













全面介紹Prometheus的官方導出器Blackbox
譯文【51CTO.com快譯】眾所周知,Prometheus是一個開源的、基于指標的監控系統。它能夠通過強大的數據模型和查詢語言,來分析應用程序和基礎架構的執行方式與狀態。目前,Prometheus棧是由多個部分組成,其中包括:負責存儲和提供數據的Prometheus服務器、負責管理警告的警報管理器、以及具體執行指標收集任務的大量Prometheus導出器。導出器通過從一個應用程序處獲取統計信息,并將它們公布給特定的端點(通常是某個端口和路徑),以允許遠程Prometheus服務器收集到此類指標。
在應用社區中,我們可以輕松地獲取各種導出器。它們有的是作為官方的Prometheus GitHub組織的一部分被維護,其他則是由外部貢獻者進行維護的。我們即將介紹到的Blackbox,便是一種由Prometheus組織維護的官方導出器。
作為一種導出工具,Blackbox能夠協助系統管理員執行HTTP/S、DNS、TCP和ICMP端點的可用性檢查等日常任務。簡單而言,我們可以將Prometheus Blackbox導出器視為PingDOM、Freshping或Uptime.com等工具的免費、簡單替代品,可以被用于監控那些未在互聯網上公布的內部端點。
為什么需要Prometheus Blackbox?
Prometheus Blackbox導出器的主要功能是檢測遠程的內、外部端點,在HTTP/S、DNS、TCP和ICMP等方面的響應時間。其具體捕獲的指標包括:
- HTTP延遲 - 訪問遠程端點需要多長時間?
- DNS查找延遲 - 解析DNS記錄需要多長時間?
- SSL證書信息 - 遠程端點是否安全?是否持有有效的證書?證書的有效期到何時?
- TLS版本 - 遠程端點使用什么版本的TLS?
- 基本身份驗證 – 是否可以在遠程端點上運行一個簡單的網絡場景,比如身份驗證?
- 標頭(Header)驗證 – 是否可以在HTTP標頭中找到必需的參數?其標頭是否符合安全合規性?
這些指標對于應用基礎架構來說,都是重要的組成部分。我們需要通過針對各個面向客戶(外部)和內部端點的持續監控,以確保應用服務的連續性,以及某些安全認證的合規性。
應用程序通常需要顯性地將各種客戶端庫添加到代碼之中,以公布出待檢測的指標。而Blackbox則會隱性地驗證諸如:DNS解析、網絡連接、證書頒發機構(CA)等外部服務的狀態,而且側重于檢測應用程序的性能。因此,Blackbox通常會被部署在 Kubernetes集群上,提供免費、具有高度可用性的監控過程,以全面了解遠程端點。
如何部署
與其他Prometheus導出器類似,Blackbox可以被部署在任何操作系統上,或以容器的形式被部署。不過,鑒于其主要目的是為了監控應用基礎架構的關鍵方面,因此我強烈建議您將其部署在容器編排的平臺上,并發揮如下優勢:
- 高可用性 – 作為最重要的方面,保證監控工具的可用性,是每位管理員的頭等大事。
- 可擴展性 - 根據檢查的次數需要,Blackbox可以按需擴展。
- 可移植性 – 由于無法預知應用基礎架構的演變,因此我們需要確保可以在本地或云端,以不同的方式流暢地部署該工具。這也是其作為監控棧的另一個重要方面。
- 靈活性 – 能夠與Kubernetes等現有平臺輕松地集成。這是該工具的一大優勢所在。
由于Blackbox是由Prometheus組織在GitHub上管理的官方導出器,因此Helm chart能夠很容易地被部署到Kubernetes群集上。具體設置與部署,請參見如下命令行:
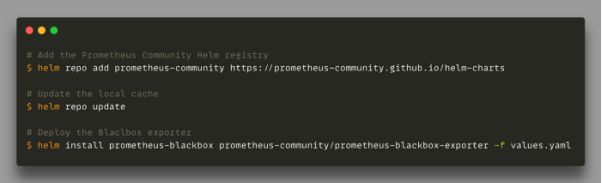
部署Prometheus
由于在完成默認安裝后,它會自帶有了一個簡單的HTTP探測器,因此我們可以輕松地啟動針對不同HTTP/S端點的監控。
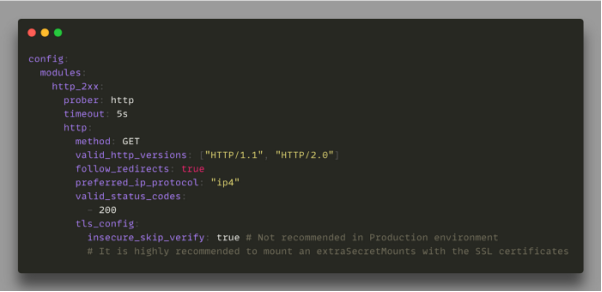
Prometheus的默認安裝
Blackbox會帶有一個簡單的Web UI,可以輕松地訪問到每個健康檢查服務的日志。您可以在Helm chart中啟用一個入口規則(ingress rule),以開啟對于UI的訪問,并調試針對的各項Web檢查:
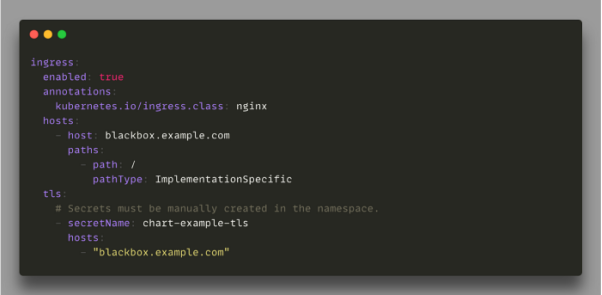
用Blackbox進行健康檢查
為何以及如何使用Kubernetes ServiceMonitor
如今,監控不再只是某個專職團隊的任務。它往往會被分散到各個協作團隊,以確保能夠覆蓋到應用架構的每個部分。因此,我們只有讓整個監測過程越易于被理解,也就越易于被頻繁使用。
為此,Prometheus operator引入了一個名為ServiceMonitor的全新Kubernetes對象。該資源可以被用于描述Prometheus監控的一組目標,而無需在Prometheus服務器端進行任何額外的配置。
通過這種自動化配置Prometheus新目標的簡單方法,服務器就能夠找到任何被配置了特定標簽的Kubernetes ServicesMonitor,并自動將其添加到當前的列表中(默認情況下,它使用的標簽是“release=kube-prometheus-stack”)。
我們推薦您使用帶有Blackbox的ServiceMonitor對象,去監視各個內、外部端點。值得注意的是,添加新的檢測節點屬于創建的獨立對象,它是與Prometheus服務器的配置相分離的。這就意味著任何想要部署新應用的運維人員,都可以獨立地管理對其應用的監控,而無需借助管理員的干預,去配置Prometheus scratch。這樣設計的主要好處在于,它分擔了運維人員對于每個部署資源進行監控的責任。
如下配置所示,Blackbox Helm chart也可以通過ServiceMonitor,去輕松創建并管理任何新加入到監控目標。
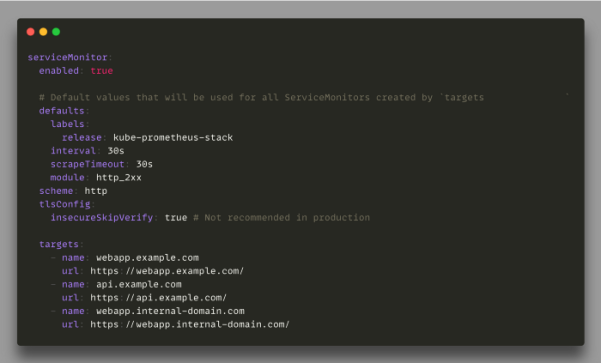
可用于服務監控的Blackbox Helm chart
上述配置命令的結果是創建了三個具有特定標簽:kube-prometheus-stack的不同ServiceMonitor對象。每個對象都被專用于配置新的Prometheus目標。
如何繪制數據圖表
Blackbox自帶有一個Web UI,可提供檢測的相關信息。不過,該UI無法持續被用來監控多個端點的狀態。對此,為了繪制由Prometheus導出器收集到的指標圖表,我們需要根據默認選項,將Grafana與Prometheus相集成。
具體說來,我們可以通過如下兩種Blackbox儀表板,來構建可讀的數據圖表。
- 9115-blackbox - 在單個圖表中,提供所有受監控端點的整體概覽,以快速獲取每個端點的狀態。
- Prometheus Blackbox Exporter - 在每個端點的專用部分,提供每個受監控端點的概覽。
當然,我們也可以將上述儀表板合并在一起,通過優化和渲染,一站式地呈現數據,以避免將同一數據源的儀表板數量翻倍。如果您想了解更多的儀表板類型,請參見--https://grafana.com/grafana/dashboards?search=blackbox。
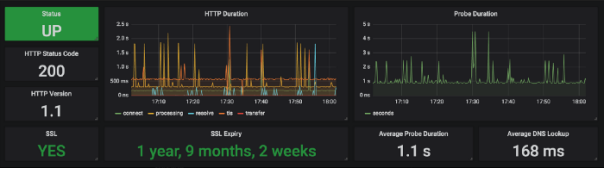
通過合并兩個儀表板,以實現更好的可視化
小結
作為一種新的導出器,Blackbox可以輕松地被部署到Prometheus平臺上,以檢測應用基礎架構的關鍵指標。通過將其與Grafana儀表板動態結合,我們不但可以改進SLA的檢測質量,還能夠為執行團隊提供應用基礎架構的整體概覽。如果您有興趣了解更多有關Prometheus Blackbox的信息,請參見:
- Github 存儲庫
- 在Kubernetes上部署Blackbox的Helm chart
- 使用Blackbox導出器和Sysdig來監控各項可用性指標
- Prometheus和Blackbox導出器如何讓監控微服務端點變得簡單且免費
- Prometheus operator入門
原文標題:Prometheus Blackbox: What? Why? How?,作者: Nicolas Giron
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】











