多種邊緣集群管理方案對比選型
本文轉載自微信公眾號「運維開發故事」,作者Double_冬&華子。轉載本文請聯系運維開發故事公眾號。
1.背景
邊緣計算平臺,旨在將邊緣端靠近數據源的計算單元納入到中心云,實現集中管理,將云服務部署其上,及時響應終端請求。然而,成千上萬的邊緣節點散布于各地,例如銀行網點、車載節點、加油站等基于一些邊緣設備管理場景,服務器分散在不同城市,無法統一管理,為了優化集群部署以及統一管理,特探索邊緣計算場景方案。
2.邊緣計算挑戰
邊緣計算框架在 Kubernetes 系統里,需要解決下面的問題:
- 網絡斷連時,節點異常或重啟時,內存數據丟失,業務容器無法恢復;
- 網絡長時間斷連,云端控制器對業務容器進行驅逐;
- 長時間斷連后網絡恢復時,邊緣和云端數據的一致性保障。
- 網絡不穩定下,K8S client ListWatch機制下為保證數據一致性,在每次重連時都需要同步ReList一次,較大規模的邊緣節點數量加以較不穩定的網絡,將造成巨大的網絡開銷和API Server的cpu負擔,特別是不可靠的遠距離跨公網場景。
3.方案選型
- KubeEdge
- Superedge
- Openyurt
- k3s
3.1. KubeEdge
3.1.1 架構簡介
KubeEdge是首個基于Kubernetes擴展的,提供云邊協同能力的開放式智能邊緣平臺,也是CNCF在智能邊緣領域的首個正式項目。KubeEdge重點要解決的問題是:
- 云邊協同
- 資源異構
- 大規模
- 輕量化
- 一致的設備管理和接入體驗
KubeEdge的架構如下所示:
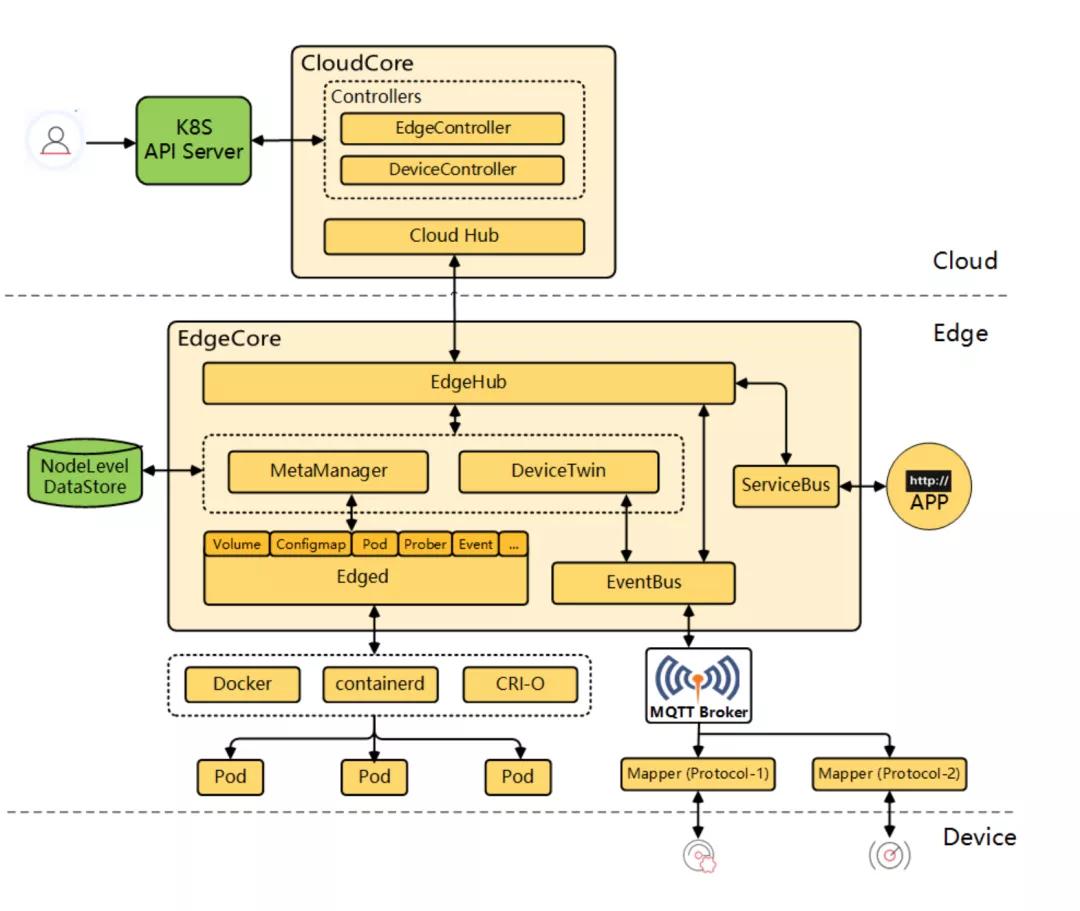
KubeEdge架構上清晰地分為三層,分別是:云端、邊緣和設備層。
云端
KubeEdge的云端進程包含以下2個組件:
- cloudhub部署在云端,接收edgehub同步到云端的信息;
- edgecontroller部署在云端,用于控制Kubernetes API Server與邊緣的節點、應用和配置的狀態同步。
Kubernetes maser運行在云端,用戶可以直接通過kubectl命令行在云端管理邊緣節點、設備和應用,使用習慣與Kubernetes原生的完全一致,無需重新適應。
邊緣
KubeEdge的邊緣進程包含以下5個組件:
- edged是個重新開發的輕量化Kubelet,實現Pod,Volume,Node等Kubernetes資源對象的生命周期管理;
- metamanager負責本地元數據的持久化,是邊緣節點自治能力的關鍵;
- edgehub是多路復用的消息通道,提供可靠和高效的云邊信息同步;
- devicetwin用于抽象物理設備并在云端生成一個設備狀態的映射;
- eventbus訂閱來自于MQTT Broker的設備數據。
網絡
KubeEdge 邊云網絡訪問依賴EdgeMesh:
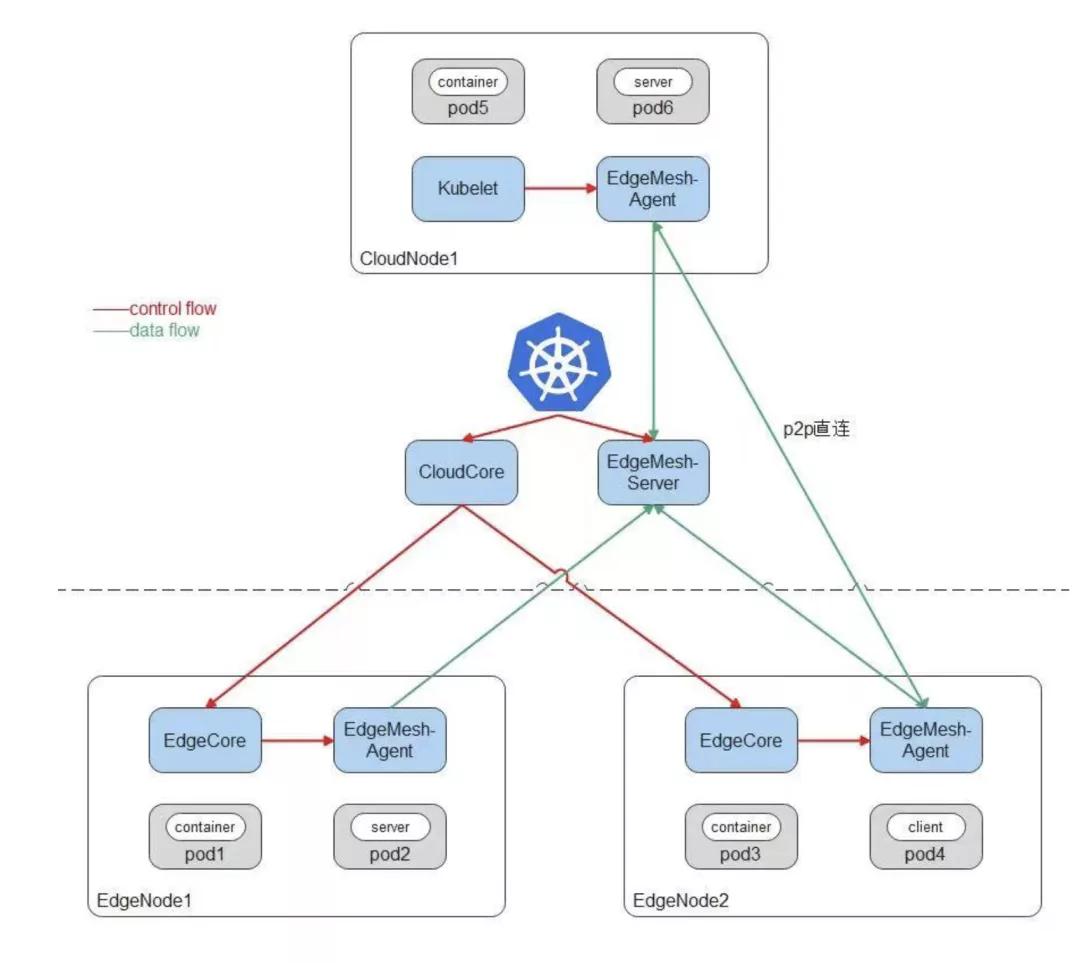
云端是標準的Kubernetes集群,可以使用任意CNI網絡插件,比如Flannel、Calico;可以部署任意Kubernetes原生組件,比如Kubelet、KubeProxy;同時云端部署KubeEdge云上組件CloudCore,邊緣節點上運行KubeEdge邊緣組件EdgeCore,完成邊緣節點向云上集群的注冊。
EdgeMesh包含兩個組件:EdgeMesh-Server和每個節點上的EdgeMesh-Agent。
EdgeMesh-Server工作原理:
- EdgeMesh-Server運行在云上節點,具有一個公網IP,監聽來自EdgeMesh-Agent的連接請求,并協助EdgeMesh-Agent之間完成UDP打洞,建立P2P連接;
- 在EdgeMesh-Agent之間打洞失敗的情況下,負責中繼EdgeMesh-Agent之間的流量,保證100%的流量中轉成功率。
EdgeMesh-Agent工作原理:
- EdgeMesh-Agent的DNS模塊,是內置的輕量級DNS Server,完成Service域名到ClusterIP的轉換。
- EdgeMesh-Agent的Proxy模塊,負責集群的Service服務發現與ClusterIP的流量劫持。
- EdgeMesh-Agent的Tunnel模塊,在啟動時,會建立與EdgeMesh-Server的長連接,在兩個邊緣節點上的應用需要通信時,會通過EdgeMesh-Server進行UDP打洞,嘗試建立P2P連接,一旦連接建立成功,后續兩個邊緣節點上的流量不需要經過EdgeMesh-Server的中轉,進而降低網絡時延。
3.1.2 實踐
根據官方文檔《Deploying using Keadm | KubeEdge》進行部署測試
| 類型 | ip | 系統版本 | 架構 | 集群版本 | 端口開放 |
|---|---|---|---|---|---|
| 云端 | 47.108.201.47 | Ubuntu 18.04.5 LTS | amd64 | k8s-v1.19.8 + kubeedge-v1.8.1 | 開放端口 10000-10005 |
| 邊緣 | 172.31.0.153 | Ubuntu 18.04.5 LTS | arm64 | kubeedge-v1.8.1 |
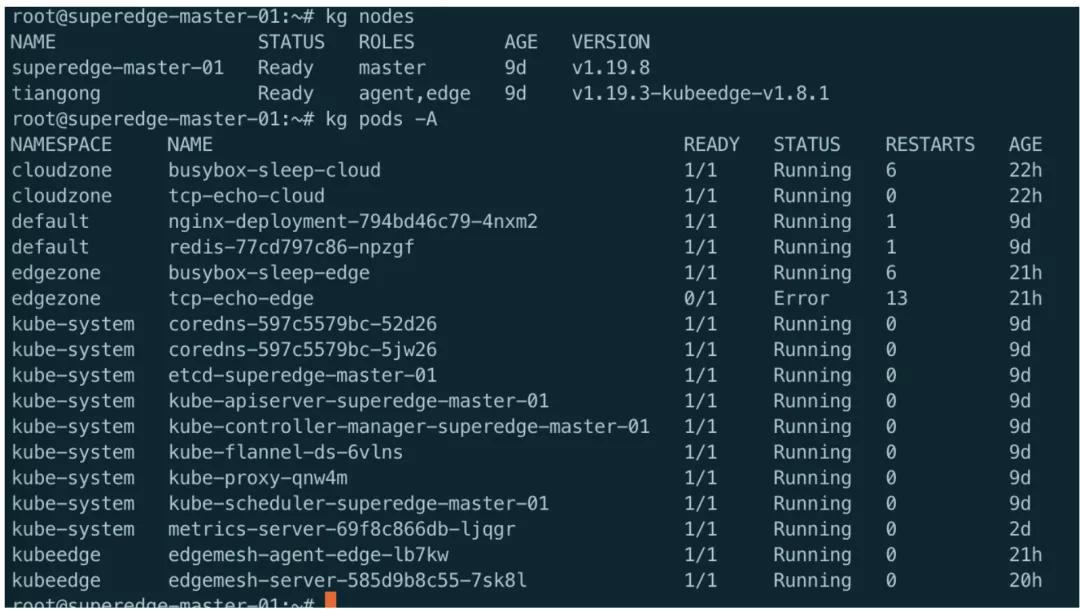
實踐結論:
根據官方文檔部署,邊緣節點可以正常加入集群,可以正常部署服務至邊緣節點,部署edgemesh測試服務訪問,邊緣可以通過svc訪問云端服務,但是云端無法通過svc訪問邊緣,邊緣節點服務之間無法通過svc進行訪問。
3.2. Superedge
3.2.1 架構簡介
SuperEdge是騰訊推出的Kubernetes-native邊緣計算管理框架。相比openyurt以及kubeedge,SuperEdge除了具備Kubernetes零侵入以及邊緣自治特性,還支持獨有的分布式健康檢查以及邊緣服務訪問控制等高級特性,極大地消減了云邊網絡不穩定對服務的影響。
整體架構:
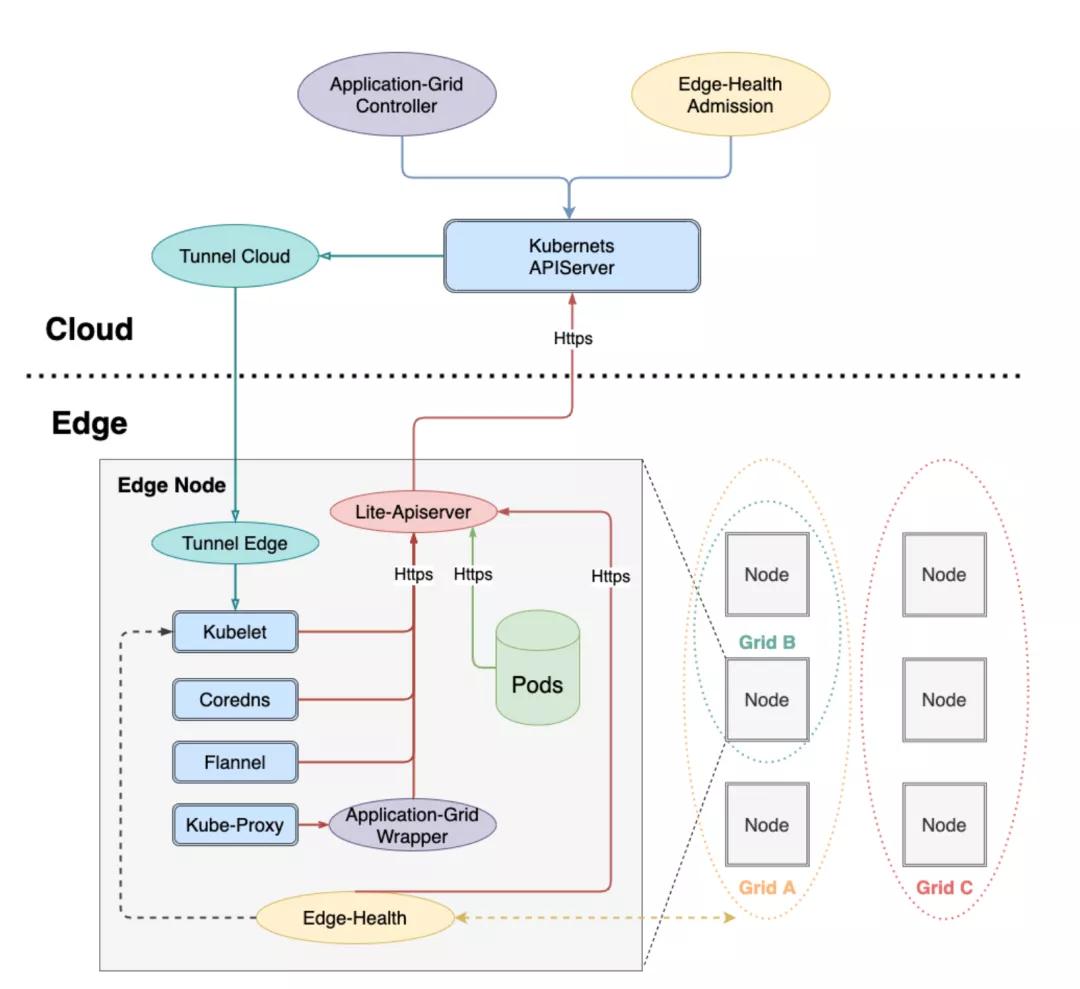
組件功能總結如下:
云端組件
云端除了邊緣集群部署的原生Kubernetes master組件(cloud-kube-APIServer,cloud-kube-controller以及cloud-kube-scheduler)外,主要管控組件還包括:
- tunnel-cloud:負責維持與邊緣節點tunnel-edge的網絡隧道,目前支持TCP/HTTP/HTTPS協議。
- application-grid controller:服務訪問控制ServiceGroup對應的Kubernetes Controller,負責管理DeploymentGrids以及ServiceGrids CRDs,并由這兩種CR生成對應的Kubernetes deployment以及service,同時自研實現服務拓撲感知,使得服務閉環訪問。
- edge-admission:通過邊端節點分布式健康檢查的狀態報告決定節點是否健康,并協助cloud-kube-controller執行相關處理動作(打taint)。
邊緣組件
邊端除了原生Kubernetes worker節點需要部署的kubelet,kube-proxy外,還添加了如下邊緣計算組件:
- lite-apiserver:邊緣自治的核心組件,是cloud-kube-apiserver的代理服務,緩存了邊緣節點組件對APIServer的某些請求,當遇到這些請求而且與cloud-kube-apiserver網絡存在問題的時候會直接返回給client端。
- edge-health:邊端分布式健康檢查服務,負責執行具體的監控和探測操作,并進行投票選舉判斷節點是否健康。
- tunnel-edge:負責建立與云端邊緣集群tunnel-cloud的網絡隧道,并接受API請求,轉發給邊緣節點組件(kubelet)。
- application-grid wrapper:與application-grid controller結合完成ServiceGrid內的閉環服務訪問(服務拓撲感知)。
3.2.2 實踐
根據官方文檔《superedge/README_CN.md at main · superedge/superedge (github.com)》部署測試
| 類型 | ip | 系統版本 | 架構 | 集群版本 | 端口開放 |
|---|---|---|---|---|---|
| 云端 | 47.108.201.47 | Ubuntu 18.04.5 LTS | amd64 | k8s-v1.19.8 + kubeedge-v1.8.1 | 開放端口 10000-10005 |
| 邊緣 | 172.31.0.153 | Ubuntu 18.04.5 LTS | arm64 | kubeedge-v1.8.1 |
實踐結論:
根據官方文檔部署,邊緣節點可以正常加入集群,但是無法部署服務至邊緣節點,提了issue未回復,其他測試未再進行
3.3. Openyurt
3.3.1. 架構簡介
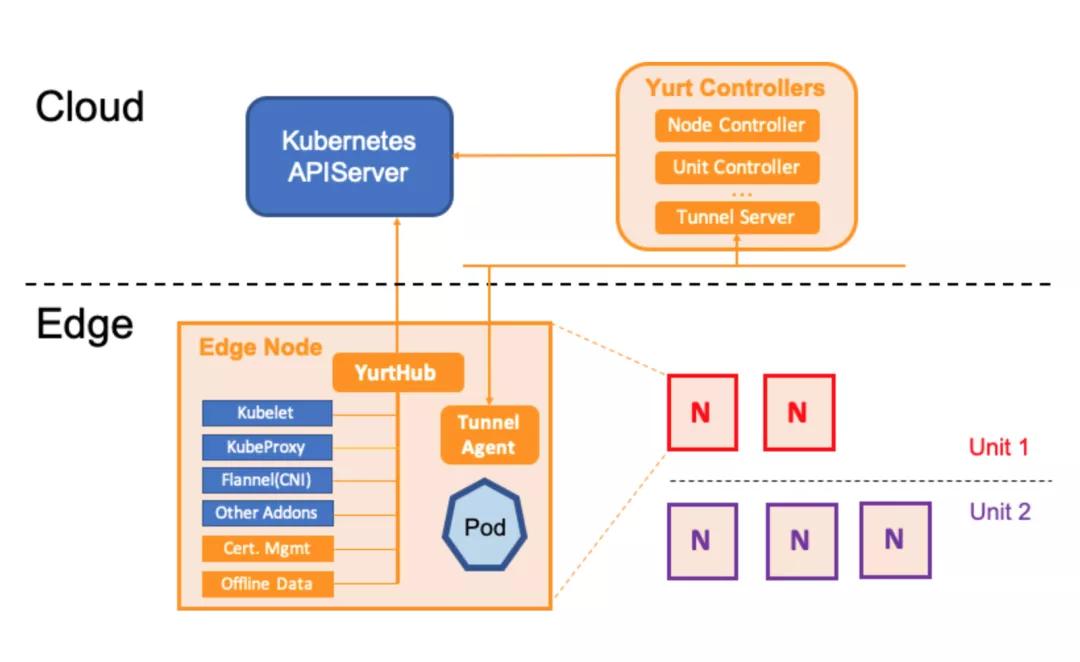
OpenYurt的架構設計比較簡潔,采用的是無侵入式對Kubernetes進行增強。在云端(K8s Master)上增加Yurt Controller Manager, Yurt App Manager以及Tunnel Server組件。而在邊緣端(K8s Worker)上增加了YurtHub和Tunnel Agent組件。從架構上看主要增加了如下能力來適配邊緣場景:
- YurtHub: 代理各個邊緣組件到K8s Master的通信請求,同時把請求返回的元數據持久化在節點磁盤。當云邊網絡不穩定時,則利用本地磁盤數據來用于邊緣業務的生命周期管控。同時云端的Yurt Controller Manager會管控邊緣業務Pod的驅逐策略。
- Tunnel Server/Tunnel Agent: 每個邊緣節點上的Tunnel Agent將主動與云端Tunnel Server建立雙向認證的加密的gRPC連接,同時云端將通過此連接訪問到邊緣節點及其資源。
- Yurt App Manager:引入的兩個CRD資源: NodePool 和 UnitedDeployment. 前者為位于同一區域的節點提供批量管理方法。后者定義了一種新的邊緣應用模型以節點池維度來管理工作負載。
3.3.2 實踐
只根據官方文檔了解其架構,未進行部署測試。
3.4. K3s
3.4.1 架構簡介
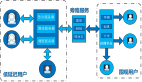
K3S是CNCF官方認證的Kubernetes發行版,開源時間較KubeEdge稍晚。K3S專為在資源有限的環境中運行Kubernetes的研發和運維人員設計,目的是為了在x86、ARM64和ARMv7D架構的邊緣節點上運行小型的Kubernetes集群。K3S的整體架構如下所示:
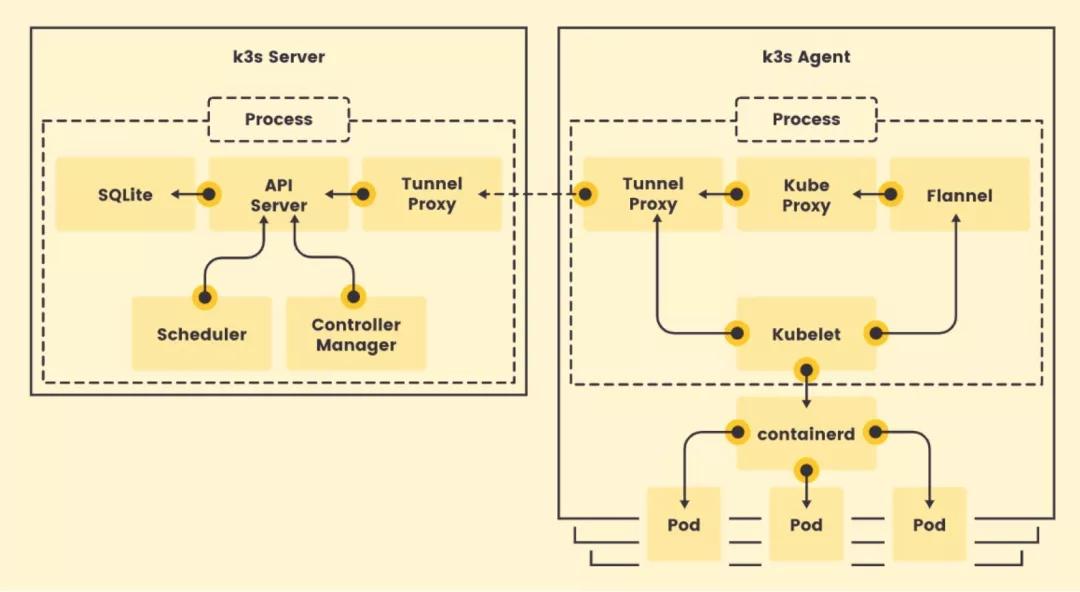
事實上,K3S就是基于一個特定版本Kubernetes(例如:1.13)直接做了代碼修改。K3S分Server和Agent,Server就是Kubernetes管理面組件 + SQLite和Tunnel Proxy,Agent即Kubernetes的數據面 + Tunnel Proxy。
為了減少運行Kubernetes所需的資源,K3S對原生Kubernetes代碼做了以下幾個方面的修改:
- 刪除舊的、非必須的代碼。K3S不包括任何非默認的、Alpha或者過時的Kubernetes功能。除此之外,K3S還刪除了所有非默認的Admission Controller,in-tree的cloud provider和存儲插件;
- 整合打包進程。為了節省內存,K3S將原本以多進程方式運行的Kubernetes管理面和數據面的多個進程分別合并成一個來運行;
- 使用containderd替換Docker,顯著減少運行時占用空間;
- 引入SQLite代替etcd作為管理面數據存儲,并用SQLite實現了list/watch接口,即Tunnel Proxy;
- 加了一個簡單的安裝程序。K3S的所有組件(包括Server和Agent)都運行在邊緣,因此不涉及云邊協同。如果K3S要落到生產,在K3S之上應該還有一個集群管理方案負責跨集群的應用管理、監控、告警、日志、安全和策略等。
3.4.2 實踐
官方文檔:https://docs.rancher.cn/docs/k3s/installation/install-options/_index
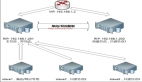
運維架構圖
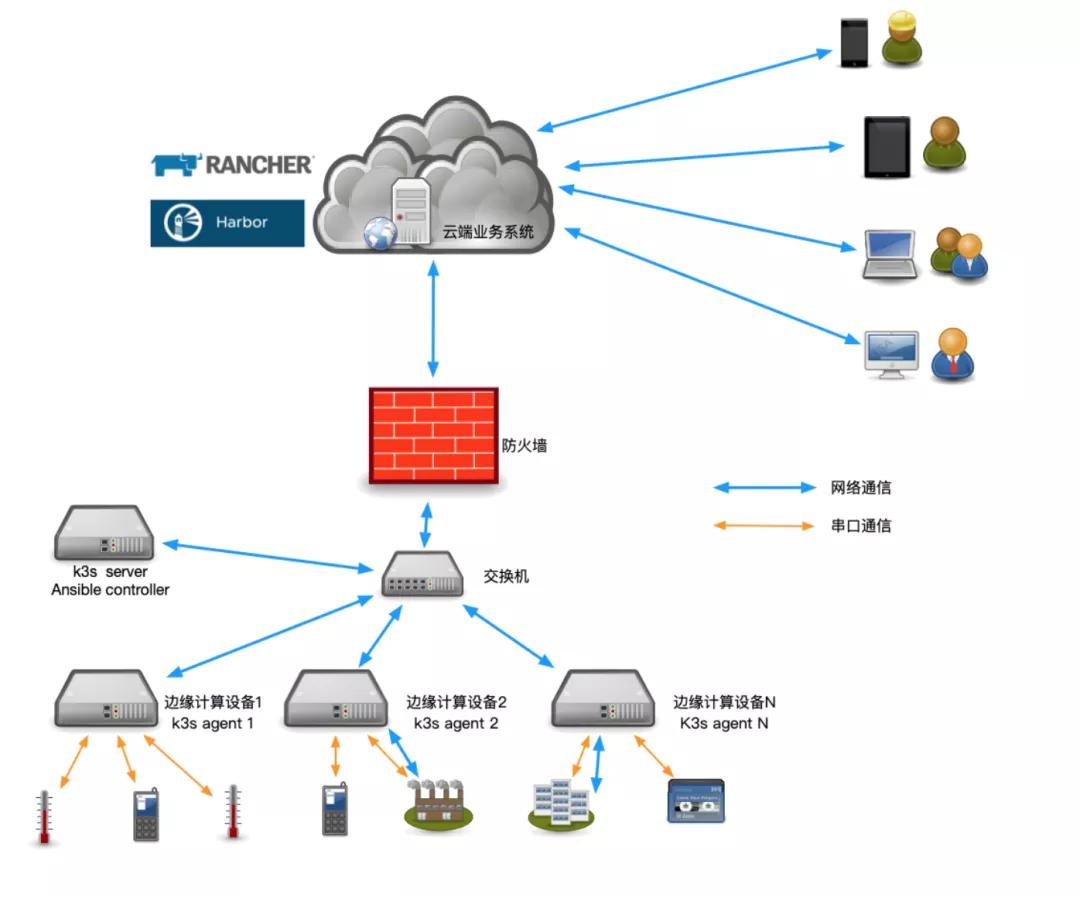
節點信息
k3s server—192.168.15.252
k3s agent—192.168.15.251
注意點:server一定要有免密登錄agent權限!!!
總體思路
K3S部署Kubernetes集群,創建集群的https證書,Helm部署rancher,通過rancher的UI界面手動導入Kubernetes集群,使用Kubernetes集群。
使用腳本安裝 Docker
- 安裝GPG證書
- curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
- #寫入軟件源信息
- sudo add-apt-repository "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
- sudo apt-get -y update
- #安裝Docker-CE
- sudo apt-get -y install docker-ce
Kubernetes部署
在rancher中文文檔中推薦了一種更輕量的Kubernetes集群搭建方式:K3S,安裝過程非常簡單,只需要服務器能夠訪問互聯網,執行相應的命令就可以了。
k3s server主機執行命令,執行完成后獲取master主機的K3S_TOKEN用于agent節點安裝(默認路徑:/var/lib/rancher/k3s/server/node-token)。
- curl -sfL http://rancher-mirror.cnrancher.com/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn INSTALL_K3S_EXEC="--docker" sh -s - server
k3s agent主機執行命令,加入K3S集群。
- curl -sfL http://rancher-mirror.cnrancher.com/k3s/k3s-install.sh | INSTALL_K3S_MIRROR=cn INSTALL_K3S_EXEC="--docker" K3S_URL=https://192.168.15.252:6443 K3S_TOKEN=K10bb35019b1669197e06f97b6c14bb3b3c7c7076cd20afe1f550d6793d02b9eed8::server:9599c8b3ffbbd38b7721207183cd6a62 sh -
http://rancher-mirror.cnrancher.com/k3s/k3s-install.sh是國內的加速地址,可以正常執行。
執行完畢后,在server服務器上驗證是否安裝K3S集群成功。

4. 對比
上述四種開源方案,其中KubeEdge、SuperEdge、OpenYurt,遵循如下部署模型:
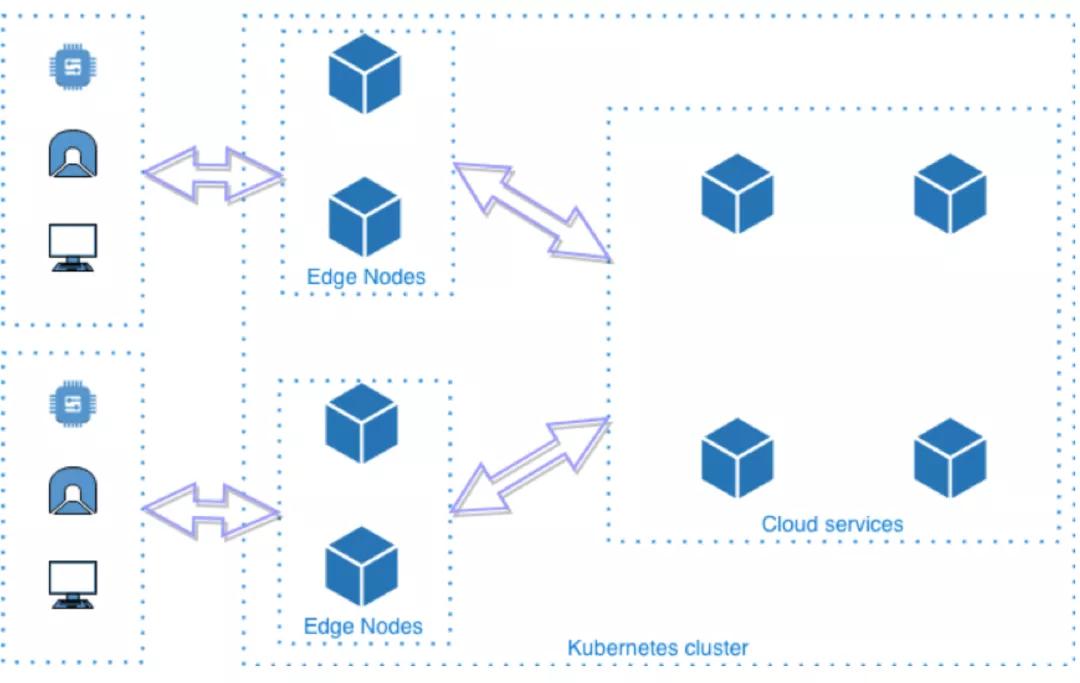
是一種完全去中心化的部署模式,管理面部署在云端,邊緣節點無需太多資源就能運行Kubernetes的agent,云邊通過消息協同。從Kubernetes的角度看,邊緣節點 + 云端才是一個完整的Kubernetes集群。這種部署模型能夠同時滿足“設備邊緣”和“基礎設施邊緣”場景的部署要求。
所以先基于這三種方案對比如下:
| 項目 | 華為KubeEdge | 阿里OpenYurt | 騰訊SuperEdge |
|---|---|---|---|
| 是否CNCF項目 | 是(孵化項目) | 是(沙箱項目) | 否 |
| 開源時間 | 2018.11 | 2020.5 | 2020.12 |
| 侵入式修改Kubernetes | 是 | 否 | 否 |
| 和Kubernetes無縫轉換 | 無 | 有 | 未知 |
| 邊緣自治能力 | 有(無邊緣健康檢測能力) | 有(無邊緣健康檢測能力) | 有(安全及流量消耗待優化) |
| 邊緣單元化 | 不支持 | 支持 | 支持(只支持Deployment) |
| 是否輕量化 | 是(節點維度待確認) | 否 | 否 |
| 原生運維監控能力 | 部分支持 | 全量支持 | 全量支持(證書管理及連接管理待優化) |
| 云原生生態兼容 | 部分兼容 | 完整兼容 | 完整兼容 |
| 系統穩定性挑戰 | 大(接入設備數量過多) | 大(大規模節點并且云邊長時間斷網恢復) | 大(大規模節點并且云邊長時間斷網恢復) |
| 設備管理能力 | 有(有管控流量和業務流量耦合問題) | 無 | 無 |
初步結論:
對比這三種方案,KubeEdge和OpenYurt/SuperEdge的架構設計差異比較大,相比而言OpenYurt/SuperEdge的架構設計更優雅一些。而OpenYurt和SuperEdge架構設計相似,SuperEdge的開源時間晚于OpenYurt,項目成熟度稍差。但是根據業界已經落地的生產方案,KubeEdge使用度及成熟度較高,同時OpenYurt/SuperEdge 開源時間較晚,還未進入CNCF孵化項目,同時結合實踐過程中的測試情況,考慮KubeEdge。
接下來,再針對KubeEdge和K3s進行對比:
K3S的部署模型如下所示:
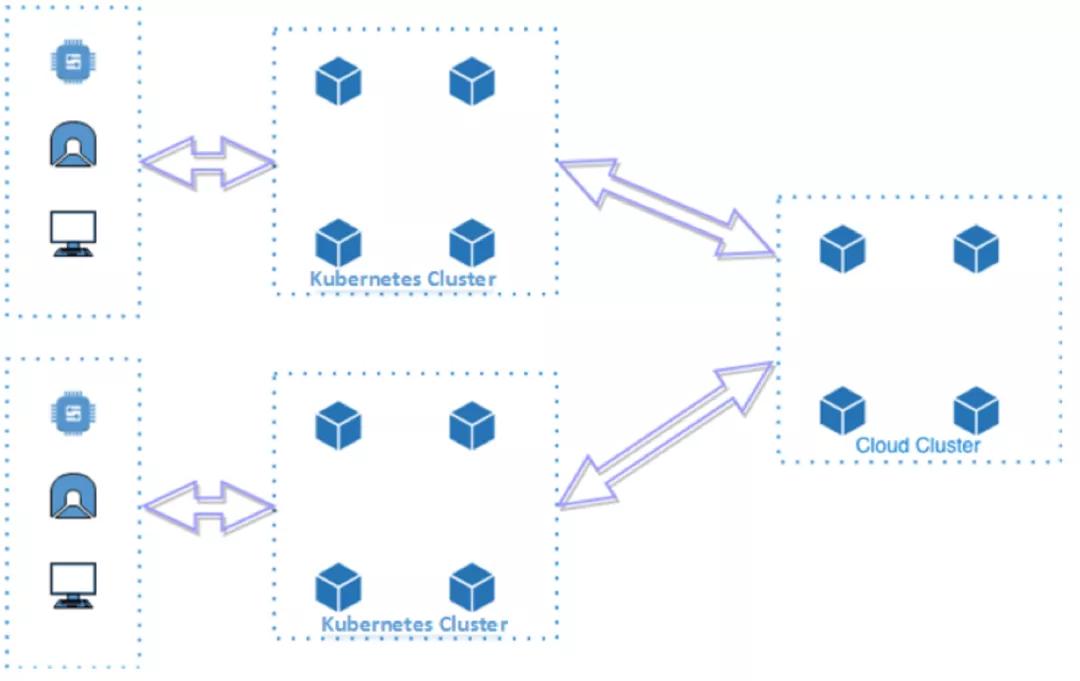
K3S會在邊緣運行完整的Kubernetes集群,這意味著K3S并不是一個去中心化的部署模型,每個邊緣都需要額外部署Kubernetes管理面,因此該部署模型只適合資源充足的“基礎設施邊緣”場景,并不適用于資源較少的“設備邊緣”的場景;同時集群之間網絡需要打通;為了管理邊緣Kubernetes集群還需要在上面疊加一層多集群管理組件。
相關對比如下:
| 項目 | KubeEdge | K3s |
|---|---|---|
| 是否CNCF項目 | 是 | 是 |
| 開源時間 | 2018.11 | 2019.2 |
| 架構 | 云管邊 | 邊緣托管 |
| 邊緣自治能力 | 支持 | 暫無 |
| 云邊協同 | 支持 | 依賴多集群管理 |
| 原生運維監控能力 | 部分支持 | 支持 |
| 與原生K8s關系 | k8s+addons | 裁剪k8s |
| iot設備管理能力 | 支持 | octopus |
5. 總體結論
KubeEdge的一大亮點是云邊協同,KubeEdge 通過 Kubernetes 標準 API 在云端管理邊緣節點、設備和工作負載的增刪改查。邊緣節點的系統升級和應用程序更新都可以直接從云端下發,提升邊緣的運維效率。但是云邊協同訪問需要借助EdgeMesh組件,其中包含server端和agent端,劫持了dns訪問流量,進行轉發,增加了網絡復雜度,同時實際測試過程中發現邊緣端服務之間無法通過svc進行訪問。而k3s雖然不涉及到云邊協同能力,但是針對加油站業務場景,可以將業務進行拆分為中心端和邊緣端,中心側業務復雜下發解碼任務等,邊緣側只負責解碼分析產生事件,并進行展示,也可以做到另一個層面的云邊協同,相比于KubeEdge云邊協同的訪問方案來講,不用部署額外組件,減少了網絡復雜度,出問題也好排查。
KubeEdge的另一大亮點是邊緣節點離線自治,KubeEdge 通過消息總線和元數據本地存儲實現了節ku點的離線自治。用戶期望的控制面配置和設備實時狀態更新都通過消息同步到本地存儲,這樣節點在離線情況下即使重啟也不會丟失管理元數據,并保持對本節點設備和應用的管理能力。而K3s在邊緣節點是一套完整集群,所以及時和中心端網絡斷聯,也同樣并不影響當前業務的運行。
從輕量化的角度來看,k3s二進制文件大小50M,edgecore80M。資源消耗,由于k3s在邊緣端是一套完整集群,所以資源消耗對比KubeEdge要高,但是針對加油站場景,邊緣服務器內存配置較高,所以這一塊也能接受。
從運維角度來看,k3s維護跟原生k8s類似,不增加額外組件,唯一難點是多集群管理,這一塊可以調研rancher及其他多集群管理方案,同時golive2.0也支持一個部署同時部署至多集群。而KubeEdge如果要接入多個加油站,需要namespace隔離,部署涉及到加污點,容忍,同時需要支持一個部署包同時部署多個namespace,而且KubeEdge為了云邊訪問,額外加入EdgeMesh組件,轉發流量,增加了網絡復雜度,遇到問題,不易排查。
所以綜合對比來看,建議選用k3s。