













PLEG is not healthy?幕后黑手居然是它!
本文轉載自微信公眾號「運維開發故事」,作者沒有文案的夏老師。轉載本文請聯系運維開發故事公眾號。
問題描述
環境 :ubuntu18.04,自建集群k8s 1.18 ,容器運行時docker。
現象:某個Node頻繁NotReady,kubectl describe該Node,出現“PLEG is not healthy: pleg was last seen active 3m46.752815514s ago; threshold is 3m0s”錯誤,頻率在5-10分鐘就會出現一次。
我們首先要明白PLEG是什么?
PLEG 全稱叫 Pod Lifecycle Event Generator,即 Pod 生命周期事件生成器。實際上它只是 Kubelet 中的一個模塊,主要職責就是通過每個匹配的 Pod 級別事件來調整容器運行時的狀態,并將調整的結果寫入緩存,使 Pod 的緩存保持最新狀態。先來聊聊 PLEG 的出現背景。在 Kubernetes 中,每個節點上都運行著一個守護進程 Kubelet 來管理節點上的容器,調整容器的實際狀態以匹配 spec 中定義的狀態。具體來說,Kubelet 需要對兩個地方的更改做出及時的回應:
- Pod spec 中定義的狀態
- 容器運行時的狀態
對于 Pod,Kubelet 會從多個數據來源 watch Pod spec 中的變化。對于容器,Kubelet 會定期(例如,10s)輪詢容器運行時,以獲取所有容器的最新狀態。隨著 Pod 和容器數量的增加,輪詢會產生不可忽略的開銷,并且會由于 Kubelet 的并行操作而加劇這種開銷(為每個 Pod 分配一個 goruntine,用來獲取容器的狀態)。輪詢帶來的周期性大量并發請求會導致較高的 CPU 使用率峰值(即使 Pod 的定義和容器的狀態沒有發生改變),降低性能。最后容器運行時可能不堪重負,從而降低系統的可靠性,限制 Kubelet 的可擴展性。為了降低 Pod 的管理開銷,提升 Kubelet 的性能和可擴展性,引入了 PLEG,改進了之前的工作方式:
- 減少空閑期間的不必要工作(例如 Pod 的定義和容器的狀態沒有發生更改)。
- 減少獲取容器狀態的并發請求數量。
所以我們看這一切都離不開kubelet與pod的容器運行時。
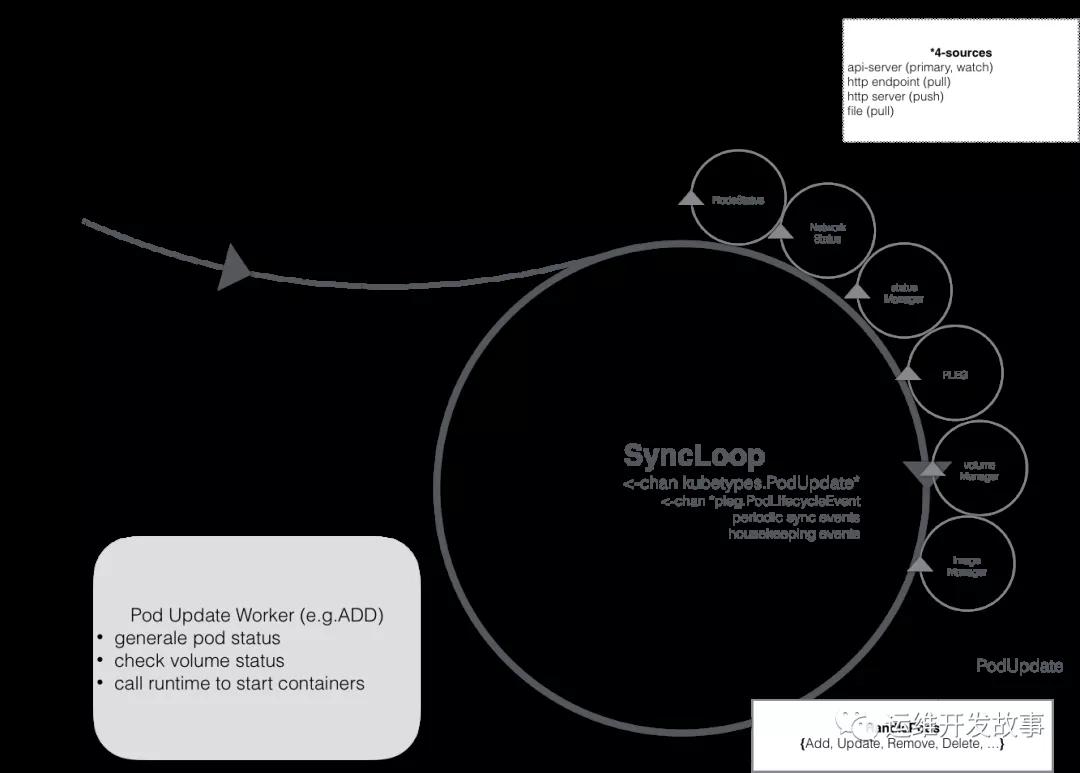
一方面,kubelet扮演的是集群控制器的角色,它定期從API Server獲取Pod等相關資源的信息,并依照這些信息,控制運行在節點上Pod的執行;
另外一方面,kubelet作為節點狀況的監視器,它獲取節點信息,并以集群客戶端的角色,把這些狀況同步到API Server。在這個問題中,kubelet扮演的是第二種角色。Kubelet會使用上圖中的NodeStatus機制,定期檢查集群節點狀況,并把節點狀況同步到API Server。而NodeStatus判斷節點就緒狀況的一個主要依據,就是PLEG。
PLEG是Pod Lifecycle Events Generator的縮寫,基本上它的執行邏輯,是定期檢查節點上Pod運行情況,如果發現感興趣的變化,PLEG就會把這種變化包裝成Event發送給Kubelet的主同步機制syncLoop去處理。但是,在PLEG的Pod檢查機制不能定期執行的時候,NodeStatus機制就會認為,這個節點的狀況是不對的,從而把這種狀況同步到API Server。
整體的工作流程如下圖所示,虛線部分是 PLEG 的工作內容。
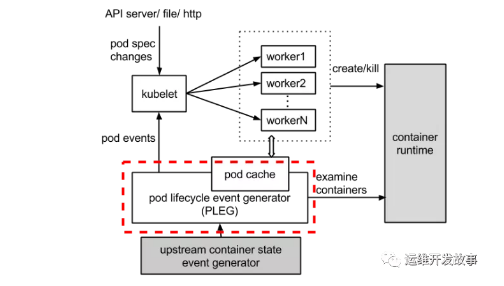
以node notready 這個場景為例,來講解PLEG:
Kubelet中的NodeStatus機制會定期檢查集群節點狀況,并把節點狀況同步到API Server。而NodeStatus判斷節點就緒狀況的一個主要依據,就是PLEG。
PLEG定期檢查節點上Pod運行情況,并且會把pod 的變化包裝成Event發送給Kubelet的主同步機制syncLoop去處理。但是,在PLEG的Pod檢查機制不能定期執行的時候,NodeStatus機制就會認為這個節點的狀況是不對的,從而把這種狀況同步到API Server,我們就會看到 not ready 。
PLEG有兩個關鍵的時間參數,一個是檢查的執行間隔,另外一個是檢查的超時時間。以默認情況為準,PLEG檢查會間隔一秒,換句話說,每一次檢查過程執行之后,PLEG會等待一秒鐘,然后進行下一次檢查;而每一次檢查的超時時間是三分鐘,如果一次PLEG檢查操作不能在三分鐘內完成,那么這個狀況,會被NodeStatus機制當做集群節點NotReady的憑據,同步給API Server。
PLEG Start就是啟動一個協程,每個relistPeriod(1s)就調用一次relist,根據最新的PodStatus生成PodLiftCycleEvent。relist是PLEG的核心,它從container runtime中查詢屬于kubelet管理containers/sandboxes的信息,并與自身維護的 pods cache 信息進行對比,生成對應的 PodLifecycleEvent,然后輸出到 eventChannel 中,通過 eventChannel 發送到 kubelet syncLoop 進行消費,然后由 kubelet syncPod 來觸發 pod 同步處理過程,最終達到用戶的期望狀態。
PLEG is not healthy的原因
這個報錯清楚地告訴我們,容器 runtime 是不正常的,且 PLEG 是不健康的。這里容器 runtime 指的就是 docker daemon 。Kubelet 通過操作 docker daemon 來控制容器的生命周期。而這里的 PLEG,指的是 pod lifecycle event generator。PLEG 是 kubelet 用來檢查 runtime 的健康檢查機制。這件事情本來可以由 kubelet 使用 polling 的方式來做。但是 polling 有其高成本的缺陷,所以 PLEG 應用而生。PLEG 嘗試以一種“中斷”的形式,來實現對容器 runtime 的健康檢查,雖然實際上,它同時用了 polling 和”中斷”這樣折中的方案。
從 Docker 1.11 版本開始,Docker 容器運行就不是簡單通過 Docker Daemon 來啟動了,而是通過集成 containerd、runc 等多個組件來完成的。雖然 Docker Daemon 守護進程模塊在不停的重構,但是基本功能和定位沒有太大的變化,一直都是 CS 架構,守護進程負責和 Docker Client 端交互,并管理 Docker 鏡像和容器。現在的架構中組件 containerd 就會負責集群節點上容器的生命周期管理,并向上為 Docker Daemon 提供 gRPC 接口。
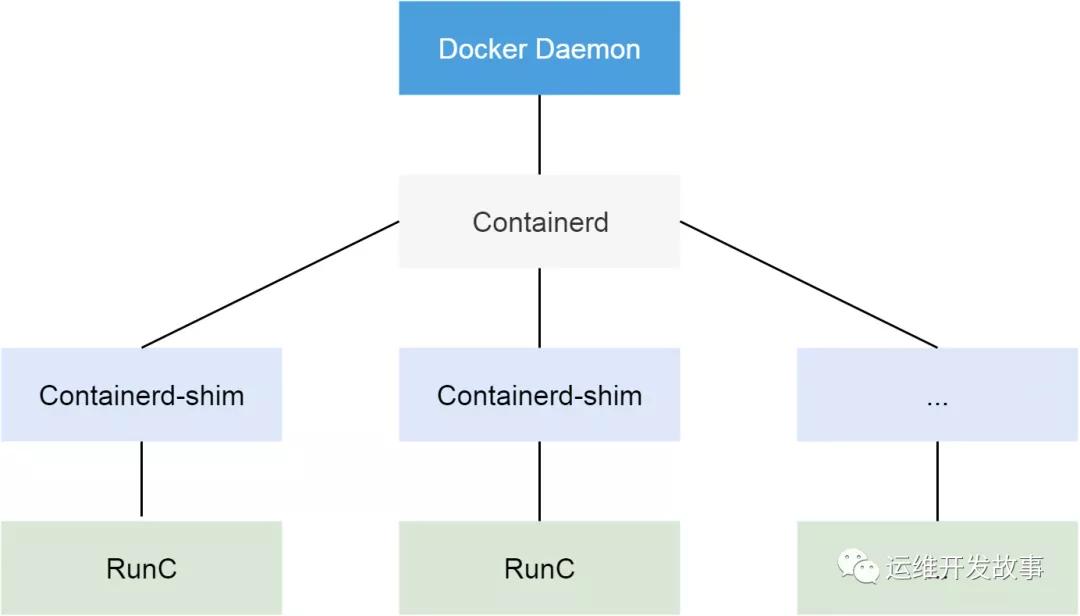
PLEG在每次迭代檢查中會調用runc的 relist() 函數干的事情,是定期重新列出節點上的所有容器,并與上一次的容器列表進行對比,以此來判斷容器狀態的變換。相當于docker ps來獲取所有容器,在通過docker Inspect來獲取這些容器的詳細信息。在有問題的節點上,通過 docker ps命令會沒有響應,這說明上邊的報錯是準確的。
經常出現的場景
出現 pleg not healthy,一般有以下幾種可能:
- 容器運行時無響應或響應超時,如 docker進程響應超時(比較常見)
- 該節點上容器數量過多,導致 relist 的過程無法在 3 分鐘內完成
- relist 出現了死鎖,該 bug 已在 Kubernetes 1.14 中修復。
- 網絡
排查處理過程描述
1.我們在問題節點上執行top,發現有進程名為scope的進程cpu占用率一直是100%。通過翻閱資料得知 systemd.scope:范圍(scope)單元并不通過單元文件進行配置, 而是僅能以編程的方式通過 systemd D-Bus 接口創建。范圍單元的名稱都以 ".scope" 作為后綴。與服務(service)單元不同,范圍單元用于管理 一組外部創建的進程, 它自身并不派生(fork)任何進程。范圍(scope)單元的主要目的在于以分組的方式管理系統服務的工作進程。2.在繼續執行在有問題的節點上,通過 docker ps命令會沒有響應。說明容器 runtime也是有問題的。那容器 runtime與systemd有不有關系呢?3.我們通過查閱到阿里的一篇文章,阿里巴巴 Kubernetes 集群問題排查思路和方法。找到了關系,有興趣的可以根據文末提供的鏈接去細致了解。以下是在該文章中截取的部分內容。
什么是D-Bus呢?
通過阿里巴巴 Kubernetes 集群問題排查思路和方法[1]中如下描述:在 Linux 上,dbus 是一種進程間進行消息通信的機制。
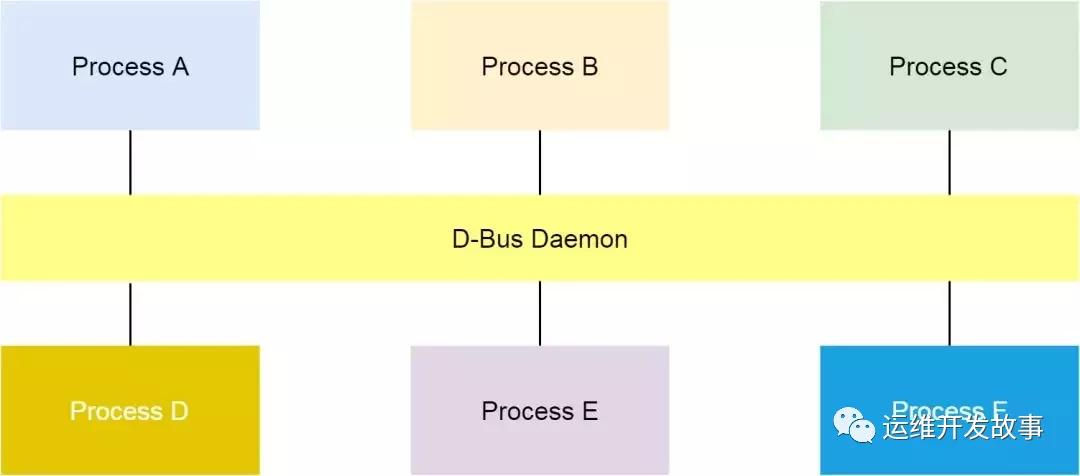
RunC 請求 D-Bus
容器 runtime 的 runC 命令,是 libcontainer 的一個簡單的封裝。這個工具可以用來管理單個容器,比如容器創建和容器刪除。在上節的最后,我們發現 runC 不能完成創建容器的任務。我們可以把對應的進程殺掉,然后在命令行用同樣的命令啟動容器,同時用 strace 追蹤整個過程。
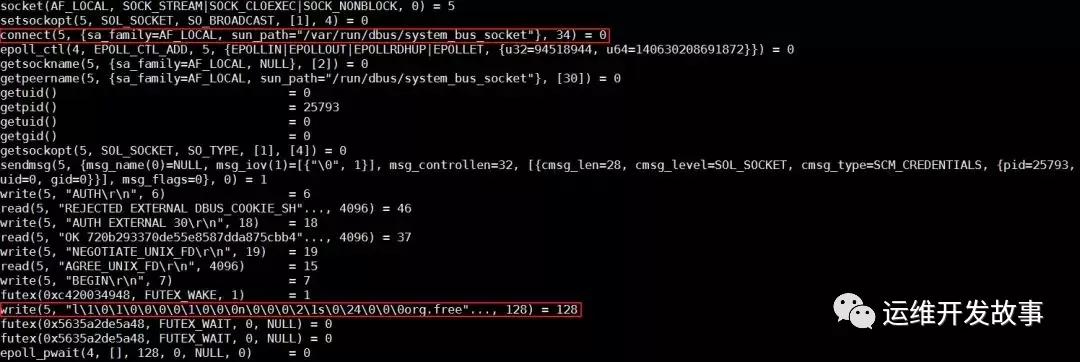
分析發現,runC 停在了向帶有 org.free 字段的 dbus socket 寫數據的地方。
解決問題
最后可以斷定是systemd的問題,我們用 systemctl daemon-reexec 來重啟 systemd,問題消失了。所以更加確定是systemd的問題。
具體原因大家可以參考:https://www.infoq.cn/article/t_ZQeWjJLGWGT8BmmiU4這篇文章。
根本上解決問題是:將systemd升級到 v242-rc2,升級后需要重啟操作系統。(https://github.com/lnykryn/systemd-rhel/pull/322)
總結
PLEG is not healthy的問題居然是因為systemd導致的。最后通過將systemd升級到 v242-rc2,升級后需要重啟操作系統。(https://github.com/lnykryn/systemd-rhel/pull/322) 參考資料
- Kubelet: Pod Lifecycle Event Generator (PLEG)
- Kubelet: Runtime Pod Cache
- relist() in kubernetes/pkg/kubelet/pleg/generic.go
- Past bug about CNI — PLEG is not healthy error, node marked NotReady
- https://www.infoq.cn/article/t_ZQeWjJLGWGT8BmmiU4
- https://cloud.tencent.com/developer/article/1550038

















