹下這兩個方法的實現。當調用 DistributeedFileSytem.creat() 方法時,其底層調用的其實是 DFSClient.create()方法,其源碼如下:
- create( )方法
- public DFSOutputStream create(String src, FsPermission permission,
- EnumSet<CreateFlag> flag, boolean createParent,
- short replication,long blockSize,
- Progressable progress, int buffersize,
- ChecksumOpt checksumOpt,
- InetSocketAddress[] favoredNodes,
- String ecPolicyName) throws IOException {
- //檢查客戶端是否已經打開
- checkOpen();
- final FsPermission masked = applyUMask(permission);
- LOG.debug("{}: masked={}", src, masked);
- //調用 DFSOutputStream.newStreamForCreate()創建輸出流對象
- final DFSOutputStream result = DFSOutputStream.newStreamForCreate(this,
- src, masked, flag, createParent, replication, blockSize, progress,
- dfsClientConf.createChecksum(checksumOpt),
- getFavoredNodesStr(favoredNodes), ecPolicyName);
- //獲取 HDFS 文件的租約
- beginFileLease(result.getFileId(), result);
- return result;
- }
DistributeFileSystem.create()在底層會調用 DFSClient.create()方法。該方法主要完成三件事:
租約:指的是租約持有者在規定時間內獲得該文件權限(寫文件權限)的合同
第一,檢查客戶端是否已經打開
第二,調用靜態的 newStreamForCreate() 方法,通過 RPC 與 NameNode 通信創建新文件,并構建出 DFSOutputStream流
第三,執行 beginFileLease() 方法,獲取新J建文件的租約
- newStreamForCreate() 方法
- static DFSOutputStream newStreamForCreate(DFSClient dfsClient, String src,
- FsPermission masked, EnumSet<CreateFlag> flag, boolean createParent,
- short replication, long blockSize, Progressable progress,
- DataChecksum checksum, String[] favoredNodes, String ecPolicyName)
- throws IOException {
- try (TraceScope ignored =
- dfsClient.newPathTraceScope("newStreamForCreate", src)) {
- HdfsFileStatus stat = null;
- // 如果發生異常,并且異常為 RetryStartFileException ,便重新調用create()方法,重試次數為 10
- boolean shouldRetry = true;
- //重試次數為 10
- int retryCount = CREATE_RETRY_COUNT;
- while (shouldRetry) {
- shouldRetry = false;
- try {
- //調用 ClientProtocol.create() 方法,在命名空間中創建 HDFS 文件
- stat = dfsClient.namenode.create(src, masked, dfsClient.clientName,
- new EnumSetWritable<>(flag), createParent, replication,
- blockSize, SUPPORTED_CRYPTO_VERSIONS, ecPolicyName);
- break;
- } catch (RemoteException re) {
- IOException e = re.unwrapRemoteException(AccessControlException.class,
- //....此處省略了部分異常類型
- UnknownCryptoProtocolVersionException.class);
- if (e instanceof RetryStartFileException) {//如果發生異常,判斷異常是否為 RetryStartFileException
- if (retryCount > 0) {
- shouldRetry = true;
- retryCount--;
- } else {
- throw new IOException("Too many retries because of encryption" +
- " zone operations", e);
- }
- } else {
- throw e;
- }
- }
- }
- Preconditions.checkNotNull(stat, "HdfsFileStatus should not be null!");
- final DFSOutputStream out;
- if(stat.getErasureCodingPolicy() != null) {
- //如果用戶指定了糾刪碼策略,將創建一個 DFSStripedOutputStream 對象
- out = new DFSStripedOutputStream(dfsClient, src, stat,
- flag, progress, checksum, favoredNodes);
- } else {
- //如果沒指定糾刪碼策略,調用構造方法創建一個 DFSOutputStream 對象
- out = new DFSOutputStream(dfsClient, src, stat,
- flag, progress, checksum, favoredNodes, true);
- }
- //啟動輸出流對象的 Datastreamer 線程
- out.start();
- return out;
- }
- }
newStreamForCreate()方法總共涉及三個部分:
當構建完 DFSOutputStream 輸出流時,客戶端調用 write() 方法把數據包寫入 dataQueue 隊列,在將數據包發送到 DataNode 之前,DataStreamer會向 NameNode 申請分配一個新的數據塊
然后建立寫這個數據塊的數據流管道(pipeline),之后DataStreamer 會從 dataQueue 隊列取出數據包,通過 pipeline 依次發送給各個 DataNode。每個數據包(packet)都有對應的序列號,當一個數據塊中所有的數據包都發送完畢,
并且都得到了 ack 消息確認后,Datastreamer會將當前數據塊的 pipeline 關閉。通過不斷循環上述過程,直到該文件(一個文件會被切分為多個 Block)的所有數據塊都寫完成。
調用 ClientProtocol.create()方法,創建文件,如果發生異常為 RetryStartFileException ,則默認重試10次
調用 DFSStripedOutputStream 或 DFSOutputStream 構造方法,構造輸出流對象
啟動 Datastreamer 線程,Datastreamer 是 DFSOutputStream 中的一個內部類,負責構建 pipeline 管道,并將數據包發送到 pipeline 中的第一個 DataNode
- writeChunk()方法
- protected synchronized void writeChunk(ByteBuffer buffer, int len,
- byte[] checksum, int ckoff, int cklen) throws IOException {
- writeChunkPrepare(len, ckoff, cklen);
- //將當前校驗數據、校驗塊寫入數據包中
- currentPacket.writeChecksum(checksum, ckoff, cklen);
- currentPacket.writeData(buffer, len);
- currentPacket.incNumChunks();
- getStreamer().incBytesCurBlock(len);
- // 如果當前數據包已經滿了,或者寫滿了一個數據塊,則將當前數據包放入發送隊列中
- if (currentPacket.getNumChunks() == currentPacket.getMaxChunks() ||
- getStreamer().getBytesCurBlock() == blockSize) {
- enqueueCurrentPacketFull();
- }
- }
最終寫數據調用都的是 writeChunk ()方法,其會首先調用 checkChunkPrepare()構造一個 Packet 對象保存數據包,
然后調用writeCheckSum()和writeData()方法,將校驗塊數據和校驗和寫入 Packet 對象中。
當 Packet 對象寫滿時(每個數據包都可以寫入 maxChunks 個校驗塊),則調用 enqueueCurrentPacketFull()方法,將當前的 Packet 對象放入 dataQueue 隊列中,等待 DataStreamer 線程的處理。
如果當前數據塊中的所有數據都已經發送完畢,則發送一個空數據包標識所有數據已經發送完畢。
3.HDFS 如何保證可用性?
在 1.1 節中已經闡述了 HDFS 的高可用的架構,分別涉及到 NameNode,DataNode,Journalnode,ZKFC等組件。所以,在談及 HDFS 如何保證可用性,要從多個方面去回答。
- 在 Hadoop 2.X 時,主備 NameNode 節點通過 JournalNode 的數據同步,來保證數據一致性,2個 ZKFC 進程負責各自的 NameNode 健康監控,從而實現了 NameNode 的高可用。Hadoop 3.X 時,NameNode 數量可以大于等于 2。
- 對于 JournalNode 來講,也是分布式的,保證了可用性。因為有選舉機制,所以 JournalNode 個數 一般都為 2N+1 個。在 主NameNode向 JournalNode寫入 editlog 文件時,當有一半以上的(≥N+1) JournalNode返回寫操作成功時即認為該次寫成功。所以 JournalNode集群能容忍最多 N 臺節點宕掉,如果多于 N 臺機器掛掉,服務才不可用。
- ZKFC 主要輔助 ZooKeeper 做 Namenode 的健康監控,能夠保證故障自動轉移,它是部署在兩臺 NameNode 節點上的獨立的進程。此外,ZooKeeper 集群也是一個獨立的分布式系統,它通過 Zab 協議來保證數據一致,和主備節點的選舉切換等機制來保證可用性。
- DataNode 節點主要負責存儲數據,通過 3 副本策略來保證數據的完整性,所以其最大可容忍 2 臺 DataNode 掛掉,同時 NameNode 會保證副本的數量。
- 最后,關于數據的可用性保證,HDFS 提供了數據完整性校驗的機制。當客戶端創建文件時,它會計算每個文件的數據塊的checknums,也就是校驗和,并存儲在 NameNode 中。當客戶端去讀取文件時,會驗證從 DataNode 接收的數據塊的校驗和,如果校驗和不一致,說明該數據塊已經損壞,此時客戶端會選擇從其它 DataNode 獲取該數據塊的可用副本。
4.HDFS 高頻面試題
- HDFS 客戶端是如何與 DataNode 、NameNode 交互的?
- ZKFC 是如何實現主 NameNode 故障自動轉移的?
- NameNode 存儲了哪些數據?
- Zookeeper 在故障轉移過程中是如何起作用的?
- HDFS 的讀寫流程?
- 在 Hadoop 2.X 時,HDFS block 塊為什么設置為 128 M?
本文轉載自微信公眾號「小林玩大數據」,可以通過以下二維碼關注。轉載本文請聯系小林玩大數據公眾號。