跨數據庫跨系統,數據脫敏有新招(附工具下載)
作者介紹
貝殼找房DBA團隊 , 負責鏈家、貝殼找房的數據庫服務治理及運維,包括MySQL、Redis、Kafka、RocketMQ、TiDB等產品。為保證線上服務高效、安全、穩定運行,面向研發同學提供一站式的數據庫操作平臺,建設了滿足99.99%標準的高可用自動化切換平臺,并結合DBA豐富的運維經驗和機器學習算法實現了數據庫故障的自助診斷 。
引言
2021 年 9 月 1 日起《中華人民共和國數據安全法》( 以下簡稱《安全法》 )正式施行,成為了規范數據處理活動,保障數據安全,促進數據開發利用,保護個人、組織的合法權益,維護國家主權、安全和發展利益的法律依據。數據脫敏技術則是對敏感數據按需進行漂白、變形、遮蓋等處理,避免敏感信息泄露。數據脫敏工具使用、開發、平臺建設是每家互聯網公司保護用戶隱私應盡的義務。
貝殼在用戶隱私數據保護上也做了很多努力,嚴格遵守國家法律要求,本文將分享一款由貝殼 DBA 團隊開發的數據脫敏工具,即 d18n,它是 data-desensitization 的 Numeronym 縮寫,即使用 18 代替中間的 18 個字母。下面將拆解 d18n 的技術實現,讓大家了解數據安全背后的故事。
一、數據脫敏場景
從上圖可見敏感信息脫敏其實已經融入到生活的方方面面,我們看的電影,讀的小說,聽的新聞都會用到信息脫敏。以下列舉三個互聯網公司常見的三種數據脫敏場景。
場景一:測試開發
線上數據庫服務做了嚴格的權限控制和資源隔離,非授權用戶無法獲取任何數據。測試環境為了盡量仿真生產環境有時會提出使用獲取線上數據樣本的需求,但測試環境的權限控制相對較寬松,因此不可將未脫敏的數據直接導入測試環境。
場景二:數據分析
隨著大數據應用在互聯網的不斷落地,大數據分析能夠輔助公司進行產品決策,準確分析用戶行為。直接使用生產數據進行數據分析,未經管控和數據脫敏,敏感數據泄露的風險的幾率將大大增加。
場景三:數據共享
政府與企業,企業與企業,企業內應用與應用之間都有數據交換和信息共享的需求。針對不同級別的數據共享需求,要制定不同的數據脫敏方案。在保護好公司核心數據資產的情況下,為政企合作、企業合作、服務迭代提供數據安全保障。
二、跨平臺數據脫敏

d18n 工具使用 Go 語言開發,在設計選型時它特意避開了部分依賴 CGO 的數據庫驅動,因此它是完全跨平臺的,可以直接在 Windows、Linux、Mac 系統中使用,即使是最新的 Apple Silicon MacBook Pro 也可功能無損支持。
由于 d18n 開發時 Go 1.16 已經支持了 embed 功能,它原生支持將靜態資源與二進制程序一起打包。在數據脫敏和敏感信息識別時需要使用的語料包已經被 d18n 打包封裝好了,因此無需再下載任何其他靜態資源文件,真正做到開箱即用。這一點對于目前流行的容器化環境來說也是特別友好的。
d18n 的跨平臺不僅體現在操作系統級別的跨平臺上,它對數據庫平臺的支持也是多樣化的。除了互聯網公司最常使用的 MySQL 數據庫,d18n 還支持 Oracle、SQL Server、PostgreSQL 等等多種關系型數據庫。可以說,只要是使用 SQL 語言的數據庫,只要它有 Pure Go 驅動,d18n 都能支持。很多同學甚至直接把 d18n 當作一個簡單的數據庫命令行查詢工具使用,帶來跨平臺一致性的用戶體驗。
d18n 支持導出、導入的文件類型相對也比較豐富,有絕大多數人都熟悉的 Excel, TXT,也有對應用程序友好的 CSV、JSON、SQL、HTML 等文件格式。無論是交給人用肉眼閱讀,還是交給程序做自動化處理,d18n 都應付得來。
三、敏感數據識別
前面講了很關于多跨平臺的友好性,一款數據脫敏工具用戶真正看重的是它對敏感數據的識別和處理能力上,這一節開始將進入硬核知識介紹。
關系型數據庫敏感數據識別常用的算法有“關鍵字匹配”和“正則匹配”。d18n 當然也不能免于俗套,這兩項技術也是妥妥的支持。更有誠意的是,d18n 還一并提供了敏感信息識別使用的通用規則庫。對于想“偷懶”的同學,它能讓你開箱即用;對于“勤奮”的同學,你也可以參照模板進行深度自定義且無需修改源碼。
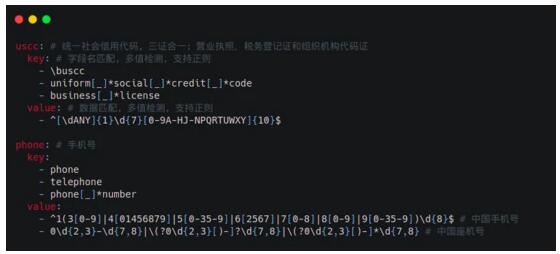
在傳統技術基礎之上,為了進一步提高敏感數據發現能力,d18n 還引入了自然語言處理包 (gse),它將語料庫轉化成 Trier 數據結構,通過有窮自動機算法 (DFA) 來匹配經過自動分詞的數據。
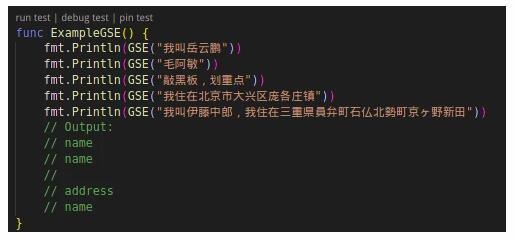
自然語言處理識別敏感數據的核心難點是如何生成精準有效的語料庫,一個有效語料庫通常是針對真實的數據集進行機器學習訓練得到的。d18n 中提供的關于地址、姓名的語料庫模板并非真實數據訓練得到僅供用戶參考。下面是 d18n 中應用自然語言處理來識別敏感信息的測試用例。
敏感信息存儲主動申報已經深深的融入到了貝殼的各項流程制度中,機器識別做為一個有效的補充可以幫助業務查缺補漏,及時發現可能存在的隱患。
四、數據脫敏導出
有了全平臺的敏感數據信息,接下來就是如何做好數據脫敏工作,綜合整理法律合規以及來自不同業務方的需求,主要有以下幾點。
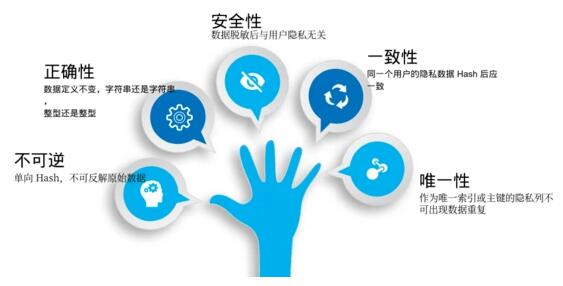
為了滿足上面五點需求,本文從六個維度出發(即:無效化、隨機化、數據替換、加密替換、差分隱私、偏移取整)分別介紹數據脫敏算法實現。
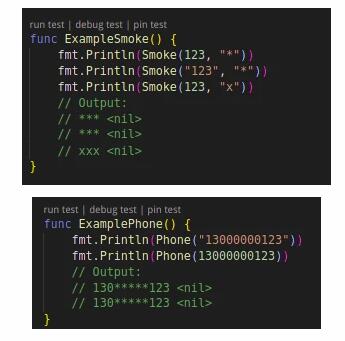
首先是“無效化”,在處理待脫敏的數據時,通過對字段數據值進行截斷、加密、隱藏等方式讓敏感數據脫敏,使其不再具有利用價值。一般采用特殊字符(*等)代替真值。以下是 d18n 中 smoke 和 phone 兩個算法的測試用例展示。
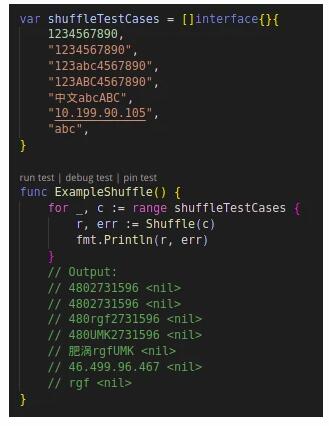
其次是“隨機化”,隨機值替換,字母變為隨機字母,數字變為隨機數字,這種方案可以在一定程度上保留原有數據的格式,且不可打破數據的唯一性約束。d18n 中內置了常用漢字的語料庫,中文默認也可以做隨機化替換。
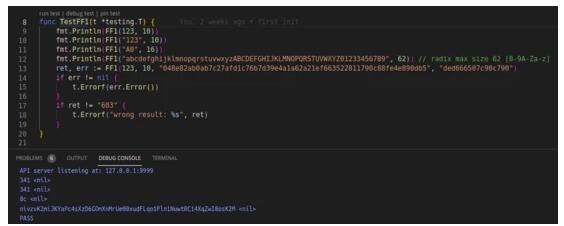
對于 ASCII 碼表中的字符,d18n 還集成了先進的 FPE(Format Preserving Encryption) 算法,進一步保證了數據的“不可逆”性。
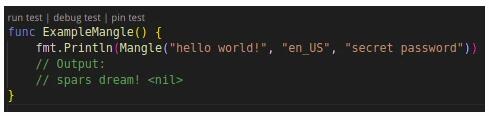
除了單個字符的隨機化,d18n 還支持單詞級別的隨機化替換,可保持語句長度及標點符號不變。根據用戶生成的語料庫不同,支持不同語言的單詞替換。下面是一個英文替換的例子。
第三是“數據替換”,數據替換與“無效化”方式比較相似,不同的是這里不以特殊字符進行遮擋,而是用一個設定的虛擬值替換真值。比如說將 IP 統一設置成 “127.0.0.1”。
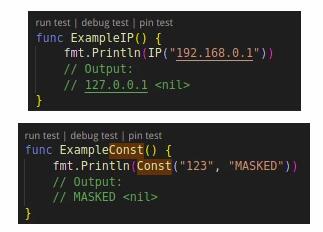
第四是“加密替換”,d18n 支持對稱加密算法和非對稱加密算法。數據加密是一種特殊的可逆脫敏方法,通過密鑰和算法對敏感數據進行加密,已知密鑰和算法可解密恢復原始數據,要注意密鑰的安全性。雖然 d18n 也支持 RSA,ECC 等數據加密算法,但 d18n 不會生成密鑰文件、也不保留加密密鑰,更不提供解密支持。

第五是“差分隱私”,它是密碼學中的詞匯,旨在提供一種當從統計數據庫查詢時,最大化數據查詢的準確性,同時最大限度減少識別其記錄的機會。d18n 使用了 Google 開源的 github.com/google/differential-privacy 包實現了這部分能力。
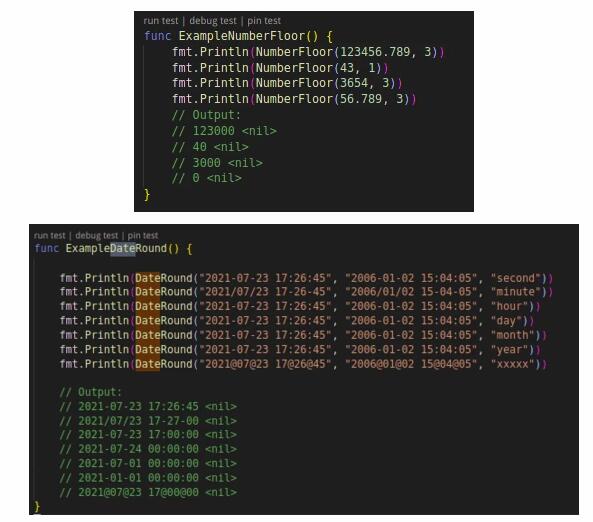
第六是“偏移取整”,這種方式通過數據移位去除隱私信息,偏移取整在保持了數據的安全性的同時保證了范圍的大致真實性,比之前幾種方案更接近真實數據。下面兩個例子分別是對數值類型取整和對時間類型取整。
五、數據脫敏導入
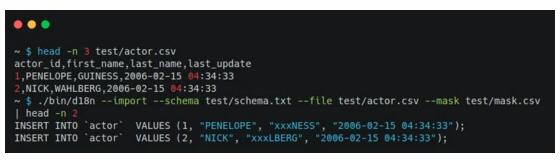
至此僅實現了把數據庫中的數據脫敏后共享給使用方的需求,如果有同學給了一份未脫敏的數據文件讓你導入到測試環境呢?d18n 也支持對 Excel、TXT、CSV、HTML、JSON 等格式的文件進行二次脫敏生成 SQL,可生成 SQL 文件,也可直接連接數據庫導入至數據庫中查看。
總結
d18n 中引入了很多優秀的第三方開源 Library,它雖然是一個命令行工具,但作者們更想把它作為一個 Library 來開發,這樣可以更好的回饋給開源社區,也給 d18n 帶來更多的可能。命令行工具提供的是靜態數據脫敏能力,可以用于日常學習、測試。基于 d18n 這個 Library 相信你也不難實現適用各家公司自己的動態數據脫敏平臺。保護用戶隱私數據每一個人都責無旁貸,期待社區能夠涌現更多優秀的產品共同提高數據安全水平。
> > > >
開源地址
【項目文檔】https://github.com/LianjiaTech/d18n/blob/main/doc/toc.md
【Github地址】https://github.com/LianjiaTech/d18n
【Issue 反饋】https://github.com/LianjiaTech/d18n/issues