一文了解大數據下 Redis 的應用

大數據下Redis的應用
1、Redis客戶端區別
1.1 redis常用客戶端
目前市面上比較流行的客戶端有jedis、lettuce、redisson
jedis
jedis客戶端連接方式是基于TCP阻塞方式
lettuce
lettuce內部是基于netty的多路復用異步非阻塞方式(目前業界解決高并發大數據的問題的思路)
redisson
相對于上面兩種使用得較少
在并發數量不大的情況下,兩者性能可能差不多,jedis的性能可能還優于lettuce,但當并發量的提升,jedis的超時錯誤會增加,但lettuce只是平均響應時間增加和最大響應時間會增加,lettuce是已穩定性為主的。
1.2 epoll模型-單線程的redis為什么快
redis內部使用epoll模型來提高鏈接處理能力
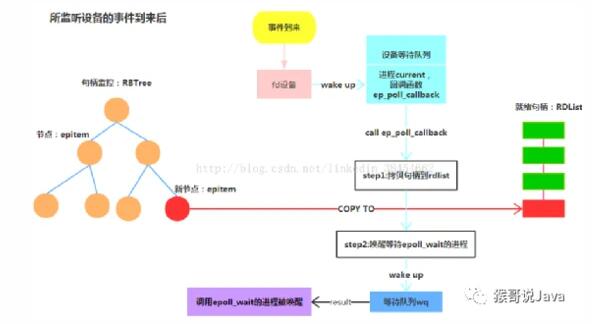
傳統TCP鏈接與epoll模型的本質區別
TCP鏈接存在鏈接數瓶頸,隨著連接數的增加,響應速度會明顯變慢
epoll可支持更大數量的連接數而不會對性能有明顯的影響
2、大數據下的redis的存儲方案
2.1 分片模式
分片模式是把部署多個redis節點,然后由客戶端決定數據分片規則,常見的分片規則就是以節點數量進行哈希分片
優點:
服務端不需要進行繁瑣的配置,由客戶端決定路由規則
缺點:
缺點很明顯,如果多個節點中的某個節點掛了,將丟失這一部分數據,因為客戶端還是為每個節點分配了連接,而且客戶端配置分片節點IP的時候要注意
IP列表的順序不能隨意指定順序,IP變更也會影響數據,擴容相當麻煩。
建議:如果分片節點較少可以使用分片來適當的分攤壓力
配置示例:
- spring :
- remote :
- ecredis :
- type : sharding
- uri :
- - 192.168.1.3:6379
- - 192.168.1.4:6379
- - 192.168.1.5:6379
- - 192.168.1.6:6379
- - 192.168.1.7:6379
- db : 1
- maxIdle : 10
- minIdle : 5
- maxActive : 10
- password : GpG4fZoxsp7cTB5f
- keyPrefix : 'ERP:EXPORT-CENTER:'
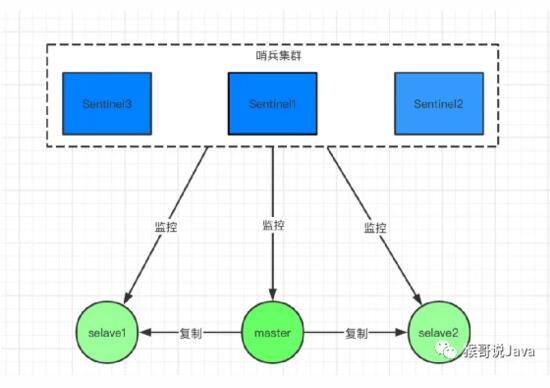
2.2 哨兵機制
在Redis 2.8版本開始引入,就有了哨兵這個概念,哨兵實現了自動化的故障恢復,無需關心IP是否變更。
優點:
哨兵模式是基于主從模式的,所有主從的優點,哨兵模式都具有。
主從可以自動切換,系統更健壯,可用性更高。
Sentinel 會不斷的檢查 主服務器 和 從服務器 是否正常運行。當被監控的某個 Redis 服務器出現問題,Sentinel 通過API腳本向管理員或者其他的應用程序發送通知。
缺點:
Redis較難支持在線擴容,對于集群,容量達到上限時在線擴容會變得很復雜。
- spring :
- redis :
- password : 123456
- sentinel :
- master : master
- nodes : 47.98.217.106:26379,47.98.217.109:26380,47.98.217.109:26381
- timeout : 20000
- database : 0
- jedis :
- pool :
- max-active : 300
- max-wait : -1
- max-idle : 100
- min-idle : 20
2.3 redis cluster集群
通過數據分片的方式來進行數據共享問題,同時提供數據復制和故障轉移功能,包含了哨兵模式的所有功能。
優點:數據按slot來分散存儲,訪問任何一個master節點都可以獲取任何分片上面的數據,任何一個master節點都可以做擴容或者新增master節點的時候,數據會自動分片同步遷移(redis集群的重新分片由redis內部的redis-trib負責執行),服務器不需要下線。如果每個master使用了主從模式,那么當master發生故障的時候,下面的slave們會選舉一個新的master
缺點:需要使用ruby進行部署,配置相當麻煩,維護不方便
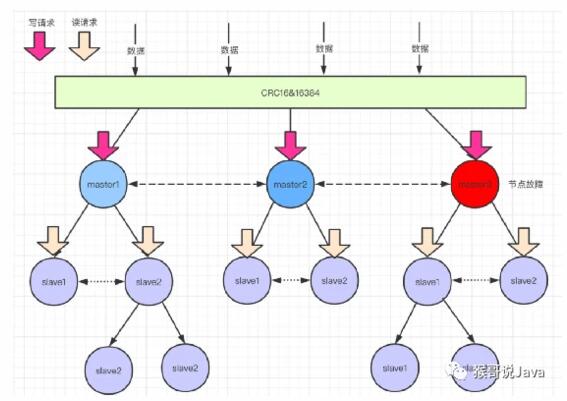
配置示例:
- spring :
- redis :
- password :
- cluster :
- nodes : 192.168.1.3:6379,192.168.1.4:6379,192.168.1.5:6379
- max-redirects : 3
- lettuce :
- pool :
- max-idle : 16
- max-active : 32
- min-idle : 8
2.4 cachecloud
cachecloud是一套解決方案,實現多種類型(Redis Standalone、Redis Sentinel、Redis Cluster)自動部署、解決Redis實例碎片化現象、提供完善統計、監控、運維功能、減少運維成本和誤操作,提高機器的利用率,提供靈活的伸縮
優點:
使配置更簡單,集群節點不再由客戶端維護,配置一個domain即可自動獲取節點列表
配置示例:
- spring :
- domain : cachecloud.server1.com:8080
- remote :
- ecredis :
- appid : 2
- type : cloud
- uri :
- db : 1
- maxIdle : 10
- minIdle : 5
- maxActive : 10
- password : GpG4fZoxsp7cTB5f
- keyPrefix : 'ERP:EXPORT-CENTER:'
應用案例:
2.5 redis存儲方案選型
吞吐量數據量較少、數據安全性不高:單機模式或者分片模式
吞吐量數據量較大、數據安全性較高:哨兵模式、集群模式
吞吐量數據量大、數據安全性高、擴展性強:集群模式
3、性能優化
3.1 日志優化
Redis日志存儲模式分為兩種:RDB和AOF,RDB為實時寫入磁盤,AOF為延遲批量寫入磁盤
RDB模式:
優點:實時存儲日志,在數據恢復方面更有優勢
缺點:磁盤IO比較頻繁,會影響redis的吞吐能力
AOF模式:
優點:定時批量刷新日志到磁盤,適合高吞吐的場景,對redis性能影響較小
缺點:如果某一個時刻redis發生故障,可能會丟失內存中的數據,故障恢復的時候恢復不了這部分數據
模式選擇:
如果吞吐量較小,使用RDB即可,吞吐量較大,可以選擇AOF來提高性能,兩種方式根據具體場景來選擇
AOF配置:
- appendonly yes
- #aof文件名設置
- appendfilename "appendonly-${port}.aof"
- #配置選擇
- appendfsync everysec
- dir /bigdiskpath
- #不開啟aof重寫,因為太消耗性能
- no-appendfsync-on-rewrite yes
AOF重寫:分析當前redis中key對應的值來優化指令,來減少磁盤空間和壓力,但因為需要判斷合并邏輯,會有很大的性能開銷,一般不開啟aof重寫
- # 假設服務器對鍵list執行了以下命令;
- 127.0.0.1:6379> RPUSH list "A" "B"
- (integer) 2
- 127.0.0.1:6379> RPUSH list "C"
- (integer) 3
- 127.0.0.1:6379> RPUSH list "D" "E"
- (integer) 5
- 127.0.0.1:6379> LPOP list
- "A"
- 127.0.0.1:6379> LPOP list
- "B"
- 127.0.0.1:6379> RPUSH list "F" "G"
- (integer) 5
- 127.0.0.1:6379> LRANGE list 0 -1
- 1) "C"
- 2) "D"
- 3) "E"
- 4) "F"
- 5) "G"
- 127.0.0.1:6379>
正常AOF會把前面的6條寫入命令都存入日志中,AOF重寫會先去redis獲取list的值,發現是["C","D","E","F","G"],然后生成一條 RPUSH list "C" "D" "E" "F" "G" 來代替前面6條
3.2 緩存更新策略
redis默認情況下就是使用LRU策略的,因為內存是有限的,但是如果你不斷地往redis里面寫入數據,那肯定是沒法存放下所有的數據在內存的
(1)noeviction: 如果內存使用達到了maxmemory,client還要繼續寫入數據,那么就直接報錯給客戶端
(2)allkeys-lru: 就是我們常說的LRU算法,移除掉最近最少使用的那些keys對應的數據(最常用的)
(3)volatile-lru: 也是采取LRU算法,但是僅僅針對那些設置了指定存活時間(TTL)的key才會清理掉
(4)allkeys-random: 隨機選擇一些key來刪除掉
(5)volatile-random: 隨機選擇一些設置了TTL的key來刪除掉
(6)volatile-ttl: 移除掉部分keys,選擇那些TTL時間比較短的keys
除了LRU,還可以使用scan的方式進行輪詢ttl的方式清理
3.3 代碼中使用redis的一些建議
避免使用keys *這種模糊查詢,會阻塞當前線程,使用scan的方式去處理,redis客戶端建議不要使用redis desktop manager
- String cursor = ScanParams . SCAN_POINTER_START ;
- ScanParams scanParams = new ScanParams ();
- // 匹配表達式
- scanParams . match ( "key*" );
- // 每次scan的條數
- scanParams . count ( 1000 );
- while ( true ) {
- ScanResult << span=""> String > result = jedis . scan ( cursor , scanParams );
- cursor = result . getStringCursor ();
- if ( "0" . equals ( cursor )) {
- break ;
- }
- }
hgetall也應該避免使用,使用hscan代替,但如果通過RedisTemplate回調的方式使用hscan應該注意資源的釋放,否則會出現請求到達一定次數的時候就不能發起請求的問題(客戶端hang住了)
如果set的時候同時設置expire過期時間,不要先set再expire這種方式,應該使用原子操作
- set key value [EX seconds] [PX milliseconds] [NX|XX]
對于同一個需求多次改版redis中寫入不同格式的數據,會產生兼容性問題,可以使用type命令去處理兼容,然后監控等老數據不存在之后再把判斷邏輯移除
- String type = jedis . type ( "a" );
- if ( "string" . equalsIgnoreCase ( type )) {
- // do something
- } else if ( "list" . equalsIgnoreCase ( type )) {
- // do something
- }
如果redis中的數據需要做去重,可以使用set或hashmap,hashmap性能更高,但對于維護hashmap數據結構之外的數據比較多,之前測試過,100B的數據存放到hashmap,但實際占用量可能有200B~300B甚至更多,set對于數據多的情況下性能會低一點
建議:數據少的情況下用set,數據多就用hashmap,但要注意盡量減少存儲內容的長度,比如{"source":"order"}可以改成{"s":1}
去重操作不建議使用list,因為每次判斷都要從list中取數據然后再add進去,多線程操作下還是可能會出現重復問題(比如兩個線程同時lrange操作)
- // 在多線程模式下會有問題
- // 假設線程A和線程B同時執行lrange
- List << span=""> String > list = jedis . lrange ( "a" , 0 , - 1 );
- if (! list . contains ( "bbb" )) {
- jedis . lpush ( "bbb" );
- }
如果一次處理的命令很多,使用pipeline性能更好
list可以結合lpush/rpop、rpush/lpop來實現隊列功能,但不建議把list當成是MQ的功能,因為沒有記錄的狀態,無法跟蹤數據處理情況
關于redis分布式鎖,目前流行的實現方式還沒有完美的方案,使用lua腳本的版本也不是完美的,如果需求允許延時或者一定時間內不允許執行多次,setnx設置過期時間是最好的方案
4、故障轉移與數據遷移
4.1 數據遷移方案
老節點替換為新節點、新老key兼容處理
將新節點作為老節點的slave節點,等數據自動同步完成之后下架老節點,不建議使用代碼遷移,因為不同業務數據結構可能很多
不同類型的節點之間遷移的方法不同,如果單節點遷移至分片集群只能借助遷移工具來完成
如果新業務將使用新的key,要保留舊key,可以開啟兩個連接池,一個處理新key,一個處理舊key,這樣等舊key都失效的時候移除對舊key的連接就可以完全遷移到新key業務
動態擴容
必須在集群模式下才可以進行動態擴容,也可以使用cachecloud,數據會自動同步到各個節點
在數據遷移的過程中即使訪問的某個key正在遷移,數據也是可以正常返回的,不用擔心遷移過程會對數據訪問造成影響
4.2 故障轉移對于客戶端的影響
redis集群模式雖然可以在某個master節點發生故障的時候自動從slave中選舉節點當master,但類似jedis的客戶端并不支持故障轉移,也就是當集群某節點發生故障正在切換的時候,客戶端如果正在訪問故障節點,這時集群故障轉移還沒有完成,客戶端會報錯,如果需要讓客戶端也支持故障轉移,需要修改jedis客戶端源碼來實現。