













手把手教你數據倉庫建設
本文轉載自微信公眾號「數倉寶貝庫」,作者范鋼 孫玄 。轉載本文請聯系數倉寶貝庫公眾號。
前面部分是對數據的采集,然后經過ETL過程,最終存入數據倉庫。這部分是通過一切手段收集數據,然而它的建設與數據應用需求無關。因為數據倉庫存儲的是過去數年的數據,而數據應用需求總是在變。如果數據應用需求一變化,就需要修改數據倉庫的表結構,那么這數年的數據都必須要重新計算,系統就會始終處于一種十分不穩定的狀態,維護成本極高。所以,只有數據倉庫的建設與數據應用需求無關,才能保證需求變更對數據倉庫沒有影響,才能讓系統穩定運行。
后面部分是根據不同的數據分析需求,從數據倉庫中獲取數據,完成各自的數據分析,將最終的分析結果寫入數據集市。數據集市的建設是與各自的數據分析的需求息息相關的,每次需求變更時,變更的是各自的數據集市,而不是數據倉庫。
01多維數據建模
經過前面一系列的ETL過程(什么是ETL?一文掌握ETL設計過程),我們最終將數據裝載到數據倉庫中。數據倉庫是按照多維數據模型的思路進行建設的。在多維數據模型中,動態數據就轉化為了事實表,靜態數據就轉化為了維度表。進項發票事實表、銷項發票事實表都是事實表,但從其中關聯出來了日期維度表、納稅人維度表、稅務機關維度表、地域維度表與行業維度表。
多維數據模型的設計有兩種思路:雪花模型與星形模型,如下圖所示。
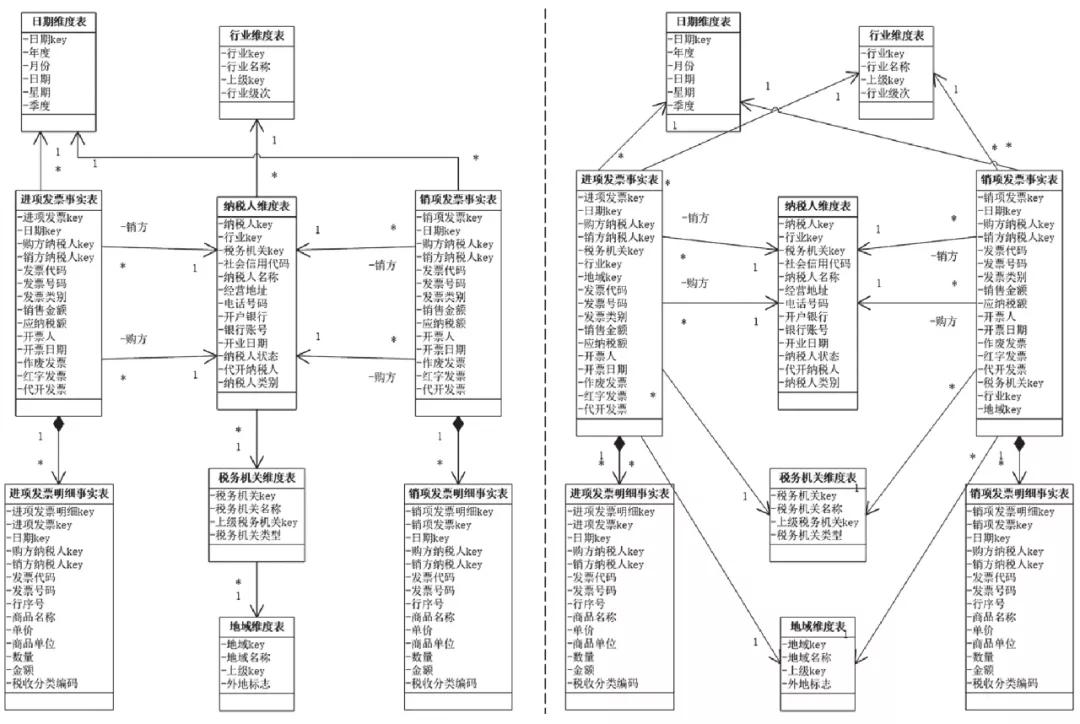
雪花模型與星形模型
左圖是雪花模型的設計,它最大的特點是在維度表上還要關聯維度表,如在納稅人維度表的基礎上還要關聯行業維度表。這樣設計比較容易理解,但會造成頻繁的join操作,在海量數據中降低查詢性能。譬如,要對進項發票進行地域的統計,就需要將進項發票事實表與納稅人維度表相關聯,再關聯稅務機關維度表、地域維度表,才能完成,這極大影響了系統性能。因此,為了提升查詢性能,基于空間換時間的思想,我們又提出了星形模型。
右圖是星形模型的設計,它最大的特點是不會再有維度與維度的關聯,而是所有維度表都只與事實表關聯。譬如對進項發票進行地域分析,只需要進項發票事實表關聯地域維度表就可以了,在海量數據中的性能將得到極大的提升。
接著,在以上事實表的基礎上,還可以從不同的維度與粒度對數據進行匯總,形成聚合表。譬如,對進項發票事實表按照行業進行匯總,或者按照地域進行匯總,形成“進項發票行業聚合表”與“進項發票地域聚合表”,等等。
以上的分析都是在“開票主題域”中進行的,但是按照業務流程,還有“申報主題域”“征收主題域”“稽查主題域”等,如下圖所示。這樣,數據中臺就按照業務模塊劃分為了多個主題域,然后在各個主題域進行多維建模,形成數據倉庫。但各個主題域可以擁有共同的維度表,如納稅人維度表、稅務機關維度表等。

主題域模型
02數據中臺的分層
數據中臺的建設,除了按照主題域進行縱向劃分,還要通過分層進行橫向劃分。數據中臺通過分層,劃分為原始數據層(STAGE)、細節數據層(ODS/DWD)、輕度綜合層(MID/DWS)與數據集市層(DM),如下圖所示。每一層的數據都存儲在Hive數據庫中,然后通過Schema劃分出不同的層次。
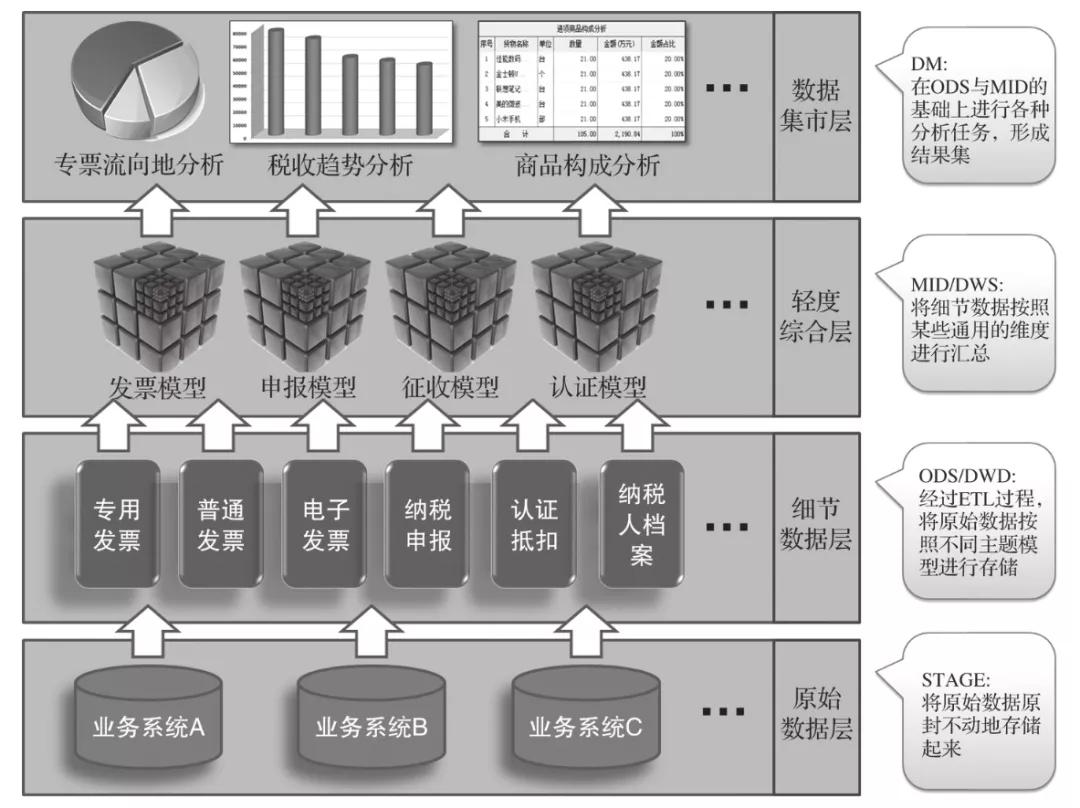
數據中臺的系統分層
最底層是原始數據層(STAGE)。所有的原始數據都在這里,通過Schema進行劃分,來自哪個數據來源就存儲在哪個Schema中,并且表名與原始庫的表名一致。
接著是細節數據層(ODS/DWD),它是經過ETL過程以后導入數據倉庫的事實表與維度表。ETL過程的中間臨時表存入名為etl的Schema,數據倉庫的事實表與維度表存入名為dw的Schema。同時,制訂命名規范,事實表以dw_fact_xxx命名,如訂單事實表dw_fact_order,維度表以dw_dim_xxx命名,如日期維度表dw_dim_date。
緊接著是輕度綜合層(MID/DWS),它是在事實表的基礎上按照不同維度與粒度形成的聚合表。聚合表以dw_agg_xxx命名,如進項發票按納稅人聚合表dw_agg_jxfp_nsr、進項發票按稅務機關聚合表dw_agg_jxfp_swjg等。
最后,是在數據倉庫之上的數據集市層(DM),它通過抽取前兩層中的事實表與聚合表的數據,按照不同的用戶需求進行數據分析,最后形成數據結果。數據集市既包括最終結果表,也包括中間結果表。數據集市以dw_dm_xxx命名,如“購車人未繳納車輛購置稅預警”屬于“機動車消費稅”分析模塊,它需要計算出應免稅數據dw_dm_jdcxfs_ms,然后計算出未繳稅數據dw_dm_jdcxfs_wjs。大多數常規數據分析就是這樣通過SparkSQL進行的。
本書摘編自《架構真意:企業級應用架構設計方法論與實踐》,經出版方授權發布。


















