













12 個問題搞懂 Redis
作者: oec2003
隨著硬件性能的提升,Redis 的性能瓶頸有時會出現在網絡 IO 的處理上,也就是說,單個主線程處理網絡請求的速度跟不上底層網絡硬件的速度,而讀寫的操作和網絡 IO 是在一個主線程中,勢必會有所影響。
都說學習需要帶著問題,帶著思考進行學習,下面就以問題的形式來學習下 Redis 。
1、什么是 Redis ?
- Redis 是一個高性能的 key-value 數據庫;
- 作者來自意大利西西里島的 Salvatore Sanfilippo ;
- Redis 使用 ANSI C 語言編寫、并遵守 BSD 開源協議;
- Redis 支持網絡、可基于內存、分布式、也可以用來實現簡易的消息隊列;
- 提供豐富的數據結構:字符串(String)、哈希(Hash)、列表(list)、集合(sets)和有序集合(sorted sets) 。
2、都說 Redis 是單線程模型,到底是什么意思?
- 單線程并不是說在 Redis 中所有的操作都是由一個線程來完成;
- 核心功能,比如:網絡 IO 和數據的讀寫是由一個線程來進行處理的;
- 其他的一些輔助功能,比如:持久化、集群間的數據同步是由單獨的線程進行處理;
- 所以說 Redis 的單線程不是“真正”的單線程。
3、為什么在數據讀寫處理上不使用多線程?
- 多線程雖然可以增加系統的吞吐率,但線程的切換會有開銷;
- 多個線程對共享資源的并發處理問題,必然會用到各種鎖,有鎖就會存在等待鎖的釋放,反而吞吐率降低了;
- 處理各種多線程帶來的問題,會使系統變得復雜,復雜的系統就容易出現問題。
4、為什么使用單線程,速度卻很快?
- Redis 的操作是基于內存的,相比較于磁盤,速度上有先天的優勢;
- Redis 有高效的數據結構,比如:哈希表、跳表;
- 采用了多路復用機制,可以并發處理大量的請求,實現高吞吐率。
5、單線程處理的瓶頸是什么?
- 如果有耗時長的操作,后面的請求都需要進行等待;
- 單個 value 的內容過大,在添加、獲取、刪除時都會比較耗時;
- 使用復雜的命令,比如:SORT/SUNION/ZUNIONSTORE;
- 集合的數據非常大,而又進行了全量查詢。
- 并發量非常大時,雖然 IO 有多路復用機制,從內核緩沖區中拷貝數據的操作仍然是同步操作,會帶來性能瓶頸。
6、Redis 6.0 調整為多線程的原因?
- 上面提到過 6.0 之前的版本是網絡 IO 和數據讀寫是在一個線程中完成的;
- 隨著硬件性能的提升,Redis 的性能瓶頸有時會出現在網絡 IO 的處理上,也就是說,單個主線程處理網絡請求的速度跟不上底層網絡硬件的速度,而讀寫的操作和網絡 IO 是在一個主線程中,勢必會有所影響;
- 所以在 Redis 6.0 中,網絡 IO 是由多個 IO 線程并行處理,可以充分利用服務器的多核資源,提高網絡讀寫操作;
- Redis 數據的讀寫處理仍然在單個主線程中完成。
7、在 Redis 中怎樣做持久化?
- 在 Redis 實現持久化有兩種方式:AOF 日志 和 RDB 快照;
- AOF 日志
- 命令執行成功后,才記錄日志;
- 命令執行后進行日志記錄,不會堵塞當前的寫操作。
- 命令執行完,日志記錄前宕機,數據會丟失;
- AOF 日志在主線程中執行,有 IO 瓶頸時會對后面的操作有堵塞風險;
- 數據量比較大的時候,恢復很慢。
- 配置項(appendfsync)
Always,同步寫回磁盤:每個寫命令執行完,立即同步將日志寫回磁盤;
Everysec,每秒寫回磁盤:每個寫命令執行完,只是先把日志寫到 AOF 文件的內存緩沖區,每隔一秒把緩沖區中的內容寫入磁盤;
No,操作系統控制的寫回磁盤:每個寫命令執行完,只是先把日志寫到 AOF 文件的內存緩沖區,由操作系統決定何時將緩沖區內容寫回磁盤。
RDB 快照
- 和 AOF 相比較,RDB 快照記錄的是某一個時刻的數據,數據恢復是直接將 RDB 文件讀入內存,速度很快;
- 生成 RDB 文件的兩種方式:
- save:在主線程中執行,會導致阻塞;
- bgsave:創建一個子進程,專門用于寫入 RDB 文件,避免了主線程的阻塞,這也是 Redis RDB 文件生成的默認配置。子進程是由主線程 fork 生成的,可以共享主線程的所有內存數據。
- RDB 快照的間隔時間不宜設置過短,因為頻繁進行 Redis 的全量快照,會帶來性能問題:
- 前一個快照還沒做完,后面一個開始了,會給磁盤帶來壓力;
- bgsave 的子進程雖然不會阻塞主線程,但創建的過程會阻塞,頻繁創建也會帶來性能問題。
- 解決上面問題的一種辦法就是使用增量快照;
- 在 Redis 4.0 中提出了一種混合 AOF 日志和 RDB 快照的方式:
- RDB 快照的間隔時間可以設置比較大,就不會影響到主線程的操作;
- 在快照的間隔期間可以使用 AOF 日志記錄所有的操作,當下一次做全量 RDB 快照的時候,清空 AOF 日志;
- 通過 aof-use-rdb-preamble yes 來進行設置。
8、常說的緩存雪崩、擊穿、穿透是什么?
- 雪崩、擊穿、穿透最終的結果都是請求壓力會轉移到數據庫,導致系統崩潰,但場景有所區別;
- 雪崩
- 大量的不同請求無法在 Redis 中命中,導致請求都流向了數據庫,數據庫的壓力劇增;
- 發生雪崩的原因可能是,有大量的緩存 Key 在同一時間過期。
- 擊穿
- 并發很大的情況下,針對某個特定的請求,緩存中數據不存在,導致都請求到了數據庫,造成數據庫壓力過大;
- 原因通常是某個 Key 過期了;
- 和雪崩相比較,擊穿是針對的單個 Key。
- 穿透
- 緩存穿透是指請求的數據不在 Redis 緩存中,也不在數據庫中,導致訪問緩存時,找不到數據,會去請求數據庫,而在數據庫中也找不到相應的數據;
- 并發比較大的時候,數據庫會遭受巨大的壓力;
- 發生穿透的原因可能有兩個:
- 誤操作導致 Redis 和數據庫中的數據都被刪除了;
- 惡意攻擊。
9、怎樣解決雪崩、擊穿、穿透帶來的問題?
- 雪崩
- 緩存的數據過期時間設置隨機,防止同一時間大量數據過期現象發生;
- 如果緩存數據庫是分布式部署,將熱數據均勻分布在不同緩存數據庫中;
- 當發生雪崩時,可以通過服務降級來應對。
- 擊穿
- 設置熱數據永遠不過期。
- 穿透
- 在接口層進行校驗,將惡意請求直接過濾掉;
- 使用布隆過濾器快速判斷數據是否存在;
- 緩存空值或缺省值。
10、怎樣設計緩存的淘汰機制?
業務數據在不斷地增長,不可能將所有數據全部存儲在 Redis 緩存中,內存的價格遠遠大于磁盤。所以需要做淘汰機制的設計;
緩存的淘汰就是根據一定的策略,將不太重要的數據從緩存中進行刪除;
Redis 一共有 8 種淘汰策略,在 Redis 4.0 之前有 6 種,4.0 之后又增加了 2 種,如下圖:
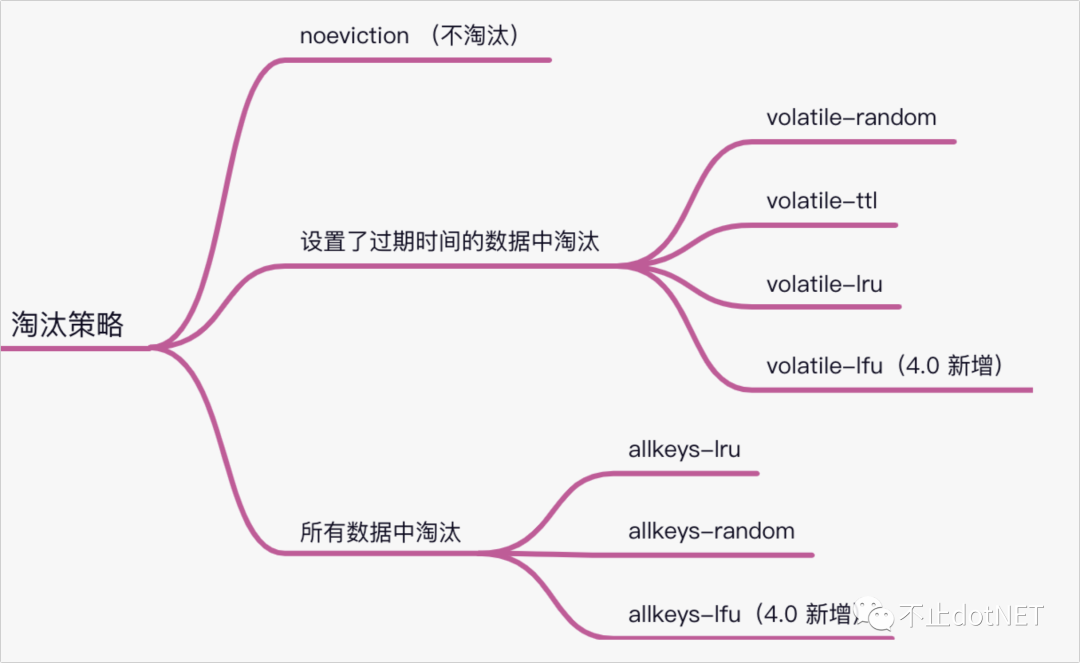
- 緩存策略的解釋:
- volatile-random:在設置了過期時間的數據中,進行隨機刪除;
- volatile-ttl:根據過期時間,越早過期的數據越先刪除;
- volatile-lru:在設置了過期時間的數據中,根據 LRU 算法進行數據刪除;
- volatile-lfu:在設置了過期時間的數據中,根據 LFU 算法進行數據刪除;
- allkeys-lru:在所有數據中,根據 LRU 算法進行數據刪除;
- allkeys-random:在所有數據中,進行隨機刪除;
- allkeys-lfu:在所有數據中,根據 LFU 算法進行數據刪除;
- 默認情況下,當 Redis 的使用空間超過 maxmemory 設置的大小時,并不會淘汰數據,也就是執行的 noeviction 策略,如果寫滿,再有寫請求時就會出錯;
- 如果業務中有明顯的熱數據和冷數據,優先使用 allkeys-lru 策略,讓熱數據保留在緩存中;
- 如果業務中沒有明顯冷熱數據,可以使用 volatile-random 或 allkeys-random。
11、怎樣保證緩存和數據庫的數據一致?
- 緩存和數據庫一致的意思是,當緩存中有數據時,緩存和數據庫數據相同,當沒有數據時,數據庫中是最新的;
- 在做增刪改操作的時候,對緩存的更新有兩種方式:
- 新增直接添加到數據庫,刪除和修改時先更新緩存,然后同步或異步進行數據庫的更新;
- 新增直接添加到數據庫,刪除和修改時先更新數據庫,再刪除對應的緩存。
- 上面的操作都涉及到兩個,操作 Redis 和操作數據庫,當其中一個成功一個失敗時就會出現數據不一致的情況;
- 解決不一致的問題:
- 將操作通過消息隊列異步處理,設置重試機制,保證最終的一致性;
- 使用分布式事務,保證操作 Redis 和數據庫的兩個操作在一個事務中。
12、Redis 有什么使用規范?
- Redis 單實例的內存大小都不要設置太大,建議在 2~6GB ,設置太大,會導致 RDB 快照、從 AOF 日志恢復、主從集群進行數據同步等都會耗時很長,阻塞正常請求的處理;
- 對集合進行全量數據獲取時,時間復雜度是 O(n),所以這個 n 不宜太大;
- 單個 key 的值不要太大,即便是最新的 6.0 版本,在讀寫這部分仍然是單線程,大 value 的讀取會耗時,導致堵塞;
- 根據具體的業務特點設計好淘汰策略;
- 使用高效的序列化和壓縮方法對緩存數據進行處理,來進一步提升性能;
- 生產環境中禁止使用 KEYS、FLUSHALL、FLUSHDB 等操作,數據量大的時候耗時長,會阻塞主線程;
- 有時為了排查錯誤,會使用 MONITOR 命令進行監控,該命令也會對性能造成嚴重影響;
- Redis 的知識遠不止如此,本文總結了一些我認為比較重要的一些點,希望對您有所幫助!
責任編輯:武曉燕
來源:
不止dotNET



















