













多云與混合云場景下的數據同步方案之Kafka
本文轉載自微信公眾號「明哥的IT隨筆」,作者IT明哥。轉載本文請聯系明哥的IT隨筆公眾號。
1 企業業務系統部署架構的變化趨勢-多云與混合云
現階段,企業信息系統部署架構 (DA: Deploy architecture)的一大變化是,越來越多的企業在不斷將越來越多的應用部署到云上,即業務系統上云的趨勢愈演愈烈。
不過企業業務系統上云不是一蹴而就的,也不是單向的一帆風順的。 這里涉及到新開發的業務系統的主動上云(由于是采用云原生技術棧新開發的業務系統,其上云相對順暢些),也包括歷史遺留系統的遷移上云(單個遺留系統的改造遷移和上云,視乎復雜程度,往往需要一年多甚至更長的時間周期),有時也會有從云端部署回退到私有云或數據中心的情形(上云后不順暢不適應,也有會退的場景)。
企業所有業務系統的上云,其最終目標,出于各種考量(有業務系統高可用的考量,也有不被云廠商綁定即 vendor-lockin的考量,也有生態系統合作伙伴即經濟因素等多種考量),部署架構不會是單一的某個公有云,而是多個公有云和私有云甚至本地數據中心的混合部署形態。
從技術視角看大數據行業的發展趨勢
2 多云與混合云部署架構下的難題-數據同步
如上文所說,企業的多個業務系統,長期來看,會是多云與混合云加本地數據中心的混合部署架構;同時由于多個業務系統之間并不是相互隔離的,而是需要協作交互數據的(當然一般不會是直接的 rpc/http 調用),這就涉及到一個難題:多云與混合云部署架構下的數據同步。
如果企業沒有公司層面的統一的規劃,由各個部門各個項目獨自設計與實施的部署方案,其架構會如下圖所示:
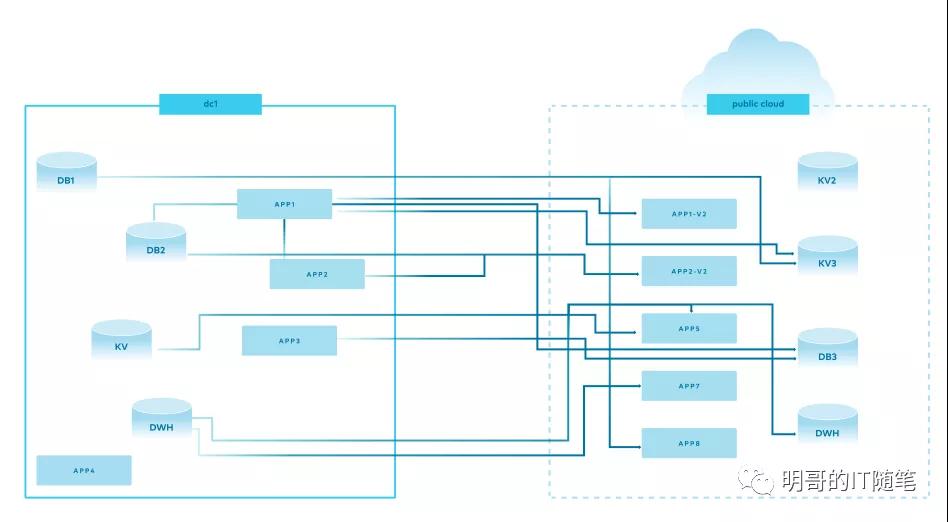
multi and hybrid cloud deploy architecture
3 多云與混合云部署架構下的數據同步方案 - KAFKA
熟悉 KAFKA 的小伙伴都知道,KAFKA 是 LinkedIn 在 201 0左右為解決企業內部繁雜多向的數據交互而推出的數據總線/中央數據管道解決方案,它簡化了 LinkedIn 的數據交互架構:
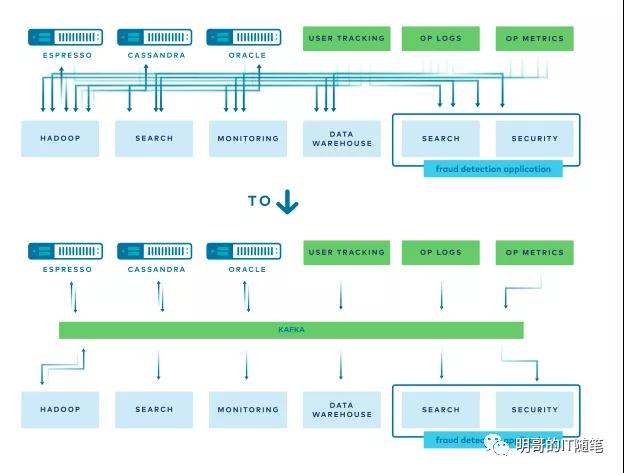
kafka-in-LinkedIn
在 LinkedIn 將 KAFKA 開源之后,由于其高吞吐低延遲的特性(順序寫和順序讀,ZeroCopy, 端到端的壓縮,基于 partition的橫向擴展),以及不斷進化獲得的其它特性(基于多副本的高可用容錯機制,EOS 有且僅有一次的語義,生產者冪等性,對ACID事務的支持,分層存儲的架構 tiered storage),還有不斷豐富擴大的生態系統 (kafka connect, kafka schema registry, 以及高層抽象 kafka stream, ksqlDB),在大數據更加注重數據時效性的今天(實時預警,實時風控,實時數倉等各種場景),在微服務更加注重松耦合的今天(微服務相互之間不再直接相互調用,而是通過同步數據來同步狀態),(站在了對的風口上,其地位水漲船高),幾乎所有的企業都或多或少在其業務系統中用到了 KAFKA (或其同類競品如 pulsa)。
既然 KAFKA 可以在企業內部作為數據總線/中央數據管道的解決方案,那么在新時代的多云與混合云部署架構下,其能否起到數據同步的作用呢?
答案是肯定的。
此時其架構如下如所示:
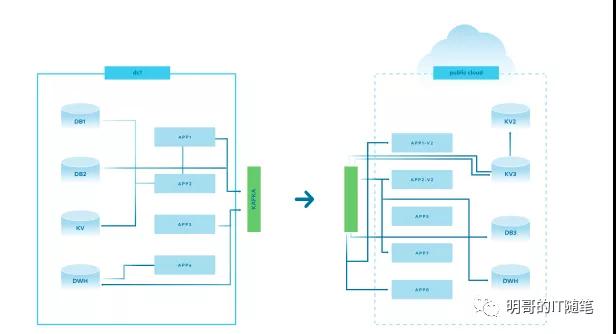
data sync in multi and hybrid cloud - kafka
該架構的要點如下:
- 本地數據中心部署一個 KAFKA 集群;
- 云端部署一個 Kafka 集群中;(如果是多云,則每個云部署一個 KAFKA 集群);
- 本地數據中心的所有應用,其數據都匯總到本地數據中心的 Kafka 集群中;(可以使用 kafka java/scala api 直接寫 kafka,也可以使用各種 cdc 工具采集 rdbms 中的 binlog/redolog 進而寫到 kafka, 可用的 cdc 工具包括 canal/maxwell/ogg/debezium等,kafka connect生態的各個 connector插件也可以使用 );
- 使用 kafka 的數據同步工具 MirrorMaker, 在數據中心與各個云端的 kafka 集群間,同步數據;
- 各個云端的應用,訪問其對應的 kafka 集群獲取數據;
該架構的優點如下:
- 多個大廠生產系統驗證了可行的多數據中心架構;
- 持續性的低延遲的數據同步方案;(在高速網絡帶寬下,延遲可達幾百毫秒);
- 集中式的管理和監控,支持集成多種安全和治理方案;
- 節約成本;
- 可以使用 KAFKA 背后的商業公司 Confluent 提供的 Confluent platform,該產品可以在數據中心/私有云/公有云部署,其架構圖如下所示:圖片
4 知識總結
- 企業IT基礎設施的一大趨勢是,上云的趨勢愈演愈烈;
- 企業業務系統上云不是一蹴而就的,也不是單向的一帆風順的;
- 未來的企業業務系統的部署架構,不會是單一的某個公有云,而是多個公有云和私有云甚至本地數據中心的混合部署形態;
- 企業業務系統在多云與混合云部署架構下有個難題,即數據同步;
- 可以使用 KAFKA 作為多云與混合云部署架構下數據同步的解決方案;
- 使用 KAFKA 作為多云與混合云部署架構下數據同步的解決方案時,本地數據中心與云端的各個云中都會部署一個 KAFKA 集群;
- 使用 KAFKA 作為多云與混合云部署架構下數據同步的解決方案時,可以使用 kafka 的數據同步工具 MirrorMaker, 在數據中心與各個云端的 kafka 集群間同步數據;
Ps: 筆者了解到,已經有一些第三方公司,基于該方案推出了其封裝版的商業產品,來解決多數據中心間的數據同步。(商機呀小伙伴們,這是塊長期的大蛋糕)。
相關資料下載:鏈接:https://pan.baidu.com/s/1FNAkwXbxQBn0tPINKPXVCg 提取碼:kafk















